






linux默认的shell /bin/bash
用户登陆后默认的bash是在 /etc/passwd中设置的
历史命令记录在 /.bash_history 中(上次登陆的记录,本次在内存中)
alias 别名设置 例:alias lm='ls -al'(注销即失效)
type 内置命令、外部命令 例:type ls
\ 命令太长时 换行符
a=123 变量名只能是英文和数字,开头不能是数字,等号两边不能是空格
单引号' ' 所见即所得 双引号" "会解析变量
转义字符 \ 例:\$ \空格 \'
变量大小写敏感
(注销即失效)
需要通过其他命令传递信息
a=`ls -a` b=$(ls -a)
echo $a echo $b
变量增加内容
c="$a"+2 c=${a}+2 c=$a+2
各种系统变量
echo $PATH $HOME $SHELL
env:查看环境变量
set: 查看所有变量
echo $$ shell的pid
echo $? 上个命令的回传码(错误码)
echo !$ 上个命令的参数
echo !:1 上个命令的第一个参数
export xxx 变量需要在其它子进程执行 自定义变量 变为环境变量
unset xxx 取消变量
login shell:通过登录的shell
non-login shell:非登录取得的shell
环境变量文件:
全局设置 /etc/profile
个人设置 ~/.bash_profile ~/.bash_login ~/.profile
login shell 读取顺序:实线是流程,虚线是调用
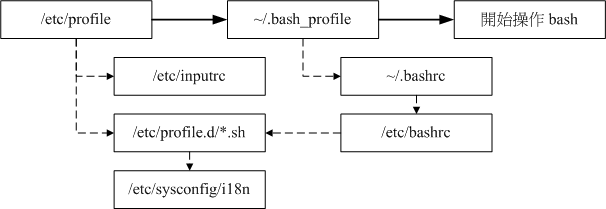
个人偏好可以写入~/.bashrc
直接读取配置
source 配置文件=. 配置文件
non-login shell
仅会读取 ~/.bashrc
在 bash 的操作环境中还有一个非常有用的功能,那就是通配符 (wildcard) !
| 符号 | 意义 |
| * | 代表『 0 个到无穷多个』任意字符 |
| ? | 代表『一定有一个』任意字符 |
| [ ] | 同样代表『一定有一个在括号内』的字符(非任意字符)。例如 [abcd] 代表『一定有一个字符, 可能是 a, b, c, d 这四个任何一个』 |
| [ - ] | 若有减号在中括号内时,代表『在编码顺序内的所有字符』。例如 [0-9] 代表 0 到 9 之间的所有数字,因为数字的语系编码是连续的! |
| [^ ] | 若中括号内的第一个字符为指数符号 (^) ,那表示『反向选择』,例如 [^abc] 代表 一定有一个字符,只要是非 a, b, c 的其他字符就接受的意思。 |
bash 环境中的特殊符号:
| 符号 | 内容 |
| # | 批注符号:这个最常被使用在 script 当中,视为说明!在后的数据均不运行 |
| \ | 跳脱符号:将『特殊字符或通配符』还原成一般字符 |
| | | 管线 (pipe):分隔两个管线命令的界定(后两节介绍); |
| ; | 连续命令下达分隔符:连续性命令的界定 (注意!与管线命令并不相同) |
| ~ | 用户的家目录 |
| $ | 取用变量前导符:亦即是变量之前需要加的变量取代值 |
| & | 工作控制 (job control):将命令变成背景下工作 |
| ! | 逻辑运算意义上的『非』 not 的意思! |
| / | 目录符号:路径分隔的符号 |
| >, >> | 数据流重导向:输出导向,分别是『取代』与『累加』 |
| <, << | 数据流重导向:输入导向 (这两个留待下节介绍) |
| ' ' | 单引号,不具有变量置换的功能 |
| " " | 具有变量置换的功能! |
| ` ` | 两个『 ` 』中间为可以先运行的命令,亦可使用 $( ) |
| ( ) | 在中间为子 shell 的起始与结束 |
| { } | 在中间为命令区块的组合! |
以上为 bash 环境中常见的特殊符号汇整!理论上,文件名尽量不要使用到上述的字符
数据流重导向
- 标准输入 (stdin) :代码为 0 ,使用 < 或 << ;
- 标准输出 (stdout):代码为 1 ,使用 > 或 >> ;
- 标准错误输出(stderr):代码为 2 ,使用 2> 或 2>> ;
- 1> :以覆盖的方法将『正确的数据』输出到指定的文件或装置上;
- 1>>:以累加的方法将『正确的数据』输出到指定的文件或装置上;
- 2> :以覆盖的方法将『错误的数据』输出到指定的文件或装置上;
- 2>>:以累加的方法将『错误的数据』输出到指定的文件或装置上;
标准输出和错误输出 写入到不同文件
find /home -name .bashrc > list_right 2> list_error标准输出和错误输出 写入到同一文件find /home -name .bashrc > list 2>&1- /dev/null 垃圾桶黑洞装置与特殊写法
find /home -name .bashrc > /dev/null 2>&1
find /home -name .bashrc &> /dev/null
- standard input : < 与 <<
将原本需要由键盘输入的数据,改由文件内容来取代
范例六:利用 cat 命令来创建一个文件的简单流程
[root@www ~]# cat > filetest
cat file test<==这里按下 [ctrl]+d 来离开
[root@www ~]# cat filetest
cat file test
由于加入 > 在 cat 后,所以那个 catfile 会被主动的创建,而内容就是刚刚键盘上面输入的那两行数据了。
那我能不能用纯文本文件取代键盘的输入,也就是说,用某个文件的内容来取代键盘的敲击呢? 可以的!如下所示:
[root@www ~]# cat > catfile < ~/.bashrc [root@www ~]# ll catfile ~/.bashrc -rw-r--r-- 1 root root 194 Sep 26 13:36 /root/.bashrc -rw-r--r-- 1 root root 194 Feb 6 18:29 catfile # 注意看,这两个文件的大小会一模一样!几乎像是使用 cp 来复制一般!
[root@www ~]# cat > catfile << "eof"
> This is a test.
> OK now stop
> eof <==输入这关键词,立刻就结束而不需要输入 [ctrl]+d
[root@www ~]# cat catfile
This is a test.
OK now stop <==只有这两行,不会存在关键词那一行!
命令运行的判断依据: ; , &&, ||
- cmd; cmd (不考虑命令相关性的连续命令下达)
- cmd1&& cmd2 命令1正确 才运行 命令2
- cmd1 ||cmd2 命令1错误 才运行 命令2
管线命令 (pipe)
管线命令『 | 』仅能处理经由前面一个命令传来的正确信息,也就是 standard output 的信息,
对于 stdandard error 并没有直接处理的能力
- 管线命令仅会处理 standard output,对于 standard error output 会予以忽略
管线命令必须要能够接受来自前一个命令的数据成为 standard input 继续处理才行。
双向重导向 tee:
tee 会同时将数据流分送到文件去与屏幕 (screen);而输出到屏幕的,其实就是 stdout
# ls -l /home | tee ~/homefile | more
# 这个范例则是将 ls 的数据存一份到 ~/homefile ,同时屏幕也有输出信息!
字符转换命令: tr, col, join, paste, expand:
tr
tr [OPTION]... SET1 [SET2]
注意:SET2是可选项
OPTION:
不带参数:用SET2中的每个字符替换SET1中的每个字符,字符是顺序替换,
如果SET1的字符长度大于SET2,那么将SET1中多出来的字符用SET2中的最后一个字符替换。
-t:将SET2中的每个字符替换SET1中的每个字符,字符字符顺序1对1替换,
无论SET1还是SET2哪个长,只替换对应的字符,多出的不替换。
-c:取反操作,取数据流中SET1中指定字符的补集。
-d:删除SET1中指定的字符,这里没有SET2
-s:将SET1中指定的连续重复的字符用单个字符替代,可以使用-s '\n'删除空行
替换功能:
范例一:将 last 输出的信息中,所有的小写变成大写字符:
# last | tr '[a-z]' '[A-Z]'
范例二:将文件file中出现的"abc"替换为"xyz"
而不是将字符串"abc"替换为字符串"xyz"。
删除功能:
而不是紧紧删除出现的"Snail”字符串。
# cat /root/passwd | tr -d '\r' > /root/passwd.linux
# 那个 \r 指的是 DOS 的断行字符
去重功能:
# echo "aaAA1bbBB2ccCC3" | tr -s 'a-zA-Z'
aA1bB2cC3
# echo "name" |tr -d -c 'a \n' a
上述操作是删除标准输入中除“a”,空格 "\n"之外的所有字符
col
[root@www ~]# col [-xb]
选项与参数:
-x :将 tab 键转换成对等的空格键
-b :在文字内有反斜杠 (/) 时,仅保留反斜杠最后接的那个字符
范例一:利用 cat -A 显示出所有特殊按键,最后以 col 将 [tab] 转成空白
[root@www ~]# cat -A /etc/man.config <==此时会看到很多 ^I 的符号,那就是 tab
[root@www ~]# cat /etc/man.config | col -x | cat -A | more
# 嘿嘿!如此一来, [tab] 按键会被取代成为空格键,输出就美观多了!
范例二:将 col 的 man page 转存成为 /root/col.man 的纯文本档
[root@www ~]# man col > /root/col.man
- paste
paste 就直接『将两行贴在一起,且中间以 [tab] 键隔开』而已!
[root@www ~]# paste [-d] file1 file2
选项与参数:
-d :后面可以接分隔字符。默认是以 [tab] 来分隔的!
- :如果 file 部分写成 - ,表示来自 standard input 的数据的意思。
范例一:将 /etc/passwd 与 /etc/shadow 同一行贴在一起
[root@www ~]# paste /etc/passwd /etc/shadow
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:14126:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:14126:0:99999:7:::
adm:x:3:4:adm:/var/adm:/sbin/nologin adm:*:14126:0:99999:7:::
# 注意喔!同一行中间是以 [tab] 按键隔开的!
范例二:先将 /etc/group 读出(用 cat),然后与范例一贴上一起!且仅取出前三行
[root@www ~]# cat /etc/group|paste /etc/passwd /etc/shadow -|head -n 3
# 这个例子的重点在那个 - 的使用!那玩意儿常常代表 stdin 喔!
- join
处理两个文件之间的数据, 而且,主要是在处理『两个文件当中,有 "相同数据" 的那一行,才将他加在一起』的意思。
[root@www ~]# join [-ti12] file1 file2
选项与参数:
-t :join 默认以空格符分隔数据,并且比对『第一个字段』的数据,
如果两个文件相同,则将两笔数据联成一行,且第一个字段放在第一个!
-i :忽略大小写的差异;
-1 :这个是数字的 1 ,代表『第一个文件要用那个字段来分析』的意思;
-2 :代表『第二个文件要用那个字段来分析』的意思。
[root@www ~]# join -t ':' /etc/passwd /etc/shadow
root:x:0:0:root:/root:/bin/bash:$1$/3AQpE5e$y9A/D0bh6rElAs:14120:0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin:*:14126:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin:*:14126:0:99999:7:::
# 透过上面这个动作,我们可以将两个文件第一字段相同者整合成一行!
# 第二个文件的相同字段并不会显示(因为已经在第一行了嘛!)
范例二:我们知道 /etc/passwd 第四个字段是 GID ,那个 GID 记录在
/etc/group 当中的第三个字段,请问如何将两个文件整合?
[root@www ~]# head -n 3 /etc/passwd /etc/group
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
==> /etc/group <==
root:x:0:root
bin:x:1:root,bin,daemon
daemon:x:2:root,bin,daemon
# 从上面可以看到,确实有相同的部分喔!赶紧来整合一下!
[root@www ~]# join -t ':' -1 4 /etc/passwd -2 3 /etc/group
0:root:x:0:root:/root:/bin/bash:root:x:root
1:bin:x:1:bin:/bin:/sbin/nologin:bin:x:root,bin,daemon
2:daemon:x:2:daemon:/sbin:/sbin/nologin:daemon:x:root,bin,daemon
# 同样的,相同的字段部分被移动到最前面了!所以第二个文件的内容就没再显示。
# 请读者们配合上述显示两个文件的实际内容来比对!
需要特别注意的是,在使用 join 之前,你所需要处理的文件应该要事先经过排序 (sort) 处理! 否则有些比对的项目会被略过呢!特别注意了!
- expand
这玩意儿就是在将 [tab] 按键转成空格键啦~可以这样玩:
[root@www ~]# expand [-t] file
选项与参数:
-t :后面可以接数字。一般来说,一个 tab 按键可以用 8 个空格键取代。
我们也可以自行定义一个 [tab] 按键代表多少个字符呢!
分割命令: split
可以帮你将一个大文件,依据文件大小或行数来分割,就可以将大文件分割成为小文件了! 快速又有效啊!
[root@www ~]# split [-bl] file PREFIX
选项与参数:
-b :后面可接欲分割成的文件大小,可加单位,例如 b, k, m 等;
-l :以行数来进行分割。
PREFIX :代表前导符的意思,可作为分割文件的前导文字。
范例一:我的 /etc/termcap 有七百多K,若想要分成 300K 一个文件时?
[root@www ~]# cd /tmp; split -b 300k /etc/termcap termcap
[root@www tmp]# ll -k termcap*
-rw-r--r-- 1 root root 300 Feb 7 16:39 termcapaa
-rw-r--r-- 1 root root 300 Feb 7 16:39 termcapab
-rw-r--r-- 1 root root 189 Feb 7 16:39 termcapac
使用 ls -al / 输出的信息中,每十行记录成一个文件
[root@www tmp]# ls -al / | split -l 10 - lsroot
[root@www tmp]# wc -l lsroot*
10 lsrootaa
10 lsrootab
6 lsrootac
26 total
参数代换: xargs
以字面上的意义来看, x 是加减乘除的乘号,args 则是 arguments (参数) 的意思,所以说,这个玩意儿就是在产生某个命令的参数的意思!
xargs 可以读入 stdin 的数据,并且以空格符或断行字符作为分辨,将 stdin 的数据分隔成为 arguments 。
因为是以空格符作为分隔,所以,如果有一些档名或者是其他意义的名词内含有空格符的时候, xargs 可能就会误判了。
[root@www ~]# xargs [-0epn] command
选项与参数:
-0 :如果输入的 stdin 含有特殊字符,例如 `, \, 空格键等等字符时,这个 -0 参数
可以将他还原成一般字符。这个参数可以用于特殊状态喔!
-e :这个是 EOF (end of file) 的意思。后面可以接一个字符串,当 xargs 分析到
这个字符串时,就会停止继续工作!
-p :在运行每个命令的 argument 时,都会询问使用者的意思;
-n :后面接次数,每次 command 命令运行时,要使用几个参数的意思。看范例三。
当 xargs 后面没有接任何的命令时,默认是以 echo 来进行输出喔!
将所有的 /etc/passwd 内的账号都以 finger 查阅,但一次仅查阅五个账号
[root@www ~]# cut -d':' -f1 /etc/passwd | xargs -p -n 5 finger
finger root bin daemon adm lp ?...y
.....(中间省略)....
bash中变量内容的删除和替换:
| 变量配置方式 | 说明 |
| ${变量#关键词} ${变量##关键词} | 若变量内容从头开始的数据符合『关键词』,则将符合的最短数据删除 若变量内容从头开始的数据符合『关键词』,则将符合的最长数据删除 |
| ${变量%关键词} ${变量%%关键词} | 若变量内容从尾向前的数据符合『关键词』,则将符合的最短数据删除 若变量内容从尾向前的数据符合『关键词』,则将符合的最长数据删除 |
| ${变量/旧字符串/新字符串} ${变量//旧字符串/新字符串} | 若变量内容符合『旧字符串』则『第一个旧字符串会被新字符串取代』 若变量内容符合『旧字符串』则『全部的旧字符串会被新字符串取代』 |
例:
# echo $a
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# echo ${a#/*sbin:}
/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# echo ${a##/*root}
/bin
# echo $a
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# echo ${a/bin/BIN}
/usr/local/sBIN:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# echo ${a//bin/BIN}
/usr/local/sBIN:/usr/local/BIN:/usr/sBIN:/usr/BIN:/root/BIN
bash中 变量的测试与内容替换:
| 变量配置方式 | str 没有配置 | str 为空字符串 | str 已配置非为空字符串 |
| var=${str-expr} | var=expr | var= | var=$str |
| var=${str:-expr} | var=expr | var=expr | var=$str |
| var=${str+expr} | var= | var=expr | var=expr |
| var=${str:+expr} | var= | var= | var=expr |
| var=${str=expr} | str=expr var=expr | str 不变 var= | str 不变 var=$str |
| var=${str:=expr} | str=expr var=expr | str=expr var=expr | str 不变 var=$str |
| var=${str?expr} | expr 输出至 stderr | var= | var=$str |
| var=${str:?expr} | expr 输出至 stderr | expr 输出至 stderr | var=$str |
例:
# unset b
# b=${a-xxx}
# echo $b
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin















 1958
1958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









