






一、学习动机
伴随互联网行业的兴起,越来越多的领域需要相应的技术方案,比如:打出软件、电商平台、直播平台、电子支付、媒体社交。
身边常见的,校园出成绩那一年,我们会感觉网站异常的卡顿,因为访问人数太多。
单机单点的数据库,一旦这台机子宕机(机器出现故障、机房停电、...),那整个网站将无法正常访问。这时候集群就出现了,一台机器出现问题了,另外的机器还在正常运行,网站依旧可以访问。
集群案例:滴滴出行、淘宝、京东、斗鱼直播、支付宝、微信、QQ
二、案例
1.天猫双十一
2017年天猫双十一的交易额达到1682亿元,3分钟破百亿,9小时破千亿
交易峰值(下订单的峰值):32.5万/秒
支付峰值:25.6万/秒
数据库峰值:4200万/秒
支持这么漂亮的数字完美运行,除了数据库集群技术还有云服务器、负载均衡、RDS云数据库等技术
2.微信红包
2017年除夕当天,全国人民总共收发142亿个红包,峰值42万/秒
央视春晚微信摇一摇互动总量达110万亿次,峰值8.1亿/秒
三、学习目标和方式
1.学习目标:
1)向大型互联网应用看起,学习架构设计和业务处理
2)掌握PXC集群MySQL方案的原理
3)掌握PXC集群的强一致性
4)掌握PXC集群的高可用方案
2.学习方式:由浅入深,循序渐进;案例有小到大,逐步扩展
四、硬件环境需求
1.win10 x64专业版或者企业版(PXC不支持windows,需要用到虚拟机,所以最好不要使用home版或者32位的系统)/Linux/MacOS
2.Docker虚拟机
3.内存8GB以上
五、单节点数据库的弊端
1.大型互联网程序用户群里庞大,所以架构必须要特殊设计
2.单节点的数据库无法满足性能上的要求,就像校园网查成绩的时候,如果1万人同时查,你可能拿到就是一个白屏,无论你是收费的还是免费的数据库,单节点都满足不了这种并发需求
3.单节点的数据库没有冗余设计,无法满足高可用,一旦这个机器出现问题,没有其他节点的数据库顶替,那网站将无法正常访问
单节点数据库测试,5000个连接,5000个并发查询,平均就1个连接1个查询,安装好数据库,配置好环境变量,[mysqld]下面配置最大连接量为6000(max_connections=6000),执行下面的命令:
mysqlslap -hlocalhost -uroot -pabc123456 -P3306 --concurrency=5000 --iterations=1 --auto-generate-sql --auto-generate-sql-load-type=mixed --auto-generate-sql-add-autoincrement --engine=innodb --number-of-queries=5000
得到下面的结论:
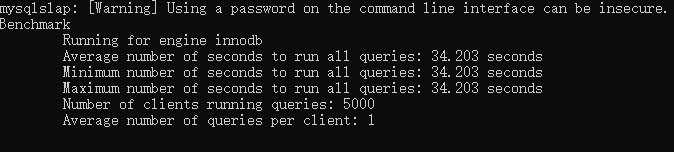
这才5000个并发,需要的时间就达到了34秒,如果设置10000个并发,将如何呢?

数据库拒绝了很多请求,把没有拒绝的执行了,需要的时间是167秒,这就是单击单点在面对并发的时候数据库的承受能力。
六、PXC高可用集群方案

这样一个最基本的PXC集群,它保证了每个节点的的数据都是一致的,不会出现数据写入了数据库1而没有写入数据库2的情况,这种的集群在遇到单表数据量超过2000万的时候,mysql性能会受损,所以一个集群还不够,我们需要把数据分到另一个集群,这个称为“切片”,就是把大量的数据拆分到不同的集群中,每个集群的数据都是不一样的,看下面的截图:

这样一来,PXC集群1存前面1000万条数据,PXC集群2存后面1000万条数据,当一个sql语句请求的时候,通过MyCat这个阿里巴巴的开源中间件,可以把sql分到不同的集群里面去。这种的分片按照数量就是2个分片。
这个切分算法也比较多,比如按照日期、月份、年份、某一列的固定值,或者最简单的按照主键值切分,主键对2求模,余0的存分片1,余1的存分片2,这样MyCat就会把2000万条数据均匀地分配到2个集群上。
PXC虽然保证了数据的强一致性,但是这是以牺牲性能为代价的,所以适合保存重要的数据,比如订单。
七、Replication集群方案

这种集群,在第一个节点插入以后,就马上返回给客户端执行成功了,然后再做每个节点之间的同步,如果某一个同步操作失败了,那用户请求的时候拿到的数据就不同步了,但是它的优势是速度快,不会牺牲任何地性能,适合保存不那么重要的数据,比如日志。
八、PXC与Replication集群结合

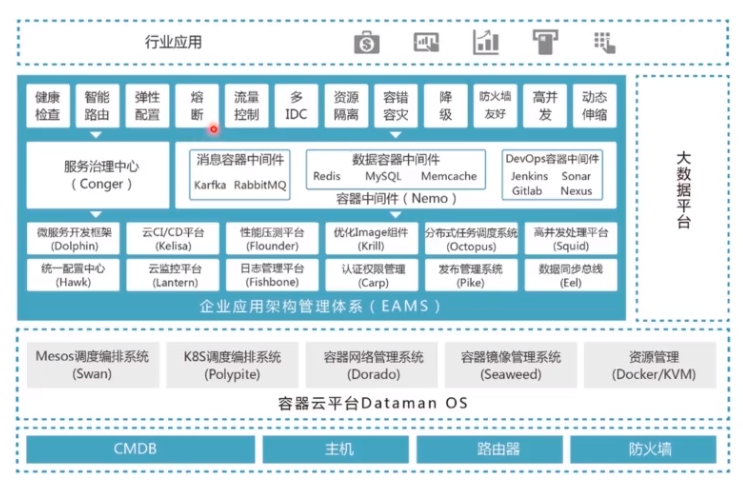
九、系统架构方案

更加清晰和详细架构请看下面的截图
十、APP的架构设计
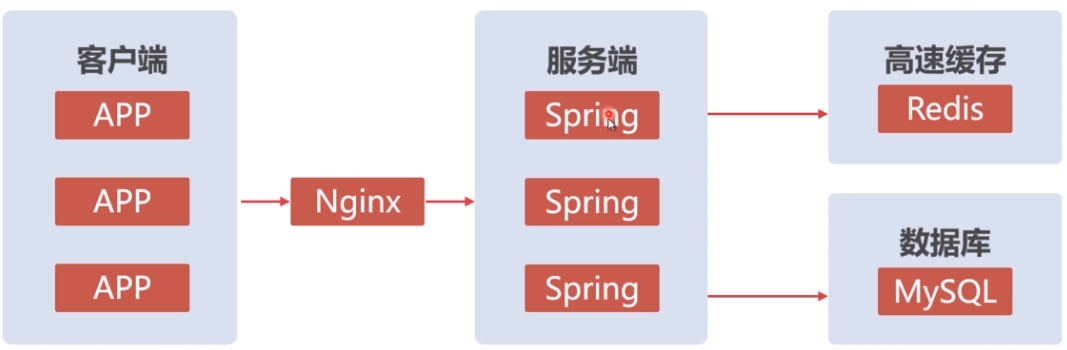
客户端包括web浏览器端,移动手机端,用户通过客户端发送一个请求后,Nginx接收到请求后,会做负载均衡,定向到当前最适合(相对没那么繁忙)处理这个请求的服务器端,服务端接收到请求后,再访问数据库,一些热点数据需要做缓存,比如淘宝首页的商品。从上面的图中看,服务器端的某一个出现故障后,nginx会将请求定向到剩下的能正常运行的服务器上面,而数据库端也是采用的集群,这样就达到了高可用,就是任意一台机器出现故障,对整个网站的运行不会产生太大的影响,这里可能有人会问如果nginx这台服务器出现问题了怎么办?可以做虚拟ip(vip),配置主从入口,就是nginx1和nginx2的虚拟ip是一样的,其中有一个是主入口,在主入口没有出现问题的时候,从机是不会工作的,当主入口机出现问题了,从入口机就会顶替,如果主从都出现问题了,那网站将无法访问。
服务器端的spring与spring之间的调用又是如何的?现在都是分布式调用,比较经典的是dubbo+zookeeper。这里有同步调用和异步调用
同步调用:提出问题的一方直接调用处理问题的一方
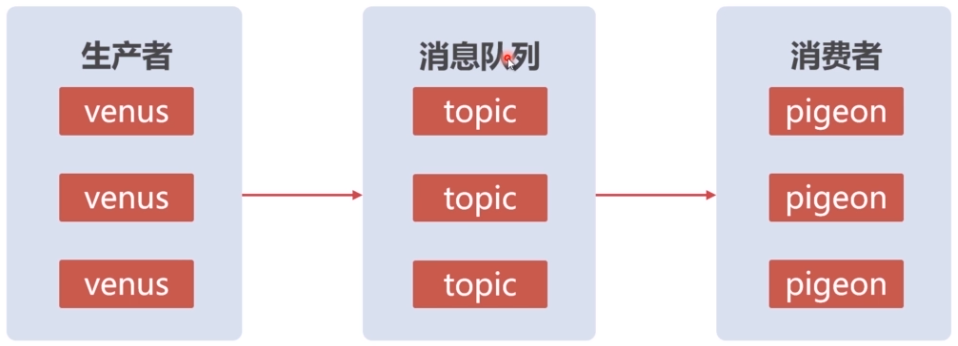
异步调用:提出问题的一方将问题交个消息中间件,由消息中间件去将问题发放给处理问题的一方,在这里,提出问题的一方称为“生产者”,处理问题的一方称为“消费者”,他们彼此是不知道对方是谁,达到业务解耦的效果,这样做的好处是以后在部署项目、程序的升级、接口的变更的时候,它的影响面就很小。比如说生产者项目开发地有问题,然后用其他语言再做了一个项目,对消费者不会产生任何影响,只要生产生能正常往消息队列里面发送消息就好;再比如用户注册一个淘宝账号,我们连带着把支付宝账号也给你开通,然后其他的投资的项目也给用户一些优惠(给你2张淘票票的电影票,免费一个月的虾米音乐会员等等),对应淘宝这一端,它发起一个消息传达给消息队列,至于接收端是支付宝还是淘票票还是虾米音乐,淘宝这一端不知道也不需要关心,等以后阿里再有什么投资项目需要给新用户优惠的时候,只需要从消息队列里接收消息就可以,对生产者而言,没有任何影响。如果是同步调用(dubbo或者webservice调用),其中一端有修改,另一端必然也要改,这种强耦合是不好的。
以下是异步调用方案图:














 3094
3094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









