







1交叉熵损失函数的由来
1.1关于熵,交叉熵,相对熵(KL散度)
熵:香农信息量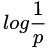 的期望。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。其计算公式如下:
的期望。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。其计算公式如下:
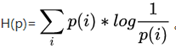
其是一个期望的计算,也是记录随机事件结果的平均编码长度(关于编码:一个事件结果的出现概率越低,对其编码的bit长度就越长。即无法压缩的表达,代表了真正的信息量.)
熵与交叉熵之间的联系:
假设有两个分布p,q。其中p是真实概率分布,q是你以为(估计)的概率分布(可能不一致);你以 q 去编码,编码方案 log(1/qi)可能不是最优的; 于是,平均编码长度 = ∑pi *log(1/qi),就是交叉熵;只有在估算的分布q完全正确时,即q与p的分布完全相同时,平均编码长度才是最短的,此时交叉熵 = 熵
相对熵: q得到的平均编码长度比由p得到的平均编码长度多出的bit数(交叉熵与熵的差值)。
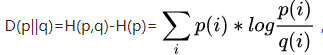
1.2交叉熵与极大似然估计得关系
一般情况下的极大似然函数如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









