






序列化协议作用:
协议在网络通信中的作用;
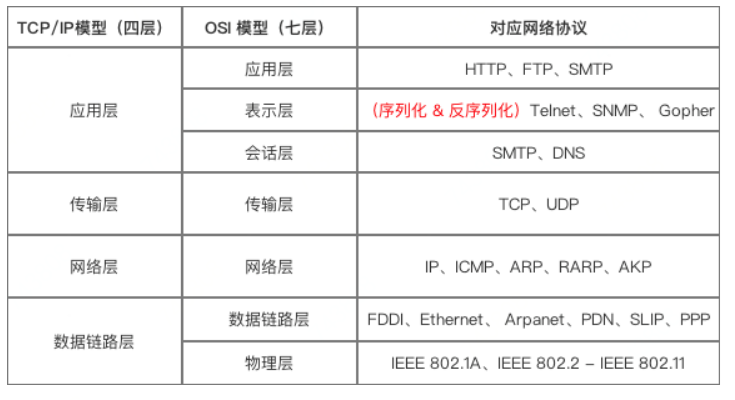
序列化 / 反序列化 属于 TCP/IP模型 应用层 和 OSI`模型 表示示层的主要功能:
(序列化)把 应用层的对象 转换成 二进制串
(反序列化)把 二进制串 转换成 应用层的对象
常见协议(messagepack介绍)
官方介绍:It’s like JSON.but fast and small.
https://github.com/msgpack/msgpack/blob/master/spec.md
简单来说,它的数据格式与json相似,但在存储时做了很多优化,减少无用的字符,二进制格式
编码方式尽量减少带来额外的存储空间。
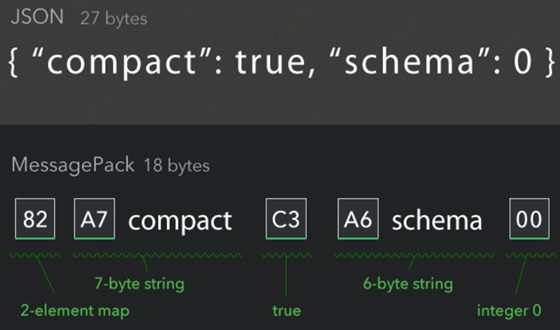
如上图:使用json需要27字节,而MessagePack仅要18字节。
在MessagePack中常见类型是怎么进行编码的?
1)Boolean类型:1字节就能标识

2)可变长度:[类型 长度] + 数据
比如:字符串、数组(map与数组类似)、二进制数据(bin类型),
1bite 前四位表示类型 后四位表示长度,接着是真实数据。
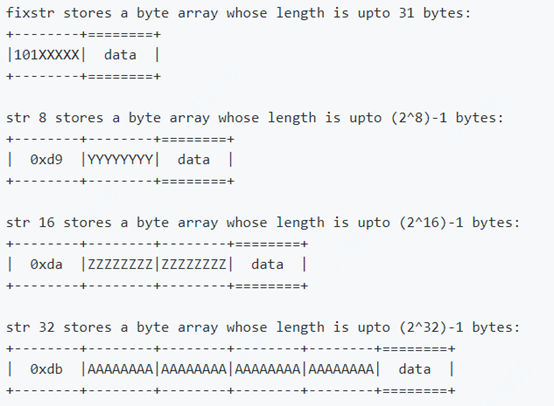
以String类型为例:
编码后就是数据真实长度+1位。
当data长度大于31字节小于(2^8)-1时,会使用0xd9的方式,第2字节记录data长度,
以此类推,最大支持(2^32)-1。
MessagePack对字符串的部分编码规则:
3)int类型:
uint8 8位正数、uint16 16位正数 最大支持64位正数。

举个例子,介绍下MessagePack是如何进行序列化和反序列化的

@Test
public void init() throws Exception {
File tempFile = new File("D:/msgPackTemp.txt");
StudentInfo studentInfo = new StudentInfo();
studentInfo.setName("jack");
studentInfo.setAge(12);
String[] strings = {"sleep", "basketball", "football"};
studentInfo.setHabits(strings);
FileOutputStream fileOutputStream = new FileOutputStream(tempFile);
MessagePack messagePack = new MessagePack();
Packer packer = messagePack.createPacker(fileOutputStream);
packer.write(studentInfo);
packer.close();
System.out.println("----------------------------end");
}
结果:

分析:

这种编码方式,解密时需要完全按照顺序去解码。
同时说明了,如果在rpc调用中接口参数升级,对象添加属性必须注意顺序。
常见协议(hessian介绍)
Hessian :是自我描述序列化的类型,不需要外部架构和接口定义。
Hessian的对象支持八种原始类型:
1,原生二进制数据
2,Boolean
3,64位毫秒值的日期
4,64位double
5,32位int
6,64位long
7,null
u8,tf-8的string
它有三种循环的类型:
1,list for lists and arrays
2,map for maps and dictionaries
3,object for objects
共享和循环对象引用
常见类型的编码方式介绍:



上述仅是部分,详细参见:
中文文档: https://www.jianshu.com/p/e800d8af4e22
官网文档: http://hessian.caucho.com/doc/hessian-serialization.html
看个例子:

@Test
public void init() throws Exception {
File tempFile = new File(fileName);
//序列化
StudentInfo studentInfo = new StudentInfo();
studentInfo.setName("jack");
studentInfo.setAge(12);
studentInfo.setHabits(new String[]{"sleep", "football", "basketball"});
Hessian2Output out = new Hessian2Output(new FileOutputStream(tempFile));
out.writeObject(studentInfo);
out.flush();
System.out.println("----------------------------end");
}
结果:
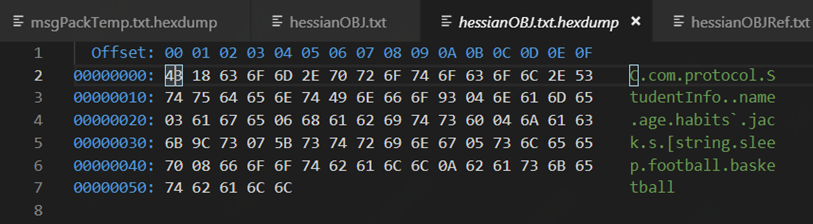
分析:

编码结果上看:对象的全描述,编码传输报文比较大,可以根据编码直接得到全量信息;
常见协议(protocolbuffer)
protocolbuffer 编码后的数据没有任何属性的描述信息,它是依赖.proto文件对数据序列化与反序列化处理。
它将结构化数据按一定的编码规范转换为指定格式,protobuf使用的是Base 128 Varints的编码方式,
Varints是一种使用可变字节序列化整型的方法。
1 . 每个Byte的最高位(msb)是标志位,如果该位为1,表示该Byte后面还有其它Byte,如果该位为0,表示该
Byte是最后一个Byte
2 . 每个Byte的低7位是用来存数值的位
3 . Varints方法用Litte-Endian(小端)字节序
Protocol Buffer 编码机制
field_number:指的是 proto文件中 属性的唯一标示;后面例子中 name = 2, 2 即是field_number。
wire_type:为proto支持的类型。

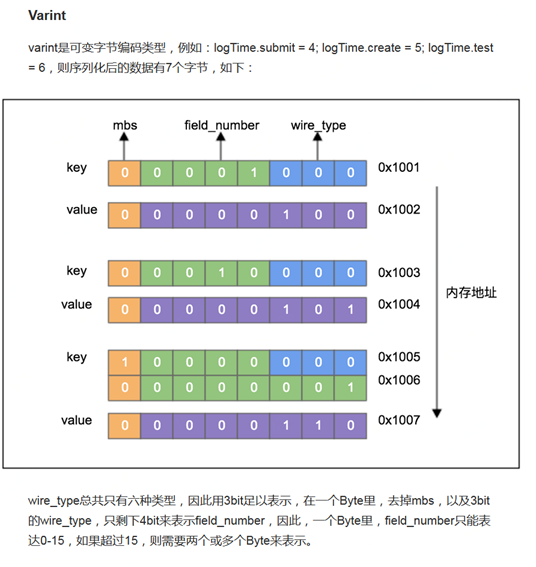
举个例子:
syntax = "proto3";
message Student {
// 姓名
string name = 2;
// 年龄
int32 age = 3;
// 习惯(集合)
repeated string habits = 4;
}

@Test
public void init() throws Exception {
StudentMsg.Student.Builder builder = StudentMsg.Student.newBuilder();
builder.setName("jack");
builder.setAge(12);
builder.addHabits("sleep");
builder.addHabits("football");
builder.addHabits("basketball");
StudentMsg.Student student = builder.build();
byte[] packet = student.toByteArray();
File file = new File("D:/pbOBJ.txt");
FileOutputStream fileOutputStream = new FileOutputStream(file);
fileOutputStream.write(packet);
fileOutputStream.flush();
fileOutputStream.close();
System.out.println("----------------------------end");
}
结果:

分析:

常见协议(协议小结)
messagePack:“无描述型” 编码方式,按照顺序将字段与数据进行编码描述;
(理论上编码数据后的长度 最小)
编码形式:类型(长度) + 数据
Hessian :“全描述型”编码方式,针对对象、属性及属性值进行编码描述,
重复的值会使用 ref 索引优化。(理论上编码数据后的长度 最大)
编码形式:对象描述+属性描述+属性值(类型、长度)+数据
protocolbuffer:“半描述型”编码方式,描述文件独立存在,编码时使用更小空间
将数据与描述文件关联上。( messagePack < 编码数据后的长度 < hessian )
编码形式:坐标(属性坐标+类型)+长度+数据
性能分析对比
测试前提:
相同的本地环境,针对相同的数据进行一千万次编码与解码操作。
执行多次,随机取了一次的值如下:
测试数据:StudentInfo对象
属性 Name: jack
属性 Age:12
属性 Habits :["sleep", "basketball", "football"]
ProtocolBuffer 编码耗时:4 002ms
ProtocolBuffer 解码耗时:3 762ms
Hessian 编码耗时:20 568 ms
Hessian 解码耗时:10 726 ms
MessagePack 编码耗时:11 992 ms
MessagePack 解码耗时:13 442 ms
相关代码详见:https://github.com/dehuiliu/protocol-demo
其它
1,从性能上看,protocolbuffer具有绝对优势;但是需要使用proto文件,增加学习成本
以及后续的维护成本。
2,hessian对类全描述,将对象描述及对象的值都进行编码,可移植行更好,跨平台
跨语言也更好。
3,从传输报文大小上考虑,messagepack是最小的传输,但基于这种编码方式,只能
按照顺序去解码并且性能不如protocolbuffer。
4,从可读性看,以上任何一种编码协议,都不如json的可读性好。
一点小小的思考:
1,流行的编码协议各具特色,但也大同小异,满足一般的业务场景 任何一种编码协议
均足以支持。
2,具体业务场景具体分析,选择应用最合适的协议。
3,接触编码协议另一个感触就是:要充分利用计算机空间,充分利用每一字节和每一
位。(例如:应用大内存k-v存储时, key及value的合理设计,会极大节省内存空间)














 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









