






在做爬虫时请求网页的requests库是必不可少的,我们常常会用到 res = resquests.get(url) 方法,在获取网页的html代码时常常使用res的text属性: html = res.text,在下载图片或文件时常常使用res的content属性:
with open(filename, 'wb') as fp: fp.write(res.content)
下面我们来看看 'text' 和 'content' 的不同之处:
输出本博客的响应对象的 text
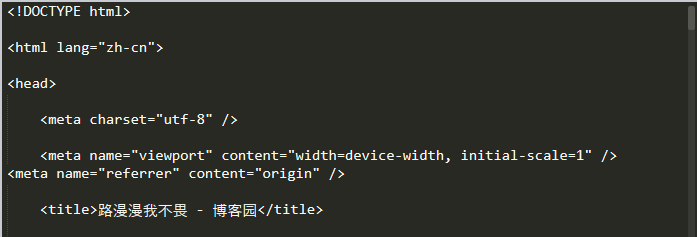
import requests url = 'https://www.cnblogs.com/huwt/' res = requests.get(url, timeout = 6) print(res.text)
(只截取到<title>标签)
输出本博客的响应对象的 content
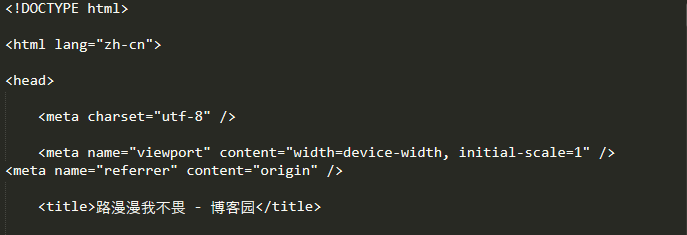
import requests url = 'https://www.cnblogs.com/huwt/' res = requests.get(url, timeout = 6) print(res.content)
(只截取到<title>标签)

通过<title>标签我们可以看出 res.text 直接输出了汉字,而 res.content 好像是以十六进制的形式来表示汉字
为了让进一步了解text 和 content 我们来看看它们的类型:
import requests url = 'https://www.cnblogs.com/huwt/' res = requests.get(url, timeout = 6) print(type(res.text)) print(type(res.content))

我们可以看到res.text是字符串类型,而res.content是二进制类型
为了进一步验证我们使用bytes类型的decode()方法对content进行‘utf-8’编码再显示
import requests url = 'https://www.cnblogs.com/huwt/' res = requests.get(url, timeout = 6) print(res.content.decode('utf-8'))
发现和res.text显示的内容完全一样
因此我们可以得出结论:
resp.text返回的是Unicode型的数据。
resp.content返回的是bytes型也就是二进制的数据。、
获取文本一般使用res.text, 获取图片或文件一般使用res.conten
再做几点补充:
text是content经过编码之后的字符串,那编码方式是什么呢? 在返回text时requests会基于 HTTP 头部对响应的编码作出有根据的推测,但不一定准确,有可能出现乱码, 而我们可以手动指定一种编码方式:res.encoding = '需要的编码方式' 或让requests根据body进行猜测:res.encoding = res.apparent_encoding
参考学习:
https://zhidao.baidu.com/question/941417472703558372.html
https://www.cnblogs.com/loveyouyou616/p/8135678.html
https://www.cnblogs.com/chownjy/p/6625299.html
https://www.jianshu.com/p/0e0336b370f3














 1298
1298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









