






当使用这个库的时候经常会出现各种乱码的情况。
首先要知道:
text返回的是处理过的unicode的数据。
content返回的是bytes的原始数据
也就是说r.content比r.text更加节省资源
如果headers没有charset字符集的化,text()会调用chardet来计算字符集,这又是消耗cpu的事情
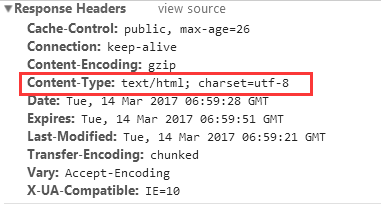
倘若在conttent-type字段中没有制定charset的时候,默认使用的是ISO-8859-1编码,在处理英文的时候是没有问题,但是在处理中文的时候就会出现乱码的情况了。
解决
如果在确定使用text,并已经得知该站的字符集编码时,可以使用 r.encoding = ‘xxx’ 模式, 当你指定编码后,requests在text时会根据你设定的字符集编码进行转换.
使用apprent_encoding可以获得真实编码
1 >>> import requests 2 >>> respone = requests.get("http://www.baidu.com/") 3 >>> respone.apparent_encoding 4 'utf-8'















 4790
4790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









