






三、物理内存管理
物理内存的组织方式
我们总是把物理内存想象成它是由连续的一页一页的块组成的。我们可以从 0 开始对物理页编号,这样每个物理页都会有个页号。由于物理地址是连续的,页也是连续的,每个页大小也是一样的。因而对于任何一个地址,只要直接除一下每页的大小,很容易直接算出在哪一页。每个页有一个结构 struct page 表示,这个结构也是放在一个数组里面,这样根据页号,很容易通过下标找到相应的 structpage 结构。
如果是这样,整个物理内存的布局就非常简单、易管理,这就是最经典的平坦内存模型(Flat Memory Model)。我们讲 x86 的工作模式的时候,讲过 CPU 是通过总线去访问内存的,这就是最经典的内存使用方式。
在这种模式下,CPU 也会有多个,在总线的一侧。所有的内存条组成一大片内存,在总线的另一侧,所有的 CPU 访问内存都要过总线,而且距离都是一样的,这种模式称为SMP(Symmetric multiprocessing),即对称多处理器。当然,它也有一个显著的缺点,就是总线会成为瓶颈,因为数据都要走它。
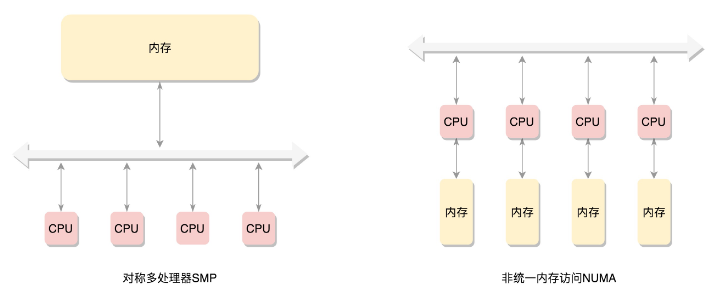
为了提高性能和可扩展性,后来有了一种更高级的模式,NUMA(Non-uniform memoryaccess),非一致内存访问。在这种模式下,内存不是一整块。每个 CPU 都有自己的本地内存,CPU 访问本地内存不用过总线,因而速度要快很多,每个 CPU 和内存在一起,称为一个 NUMA 节点。但是,在本地内存不足的情况下,每个 CPU 都可以去另外的 NUMA节点申请内存,这个时候访问延时就会比较长。
这样,内存被分成了多个节点,每个节点再被分成一个一个的页面。由于页需要全局唯一定位,页还是需要有全局唯一的页号的。但是由于物理内存不是连起来的了,页号也就不再连续了。于是内存模型就变成了非连续内存模型,管理起来就复杂一些。
节点
区域
我们把内存分成了节点,把节点分成了区域。接下来我们来看,一个区域里面是如何组织的。
页
了解了区域 zone,接下来我们就到了组成物理内存的基本单位,页的数据结构 structpage。这是一个特别复杂的结构,里面有很多的 union,union 结构是在 C 语言中被用于同一块内存根据情况保存不同类型数据的一种方式。这里之所以用了 union,是因为一个物理页面使用模式有多种。
页的分配
前面我们讲了物理内存的组织,从节点到区域到页到小块。接下来,我们来看物理内存的分配。
对于要分配比较大的内存,例如到分配页级别的,可以使用伙伴系统(Buddy System)。Linux 中的内存管理的“页”大小为 4KB。把所有的空闲页分组为 11 个页块链表,每个块链表分别包含很多个大小的页块,有 1、2、4、8、16、32、64、128、256、512 和 1024 个连续页的页块。最大可以申请 1024 个连续页,对应 4MB 大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍。
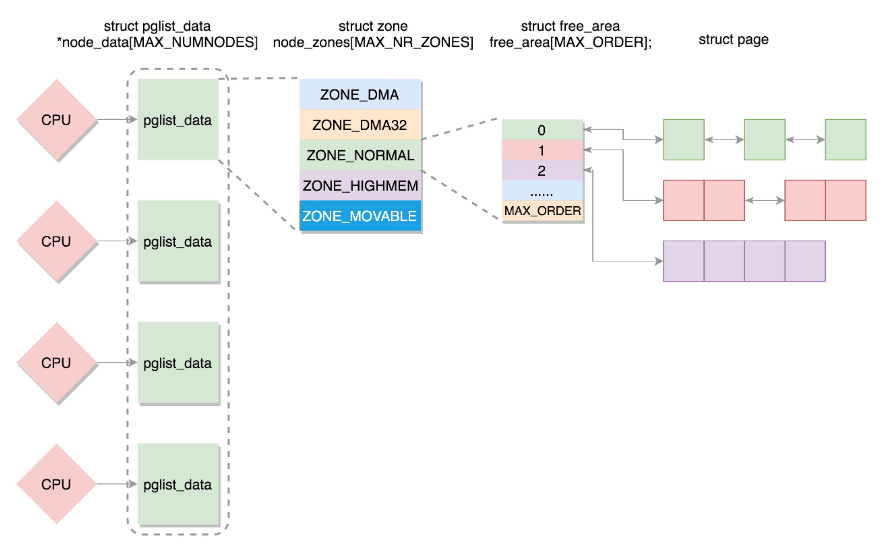
如果有多个 CPU,那就有多个节点。每个节点用 struct pglist_data 表示,放在一个数组里面。
每个节点分为多个区域,每个区域用 struct zone 表示,也放在一个数组里面。每个区域分为多个页。
为了方便分配,空闲页放在 struct free_area 里面,使用伙伴系统进行管理和分配,每一页用 struct page 表示。
小内存的分配
如果遇到小的对象,会使用 slub 分配器进行分配。
页面换出
另一个物理内存管理必须要处理的事情就是,页面换出。每个进程都有自己的虚拟地址空间,无论是 32 位还是 64 位,虚拟地址空间都非常大,物理内存不可能有这么多的空间放得下。所以,一般情况下,页面只有在被使用的时候,才会放在物理内存中。如果过了一段时间不被使用,即便用户进程并没有释放它,物理内存管理也有责任做一定的干预。例如,将这些物理内存中的页面换出到硬盘上去;将空出的物理内存,交给活跃的进程去使用。
什么情况下会触发页面换出呢?
最常见的情况就是,分配内存的时候,发现没有地方了,就试图回收一下。例如,咱们解析申请一个页面的时候,会调用 get_page_from_freelist,接下来的调用链为get_page_from_freelist->node_reclaim->__node_reclaim->shrink_node,通过这个调用链可以看出,页面换出也是以内存节点为单位的。
还有一种情况,就是作为内存管理系统应该主动去做的,而不能等真的出了事儿再做,这就是内核线程kswapd。这个内核线程,在系统初始化的时候就被创建。这样它会进入一个无限循环,直到系统停止。在这个循环中,如果内存使用没有那么紧张,那它就可以放心睡大觉;如果内存紧张了,就需要去检查一下内存,看看是否需要换出一些内存页。
对于物理内存来讲,从下层到上层的关系及分配模式如下:
物理内存分 NUMA 节点,分别进行管理;
每个 NUMA 节点分成多个内存区域;
每个内存区域分成多个物理页面;
伙伴系统将多个连续的页面作为一个大的内存块分配给上层;
kswapd 负责物理页面的换入换出;
Slub Allocator 将从伙伴系统申请的大内存块切成小块,分配给其他系统。
四、用户态内存映射
mmap 的原理
每一个进程都有一个列表 vm_area_struct,指向虚拟地址空间的不同的内存块,这个变量的名字叫mmap。其实内存映射不仅仅是物理内存和虚拟内存之间的映射,还包括将文件中的内容映射到虚拟内存空间。这个时候,访问内存空间就能够访问到文件里面的数据。而仅有物理内存和虚拟内存的映射,是一种特殊情况。
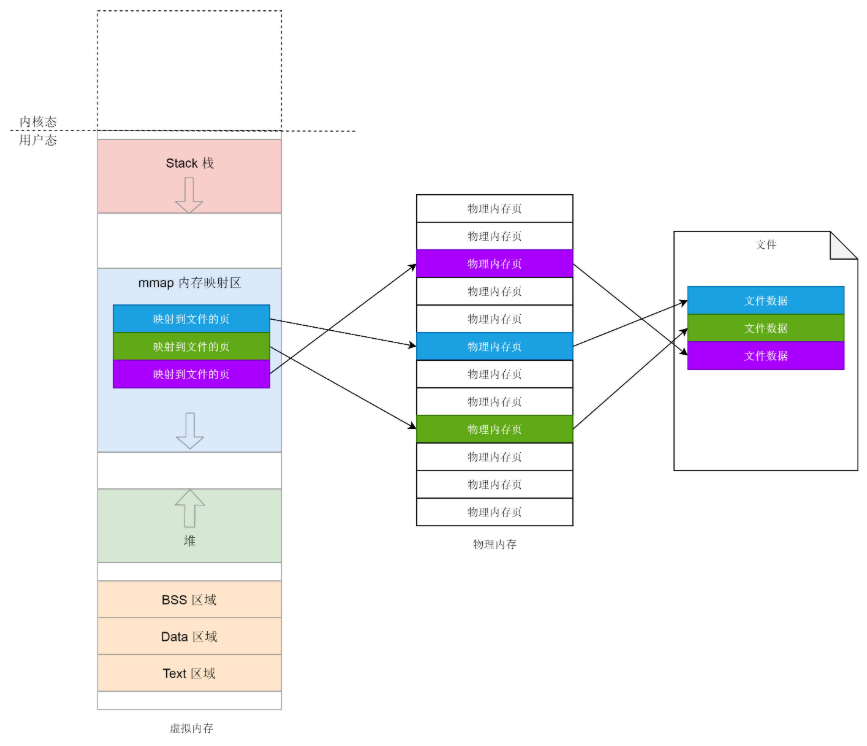
前面咱们讲堆的时候讲过,如果我们要申请小块内存,就用 brk。brk 函数之前已经解析过了,这里就不多说了。如果申请一大块内存,就要用 mmap。对于堆的申请来讲,mmap是映射内存空间到物理内存。
另外,如果一个进程想映射一个文件到自己的虚拟内存空间,也要通过 mmap 系统调用。这个时候 mmap 是映射内存空间到物理内存再到文件。可见 mmap 这个系统调用是核心。
用户态缺页异常
在用户态访问没有映射的内存会引发缺页异常,分配物理页表、补齐页表。
如果是匿名映射则分配物理内存;如果是 swap,则将 swap 文件读入;如果是文件映射,则将文件读入。
五、内核态内存映射
内核页表
和用户态页表不同,在系统初始化的时候,我们就要创建内核页表了。
vmalloc 和 kmap_atomic 原理
内核态缺页异常
总结时刻
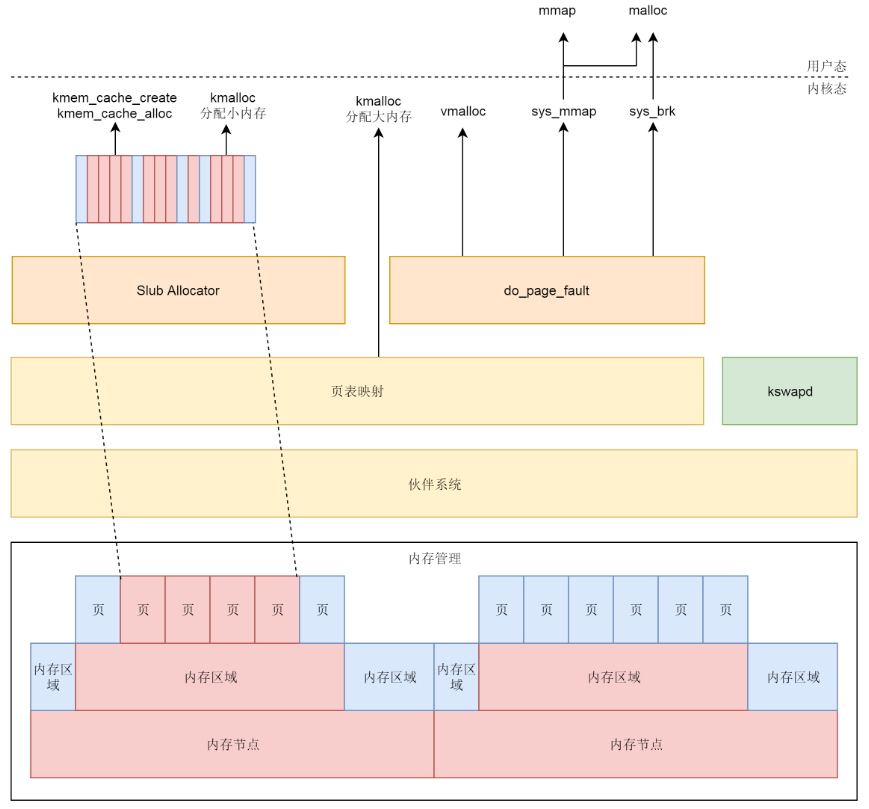
物理内存根据 NUMA 架构分节点。每个节点里面再分区域。每个区域里面再分页。
物理页面通过伙伴系统进行分配。分配的物理页面要变成虚拟地址让上层可以访问,kswapd 可以根据物理页面的使用情况对页面进行换入换出。
对于内存的分配需求,可能来自内核态,也可能来自用户态。
对于内核态,kmalloc 在分配大内存的时候,以及 vmalloc 分配不连续物理页的时候,直接使用伙伴系统,分配后转换为虚拟地址,访问的时候需要通过内核页表进行映射。
对于 kmem_cache 以及 kmalloc 分配小内存,则使用 slub 分配器,将伙伴系统分配出来的大块内存切成一小块一小块进行分配。
kmem_cache 和 kmalloc 的部分不会被换出,因为用这两个函数分配的内存多用于保持内核关键的数据结构。内核态中 vmalloc 分配的部分会被换出,因而当访问的时候,发现不在,就会调用 do_page_fault。
对于用户态的内存分配,或者直接调用 mmap 系统调用分配,或者调用 malloc。调用malloc 的时候,如果分配小的内存,就用 sys_brk 系统调用;如果分配大的内存,还是用sys_mmap 系统调用。正常情况下,用户态的内存都是可以换出的,因而一旦发现内存中不存在,就会调用 do_page_fault。















 2463
2463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









