






Burp Target 组件主要包含站点地图、目标域、Target 工具三部分组成,他们帮助渗透测试人员更好地了解目标应用的整体状况、当前的工作涉及哪些目标域、分析可能存在的攻击面等信息,下面我们就分别来看看Burp Target的三个组成部分。
本章的主要内容有:
- 目标域设置 Target Scope
- 站点地图 Site Map
- Target 工具的使用
目标域设置 Target Scope
Target Scope中作用域的定义比较宽泛,通常来说,当我们对某个产品进行渗透测试时,可以通过域名或者主机名去限制拦截内容,这里域名或主机名就是我们说的作用域;如果我们想限制得更为细粒度化,比如,你只想拦截login目录下的所有请求,这时我们也可以在此设置,此时,作用域就是目录。总体来说,Target Scope主要使用于下面几种场景中:
- 限制站点地图和Proxy 历史中的显示结果
- 告诉Burp Proxy 拦截哪些请求
- Burp Spider抓取哪些内容
- Burp Scanner自动扫描哪些作用域的安全漏洞
- 在Burp Intruder和Burp Repeater 中指定URL
通过Target Scope 我们能方便地控制Burp 的拦截范围、操作对象,减少无效的噪音。在Target Scope的设置中,主要包含两部分功能:允许规则和去除规则。 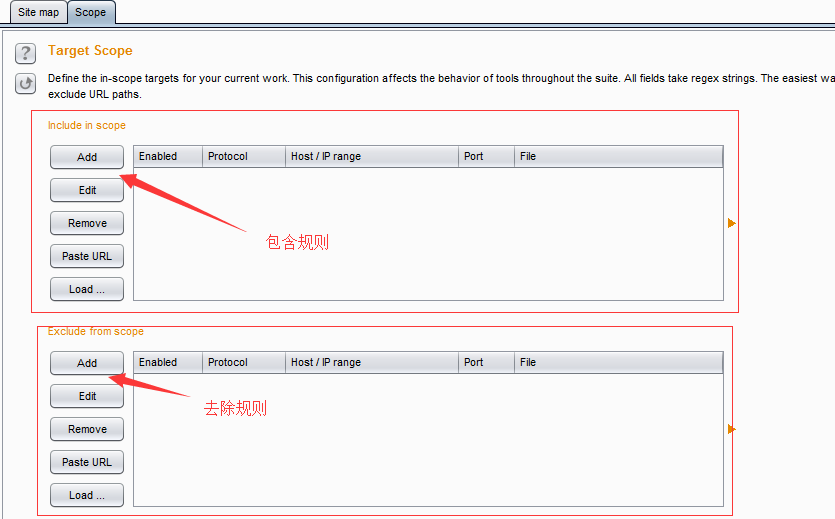
其中允许规则顾名思义,即包含在此规则列表中的,视为操作允许、有效。如果此规则用于拦截,则请求消息匹配包含规则列表中的将会被拦截;反之,请求消息匹配去除列表中的将不会被拦截。
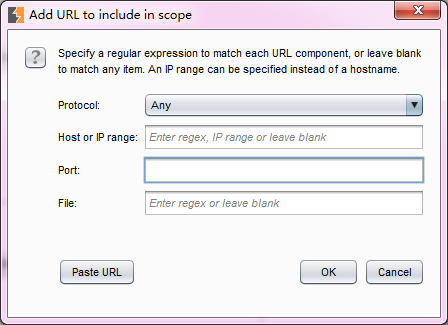
从上图的添加规则对话框中我们可以看出,规则主要由协议、域名或IP地址、端口、文件名4个部分组成,这就意味着我们可以从协议、域名或IP地址、端口、文件名4个维度去控制哪些消息出现在允许或去除在规则列表中。
当我们设置了Target Scope (默认全部为允许),使用Burp Proxy进行代理拦截,在渗透测试中通过浏览器代理浏览应用时,Burp会自动将浏览信息记录下来,包含每一个请求和应答的详细信息,保存在Target站点地图中。
站点地图 Site Map
下图所示站点地图为一次渗透测试中,通过浏览器浏览的历史记录在站点地图中的展现结果。
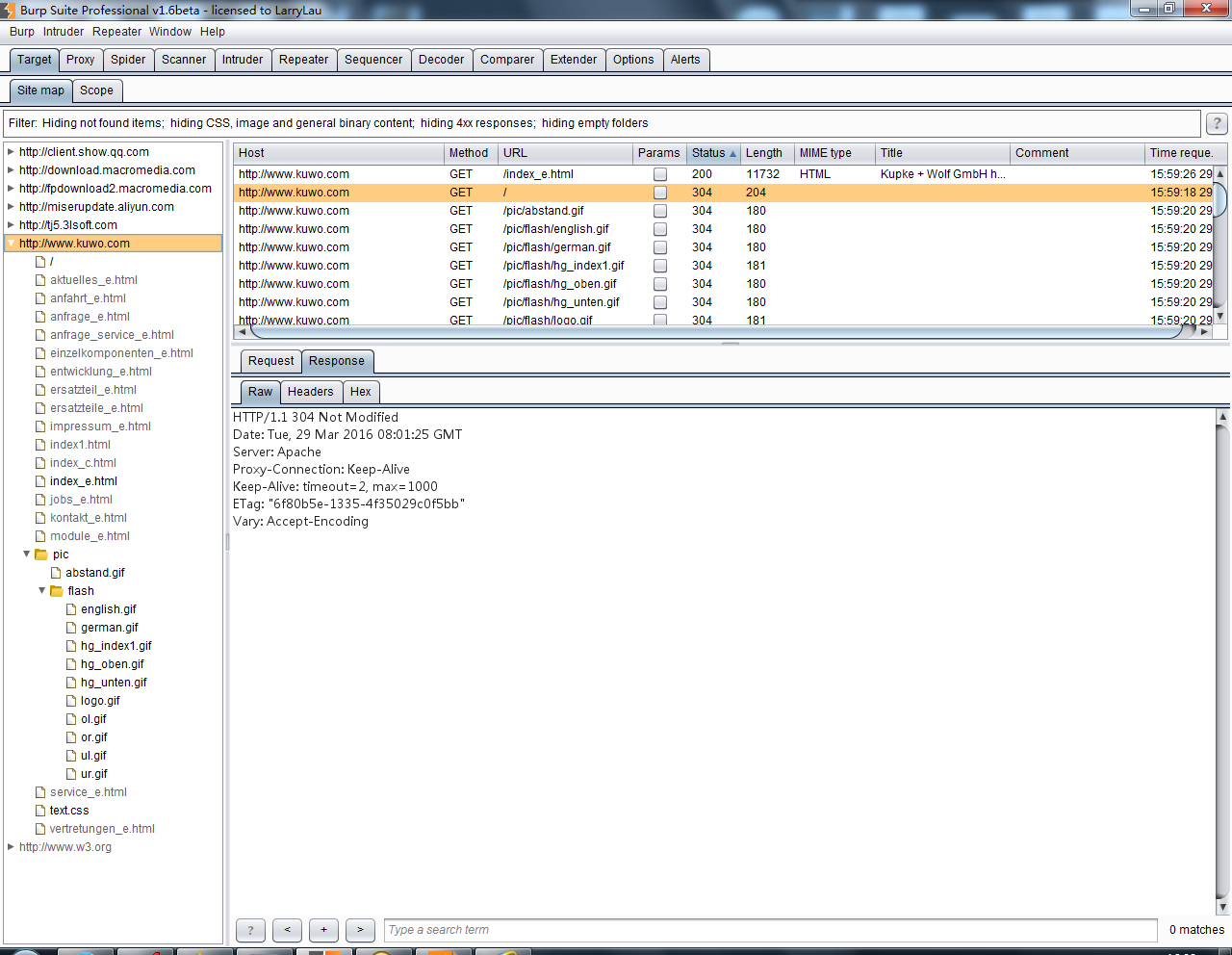
从图中我们可以看出,Site Map的左边为访问的URL,按照网站的层级和深度,树形展示整个应用系统的结构和关联其他域的url情况;
右边显示的是某一个url被访问的明细列表,共访问哪些url,请求和应答内容分别是什么,都有着详实的记录。
基于左边的树形结构,我们可以选择某个分支,对指定的路径进行扫描和抓取。
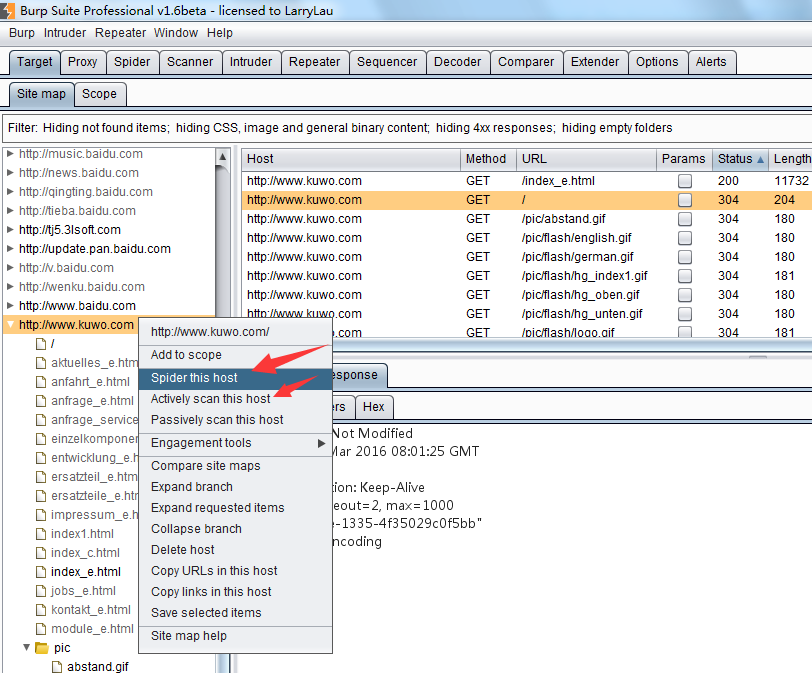
同时,我们也可以将某个域直接加入 Target Scope中.
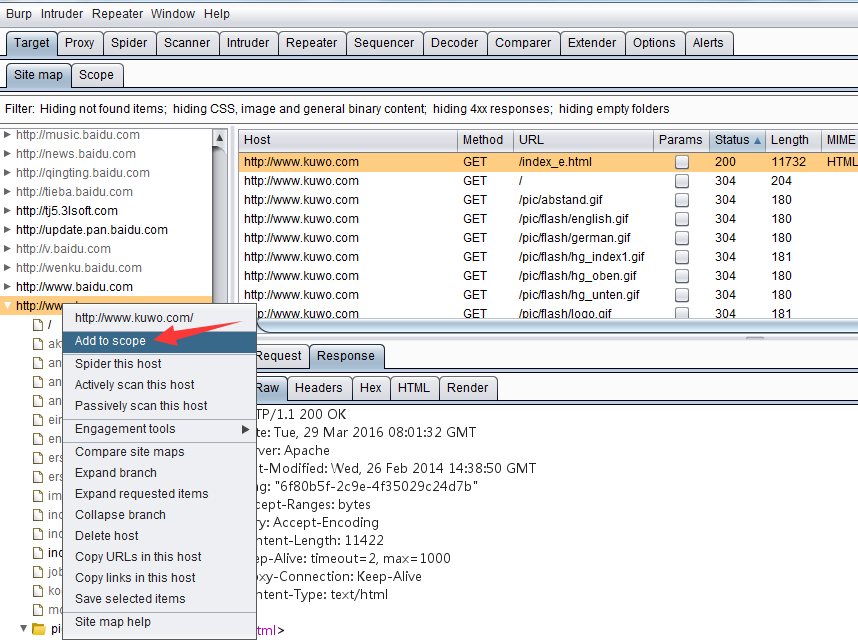
除了加入 Target Scope外,从上图中,我们也可以看到,对于站点地图的分层,可以通过折叠和展开操作,更好的分析站点结构。
Target 工具的使用
Target 工具的使用的使用主要包括以下部分:
- 手工获取站点地图
- 站点比较
- 攻击面分析
当我们手工获取站点地图时,需要遵循以下操作步骤:
1.设置浏览器代理和Burp Proxy代理,并使之能正常工作。
2.关闭Burp Proxy的拦截功能。
3.手工浏览网页,这时,Target会自动记录站点地图信息。 手工获取站点地图的方式有一个好处就是,我们可以根据自己的需要和分析,自主地控制访问内容,记录的信息比较准确。
与自动抓取相比,则需要更长的时间,如果需要渗透测试的产品系统是大型的系统,则对于系统的功能点依次操作一遍所需要的精力和时间对渗透测试人员来说付出都是很大的。
站点比较是一个Burp提供给渗透测试人员对站点进行动态分析的利器,我们在比较帐号权限时经常使用到它。
当我们登陆应用系统,使用不同的帐号,帐号本身在应用系统中被赋予了不同的权限,那么帐号所能访问的功能模块、内容、参数等都是不尽相同的,此时使用站点比较,能很好的帮助渗透测试人员区分出来。
一般来说,主要有以下3种场景:
1.同一个帐号,具有不同的权限,比较两次请求结果的差异。
2.两个不同的帐号,具有不同的权限,比较两次请求结果的差异。
3.两个不同的帐号,具有相同的权限,比较两次请求结果的差异。
下面我们就一起来看看如何进行站点比较。 1.首先我们在需要进行比较的功能链接上右击,找到站点比较的菜单,点击菜单进入下一步。
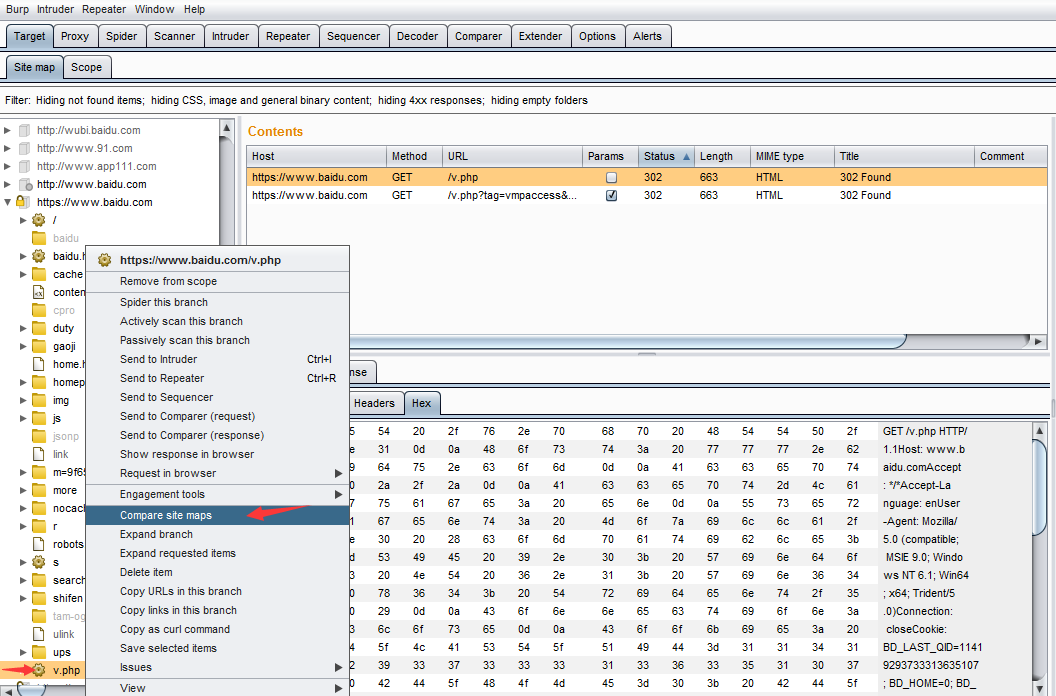
2.由于站点比较是在两个站点地图之间进行的,所以我们在配置过程中需要分别指定Site Map 1和Site Map2。通常情况下,Site Map 1 我们默认为当前会话。如图所示,点击【Next】。
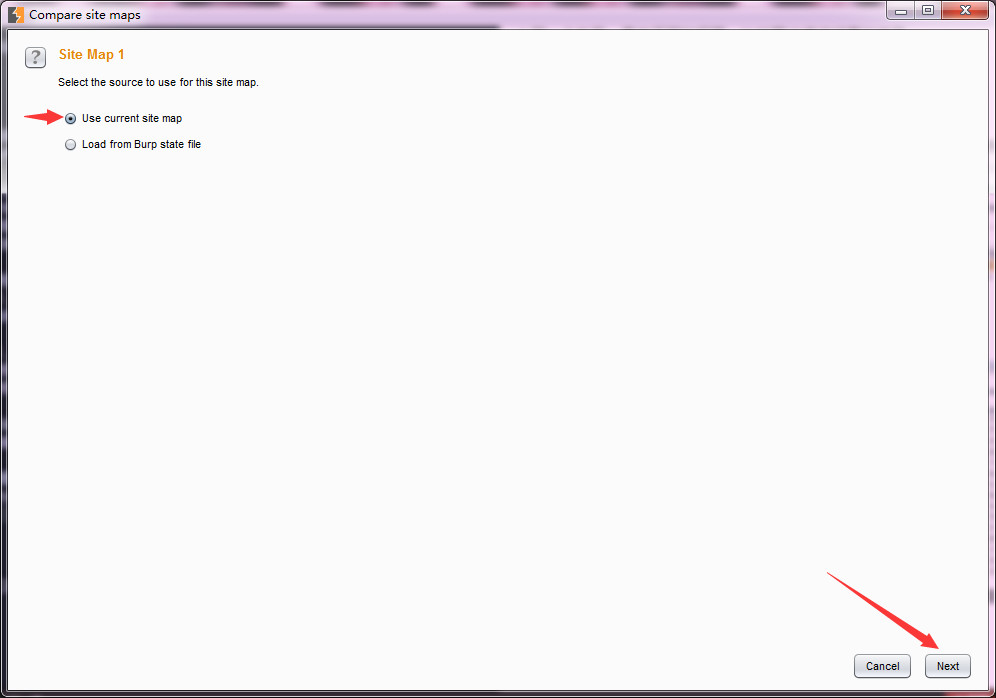
3.这时我们会进入Site Map 1 设置页面,如果是全站点比较我们选择第一项,如果仅仅比较我们选中的功能,则选择第二项。如下图,点击【Next】。
如果全站点比较,且不想加载其他域时,我们可以勾选只选择当前域。
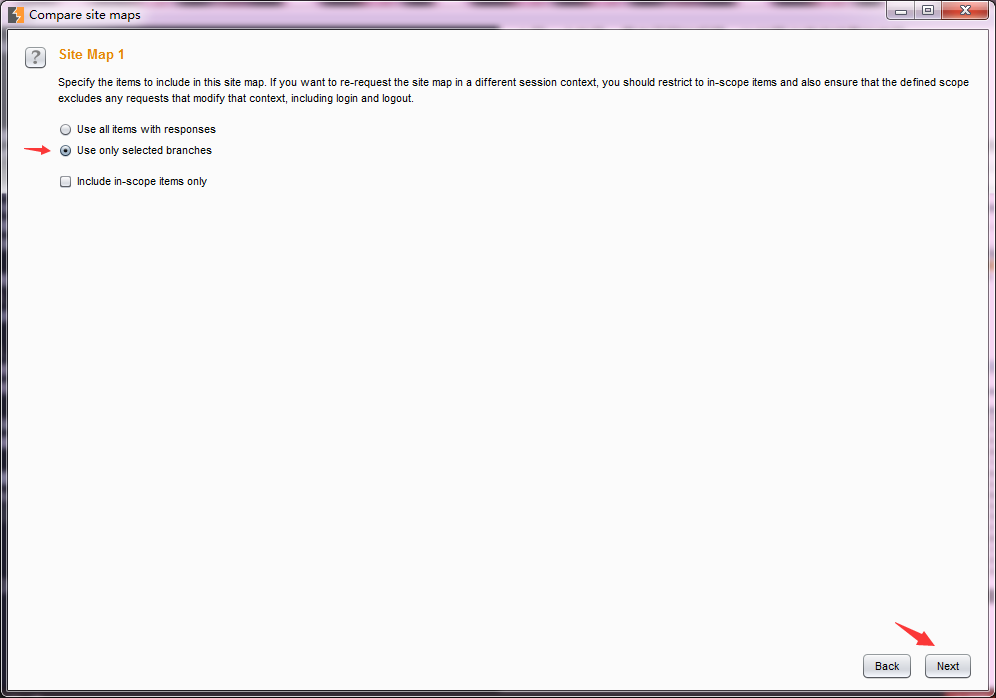
4.接下来就是Site Map 2 的配置,对于Site Map 2我们同样有两种方式,第一种是之前我们已经保存下来的Burp Suite 站点记录,第二种是重新发生一次请求作为Site Map2.这里,我们选择第二种方式。
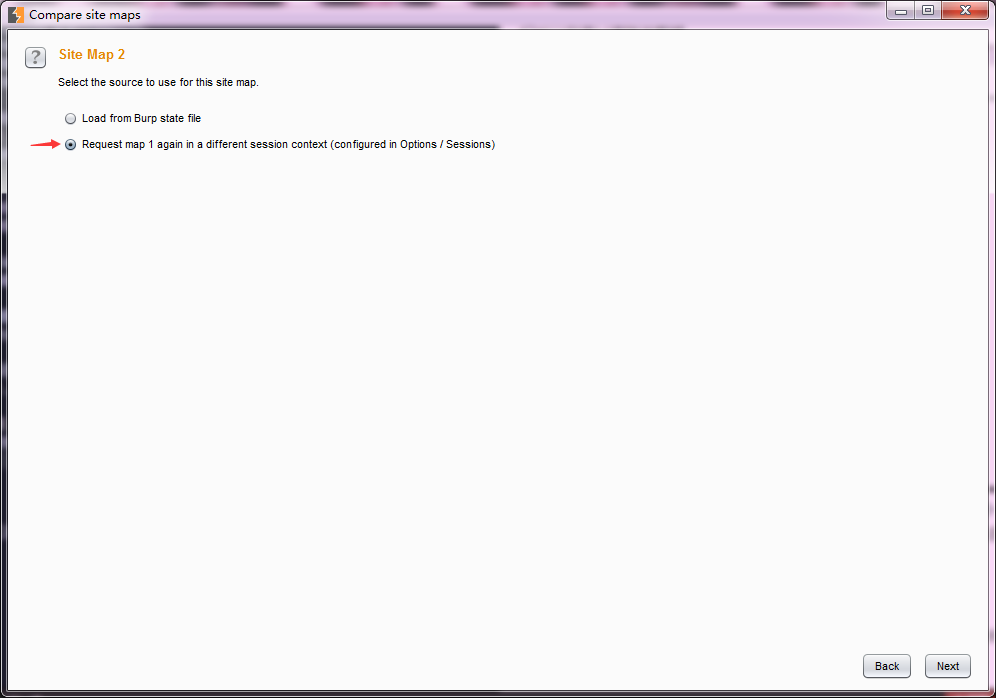
5.如果上一步选择了第二种方式,则进入请求消息设置界面。在这个界面,我们需要指定通信的并发线程数、失败重试次数、暂停的间隙时间。
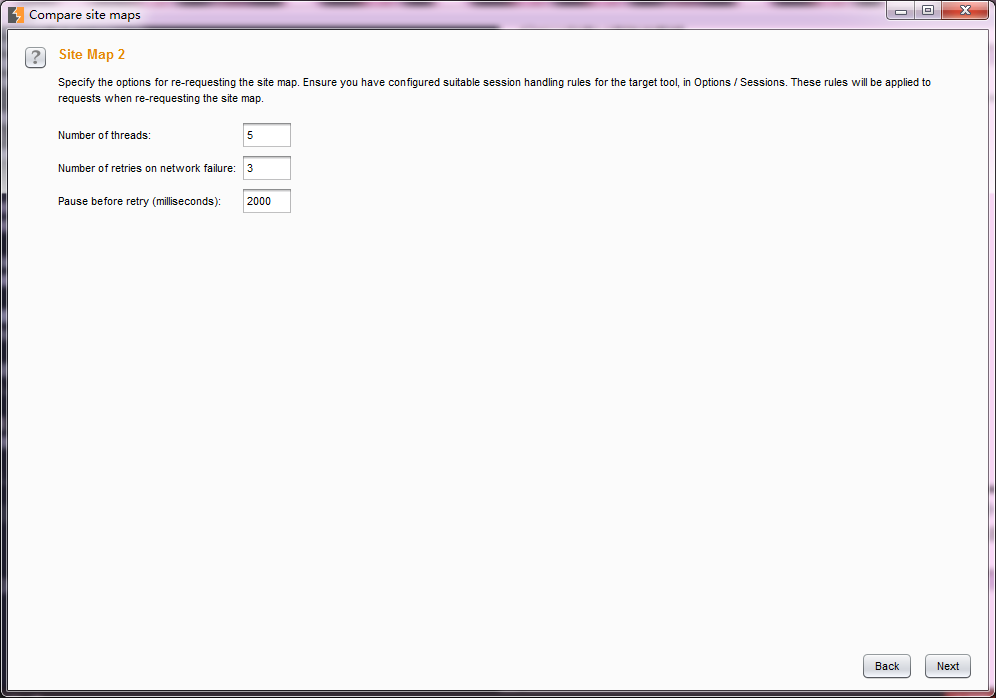
6.设置完Site Map 1 和Site Map 2之后,将进入请求消息匹配设置。在这个界面,我们可以通过URL文件路径、Http请求方式、请求参数、请求头、请求Body来对匹配条件进行过滤。
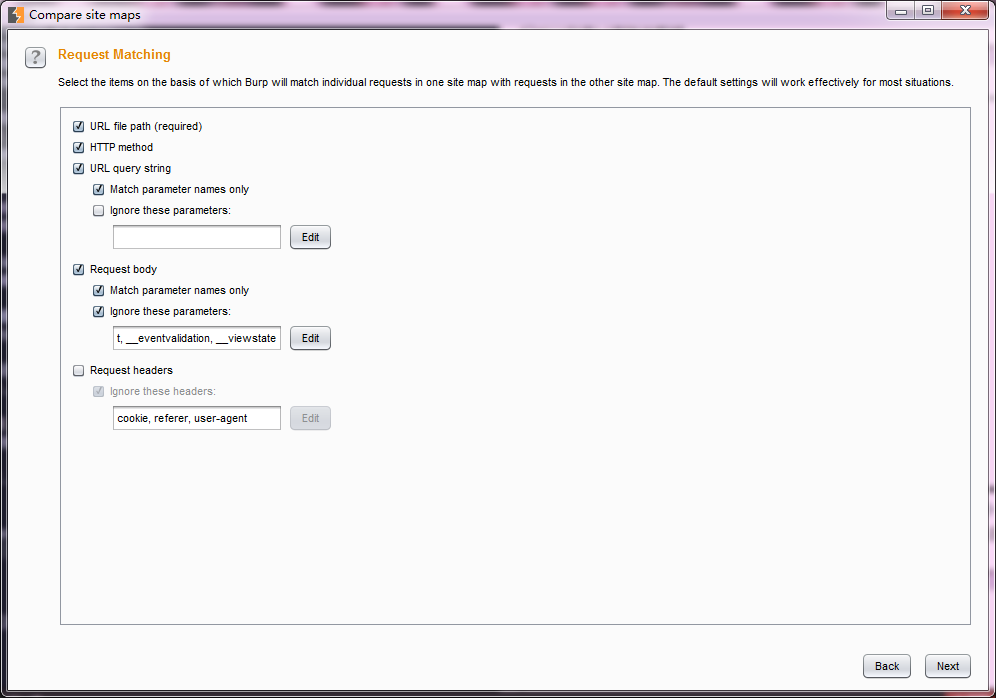
7..设置请求匹配条件,接着进入应答比较设置界面。在这个界面上,我们可以设置哪些内容我们指定需要进行比较的。从下图我们可以看出,主要有响应头、form表单域、空格、MIME类型。点击【Next】。
8.如果我们之前是针对全站进行比较,且是选择重新发生一次作为Site Map2的方式,则界面加载过程中会不停提示你数据加载的进度,如果涉及功能请求的链接较少,则很快进入比较界面。如下图。
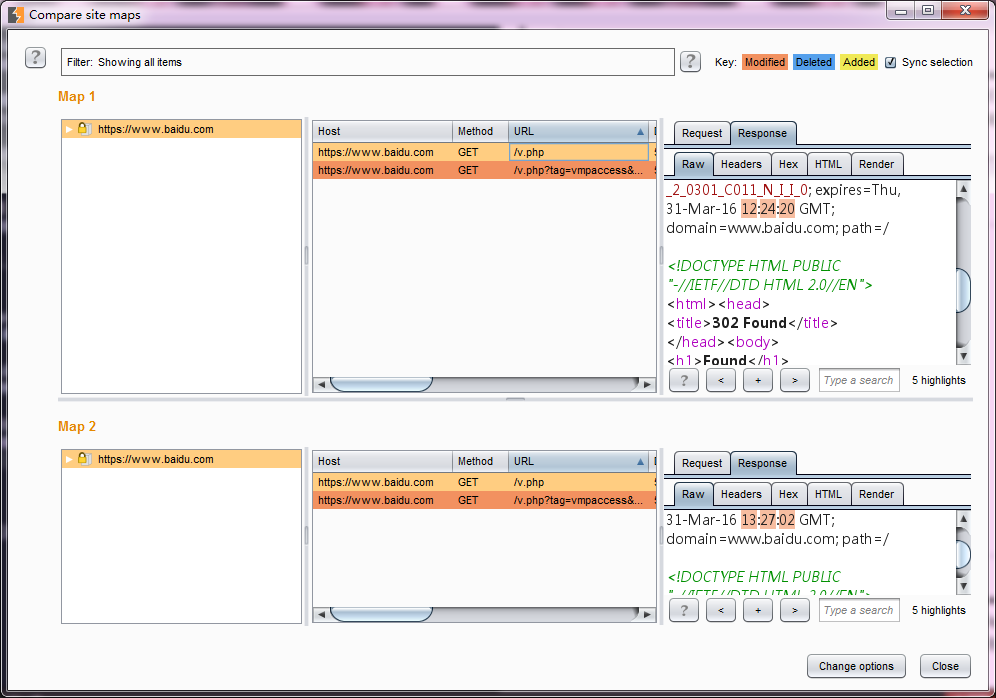
9.从上图我们可以看到,站点比较的界面上部为筛选过滤器(这个过滤器与其他过滤器使用雷同,此处不再赘述),下部由左、中、右三块构成。左边为请求的链接列表,
中间为Site Map 1 和Site Map 2的消息记录,右边为消息详细信息。当我们选择Site Map 1某条消息记录时,默认会自动选择Site Map 2与之对应的记录,
这是有右上角的【同步选择】勾选框控制的,同时,在右边的消息详细区域,会自动展示Site Map 1与Site Map 2通信消息的差异,包含请求消息和应答消息,存在差异的地方用底色标注出来。
攻击面分析是Burp Suite 交互工具(Engagement tools)中的功能,这里我们先看看Analyze Target使用,其他的功能会在高级使用相关章节讲述。
1.首先,我们通过站点地图,打开Analyze Target,如图所示。
2.在弹出的分析界面中,我们能看到概况、动态URL、静态URL、参数4个视图。
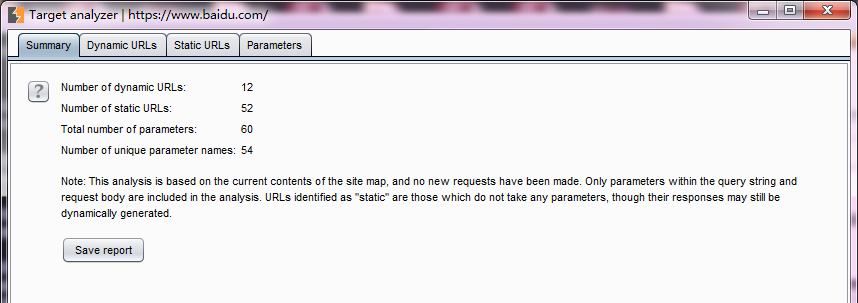
3.概况视图主要展示当前站点动态URL数量、静态URL数量、参数的总数、唯一的参数名数目,通过这些信息,我们对当前站点的总体状况有粗线条的了解。
4.动态URL视图展示所有动态的URL请求和应答消息,跟其他的工具类似,当你选中某一条消息时,下方会显示此消息的详细信息。
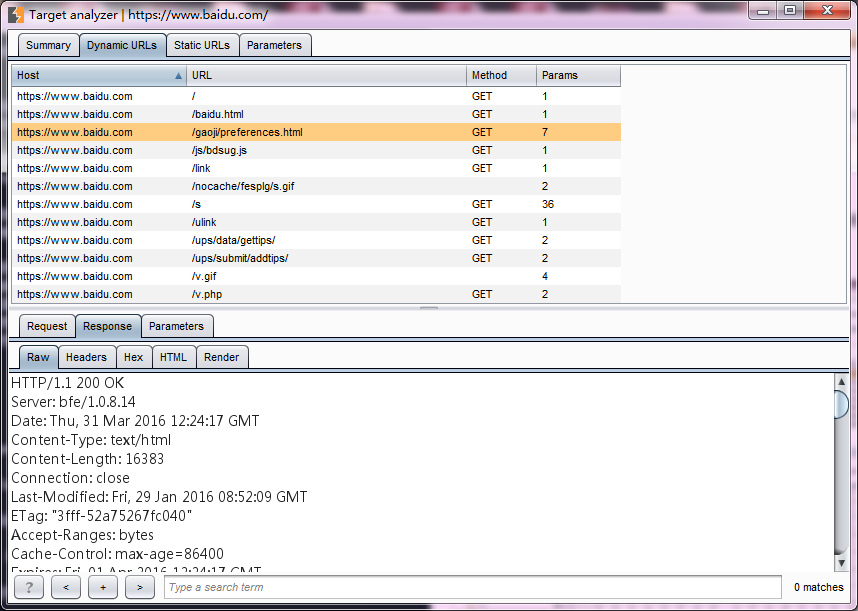
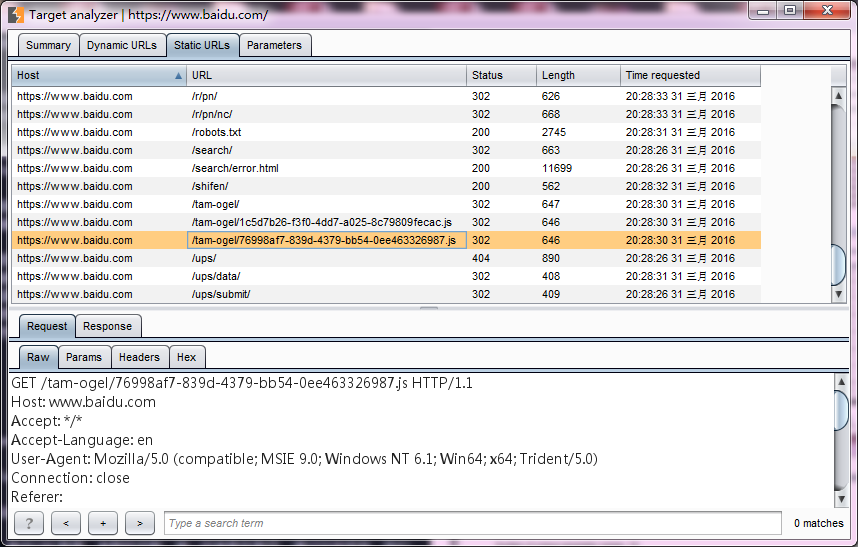
5.静态URL视图与动态URL视图类似,如图.
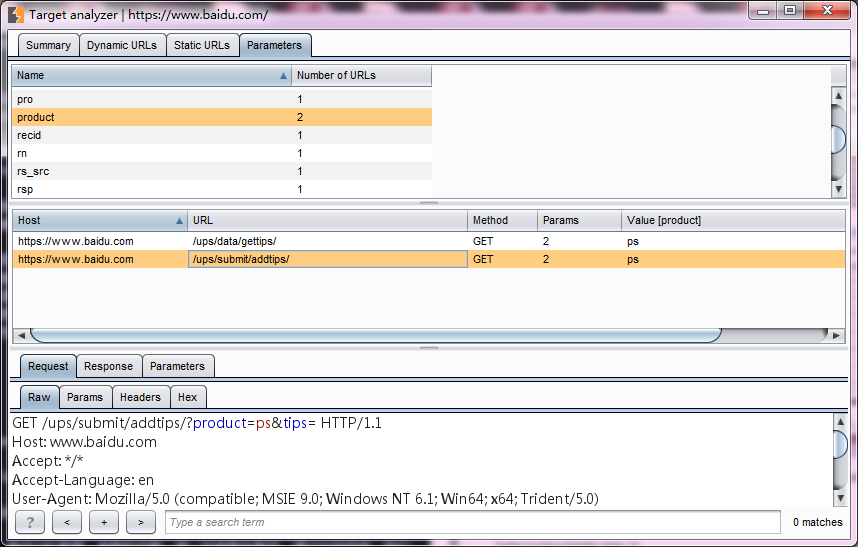
6.参数视图有上中下三部分组成,上部为参数和参数计数统计区,你可以通过参数使用的次数进行排序,对使用频繁的参数进行分析;中部为参数对于的使用情况列表,记录对于的参数每一次的使用记录;
下部为某一次使用过程中,请求消息和应答消息的详细信息。
在使用攻击面分析功能时,需要注意,此功能主要是针对站点地图中的请求URL进行分析,如果某些URL没有记录,则不会被分析到。
同时,在实际使用中,存在很点站点使用伪静态,如果请求的URL中不带有参数,则分析时无法区别,只能当做静态URL来分析。
第六章 如何使用Burp Spider
通过前一章的学习,我们了解到,存在于Burp Target中的站点信息,我们可以直接传送到Burp Spider中进行站点信息的爬取。这一章我们重点来学习Burp Spider的使用,主要包含两个方面:
- Spider控制(Control)
- Spider可选项设置(Options)
Burp Spider的功能主要使用于大型的应用系统测试,它能在很短的时间内帮助我们快速地了解系统的结构和分布情况,下面我们就先来看看Spider控制,
Spider控制
Spider控制界面由Spider 状态和Spider 作用域两个功能组成。
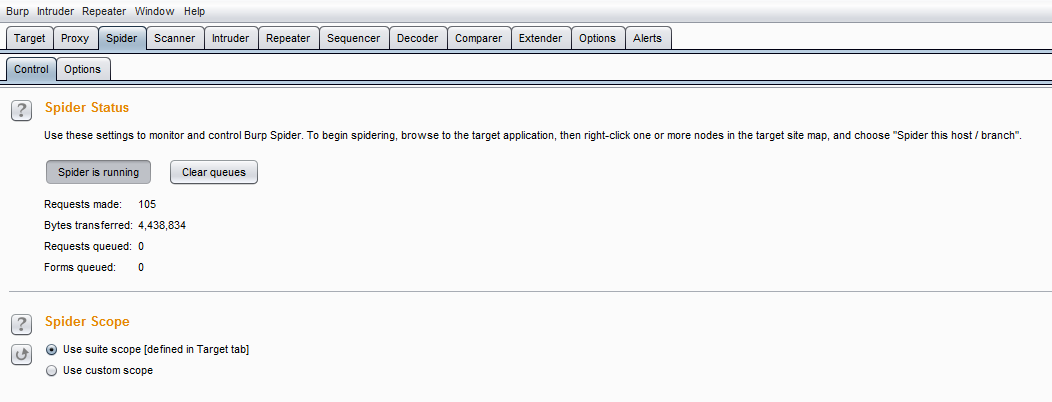
Spider 状态除了显示当前进度、传输情况、请求队列等统计信息外,还有Spider运行/暂停按钮与清空队列按钮,分别用来控制Spider是否运行和队列中的数据管理。
而Spider 作用域是用来控制Spider的抓取范围,从图中我们可以看到有两种控制方式,一种是使用上一章讲的Target Scope,另一种是用户自定义。
当我们选中用户自定义按钮,界面改变成下面的样子,如下图所示。
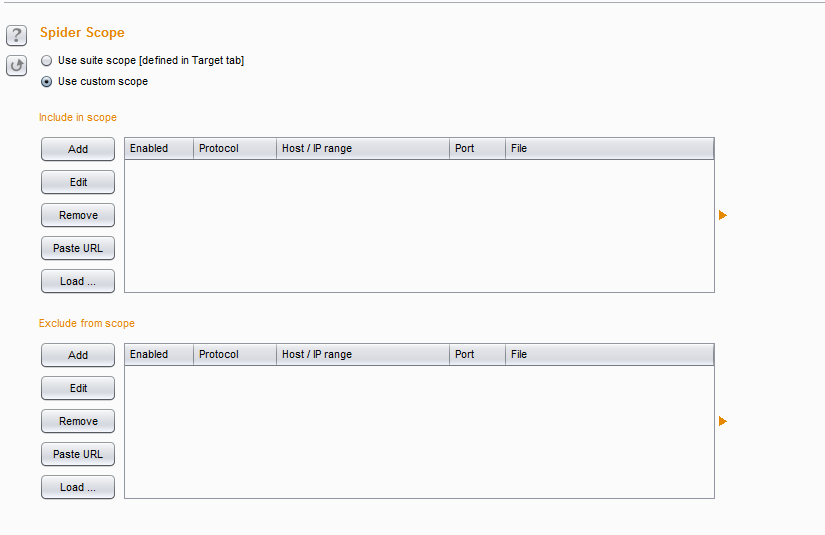
此处用户自定义作用域的配置与Target Scope 的配置完全一致,具体使用方法请参数上一章Target Scope 的配置。
Spider可选项设置
Spider可选项设置由抓取设置、抓取代理设置、表单提交设置、应用登陆设置、蜘蛛引擎设置、请求消息头设置六个部分组成。
- 抓取设置(Crawls Settings) -此项是用来控制蜘蛛抓取网页内容的方式
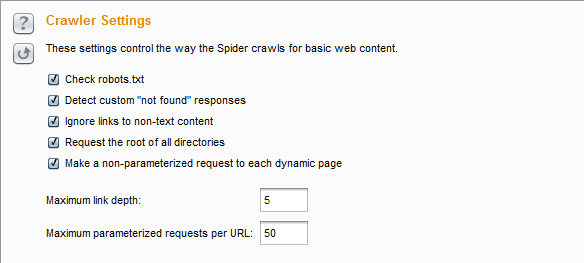
- 自上而下依次是:检查robots.txt 文件、检测404应答、忽略内容为空的链接、爬取根目录下所有文件和目录、对每一个动态页面发送无参数请求、最大链接深度、最大请求URL参数数目
- 抓取代理设置(Passive Spidering )
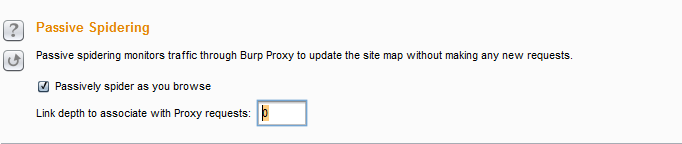
- 这个设置比较简单,第一个如果勾选,则爬取时通过Burp Proxy,反之则不通过。第二个设置是控制代理的链接深度。默认为0,表示无限深度,即无论有多少层级的URL均需要爬取。
- 表单提交设置(Form Submission) 表单提交设置主要是用来控制在蜘蛛抓取过程中,对于form表单的处理方式,其界面如下图:
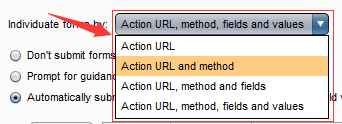
- 第一个下拉选项中,是对form表单域的处理内容做控制,默认选择Action URL、method、fields、values,即同时处理请求的url、请求方式GET或者POST、包含哪些属性名以及属性值。点击下拉选项,可以选择其中一个或者几个。如下图:
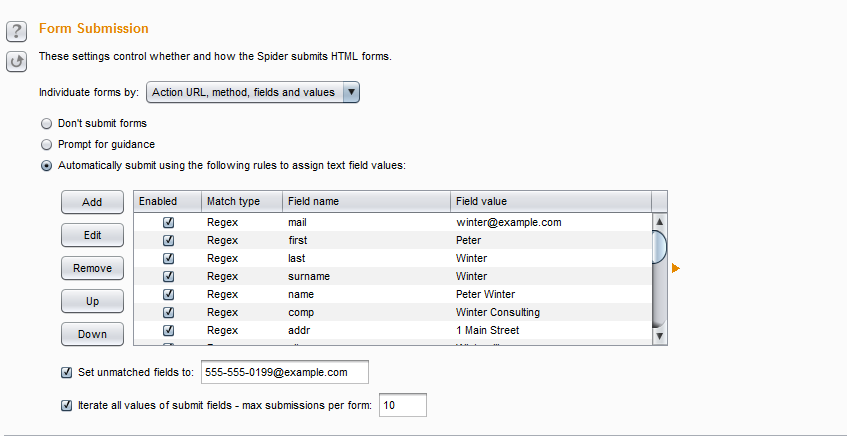
- 接下来的设置的控制form表单的处理方式:不提交表单、需要手工确认、使用默认值自动填写三种方式。 不提交表单的含义是抓取时候不提交表单数据,这个非常好理解;需要手工确认是指当抓取表单时,弹出界面,让渗透测试人员自己手工确认表单数据;使用默认值自动填写是对表单的内容,使用下方的各个配置项进行匹配(匹配时可以使用完全匹配和正则表达式匹配两种方式其一),默认填写这些值,然后自动进行提交。其界面如下图所示:
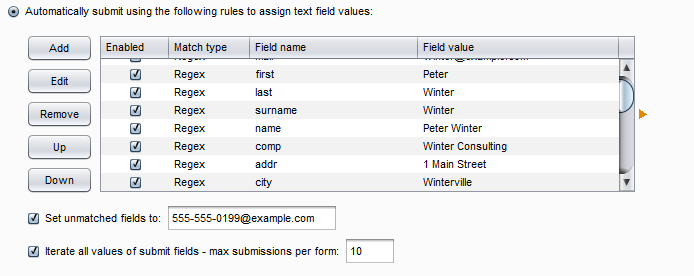
- 从上图我们可以看出,对于表单的输入域我们可以添加和修改以满足实际情况的需要,如果还有其他的属性输入域我们不想每一个都录入,可以勾选“设置不匹配的属性值”,统一指定输入的值。如图中的555-555-0199@example.com
- 应用登陆(Application Login) 此选择项主要用来控制抓取时,登陆页面的处理方式。
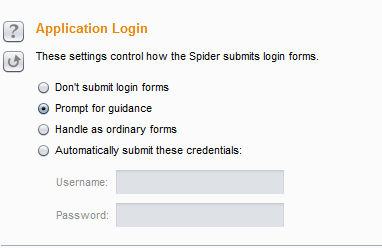
- 选择项依次是:不提交登陆信息、手工确认登陆信息、作为普通表单处理(如果选择此项,则把登陆表单的form当作其他表单一样处理,对于登陆表单将使用"表单提交设置" 中的具体配置)、自动提交登陆(选择此项,需要在下方的输入框中指定用户名和密码)
- 蜘蛛引擎设置(Spider Engine)和HTTP 消息头设置(Requests Header)
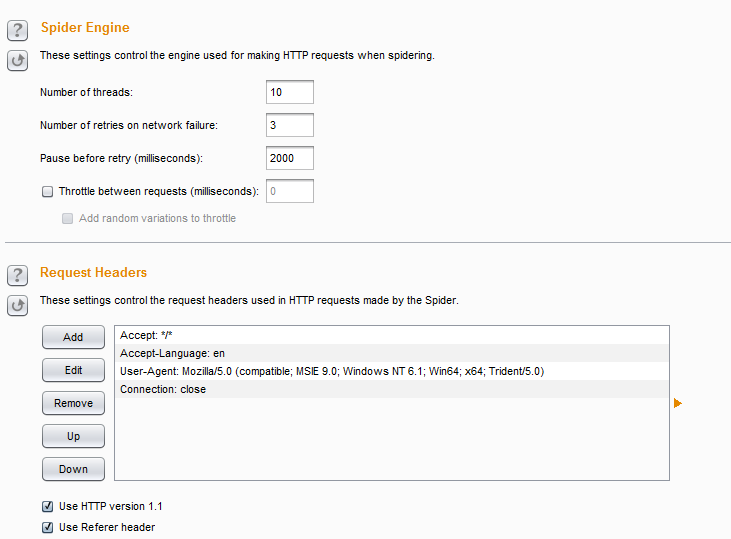
- 其中蜘蛛引擎设置主要是用来控制蜘蛛抓取的线程数、网络失败时重试的次数、重试暂停间隙等,而HTTP 消息头设置是用来设置Http请求的消息头自定义,比如说,我们可以编辑消息头信息,可以指定请求为移动设备,或者不同的手机型号,或者指定为Safari浏览器,指定HTTP协议版本为1.1、使用referer等。
第七章 如何使用Burp Scanner
Burp Scanner的功能主要是用来自动检测web系统的各种漏洞,我们可以使用Burp Scanner代替我们手工去对系统进行普通漏洞类型的渗透测试,从而能使得我们把更多的精力放在那些必须要人工去验证的漏洞上。
在使用Burp Scanner之前,我们除了要正确配置Burp Proxy并设置浏览器代理外,还需要在Burp Target的站点地图中存在需要扫描的域和URL模块路径。如下图所示:
当Burp Target的站点地图中存在这些域或URL路径时,我们才能对指定的域或者URL进行全扫描或者分支扫描。下面我们就来整体的学习一下,一次完整的Burp Scanner使用大概需要哪些步骤。
本章的主要内容有:
- Burp Scanner基本使用步骤
- Burp Scanner扫描方式
- Burp Scanner扫描报告
- Burp Scanner扫描控制
- Burp Scanner可选项设置
Burp Scanner基本使用步骤
Burp Scanner基本使用主要分为以下15个步骤,在实际使用中可能会有所改变,但大体的环节主要就是下面的这些。
1.确认Burp Suite正常启动并完成浏览器代理的配置。
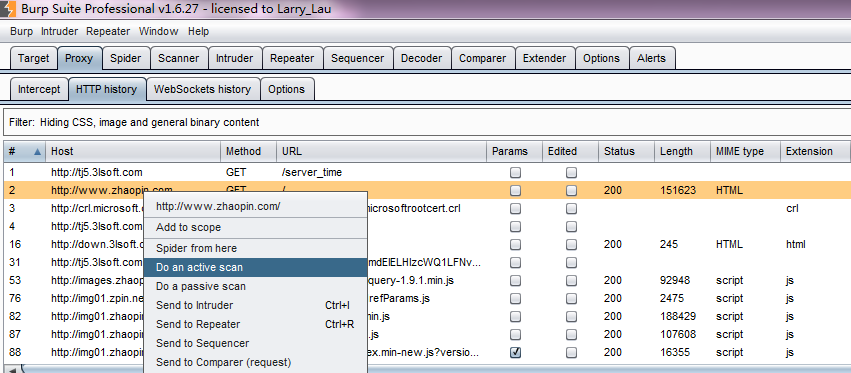
2.进入Burp Proxy,关闭代理拦截功能,快速的浏览需要扫描的域或者URL模块。
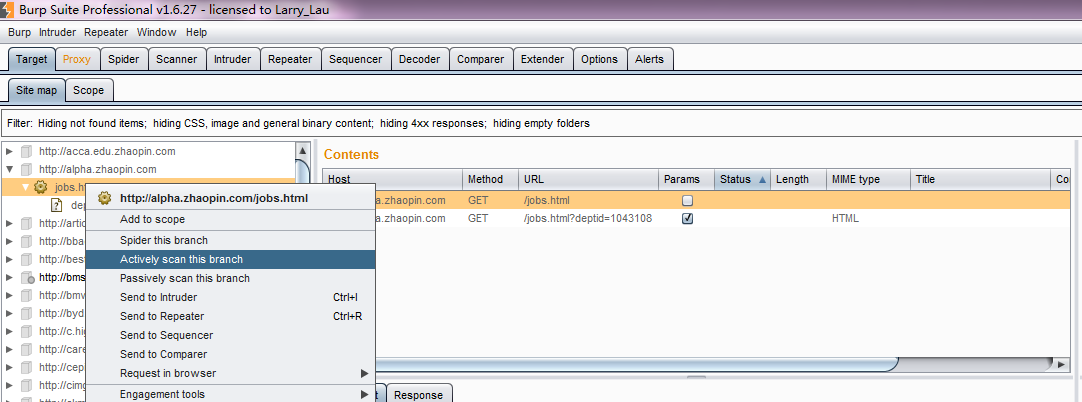
3.当我们浏览时,默认情况下,Burp Scanner会扫描通过代理服务的请求,并对请求的消息进行分析来辨别是非存在系统漏洞。同时,当我们打开Burp Target时,也会在站点地图中显示请求的URL树。
4.我们可以有针对性的选择Burp Target站点地图下的某个节点上链接URL上,弹出右击菜单,进行Active Scan。然后在弹出的确认框中,点击【YES】即进行扫描整个域。
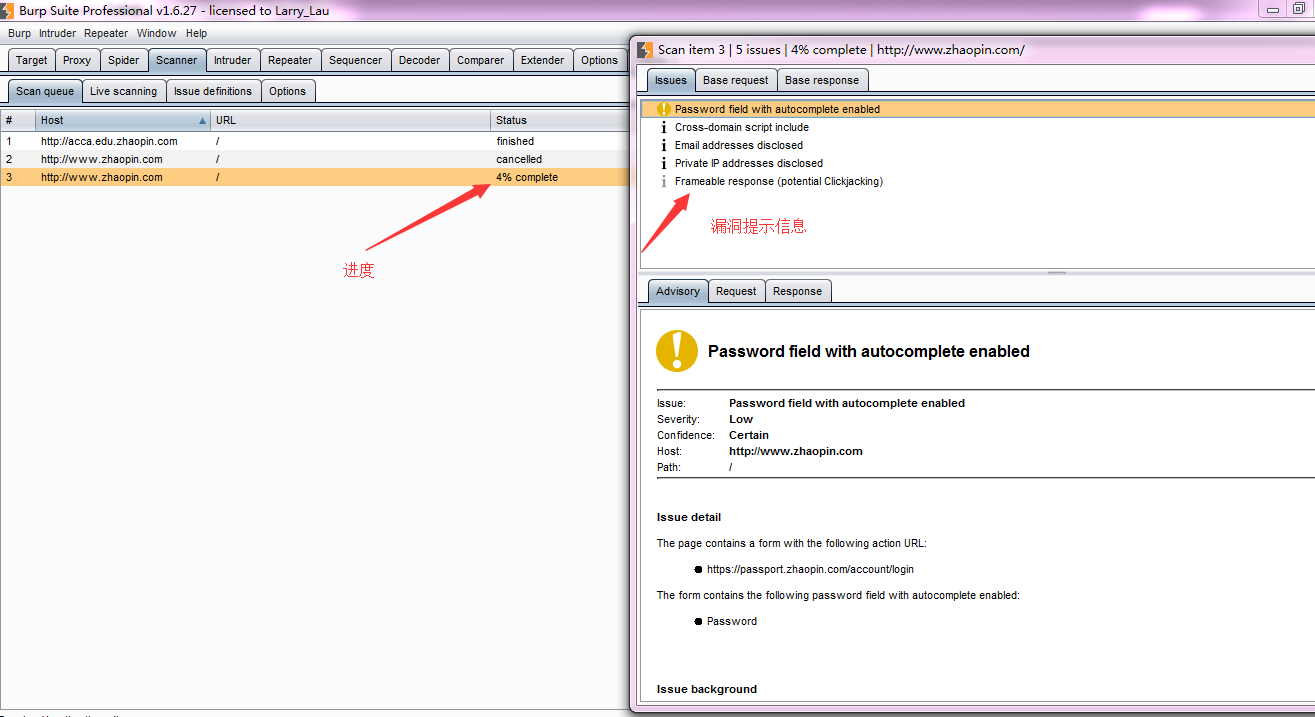
6.这时,我们打开Burp Scanner 选项卡,在队列子选项卡中,会看到当前扫描的进度。如果我们双击URL,则弹出扫描结果的提示信息。
7.如果我们在Burp Target站点地图下选择某个子目录进行扫描,则会弹出更优化的扫描选项,我们可以对选项进行设置,指定哪些类型的文件不再扫描范围之内。

8.当我们再次返回到Burp Scanner 选项卡界面时,选择的子目录已经开始在扫描中,其扫描的进度依赖于需要扫描内容的多少。
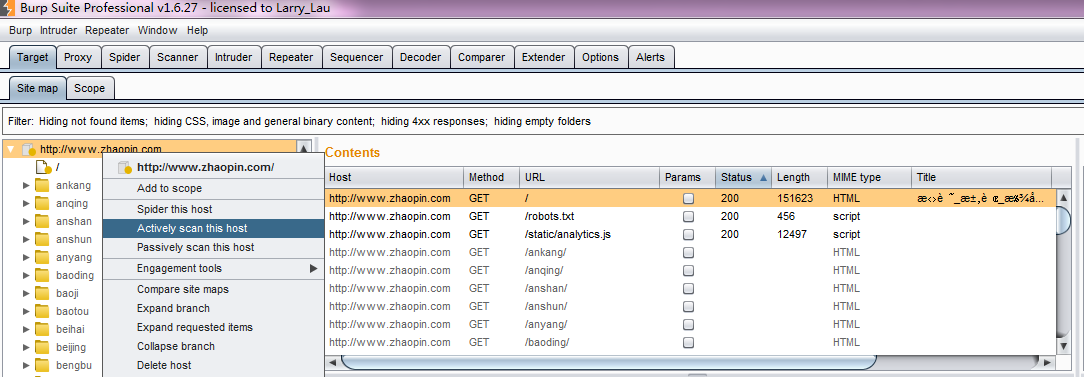
9.如果我们没有定义了目标作用域(Target Scope),最简单的方式就是在Burp Target站点地图上右击弹出菜单中添加到作用域,然后自动进行扫描。
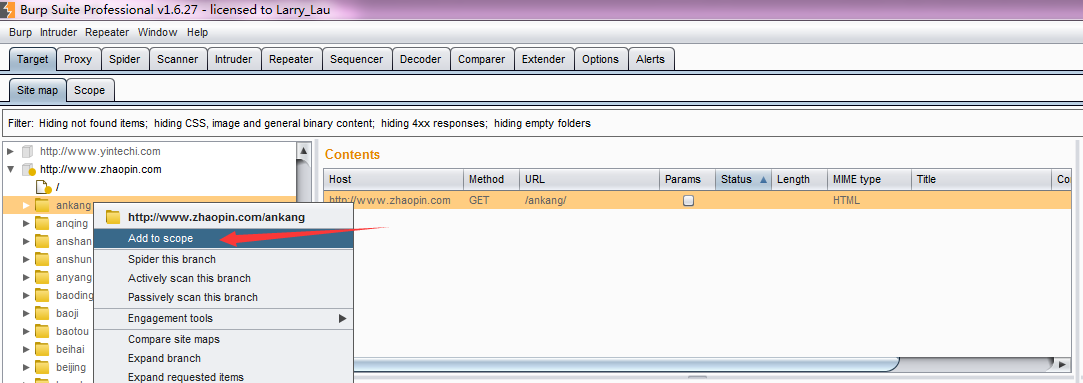
10.然后进入Burp Scanner的Live scanning子选项卡,在Live Active Scanning控制块中,选择Use suite scope,这样,Burp Scanner将自动扫描经过Burp Proxy的交互信息。
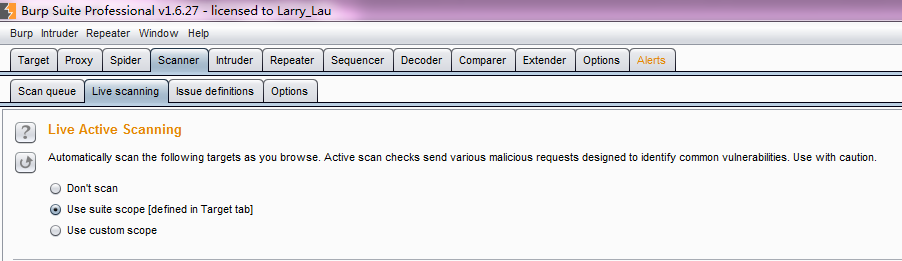
11.当我们再次使用浏览器对需要测试的系统进行浏览时,Burp Scanner不会发送额外的请求信息,自动在浏览的交互信息的基础上,完成对请求消息的漏洞分析。
12.此时,当我再返回到Burp Target站点地图界面,将提示系统可能存在的漏洞情况,以及处理这些漏洞的建议。
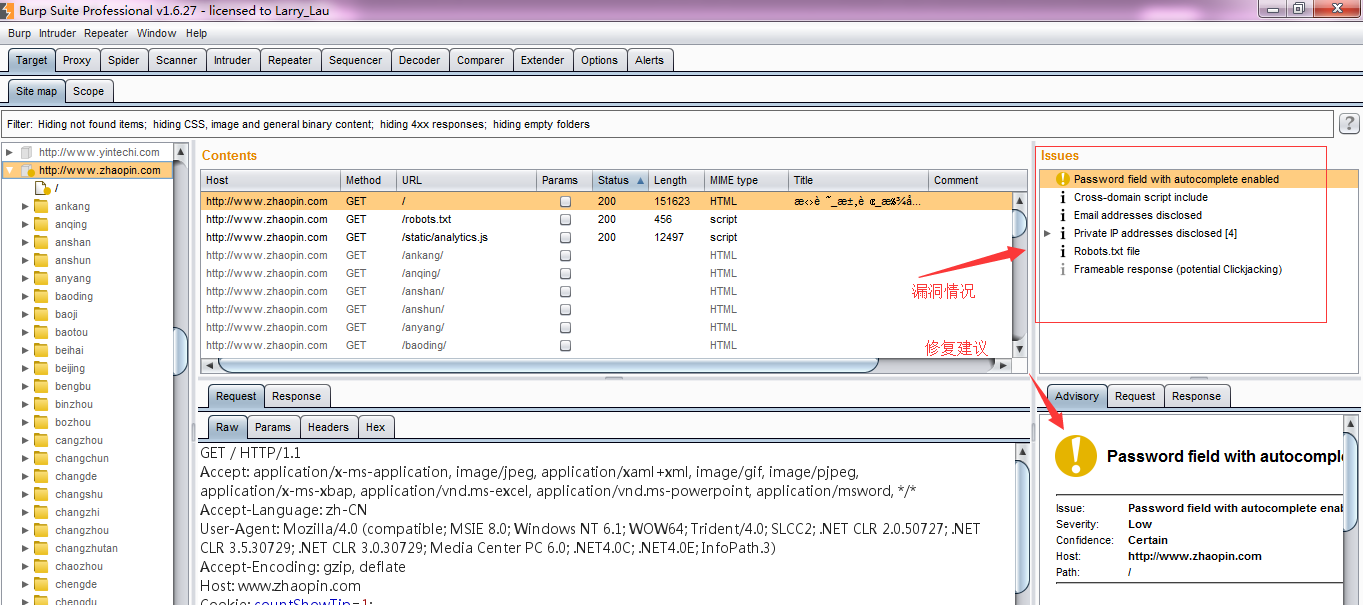
13.同时,我们也可以在漏洞提示的请求信息上,将消息发送到Burp Repeater模块,对漏洞进行分析和验证。
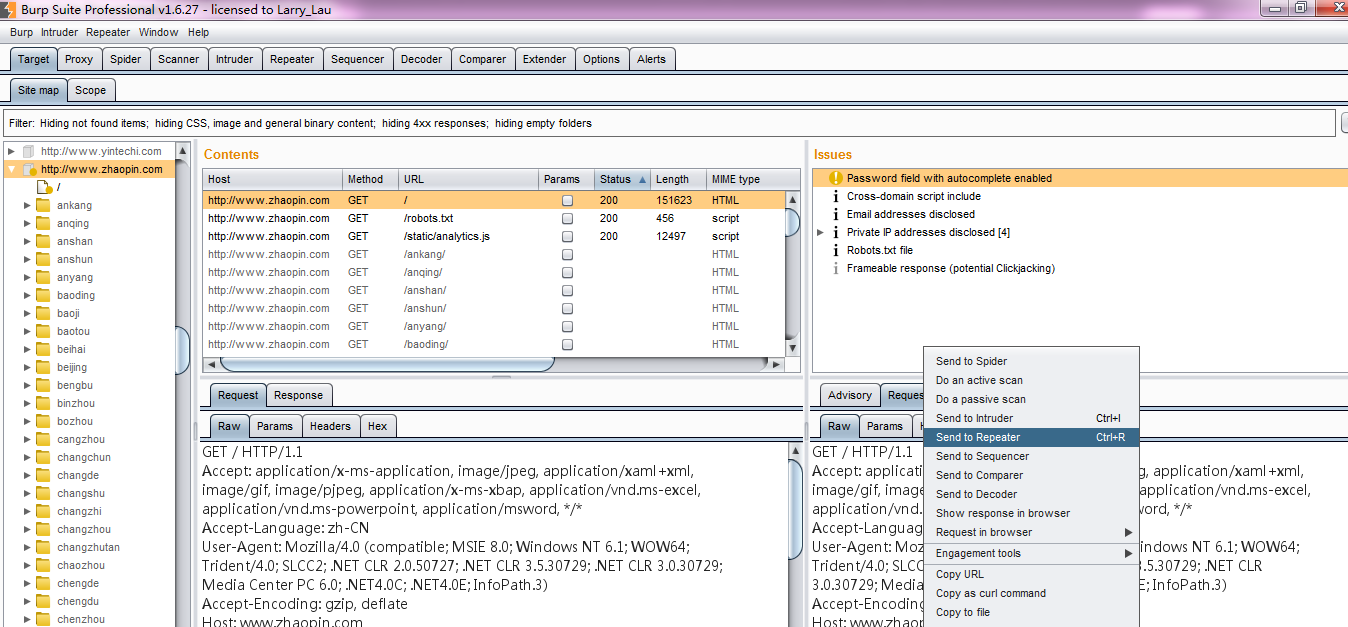
14.随着Burp Scanner扫描的进度,在Burp Target站点地图界面上的issues模块中的漏洞信息也会不断的更新。
15.当Burp Scanner扫描完成之后,我们在Burp Target站点地图的选择链接右击,依次选择issues-->report issues for this host 即可导出漏洞报告。
Burp Scanner扫描方式
通过以上的操作步骤我们可以学习到,Burp Scanner扫描方式主要有两种:主动扫描和被动扫描
- 主动扫描(Active Scanning)
当使用主动扫描模式时,Burp 会向应用发送新的请求并通过payload验证漏洞。这种模式下的操作,会产生大量的请求和应答数据,直接影响系统的性能,通常使用在非生产环境。它对下列的两类漏洞有很好的扫描效果:
- 客户端的漏洞,像XSS、Http头注入、操作重定向;
- 服务端的漏洞,像SQL注入、命令行注入、文件遍历。
对于第一类漏洞,Burp在检测时,会提交一下input域,然后根据应答的数据进行解析。在检测过程中,Burp会对基础的请求信息进行修改,即根据漏洞的特征对参数进行修改,模拟人的行为,以达到检测漏洞的目的。 对于第二类漏洞,一般来说检测比较困难,因为是发生在服务器侧。比如说SQL注入,有可能是返回数据库错误提示信息,也有可能是什么也不反馈。Burp在检测过程中,采用各个技术来验证漏洞是否存在,比如诱导时间延迟、强制修改Boolean值,与模糊测试的结果进行比较,已达到高准确性的漏洞扫描报告。
- 被动扫描(Passive Scanning)
当使用被动扫描模式时,Burp不会重新发送新的请求,它只是对已经存在的请求和应答进行分析,这对系统的检测比较安全,尤其在你授权访问的许可下进行的,通常适用于生成环境的检测。一般来说,下列这些漏洞在被动模式中容易被检测出来:
- 提交的密码为未加密的明文。
- 不安全的Cookie的属性,比如缺少的HttpOnly和安全标志。
- cookie的范围缺失。
- 跨域脚本包含和站点引用泄漏。
- 表单值自动填充,尤其是密码。
- SSL保护的内容缓存。
- 目录列表。
- 提交密码后应答延迟。
- session令牌的不安全传输。
- 敏感信息泄露,像内部IP地址,电子邮件地址,堆栈跟踪等信息泄漏。
- 不安全的ViewState的配置。
- 错误或者不规范的Content-type指令。
虽然被动扫描模式相比于主动模式有很多的不足,但同时也具有主动模式不具备的优点,除了前文说的对系统的检测在我们授权的范围内比较安全外,当某种业务场景的测试,每测试一次都会导致业务的某方面问题时,我们也可以使用被动扫描模式,去验证问题是否存在,减少测试的风险。
Burp Scanner扫描报告
当我们对一个系统进行扫描完毕后,通常需要生成扫描报告,Burp Scanner支持的报告类型有HTML和XML两种格式。无法何种格式的扫描报告,其内容基本一致,主要由以下部分组成。报告样例可以点击Burp Scanner report查看.
除了头部的综述和目录外,每一个漏洞的章节通常包含:
1.序号 表示漏洞的序号,如果有多个同样的漏洞,报告中只会有一个序号。
2.漏洞的类型,可以近似地理解与OWASP的类型相对应。
3.漏洞名称,具体可参考 Issue Definitions子选项卡。
4.漏洞路径,漏洞对应的多个URL链接。
5.漏洞的发生点,通常为参数名。
6.问题的描述(Issue background) 描述漏洞发生的成因
7.解决建议(Remediation background)提供解决的思路和建议
8.请求消息和应答消息的详细信息。
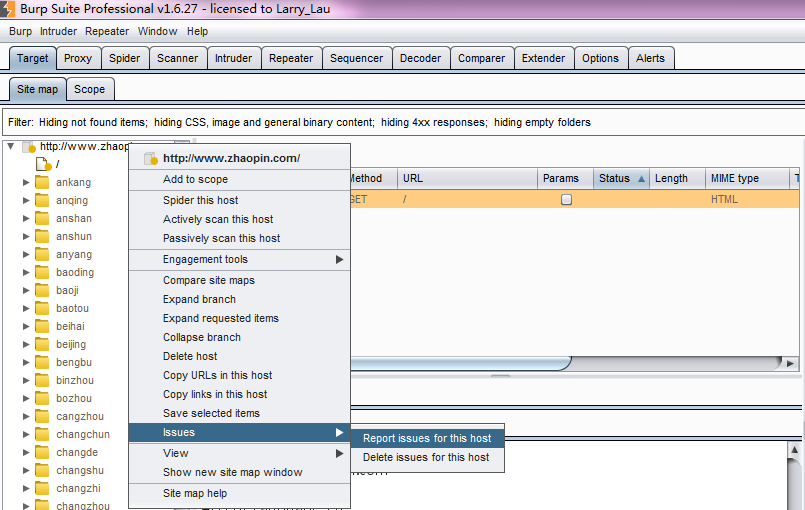
如果我们想对某次的扫描结果进行保存,需要Burp Target 的站点地图子选项卡的问题面板(Issue)上右击,在弹出的菜单中选择report Issues进行设置并保存即可。(注意,如果想导出所有的漏洞,需要选中所有的问题列表) 具体导出漏洞报告的步骤如下:
1.选中需要保存的漏洞,右击弹出菜单,如下图:
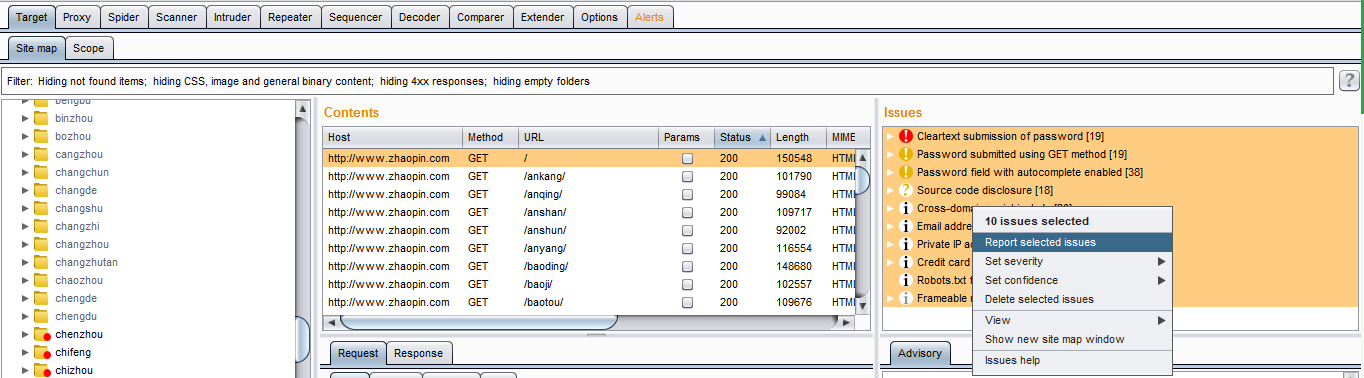
2.在弹出的对话框中选择需要保存的漏洞报告格式。
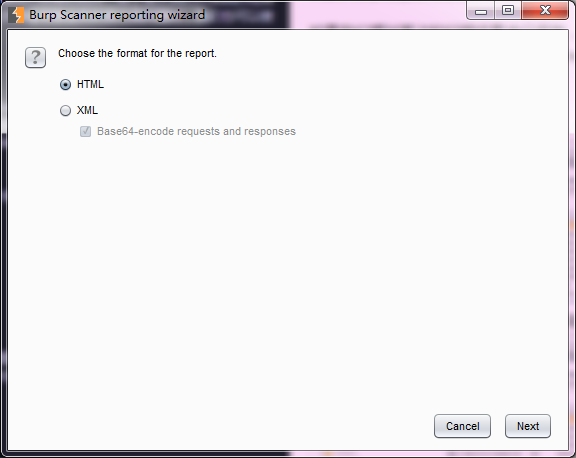
3.选择漏洞明细包含内容。
4.请求消息和应答消息设置。
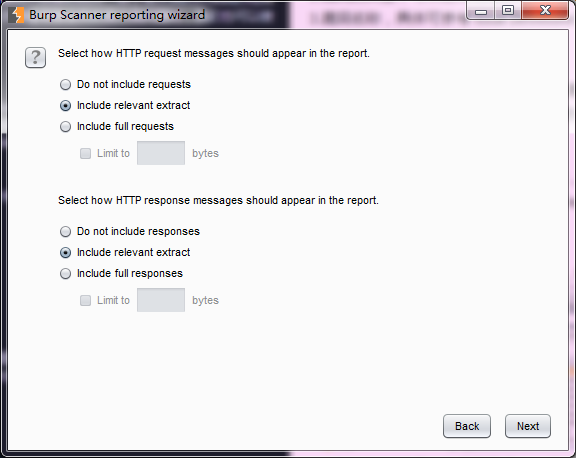
5.选择报告包含的哪些漏洞。
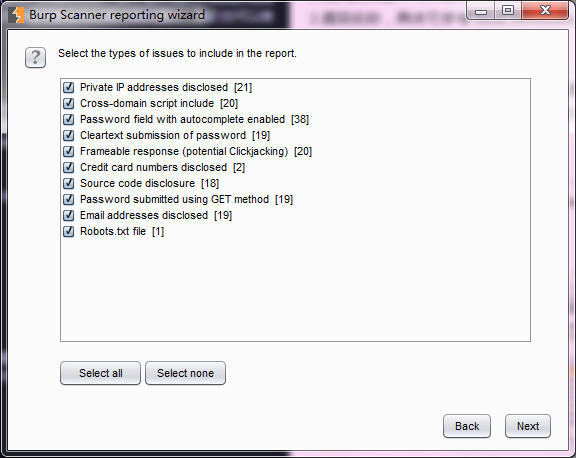
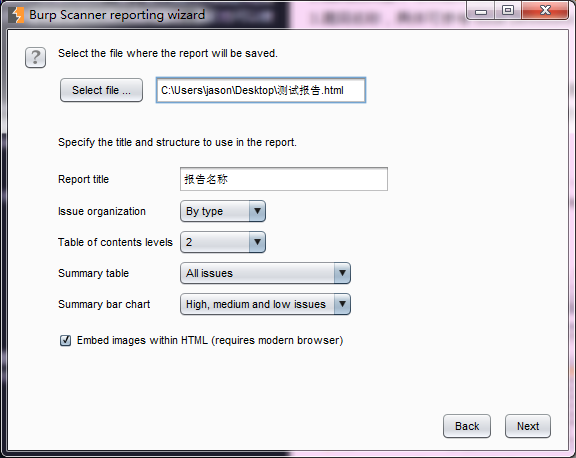
6.最后,指定报告存放位置、报告名称等属性。
Burp Scanner扫描控制
在对系统做主动扫描时,当我们激活Burp Scanner,扫描控制的相关设置也同时开始了。如下图所示,当我们在Burp Target 的站点地图上的某个URL执行Actively scan this host时,会自动弹出过滤设置。 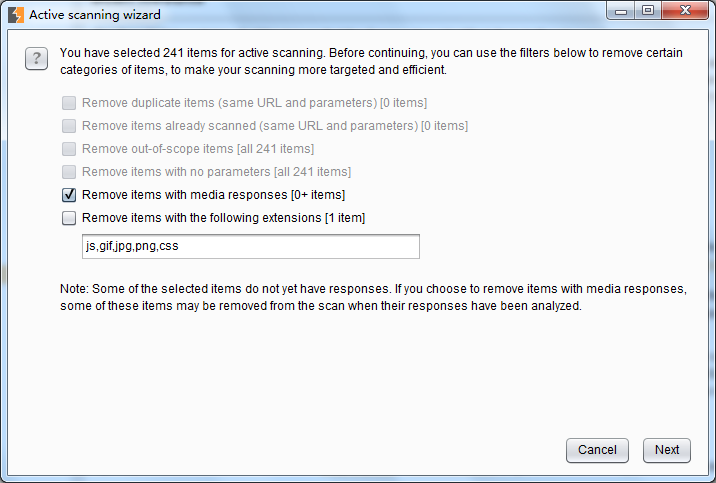
在这里,我们可以设置扫描时过滤多媒体类型的应答、过滤js、css、图片等静态资源文件。当我们点击【next】按钮,进入扫描路径分支的选择界面。如下图:
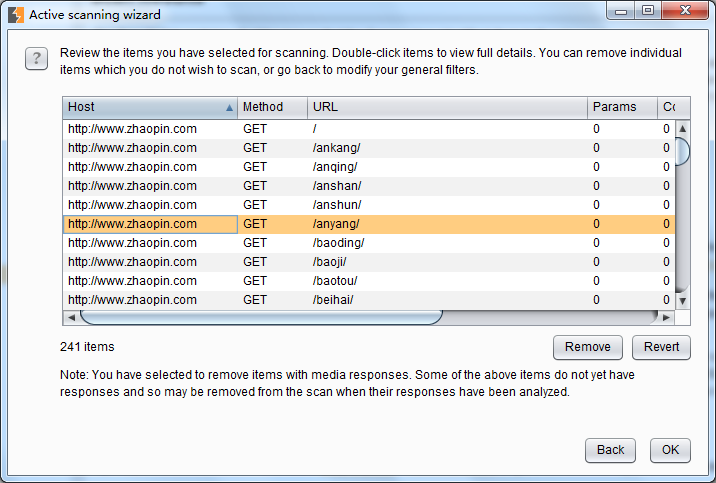
以上是Burp Scanner开始扫描前的控制,当我们设置完这些之后,将正式进入扫描阶段。此时,在Scan queue队列界面,会显示扫描的进度、问题总数、请求数和错误统计等信息。
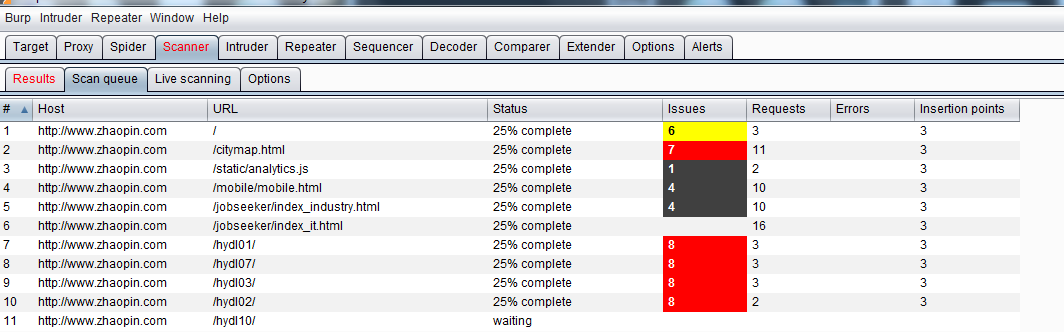
在此界面上,我们可以选中某个记录,在右击的弹出菜单中,对扫描进行控制。比如取消扫描、暂停扫描、恢复扫描、转发其他Burp组件等。如下图:

同时,在Results界面,自动显示队列中已经扫描完成的漏洞明细。
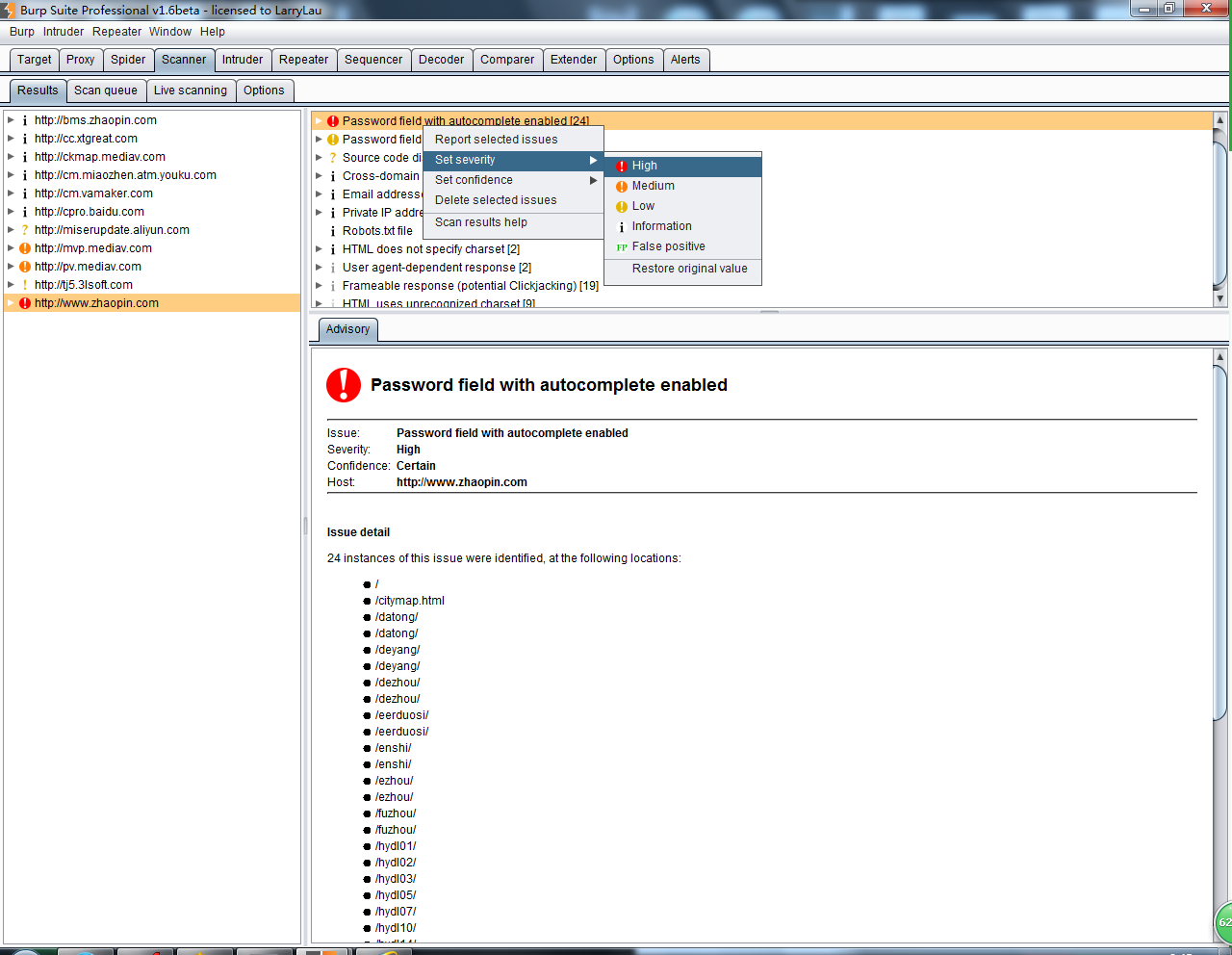
在每一个漏洞的条目上,我们可以选中漏洞。在弹出的右击菜单中,依次选择Set severity,对漏洞的等级进行标识。也可以选择Set confidence,对漏洞是否存在或误报进行标注。
另外,在Live Scanning选项卡中,我们也可以对请求的域、路径、IP地址、端口、文件类型进行控制,如下图:
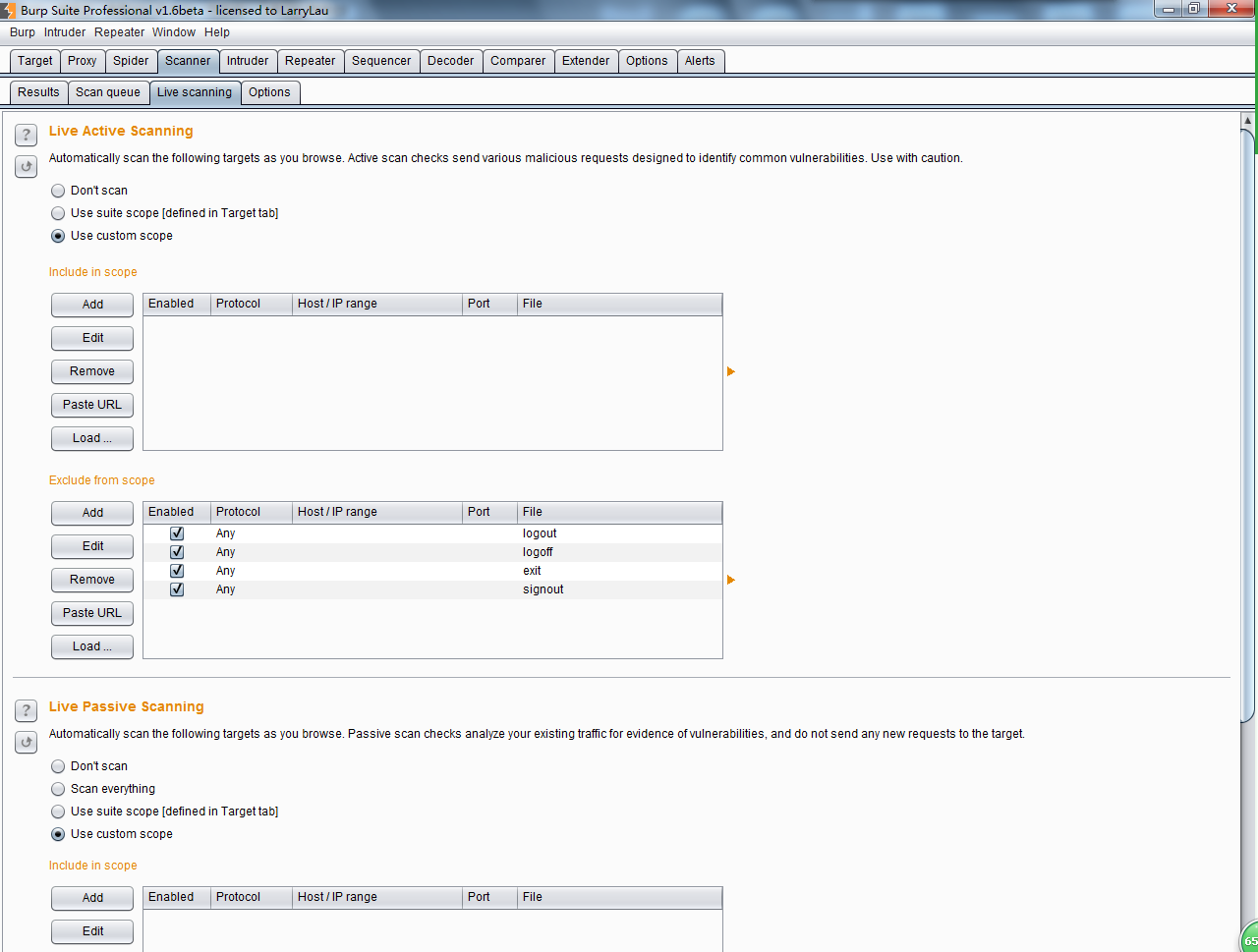
如果你选中了Use suite Scope,则指定条件与你在Burp Target中的Scope配置完全一致,如果你选择了Use customs scope,则可以自己定义Scope,对于Scope的详细配置,请参考Burp Target中的Scope配置相关章节。
Burp Scanner可选项设置
通过前几节的学习,我们已经知道Burp Scanner有主动扫描和被动扫描两个扫描方式,在Options子选项卡中,主要是针对这两种扫描方式在实际扫描中的扫描动作进行设置。具体的设置包含以下部分:
- 攻击插入点设置(Attack Insertion Points)
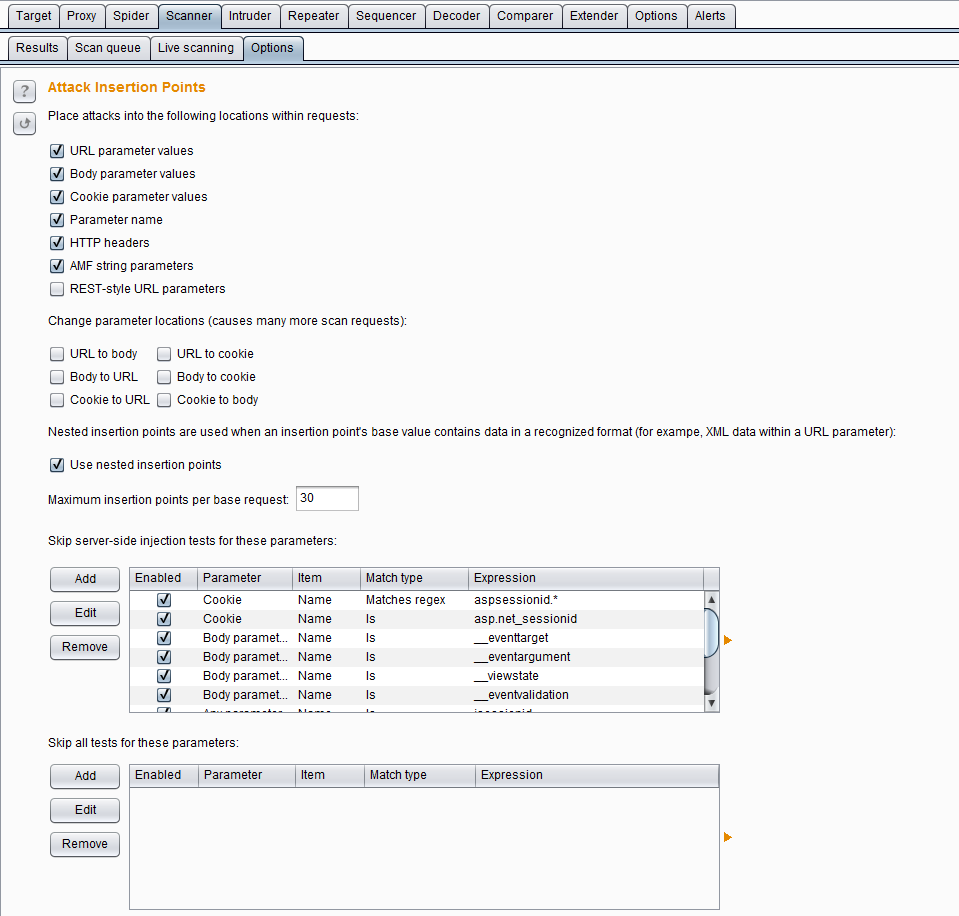
- Burp Scanner在扫描中,基于原始的请求消息,在每一个插入点构造参数,对原数据进行替换,从而去验证系统漏洞的存在性。通常,以下位置都会被Burp Scanner选择为插入点。
- URL请求参数
- Body参数(比如form表单的值,上传文件、XML参数、JSON参数)
- Cookie参数
- 参数的名称和个数(通过增加参数个数或者增加参数来验证漏洞)
- Http Header信息(通过对header信息的篡改来验证漏洞)
- AFM编码(对flash通信漏洞的验证)
- REST风格的参数
对于以上的攻击插入点,Burp Scanner还是可以通过改变参数的位置来验证漏洞,Burp Scanner中共有URL to body 、URL to cookie、Body to URL、Body to cookie、Cookie to URL、Cookie to body 六种方式。当我们在扫描验证中,可以根据实际请求,灵活选择位置改变的组合,高效快速地验证漏洞。但我们也应该明白,当我们选中了位置改变来验证漏洞,即选择了Burp发送更多的请求,如果是在生成系统中的测试需要慎重。
另外,Burp的攻击插入点也支持嵌套的方式,这意思是指,如果一个请求的参数值是JSON对象或者XML文本,Burp Scanner在扫描时,可以对JSON对象或XML文本中的属性、属性值进行验证,这会极大地提高了Burp Scanner对漏洞扫描的涉及面。这是由上图中的use nested insertion points的checkbox是否选中去控制的,默认情况下是选中生效的。
当我们设置攻击插入点的同时,我们也可以指定哪些参数进行跳过,不需要进行漏洞验证。在设置时,Burp是按照服务器端参数跳过和所有参数均跳过两种方式来管理的,界面如下图: 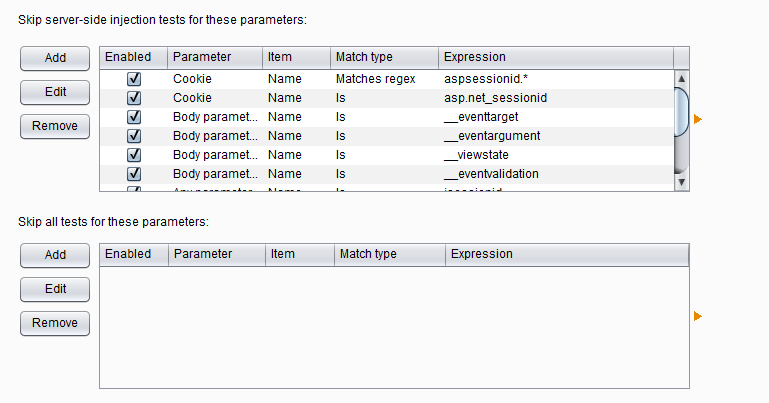
2 主动扫描引擎设置(Active Scanning Engine)
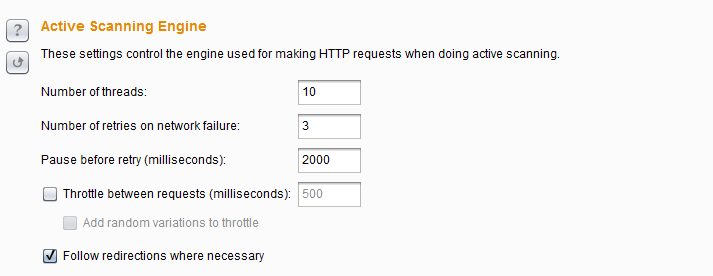
主动扫描引擎设置主要是用来控制主动扫描时的线程并发数、网络失败重试间隔、网络失败重试次数、请求延迟、是否跟踪重定向。其中请求延迟设置(Throttle between requests)和其子选项延迟随机数 (Add random variations to throttle)在减少应用负荷,模拟人工测试,使得扫描更加隐蔽,而不易被网络安全设备检测出来。 至于这些参数的具体设置,需要你根据服务器主机的性能、网络带宽、客户端测试机的性能做相应的调整。一般来说,如果您发现该扫描运行缓慢,但应用程序表现良好,你自己的CPU利用率较低,可以增加线程数,使您的扫描进行得更快。如果您发现发生连接错误,应用程序正在放缓,或你自己的电脑很卡,你应该减少线程数,加大对网络故障的重试次数和重试之间的间隔。
3.主动扫描优化设置(Active Scanning Optimization)

此选项的设置主要是为了优化扫描的速度和准确率,尽量地提高扫描速度的同时降低漏洞的误报率。 扫描速度(Scan speed)分快速、普通、彻底三个选项,不同的选项对应于不同的扫描策略,当选择彻底扫描(Thorough)时,Burp会发送更多的请求,对漏洞的衍生类型会做更多的推导和验证。而当你选择快速扫描(Fast),Burp则只会做一般性的、简单的漏洞验证。 扫描精准度(Scan accuracy)也同样分为三个选项:最小化假阴性(Minimize false negatives)、普通、最小化假阳性(Minimize false positives)。扫描精准度主要是用来控制Burp的扫描过程中针对漏洞的测试次数。当我们选择最小化假阳性时,Burp会做更多的验证测试,来防止假阳性漏洞的存在,但也是恰恰基于此,当Burp做更多的验证测试时,可能存在恰好无法获取应答的误报,增加了漏洞的噪音。 智能攻击选择(Use intelligent attack selection )这个选项通过智能地忽略一些攻击插入点基值的检查,比如说一个参数值包含不正常出现在文件名中的字符,Burp将跳过文件路径遍历检查此参数,使用此选项可加速扫描,并降低在提升扫描速度的同时会导致漏报率上升的风险。
4.主动扫描范围设置(Active Scanning Areas)
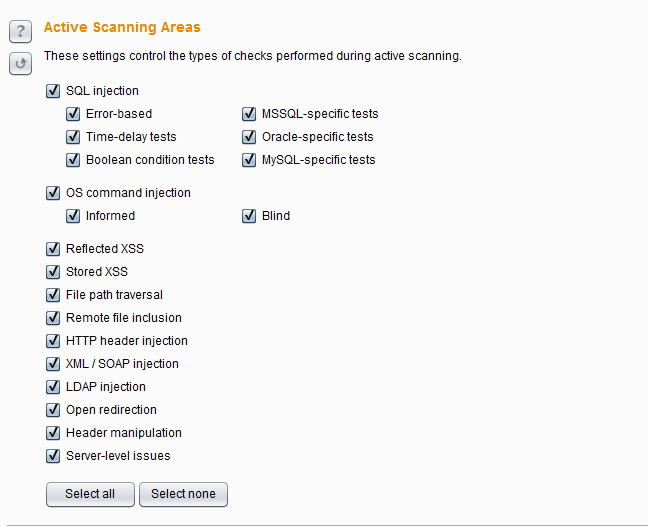
在主动扫描过程中,你可以根据你的扫描时间、关注的重点、可能性存在的漏洞类型等情况,选择不同的扫描范围。这里可选择的扫描范围有:
- SQL注入 -可以使不同的测试技术(基于误差,时间延迟测试和布尔条件测试),并且也使检查所特有的单独的数据库类型(MSSQL,Oracle和MySQL的)。
- 操作系统命令注入 - (信息通知和盲注)。
- 反射式跨站点脚本
- 存储的跨站点脚本
- 文件路径遍历
- HTTP头注入
- XML/ SOAP注入
- LDAP注入
- URL重定向
- http消息头可操纵
- 服务器的问题
5.被动扫描范围设置(Passive Scanning Areas)
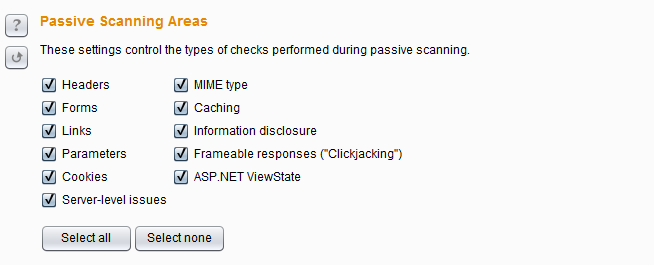
因为被动扫描不会发送新的请求,只会对原有数据进行分析,其扫描范围主要是请求和应答消息中的如下参数或漏洞类型:Headers、Forms、Links、Parameters、Cookies、MIME type、Caching、敏感信息泄露、Frame框架点击劫持、ASP.NET ViewState 。
第八章 如何使用Burp Intruder
Burp Intruder作为Burp Suite中一款功能极其强大的自动化测试工具,通常被系统安全渗透测试人员被使用在各种任务测试的场景中。本章我们主要学习的内容有:
- Intruder使用场景和操作步骤
- Payload类型与处理
- Payload 位置和攻击类型
- 可选项设置(Options)
- Intruder 攻击和结果分析
Intruder使用场景和操作步骤
在渗透测试过程中,我们经常使用Burp Intruder,它的工作原理是:Intruder在原始请求数据的基础上,通过修改各种请求参数,以获取不同的请求应答。每一次请求中,Intruder通常会携带一个或多个有效攻击载荷(Payload),在不同的位置进行攻击重放,通过应答数据的比对分析来获得需要的特征数据。Burp Intruder通常被使用在以下场景:
- 标识符枚举 Web应用程序经常使用标识符来引用用户、账户、资产等数据信息。例如,用户名,文件ID和账户号码。
- 提取有用的数据 在某些场景下,而不是简单地识别有效标识符,你需要通过简单标识符提取一些其他的数据。比如说,你想通过用户的个人空间id,获取所有用户在个人空间标准的昵称和年龄。
- 模糊测试 很多输入型的漏洞,如SQL注入,跨站点脚本和文件路径遍历可以通过请求参数提交各种测试字符串,并分析错误消息和其他异常情况,来对应用程序进行检测。由于的应用程序的大小和复杂性,手动执行这个测试是一个耗时且繁琐的过程。这样的场景,您可以设置Payload,通过Burp Intruder自动化地对Web应用程序进行模糊测试。
通常来说,使用Burp Intruder进行测试,主要遵循以下步骤:
- 确认Burp Suite安装正确并正常启动,且完成了浏览器的代理设置。
- 进入Burp Proxy选项卡,关闭代理拦截功能。
- 进行历史日志(History)子选项卡,查找可能存在问题的请求日志,并通过右击菜单,发送到Intruder。

- 进行Intruder 选项卡,打开Target和Positions子选项卡。这时,你会看到上一步发送过来的请求消息。
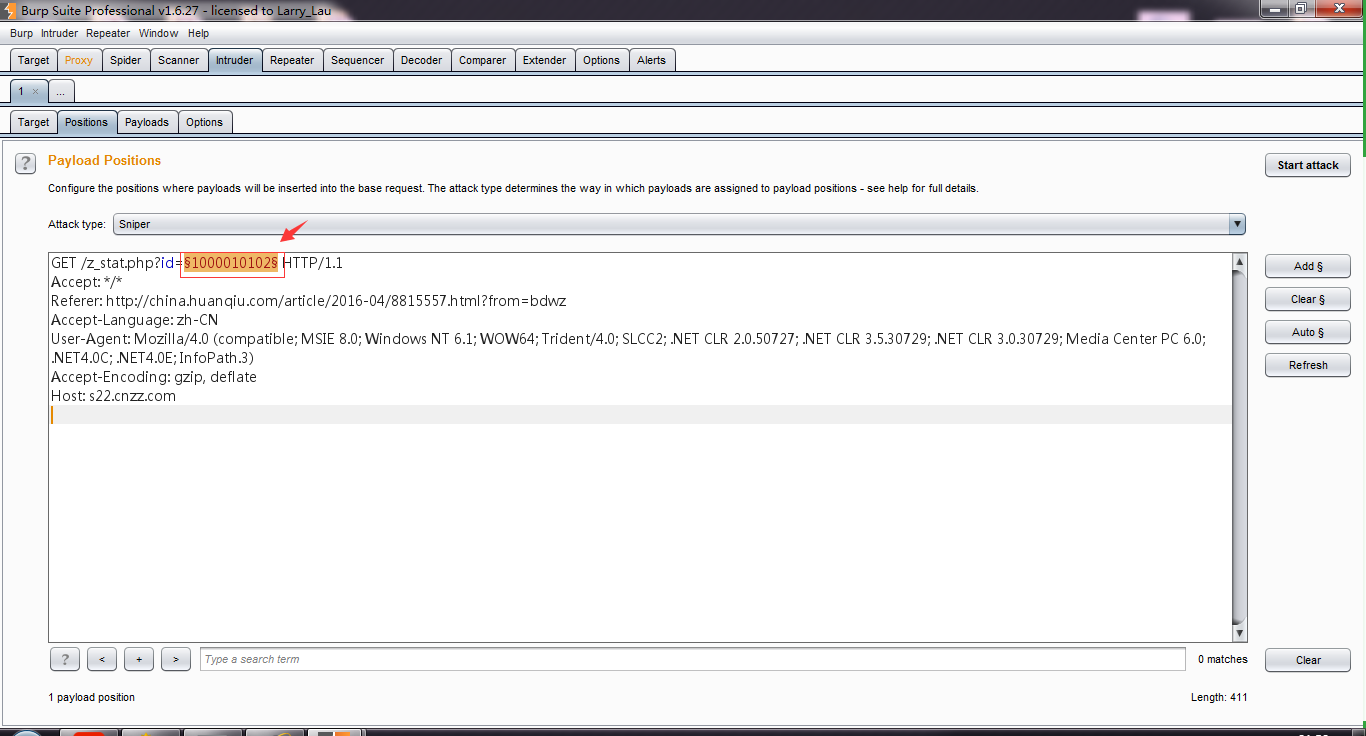
- 因为我们了解到Burp Intruder攻击的基础是围绕刚刚发送过来的原始请求信息,在原始信息指定的位置上设置一定数量的攻击载荷Payload,通过Payload来发送请求获取应答消息。默认情况下,Burp Intruder会对请求参数和Cookie参数设置成Payload position,前缀添加 $符合,如上图红色标注位置所示。当发送请求时,会将$标识的参数替换为Payload。
- 在Position界面的右边,有【Add $】、【Clear $】、【Auto $】、【Refersh $】四个按钮,是用来控制请求消息中的参数在发送过程中是否被Payload替换,如果不想被替换,则选择此参数,点击【Clear $】,即将参数前缀$去掉。
- 当我们打开Payload 子选项卡,选择Payload的生成或者选择策略,默认情况下选择“Simple list",当然你也可以通过下拉选择其他Payload类型或者手工添加。
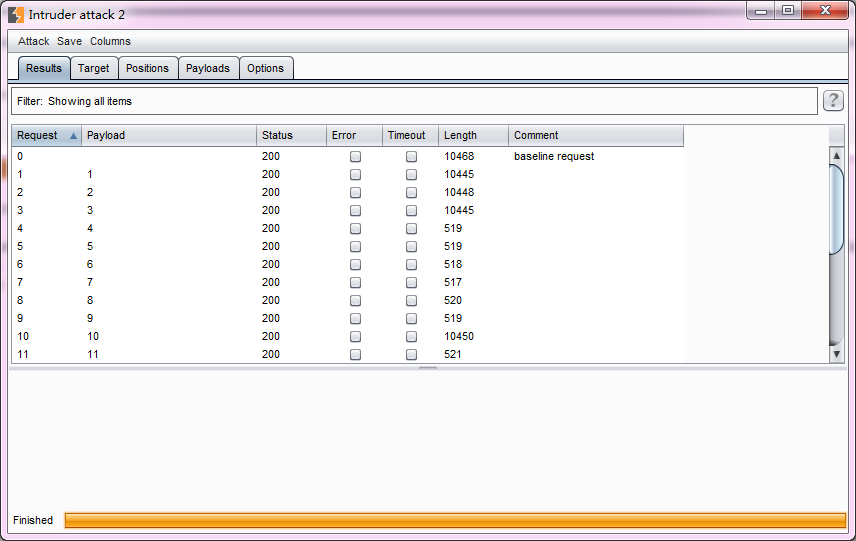
- 此时,我们再回到Position界面,在界面的右上角,点击【Start attack】,发起攻击。

- 此时,Burp会自动打开一个新的界面,包含攻击执行的情况、Http状态码、长度等结果信息。
- 我们可以选择其中的某一次通信信息,查看请求消息和应答消息的详细。
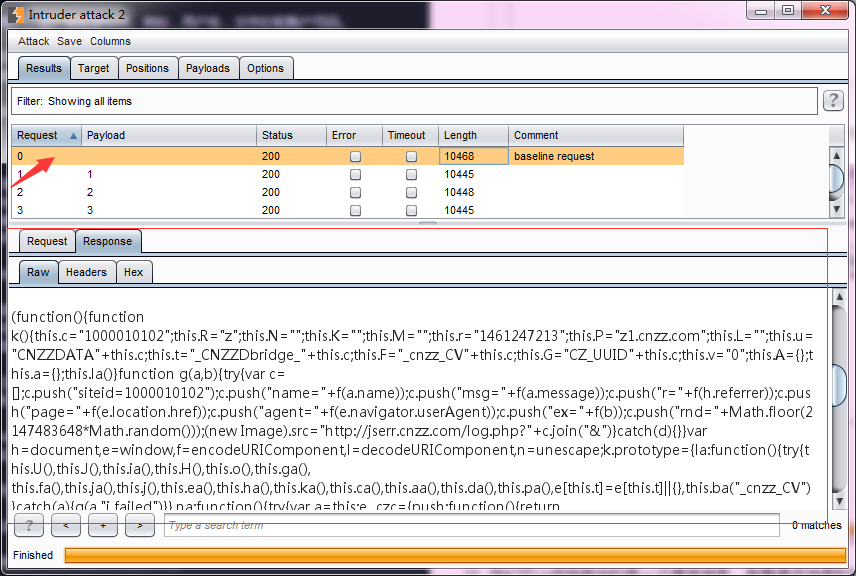
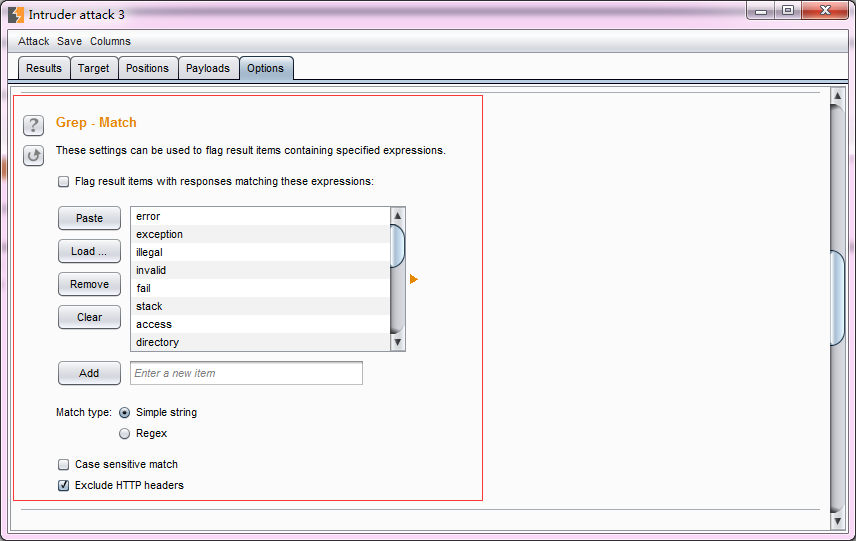
- 很多时候,为了更好的标明应答消息中是否包含有我们需要的信息,通常在进行攻击前,会进行Options选项的相关配置,使用最多的为正则表达式匹配(Grep - Match)。
- 或者,我们使用结果选项卡中的过滤器,对结果信息进行筛选。

- 同时,结果选项卡中所展示的列我们是可以进行指定的,我们可以在菜单Columns进行设置。

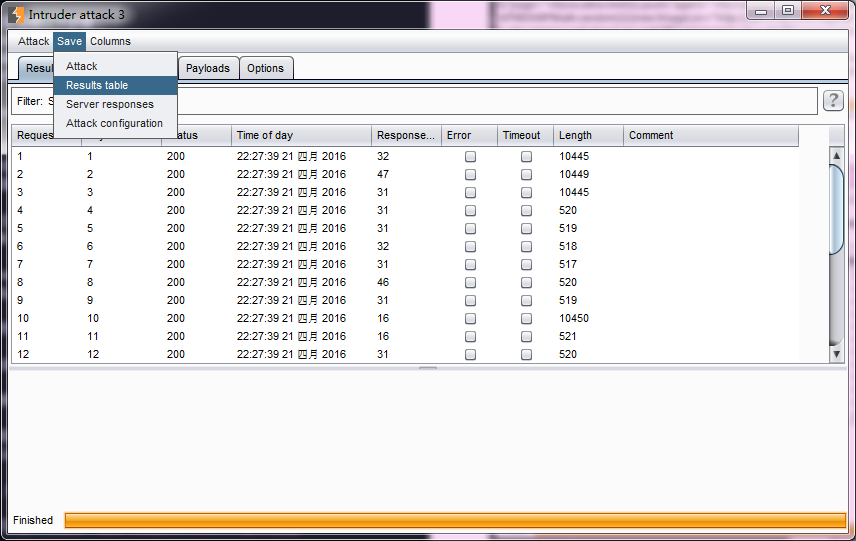
- 最后,选择我们需要的列,点击【Save】按钮,对攻击结果进行保存。
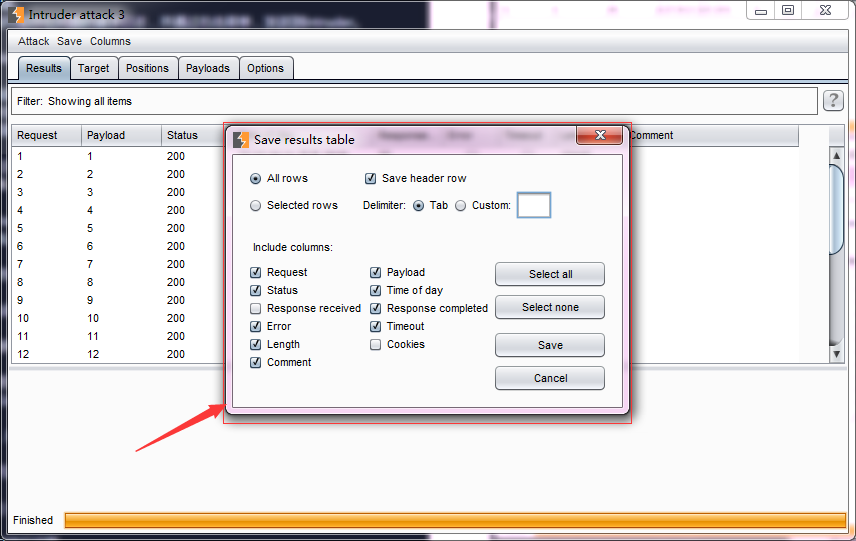
- 当然,保存之前我们也可以对保存的内容进行设置。
以上这些,是Burp Intruder一次完成的操作步骤,在实际使用中,根据每一个人的使用习惯,会存在或多或少的变动。而每一个环节中涉及的更详细的配置,将在接下来的章节中做更细致的阐述。
Payload类型与处理
在Burp Intruder的Payload选项卡中,有Payload集合的设置选项,包含了经常使用的Payload类型,共18种。 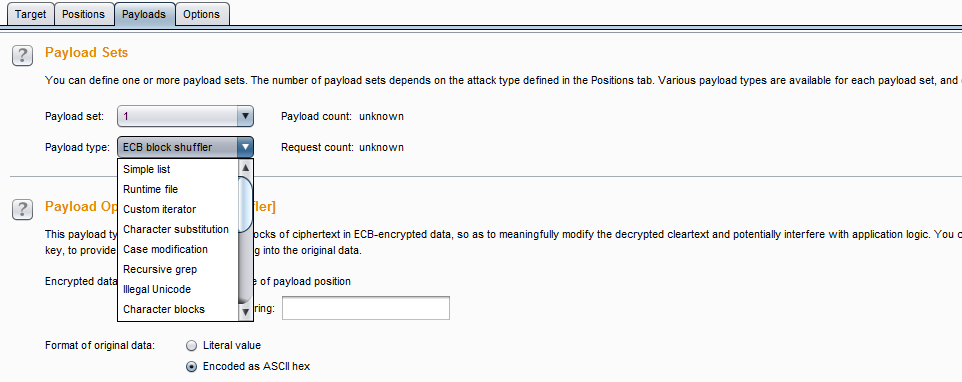
他们分别是:
- 简单列表(Simple list) ——最简单的Payload类型,通过配置一个字符串列表作为Payload,也可以手工添加字符串列表或从文件加载字符串列表。其设置界面如下图
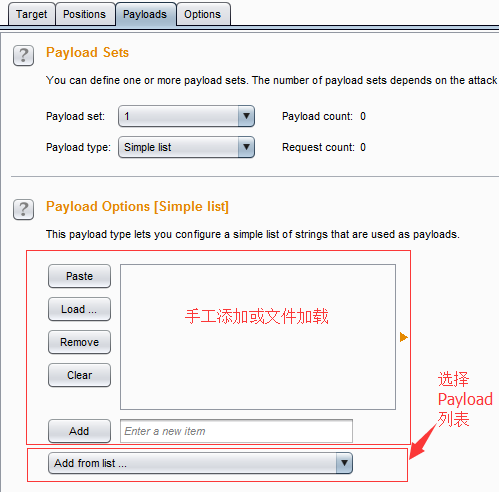
- 在此操作界面上,选择的Payload列表中,已经预定义了一组简单Payload列表,包括XSS脚本、CGI脚本、SQL注入脚本、数字、大写字母、小写字母、用户名、密码、表单域的字段名、IIS文件名和目录名等等,极大地方便了渗透测试人员的使用。
- 运行时文件(Runtime file) ——指定文件,作为相对应Payload位置上的Payload列表。其设置界面如下图:
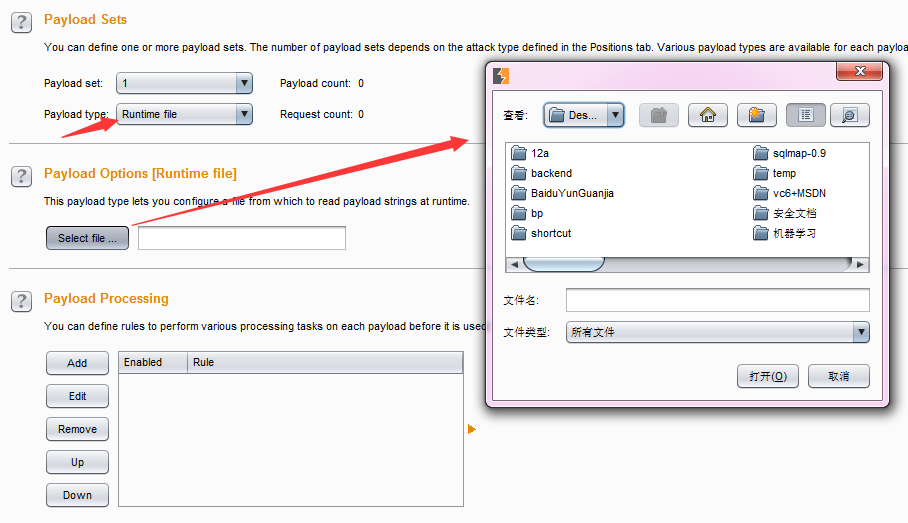
- 当我们如上图所示,指定Payload set的位置1使用的Payload类型为Runtime file时,下方的Payload Options将自动改变为文件选择按钮和输入框,当我们点击【select file】选择文件时,将弹出图中所示的对话框,选择指定的Payload文件。运行时,Burp Intruder将读取文件的每一行作为一个Payload。
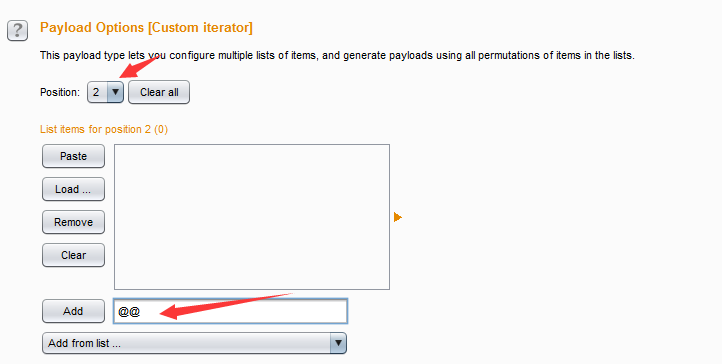
- 自定义迭代器(Custom iterator)——这是一款功能强大的Payload,它共有8个占位,每一个占位可以指定简单列表的Payload类型,然后根据占位的多少,与每一个简单列表的Payload进行笛卡尔积,生成最终的Payload列表。例如,某个参数的值格式是username@@password,则设置此Payload的步骤是:位置1,选择Usernames
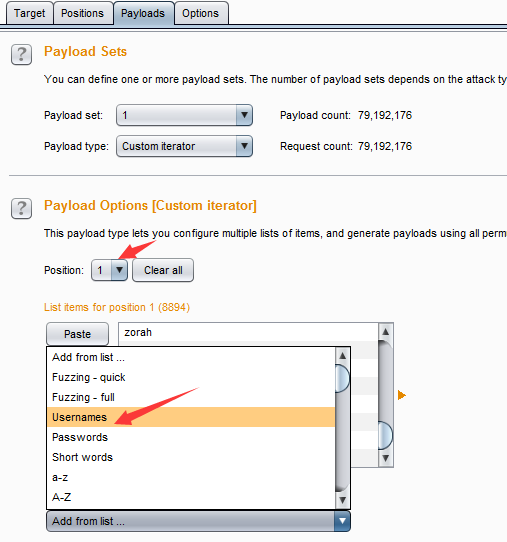
- 接着,指定位置2,输入值@@
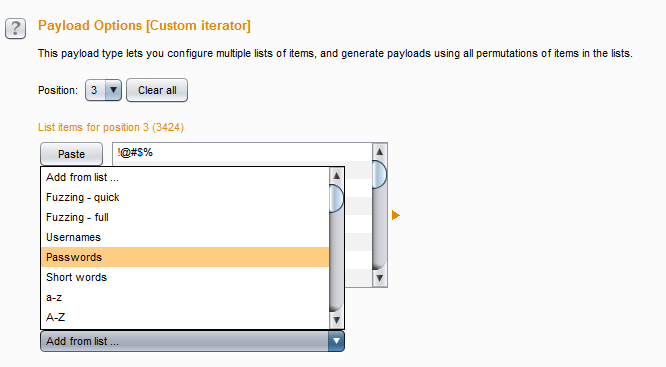
- 最后指定位置3,选择Passwords
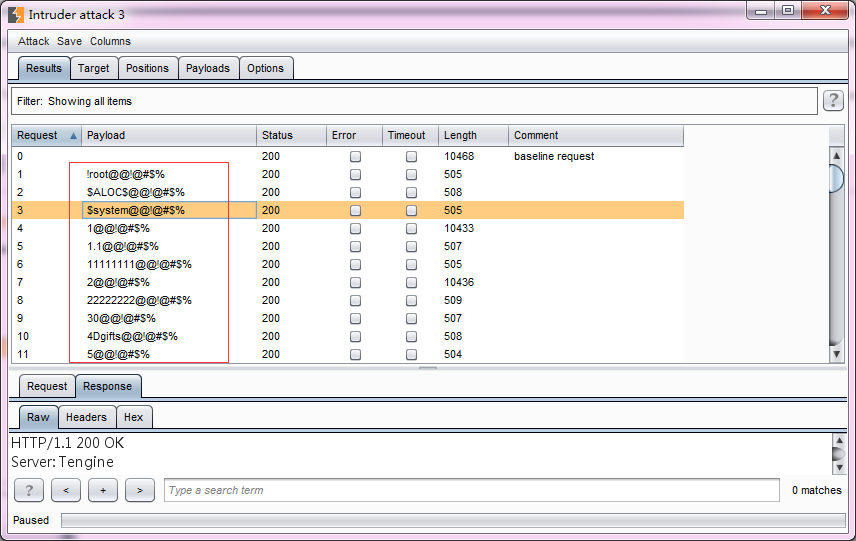
- 当我们开始攻击时,生成的Payload值如图所示
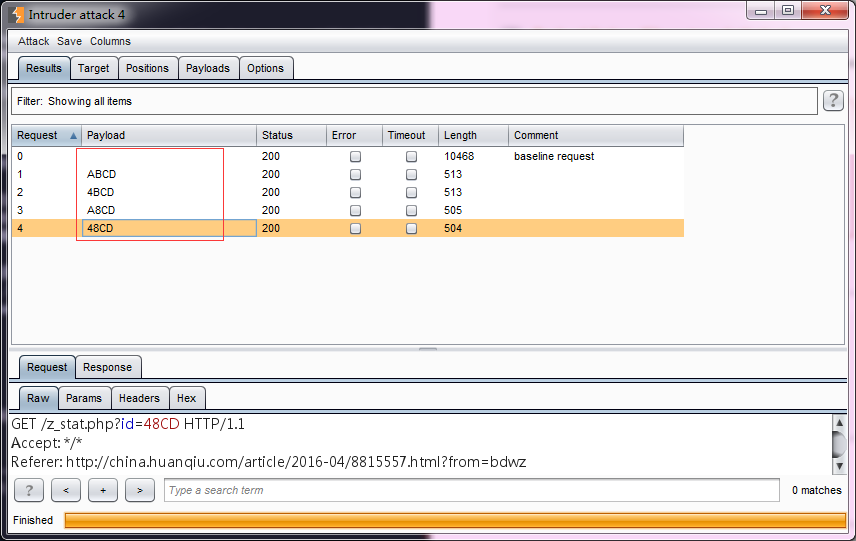
- 字符串替换(Character substitution)——顾名思义,此种Payload的类型是对预定义的字符串进行替换后生成新的Payload。比如说,预定义字符串为ABCD,按照下图的替换规则设置后,将对AB的值进行枚举后生成新的Payload。

- 生成的Payload如下图所示,分别替换了上图中的a和b的值为4与8
- 大小写替换(Case modification)——对预定义的字符串,按照大小写规则,进行替换。比如说,预定义的字符串为Peter Wiener,则按照下图的设置后,会生成新的Payload。
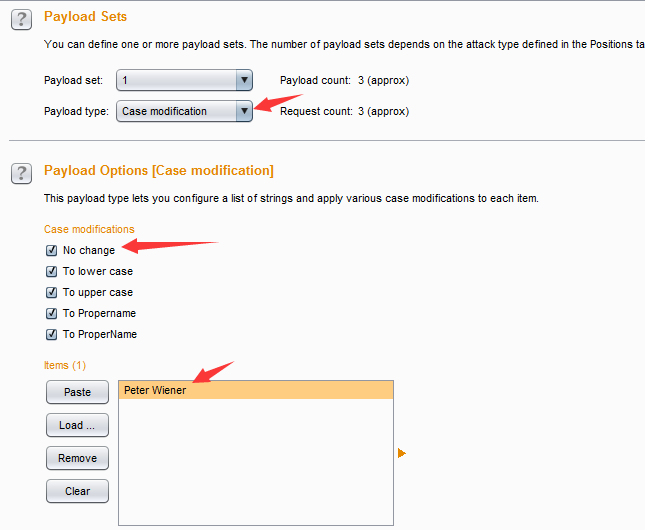
- 生成的Payload如下
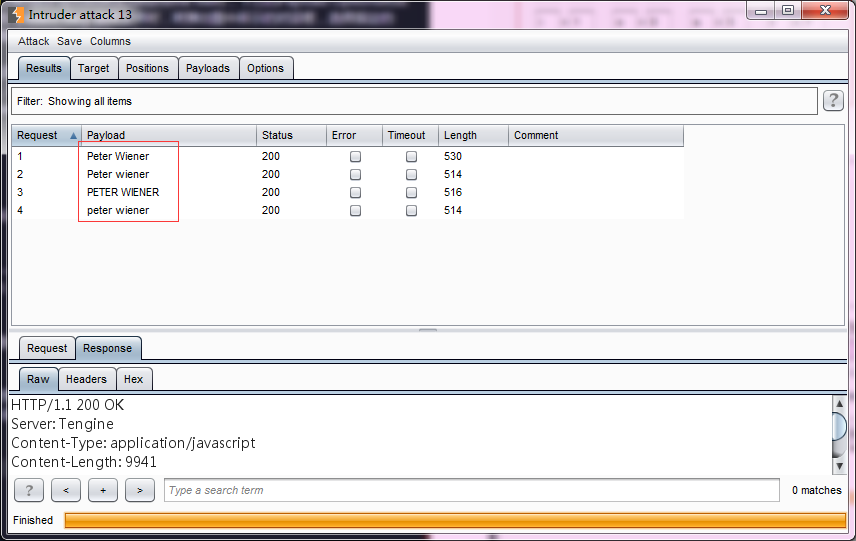
- 生成规则由上而下依次是:No change(不改变,使用原始字符串)、To lower case(转为小写字母)、To upper case(转为大写字母)、To Propername(首字母大写,其他小写)、To ProperName(首字母大写,其他不改变),在实际使用中,可以根据自己的使用规则进行勾选设置。
- 递归grep (Recursive grep)——此Payload类型主要使用于从服务器端提取有效数据的场景,需要先从服务器的响应中提取数据作为Payload,然后替换Payload的位置,进行攻击。它的数据来源了原始的响应消息,基于原始响应,在Payload的可选项设置(Options)中配置Grep规则,然后根据grep去提取数据才能发生攻击。比如,我在 grep extract 中设置取服务器端的EagleId作为新的Payload值。
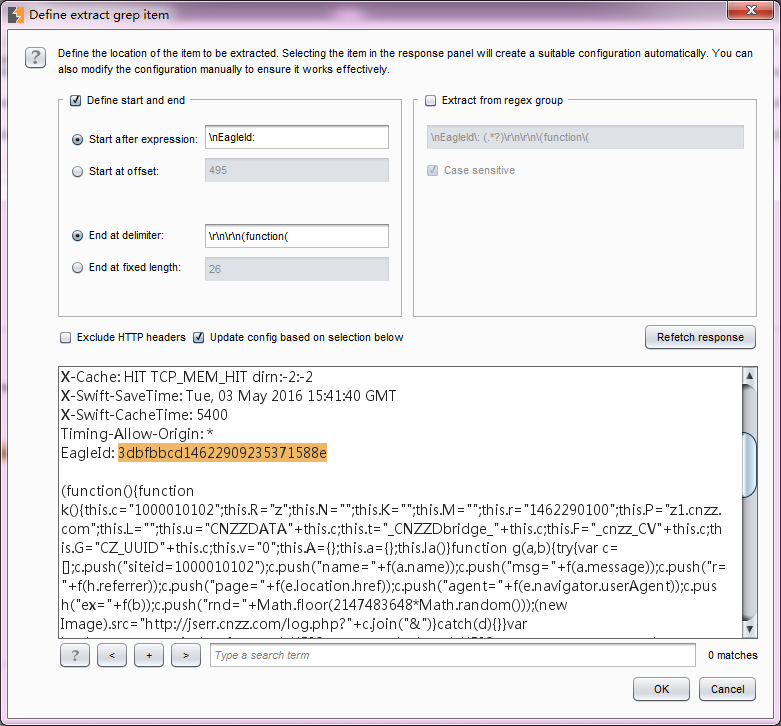
- 点击上图的【OK】按钮之后,完成了Payload的设置。
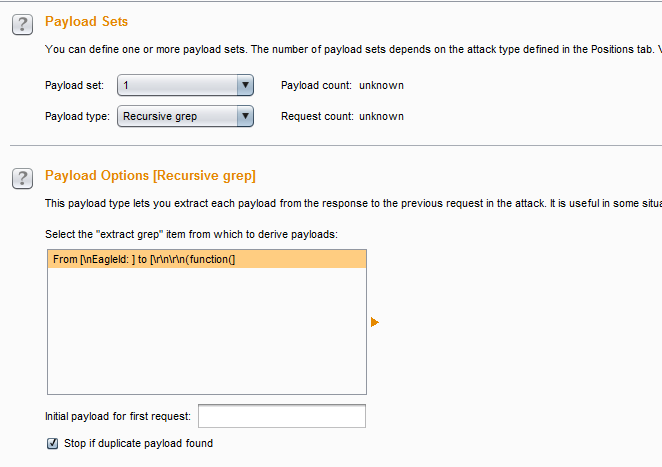
- 当我发起攻击时,Burp会对每一次响应的消息进行分析,如果提取到了EagleId的值,则作为Payload再发生一次请求。操作图如下:
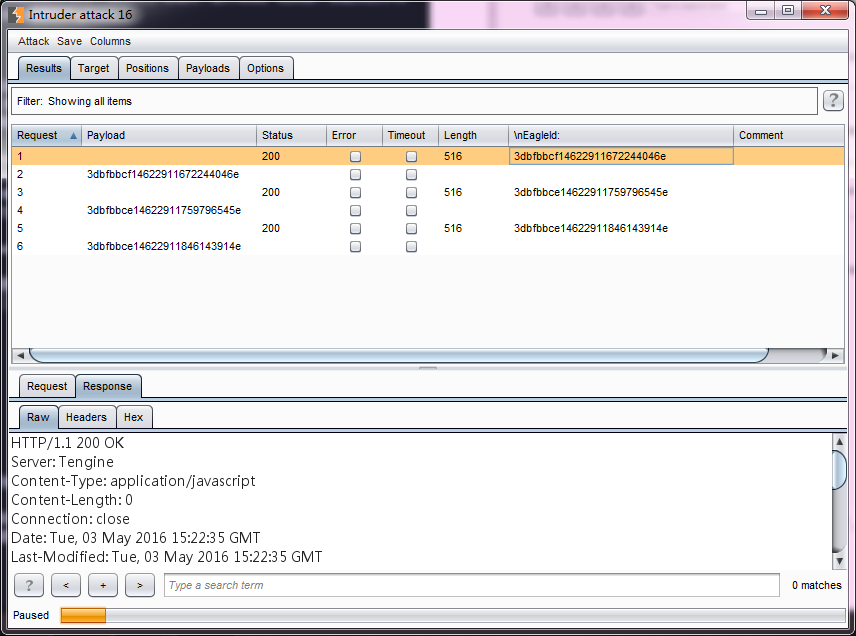
- 上图中请求序号为偶数的消息的Payload都是上一次服务器端响应的报文中的EagleId的值。
- 不合法的Unicode编码(Illegal Unicode)—— 在payloads里用指定的不合法Unicode 编码替换字符本身,从这些Payload列表里产生出一个或者多个有效负荷。在尝试回避基于模式匹配的输入验证时,这个有效负荷会有用的,例如,在防御目录遍历攻击时../和..序列的期望编码的匹配。其配置界面如下:
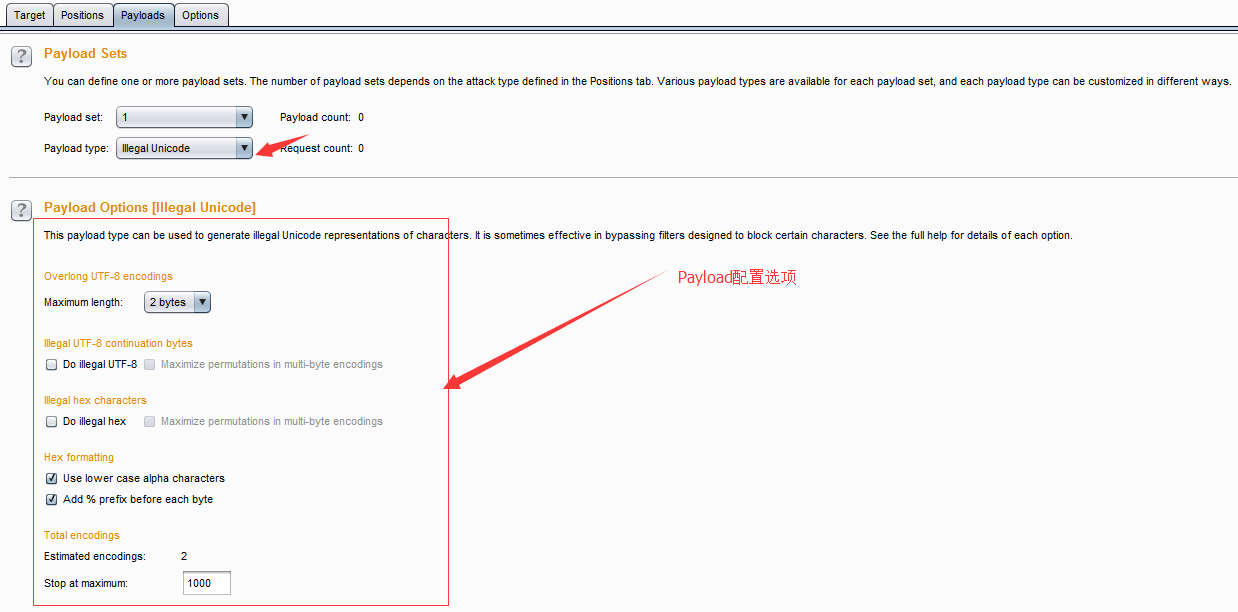
- 上图中的配置选项主要用来控制不合法编码的生成,各项的含义如下: maximum overlong UTF-8 lengthUnicode 编码允许最多使用 6 字节表示一个字符。使用一种类型就可以正确地表示出(0x00-0x7F) Basic ASCII 字符。然而,使用多字节的Unicode 方案也能表示出它们(如, ”overlong”编码)。下拉菜单用来指定是否使用超长编码,以及应该设定的最大使用长度。 Illegal UTF-8 continuation bytes当选择的最大超长 UTF-8 长度为 2 字节以上,这个选项是可用的。 Do illegal UTF-8 当使用多字节编码一个字符时,第一个字节后面的字节应该用 10XXXXXX 这样的二进制格式,来指出后续的字节。然而,第一个字节里最有意义的位会指出后面还有多少后续字节。因此,Unicode 编码例程会安全地忽略掉后续字节的前 2 位。这就意味着每个后续字节可能有 3 个非法变种,格式为 00XXXXXX, 01XXXXXX 和 11XXXXXX。如果选中这个选项,则非法 Unicode 有效负荷源会为每个后续字节生成 3 个附加编码。Maximize permutations in multi-byte encodings 如果选择的最大超长 UTF-8 长度为 3 字节以上,并且选中” illegal UTF-8 ”这个选项可用。如果”Maximize permutations in multi-byte encodings”没被选中,则在生产非法变种时,不合法 Unicode 有效负荷源会按顺序处理每个后续字节,为每个后续字节产生 3 个非法变种,并且其他的后续字节不会改变。如果”Maximize permutations in multi-byte encodings”被选中了,不合法 的Unicode 有效负荷源会为后续字节生成所有的非法变种排序 。 如,多个后续字节会同时被修改。在目标系统上回避高级模式匹配控制时,这个功能就会很有用。 Illegal hex这个选择基本上一直可用。当使用超长编码和后续字节的非法变种(如果选中)生成非法编码项列表时,通过修改由此产生的十六进制编码可能会迷惑到某种模式匹配控制。十六进制编码使用字符 A—F 代表十进制 10—15 的值。然而有些十六进制编码会把G解释为 16, H 为 17,等等。因此 0x1G 会被解释为 32。另外,如果非法的十六进制字符使用在一个 2 位数的十六进制编码的第一个位置,则由此产生的编码就会溢出单个字节的大小,并且有些十六进制编码只使用了结果数字的后 8 个有效位,因此 0x1G 会被解码为 257,而那时会被解释为 1。每个合法的 2 位数的十六进制编码有 4—6 种相关的非法十六进制表示,如果使用的是上面的编码,则这些表示会被解释为同一种十六进制编码。如果”illegal hex”被选中,则非法 Unicode 有效负荷源会在非法编码项列表里,生成每个字节的所有可能的非法十六进制编码。 Maximize permutations in multi-byte encodings 如果选中的最大超长 UTF-8 长度为 2 字节以上并且“illegal hex”也被选中,则这个选项可用。如果Maximize permutations in multi-byte encodings”没被选中,在生成非法十六进制编码时,非法 Unicode 有效负荷源会按顺序处理每个字节。对于每个字节,会生成 4—6 个非法十六进制编码,其他的字节不变。如果Maximize permutations in multi-byte encodings”被选中,则非法 Unicode 有效负荷源会为所有的字节,生成非法十六进制的所有排序。如,多个字节会被同时修改。在目标系统上回避高级模式匹配控制时,这个功能会非常有用。 add % prefix如果选中这个选项,在产生的有效负荷里的每个 2 位数十六进制编码前面,都会插入一个%符号。 Use lower case alpha characters 这个选项决定了是否在十六进制编码里使用大小写字母。 Total encodings这个选项为会产生的非法编码数量放置了一个上界,如果大量使用超长编码或者选中了最大列表,这个选项会很有用,因为那会生成大量的非法编码。 Match / replace in list items 这个选项用户控制Payload列表中的字符串,它是由匹配字符(Match character)和替换字符编码(Replace with encodings of )来成对的控制Payload的生成。当攻击执行时,这个有效负荷源会迭代所有预设项列表,在非法编码集合里,每个预设 项替换每个项里的指定字符的所有实例。
- 字符块(Character blocks)——这种类型的Payload是指使用一个给出的输入字符串,根据指定的设置产生指定大小的字符块,表现形式为生成指定长度的字符串。它通常使用了边界测试或缓冲区溢出。
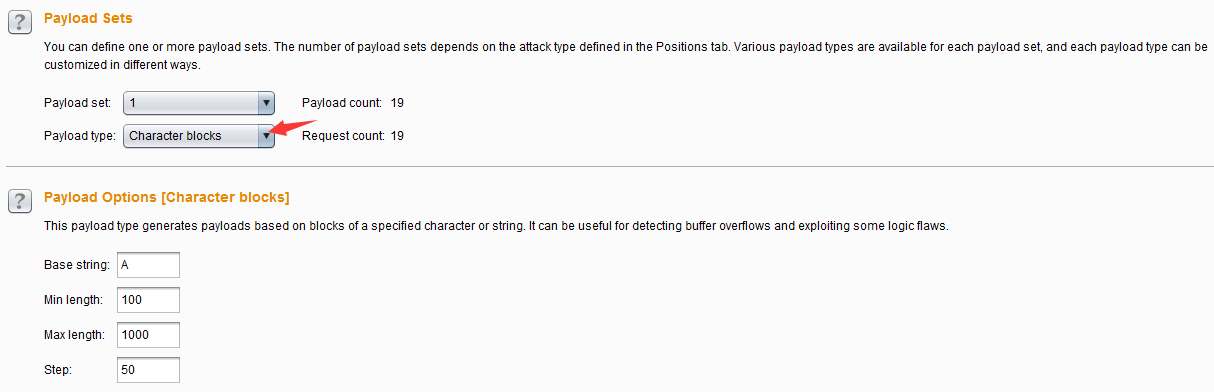
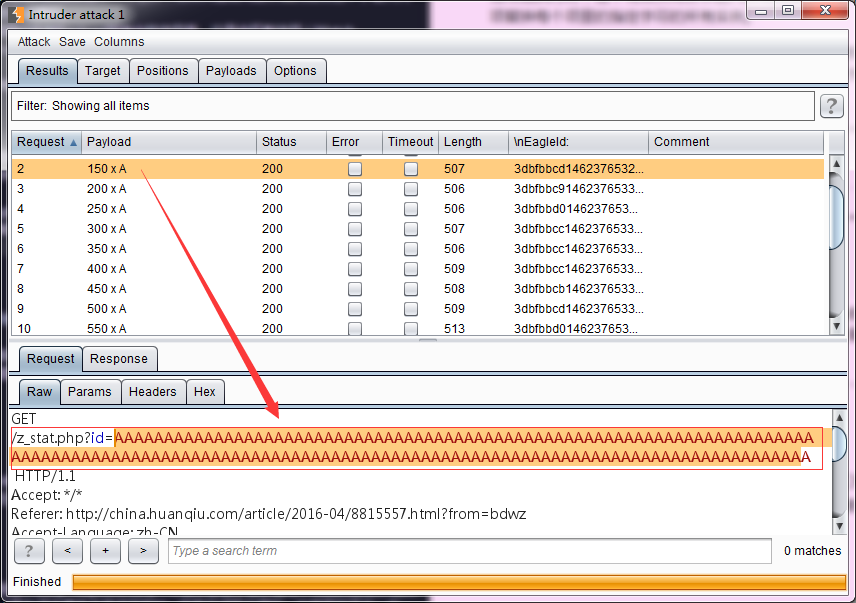
- Base string 是指设置原始字符串,Min length是指Payload的最小长度,Max length 是指Payload的最大长度,Step是指生成Payload时的步长。如上图的配置后,生成的Payload如下图所示:
- 数字类型(Number)——这种类型的Payload是指根据配置,生成一系列的数字作为Payload。它的设置界面如下:

- Type表示使用序列还是随机数,From表示从什么数字开始,To表示到什么数字截止,Step表示步长是多少,如果是随机数,则How many被激活,表示一共生成多少个随机数。Base表示数字使用十进制还是十六进制形式,Min integer digits 表示最小的整数是多少,Max integer digits表示最大的整数是多少,如果是10进制,则Min fraction digits 表示小数点后最少几位数,Max fraction digits表示小数点后最多几位数。
- 日期类型(Dates)——这种类型的Payload是指根据配置,生成一系列的日期。界面如下
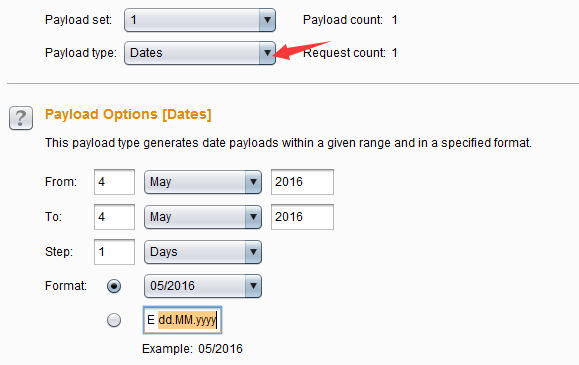
- 其设置选项比较简单,没有什么特别复杂的,不再赘述。至于日期格式,可以选择Burp自己提供的样例格式,也可以自定义,自定义的时候,格式的填写形式如下表所示 | 格式 | 样例| |--------|--------| | E | Sat | | EEEE | Saturday | | d | 7 | | dd | 07 | | M | 6 | | MM | 06 | | MMM | Jun | | MMMM| June | | yy| 16 | | yyyy| 2016 |
- 暴力字典(Brute forcer)——此类Payload生成包含一个指定的字符集的所有排列特定长度的有效载荷,通常用于枚举字典的生成,其设置界面如下:
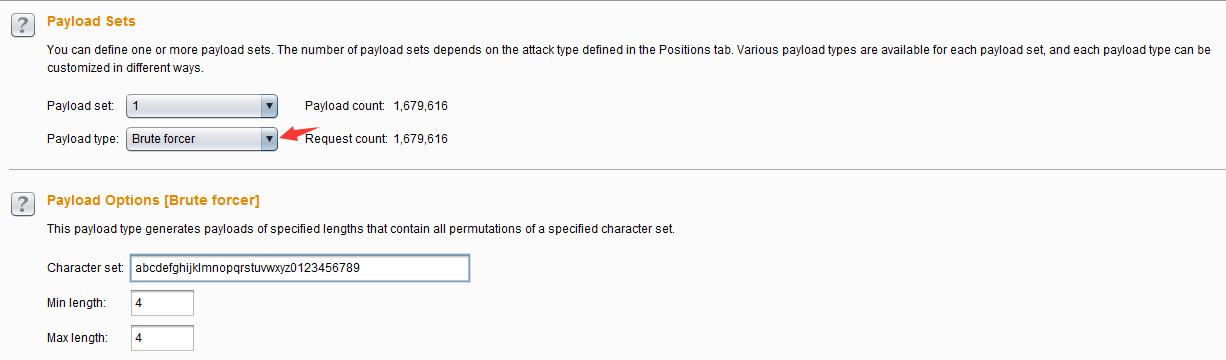
- Character set 表示生成字典的数据集,从此数据集中抽取字符进行生成。Min length表示生成Payload的最小长度,Max length表示生成Payload的最大长度。
- 空类型(Null payloads)——这种负载类型产生的Payload,其值是一个空字符串。在攻击时,需要同样的请求反复被执行,在没有任何修改原始请求的场景下此Payload是非常有用的。它可用于各种攻击,例如cookie的序列分析、应用层Dos、或保活会话令牌是在其它的间歇试验中使用。
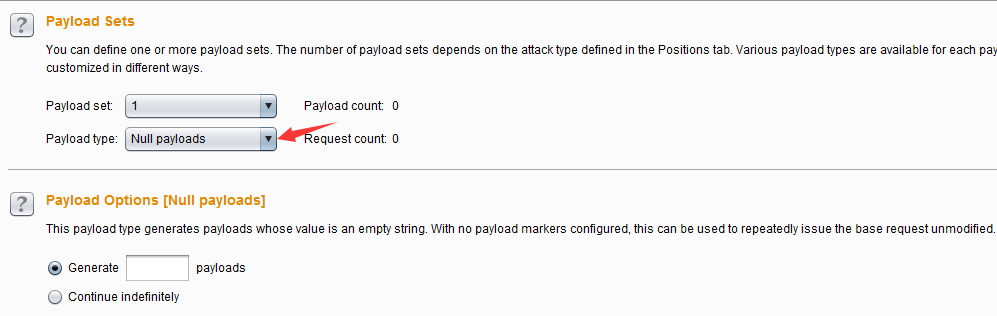
- 在配置Payload生成方式时,它有两个选项,我们可以指定生成(Generate)多少Payload,也可以设置为一直持续攻击(Continue indefinitely)
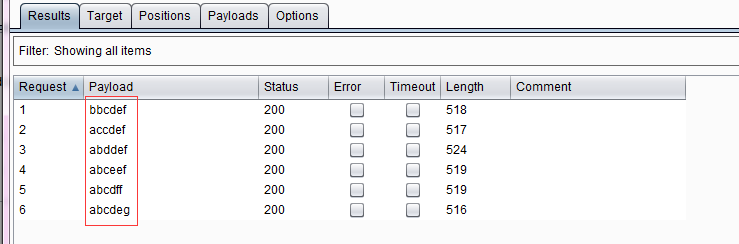
- 字符frobber(Character frobber)——这种类型的Payload的生成规律是:依次修改指定字符串在每个字符位置的值,每次都是在原字符上递增一个该字符的ASCII码。它通常使用于测试系统使用了复杂的会话令牌的部件来跟踪会话状态,当修改会话令牌中的单个字符的值之后,您的会话还是进行了处理,那么很可能是这个令牌实际上没有被用来追踪您的会话。其配置界面如图:
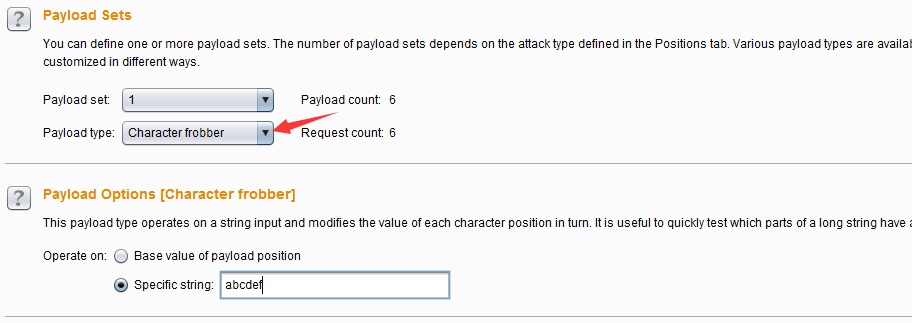
- 执行后生成的Payload如下图所示:
- Bit翻转(Bit flipper)——这种类型的Payload的生成规律是:对预设的Payload原始值,按照比特位,依次进行修改。它的设置界面如下图:

- 其设置选项主要有:Operate on 指定是对Payload位置的原始数据进行Bit翻转还是指定值进行Bit翻转,Format of original data 是指是否对原始数据的文本意义进行操作,还是应该把它当作ASCII十六进制,Select bits to flip是指选择翻转的Bit位置。 您可以配置基于文本意义进行操作,或基于ASCII十六进制字符串进行翻转。例如,如果原始值是“ab”,基于文本意义的翻转结果是:
`b cb eb ib qb Ab !b ¡b ac a` af aj ar aB a" a¢如果是基于ASCII十六进制字符串进行翻转,则结果是:
aa a9 af a3 bb 8b eb 2b这种类型的Payload类似于字符frobber,但在你需要更细粒度的控制时是有用的。例如,会话令牌或其他参数值使用CBC模式的块密码加密,有可能系统地由前一密码块内修改Bit位以改变解密后的数据。在这种情况下,你可以使用的Bit 翻转的Payload来确定加密值内部修改了个别bit位后是否对应用程序产生影响,并了解应用程序是否容易受到攻击。关于加密模式可以点击阅读这篇文章做进一步的了解。
- 用户名生成器(Username generator)这种类型的Payload主要用于用户名和email帐号的自动生成,其设置界面如下图:
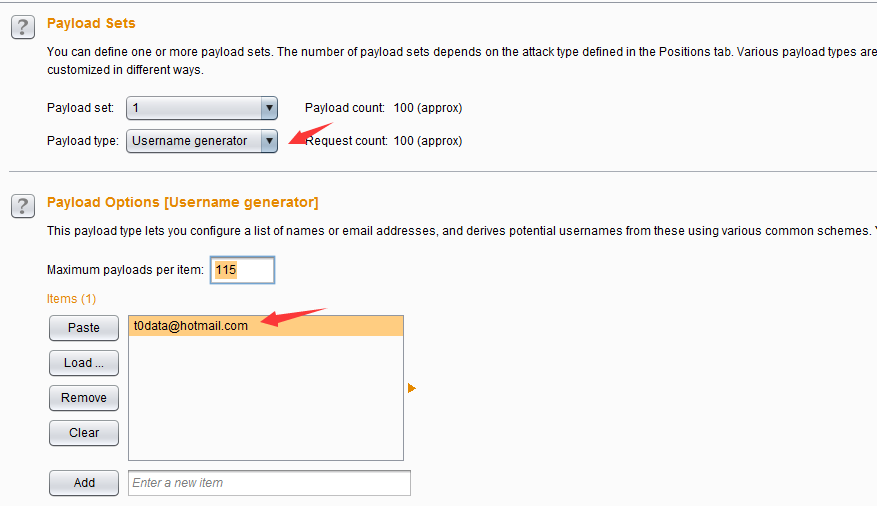
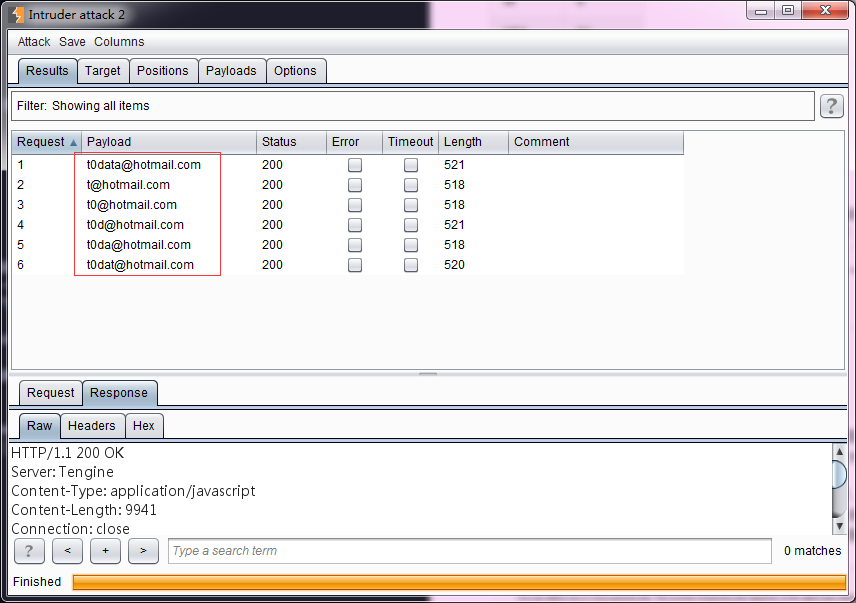
- 如上图所示,我设置了原始值为t0data@hotmail.com,然后执行此Payload生成器,其生成的Payload值如图所示
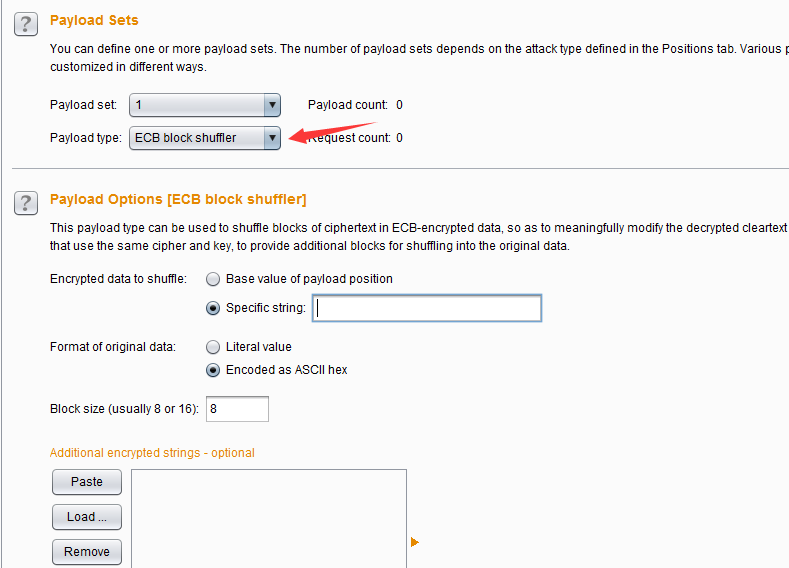
- ECB 加密块洗牌(ECB block shuffler)——这种类型的Payload是基于ECB加密模式的Payload生成器,关于加密模式可以点击阅读这篇文章做进一步的了解。其原理是因为ECB加密模式中每组64位的数据之间相互独立,通过改变分组数据的位置方式来验证应用程序是否易受到攻击。其设置界面如下图,Payload的配置参数同上一个Payload类型雷同,就不再赘述。如图:
- Burp Payload生成插件(Extension-generated)——这种类型的Payload是基于Burp插件来生成Payload值,因此使用前必须安装配置Burp插件,在插件里注册一个Intruder payload生成器,供此处调用。其基本设置和使用步骤如下图所示,因后续章节将重点叙述Burp插件,此处不再展开。

- Payload复制(Copy other payload)——这种类型的Payload是将其他位置的参数复制到Payload位置上,作为新的Payload值,通常适用于多个参数的请求消息中,它的使用场景可能是: 1.两个不同的参数需要使用相同的值,比如说,用户注册时,密码设置会输入两遍,其值也完全一样,可以使用此Payload类型。 2.在一次请求中,一个参数的值是基于另一个参数的值在前端通过脚本来生成的值,可以使用此Payload类型。 它的设置界面和参数比较简单,如下图所示,其中Payload位置的索引值就是指向图中Payload set的值。
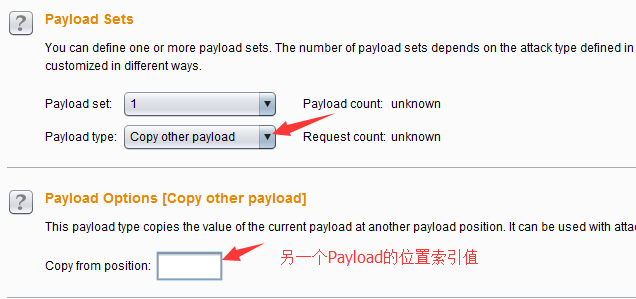
Payload位置和攻击类型
首先我们来看看Payload位置(Payload positions)选项卡的设置界面: 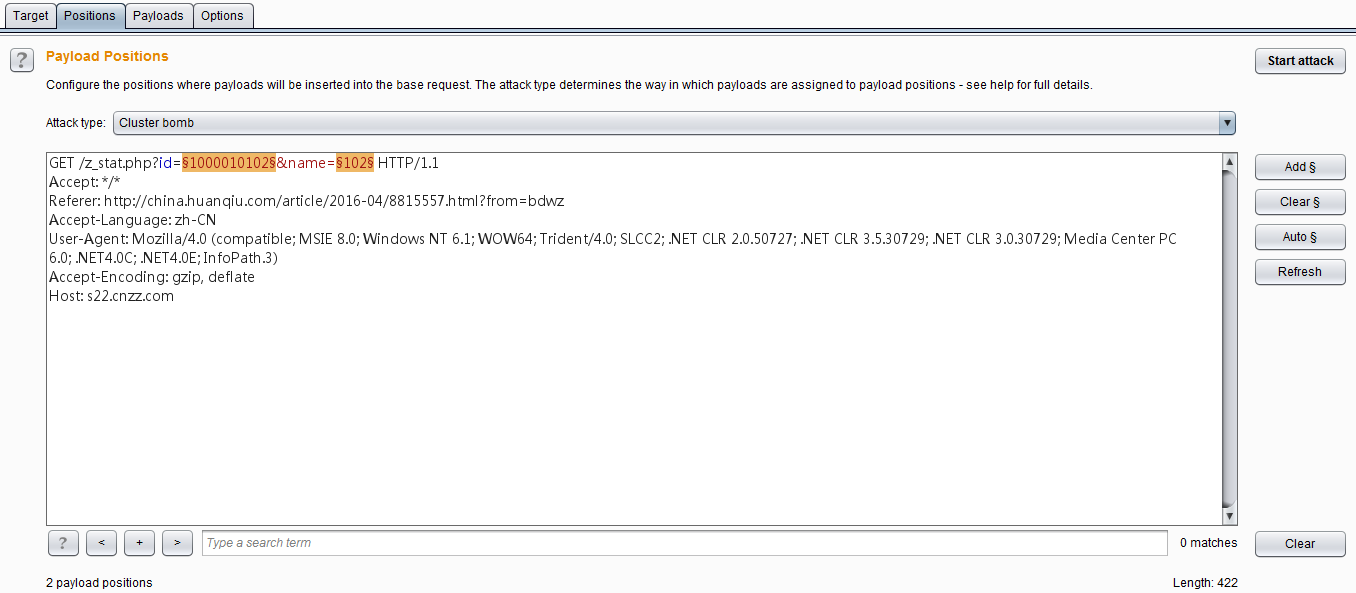
从上图中我们可以看出,Payload位置的设置是基于Http请求的原始消息作为母板,使用一对 §字符来标记出Payload的位置,在这两个号直接包含了母板文本内容。 当我们已经把一个Payload在请求消息的特殊位置上时标明后,发起攻击时,Burp Intruder 就把一个Payload值放置到给出的特殊位置上,替换 §符号标示的整个位置。如上图中的参数id后面的 §符号之间的标明的是Payload位置1,name后面的 §符号之间标明的是Payload位置2,这个值对应于Payload设置中的Payload set的值。 我们可以在消息编辑器中间对Payload位置进行编辑,它主要是由右侧的四个按钮来控制的。
- 【Add §】——在当前光标的位置添加一个Payload位置标志
- 【Clear §】——清除所有Payload位置标志或者清除选中的Payload位置标志
- 【Auto §】——对消息内容中可能需要标志的参数做一个猜测,标志为Payload位置,自动设置完之后再做人工的选择,确定哪些位置是需要传入Payload的。目前Burp支持自动选择的参数类型有: 1.URL请求参数 2.Body参数 3.cookie参数 4.复合型参数属性,比如文件上传时候的文件名 5.XML数据 6.JSON数据 虽然Burp默认是支持自动标志这些类型的参数作为Payload位置,但如果是针对于像XML或JSON的节点属性值的,还是需要手工指定。
- 【Refresh】——刷新消息内容中带有颜色的部分。
- 【Clear】——清除消息编辑器中所有内容。
在消息编辑器的上方,有一个下拉选择框,攻击类型(Attack Type)。Burp Intruder支持使用Payload进行多种方式的模拟攻击,目前只要有以下4种。
- 狙击手模式(Sniper)——它使用一组Payload集合,依次替换Payload位置上(一次攻击只能使用一个Payload位置)被§标志的文本(而没有被§标志的文本将不受影响),对服务器端进行请求,通常用于测试请求参数是否存在漏洞。
- 攻城锤模式(Battering ram)——它使用单一的Payload集合,依次替换Payload位置上被§标志的文本(而没有被§标志的文本将不受影响),对服务器端进行请求,与狙击手模式的区别在于,如果有多个参数且都为Payload位置标志时,使用的Payload值是相同的,而狙击手模式只能使用一个Payload位置标志。
- 草叉模式(Pitchfork )——它可以使用多组Payload集合,在每一个不同的Payload标志位置上(最多20个),遍历所有的Payload。举例来说,如果有两个Payload标志位置,第一个Payload值为A和B,第二个Payload值为C和D,则发起攻击时,将共发起两次攻击,第一次使用的Payload分别为A和C,第二次使用的Payload分别为B和D。
- 集束炸弹模式(Cluster bomb) 它可以使用多组Payload集合,在每一个不同的Payload标志位置上(最多20个),依次遍历所有的Payload。它与草叉模式的主要区别在于,执行的Payload数据Payload组的乘积。举例来说,如果有两个Payload标志位置,第一个Payload值为A和B,第二个Payload值为C和D,则发起攻击时,将共发起四次攻击,第一次使用的Payload分别为A和C,第二次使用的Payload分别为A和D,第三次使用的Payload分别为B和C,第四次使用的Payload分别为B和D。
可选项设置(Options)
可选项设置主要包括请求消息头设置、请求引擎设置、攻击结果设置、grep match, grep extract, grep payloads,以及重定向设置。在使用中,你可以在攻击前进行设置,也可以在攻击过程中做这些选项的调整。
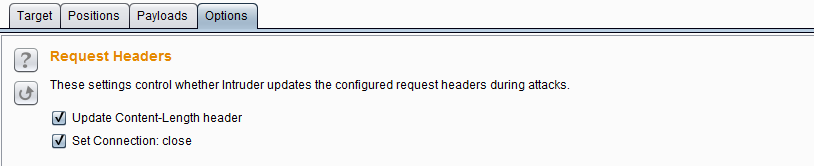
- 请求消息头设置(Request Headers)——这个设置主要用来控制请求消息的头部信息,它由Update Content-Length header和Set Connection: close两个选项组成。其中Update Content-Length header如果被选中,Burp Intruder在每个请求添加或更新Content-Length头为该次请求的HTTP体的长度正确的值。这个功能通常是为插入可变长度的Payload到模板的HTTP请求的主体的攻击中,如果没有指定正确的值,则目标服务器可能会返回一个错误,可能会到一个不完整的请求做出响应,或者可能会无限期地等待请求继续接收数据。Set Connection: close如果被选中,表示Burp Intruder在每个请求消息中添加或更新值为“关闭”的连接头,这将更迅速地执行。在某些情况下(当服务器本身并不返回一个有效的Content-Length或Transfer-Encoding头),选中此选项可能允许攻击。
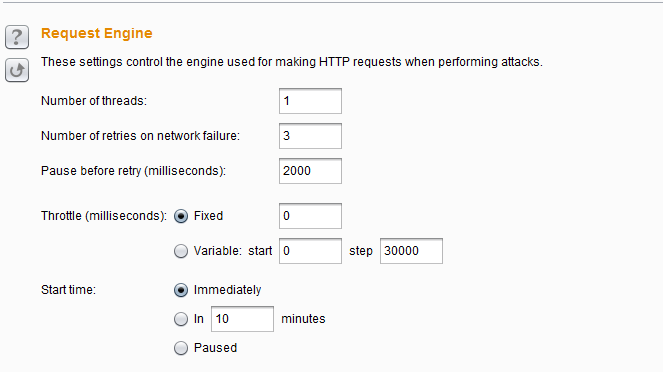
- 请求引擎设置(Request Engine)——这个设置主要用来控制Burp Intruder攻击,合理地使用这些参数能更加有效地完成攻击过程。它有如下参数:Number of threads并发的线程数,Number of retries on network failure 网络失败时候重试次数,Pause before retry重试前的暂停时间间隔(毫秒),Throttle between requests 请求延时(毫秒),Start time开始时间,启动攻击之后多久才开始执行。
- 攻击结果设置(Attack Results)——这个设置主要用来控制从攻击结果中抓取哪些信息。它的参数有:Store requests / responses 保存请求/应答消息,Make unmodified baseline request 记录请求母板的消息内容,Use denial-of-service mode使用Dos方式,tore full payloads存储所有的Payload值。

- Grep Match——这个设置主要用来从响应消息中提取结果项,如果匹配,则在攻击结果中添加的新列中标明,便于排序和数据提取。比如说,在密码猜测攻击,扫描诸如“密码不正确”或“登录成功”,可以找到成功的登录;在测试SQL注入漏洞,扫描包含“ODBC”,“错误”等消息可以识别脆弱的参数。
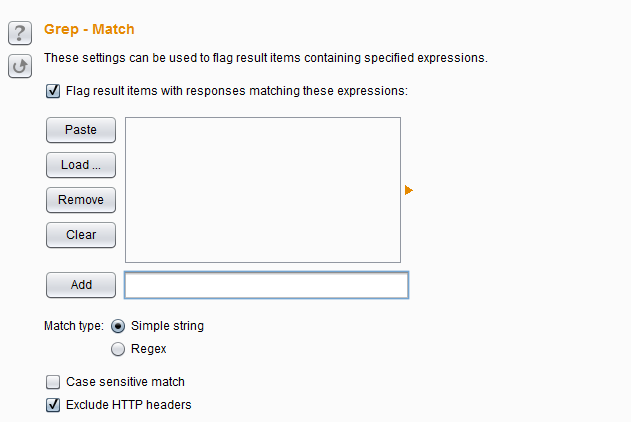
- 其选项有Match type表示匹配表达式还是简单的字符串,Case sensitive match是否大小写敏感,Exclude HTTP headers匹配的时候,是否包含http消息头。
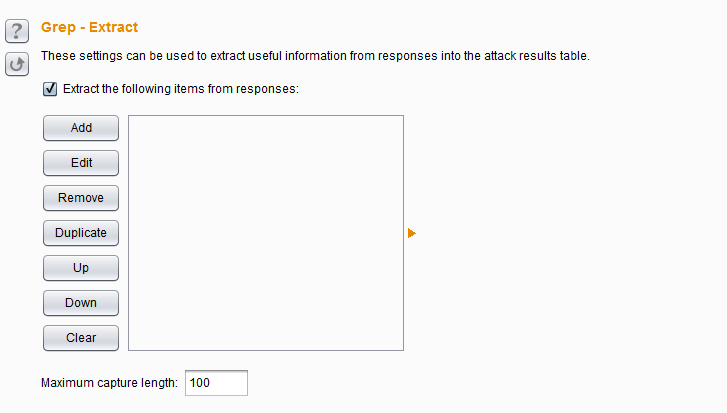
- Grep Extract——这些设置可用于提取响应消息中的有用信息。对于列表中配置的每个项目,Burp会增加包含提取该项目的文本的新结果列。然后,您可以排序此列(通过单击列标题)命令所提取的数据。此选项是从应用数据挖掘有用的,能够支持广泛的攻击。例如,如果你是通过一系列文档ID的循环,可以提取每个文档寻找有趣的项目的页面标题。如果您发现返回的其他应用程序用户详细信息的功能,可以通过用户ID重复和检索有关用户寻找管理帐户,甚至密码。如果“遗忘密码”的功能需要一个用户名作为参数,并返回一个用户配置的密码提示,您可以通过共同的用户名列表运行和收获的所有相关密码的提示,然后直观地浏览列表寻找容易被猜到密码。
- Grep Payloads——这些设置可用于提取响应消息中是否包含Payload的值,比如说,你想验证反射性的XSS脚本是否成功,可以通过此设置此项。当此项设置后,会在响应的结果列表中,根据Payload组的数目,添加新的列,显示匹配的结果,你可以通过点击列标题对结果集进行排序和查找。
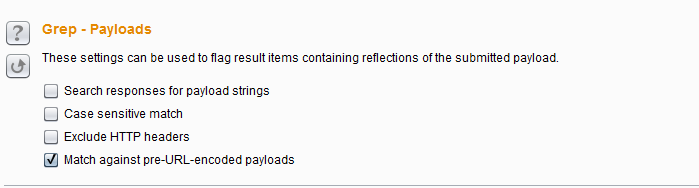
- 其设置项跟上一个类似,需要注意的是Match against pre-URL-encoded payloads,如果你在请求消息时配置了 URL-encode payloads ,则这里表示匹配未编码之前的Payload值,而不是转码后的值。
- 重定向(Redirections)——这些设置主要是用来控制执行攻击时Burp如何处理重定向,在实际使用中往往是必须遵循重定向,才能实现你的攻击目的。例如,在密码猜测攻击,每次尝试的结果可能是密码错误会重定向响应到一个错误消息提示页面,如果密码正确会重定向到用户中心的首页。 但设置了重定向也可能会遇到其他的问题,比如说,在某些情况下,应用程序存储您的会话中初始请求的结果,并提供重定向响应时检索此值,这时可能有必要在重定向时只使用一个单线程攻击。也可能会遇到,当你设置重定向,应用程序响应会重定向到注销页面,这时候,按照重定向可能会导致您的会话被终止时。 因其设置选项跟其他模块的重定向设置基本一致,此处就不再重叙。

Intruder 攻击和结果分析
一次攻击的发起,通常有两种方式。一种是你在Burp Intruder里设置了Target, Positions, Payloads and Options ,然后点击【Start attack】启动攻击;另一种是你打开一个之前保存的预攻击文件,然后点击【Start attack】启动攻击。无论是哪种方式的攻击发起,Burp都将弹出攻击结果界面。在攻击的过程中,你也可以修改攻击配置,或者做其他的操作。攻击结果的界面如下图所示: 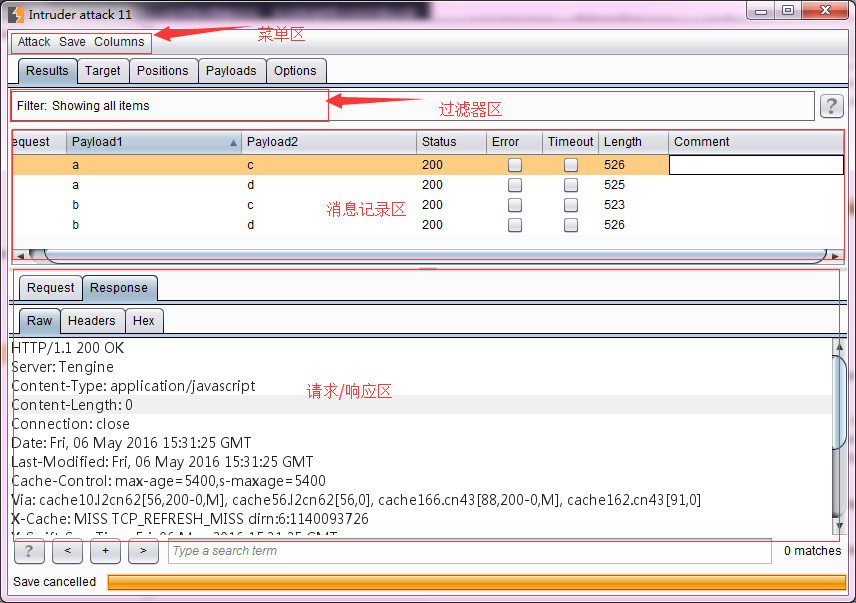
从上图我们可以看出,其界面主要又菜单区、过滤器、Payload执行结果消息记录区、请求/响应消息区四大部分组成。
- 菜单区 包含Attack菜单、Save菜单、Columns菜单。 Attack菜单主要用来控制攻击行为的,你可以暂停攻击(pause)、恢复攻击(resume)、再次攻击(repeat)。 Save菜单主要用来保存攻击的各种数据,Attack 保存当前攻击的副本,下次可以从此文件进行再次攻击;Results table保存攻击的结果列表,相当于图中的Payload执行结果消息记录区数据,当然你可以选择行和列进行保存,只导出你需要的数据;Server responses 保存所有的服务器响应消息;Attack configuration保存当前的攻击配置信息。 Columns菜单主要用来控制消息记录区的显示列。如果某个列被选中,则在Payload执行结果消息记录区显示,反之则不显示。
- 过滤器 ——可以通过查询条件、服务器响应的状态码、注释过Payload执行结果消息记录区的信息进行过滤。
- Payload执行结果消息记录区,又称结果列表(Results Table),记录Payload执行时请求和响应的所有信息,它包含的列有: 请求序列——显示请求的序列号,如果配置了记录未修改的请求消息母板,则会在第一个进行记录。Payload位置——狙击手模式下会记录 Payload值——如果有多个Payload,则存在多个列 HTTP 状态码——服务器响应状态码 请求时间——执行攻击的时间 响应时间——开始接受到响应时间,单位为毫秒。 响应完成时间——响应完成的时间,单位为毫秒。 网络错误——Payload执行时是否发生网络问题 超时情况——等待应答响应过程中,是否发生网络超时 长度——响应消息的长度 Cookie——任何的Cookie信息 Grep——如果设置了Grep 匹配、Grep 提取、Grep Payload,则会有多个列显示匹配的信息 重定向——如果配置了重定向,则显示 注释——消息记录的注释信息
- 请求/响应消息区——参考Proxy章节的相关叙述。
在对攻击结果的分析中,你可以通过单击任一列标题(单击标题循环通过升序排序,降序排序和未排序)重新排序表的内容。有效地解释攻击的结果的一个关键部分是定位有效的或成功的服务器响应,并确定生成这些请求。有效的应答通常可以通过以下中的至少一个存在差异: 1.不同的HTTP状态代码 2.不同长度的应答 3.存在或不存在某些表达式 4.错误或超时的发生 5.用来接收或完成响应时间的差异 比如说,在URL路径扫描过程中,对不存在的资源的请求可能会返回“404未找到”的响应,或正确的URL会反馈的“200 OK”响应。或者在密码猜测攻击,失败的登录尝试可能会产生一个包含“登录失败”关键字“200 OK”响应,而一个成功的登录可能会生成一个“302对象移动”的反应,或不同的“200 OK”响应页面。
每一个渗透测试人员,对Burp Intruder 攻击结果的分析方式可能会存在差异,这主要源于个人水平的不同和经验的不同。在实战中,只有慢慢尝试,积累,才能通过快速地对攻击结果的分析获取自己关注的重要信息。
第九章 如何使用Burp Repeater
Burp Repeater作为Burp Suite中一款手工验证HTTP消息的测试工具,通常用于多次重放请求响应和手工修改请求消息的修改后对服务器端响应的消息分析。本章我们主要学习的内容有:
- Repeater的使用
- 可选项设置(Options)
Repeater的使用
在渗透测试过程中,我们经常使用Repeater来进行请求与响应的消息验证分析,比如修改请求参数,验证输入的漏洞;修改请求参数,验证逻辑越权;从拦截历史记录中,捕获特征性的请求消息进行请求重放。Burp Repeater的操作界面如下图所示:
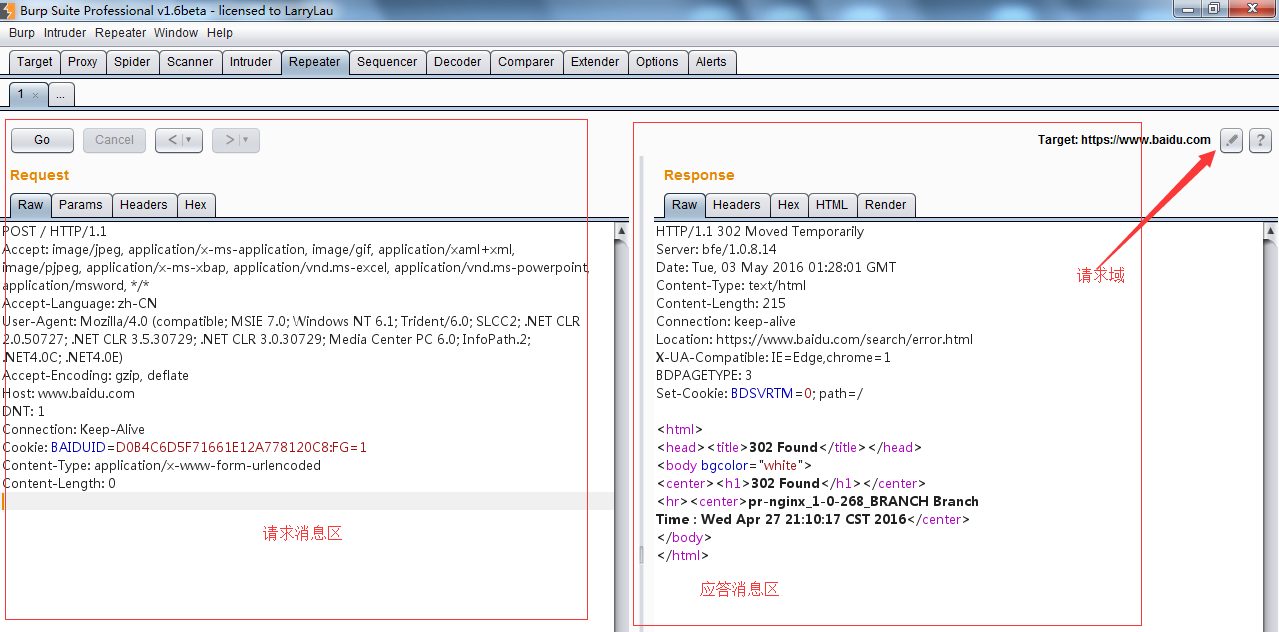
请求消息区为客户端发送的请求消息的详细信息,Burp Repeater为每一个请求都做了请求编号,当我们在请求编码的数字上双击之后,可以修改请求的名字,这是为了方便多个请求消息时,做备注或区分用的。在编号的下方,有一个【GO】按钮,当我们对请求的消息编辑完之后,点击此按钮即发送请求给服务器端。服务器的请求域可以在target处进行修改,如上图所示。
应答消息区为对应的请求消息点击【GO】按钮后,服务器端的反馈消息。通过修改请求消息的参数来比对分析每次应答消息之间的差异,能更好的帮助我们分析系统可能存在的漏洞。
在我们使用Burp Repeater时,通常会结合Burp的其他工具一起使用,比如Proxy的历史记录,Scanner的扫描记录、Target的站点地图等,通过其他工具上的右击菜单,执行【Send to Repeater】,跳转到Repeater选项卡中,然后才是对请求消息的修改以及请求重放、数据分析与漏洞验证。
可选项设置(Options)
与Burp其他工具的设置不同,Repeater的可选项设置菜单位于整个界面顶部的菜单栏中,如图所示: 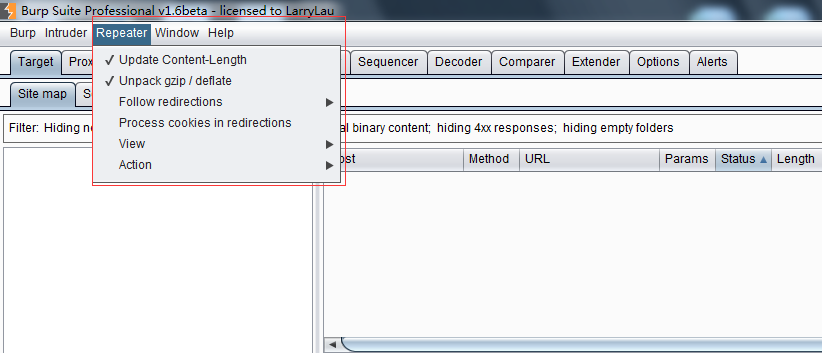
其设置主要包括以下内容:
-
- 更新Content-Length
这个选项是用于控制Burp是否自动更新请求消息头中的Content-Length - 解压和压缩(Unpack gzip / deflate ) 这个选项主要用于控制Burp是否自动解压或压缩服务器端响应的内容
- 跳转控制(Follow redirections) 这个选项主要用于控制Burp是否自动跟随服务器端作请求跳转,比如服务端返回状态码为302,是否跟着应答跳转到302指向的url地址。 它有4个选项,分别是永不跳转(Never),站内跳转(On-site only )、目标域内跳转(In-scope only)、始终跳转(Always),其中永不跳转、始终跳转比较好理解,站内跳转是指当前的同一站点内跳转;目标域跳转是指target scope中配置的域可以跳转;
- 跳转中处理Cookie(Process cookies in redirections ) 这个选项如果选中,则在跳转过程中设置的Cookie信息,将会被带到跳转指向的URL页面,可以进行提交。
- 视图控制(View) 这个选项是用来控制Repeater的视图布局
- 其他操作(Action) 通过子菜单方式,指向Burp的其他工具组件中。
- 更新Content-Length















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









