






写在前面
为什么坚持?想一想当初;
一、面向对象进阶
- 1.反射补充
- 通过字符串去操作一个对象的属性,称之为反射;
- 示例1:
class Chinese:
def __init__(self,name):
self.name=name
p = Chinese('standby') # 实例化一个对象
print(p) # 打印这个对象
---
<__main__.Chinese object at 0x0000000000B3A978>
- 示例2:
>>> l = list([1,2,3]) # 示例话一个对象(list 也是一个类)
>>> print(l) # 打印这个对象,显然和示例1的对象结果不一样;显然是list类对这个对象l做了手脚
[1, 2, 3]
>>>
- 示例3:__str__ 函数必须有返回值,且必须返回字符串类型;
class Chinese:
def __init__(self,name):
self.name=name
def __str__(self): # 在示例1的基础上,重写 __str__ 函数,实现和示例2同样的效果;
return self.name
p = Chinese('standby')
print(p)
---
standby- 2.__setattr__,__delattr__,__getattr__
__setattr__,__delattr__,__getattr__ # 这些函数默认都是有的,自己可以重写; 本质都是直接操作 obj.__dict__
__setattr__ # 添加/修改属性会触发它的执行
__delattr__ # 删除属性的时候触发执行
__getattr__ # 只有在使用点调用属性且属性不存在的时候才会触发
obj.attr '.' 就会触发 __setattr__,__delattr__,__getattr__ 这些函数的执行- 示例1:__setattr__ 和 __delattr__
1 class Foo: 2 def __init__(self,value): 3 self.x = value # 等价于 self.__dict__['x'] = value 4 def __setattr__(self, key, value): 5 print('----> from setattr') 6 # self.key=value # 这就无限递归了!!! 7 # self.__dict__[key]=value #应该使用它 8 self.__dict__[key] = value # 本质上: f.__dict__['x'] = 100,即给f这个对象设置了属性值; 9 def __getattr__(self, item): 10 print('++++> from getattr') 11 def __delattr__(self, item): 12 print('====> from delattr') 13 self.__dict__.pop(item) 14 15 f = Foo(100) # 本质上就是在执行:Foo.__init__(f,100),然后执行里面的赋值语句:f.x = 100;设置了属性x的值,所以会自动调用 __setattr__函数 16 print('-------->>>') 17 print(f.__dict__) # 查看对象f的属性字典 18 del f.x # 删除f的x属性,这一步触发了 __delattr__函数,然后执行了 f.__dict__.pop('x') 19 print(f.__dict__) # 查看删除后的属性字典 20 f.y = 'hello' # 给对象 f 设置新的属性,触发了 __setattr__函数 21 f.z = 99 # 同上 22 print(f.__dict__) # 在查看对象f的属性字典 23 24 ---结果:--- 25 ----> from setattr 26 -------->>> 27 {'x': 100} 28 ====> from delattr 29 {} 30 ----> from setattr 31 ----> from setattr 32 {'z': 99, 'y': 'hello'}
- 示例2:__getattr__
1 class Foo: 2 def __init__(self,value): 3 self.x = value # 等价于 self.__dict__['x'] = value 4 def __setattr__(self, key, value): 5 print('----> from setattr') 6 # self.key=value #这就无限递归了,你好好想想 7 # self.__dict__[key]=value #应该使用它 8 self.__dict__[key] = value 9 def __getattr__(self, item): 10 print('++++> from getattr') 11 def __delattr__(self, item): 12 print('====> from delattr') 13 self.__dict__.pop(item) 14 15 f = Foo(100) 16 print(f.__dict__) # 查看对象 f 的属性字典 17 num = f.y # 调用对象f的y属性,实际上是没有这个属性,所以触发了 __getattr__ 函数的执行; 18 19 ---结果--- 20 ----> from setattr 21 {'x': 100} 22 ++++> from getattr
- 3.__setitem__,__getitem__,__delitem__
- 按照字典的 key-value 方式进行操作;
- 应用:把对对象属性操作的方法和字典类对象的操作统一起来,做一个统一的接口;
- 示例1:
1 class Foo: 2 def __init__(self,name): 3 self.name = name 4 5 f = Foo('standby') 6 print(f.name) 7 # print(f['name']) # 这么调用会报错:TypeError: 'Foo' object is not subscriptable
- 示例2: __getitem__
1 class Foo: 2 def __init__(self,name): 3 self.name = name 4 def __getitem__(self, item): 5 print('__getitem__ is called.') 6 return self.__dict__[item] 7 f = Foo('standby') 8 print(f.name) # 直接打印 standby 9 print(f['name']) # 触发了 __getitem__ 函数的执行 10 11 --- 12 standby 13 __getitem__ is called. 14 standby
- 示例3:__setitem__ 和 __delitem__
1 class Foo: 2 def __init__(self,name,age): 3 self.name = name 4 self.age = age 5 def __setitem__(self, key, value): 6 print('__setitem__ is called.') 7 self.__dict__[key] = value 8 def __delitem__(self, key): 9 print('__delitem__ is called.') 10 self.__dict__.pop(key) 11 def __delattr__(self, item): 12 print('__delattr__ is called.') 13 self.__dict__.pop(item) 14 15 f = Foo('standby',18) # 实例化一个对象 16 print(f.__dict__) 17 f.name = 'standby666' # 通过 'obj.attr' 的方式设置对象的name属性 18 print(f.__dict__) 19 f['name'] = 'liulixin' # 通过字典的方式设置对象的name属性,触发了 __setitem__ 函数的执行 20 print(f.__dict__) 21 del f.age # 触发了 __delattr__ 函数的执行 22 print(f.__dict__) 23 del f['name'] # 通过字典的形式删除属性,触发了 __delitem__函数的执行 24 print(f.__dict__) 25 26 --- 27 {'name': 'standby', 'age': 18} 28 {'name': 'standby666', 'age': 18} 29 __setitem__ is called. 30 {'name': 'liulixin', 'age': 18} 31 __delattr__ is called. 32 {'name': 'liulixin'} 33 __delitem__ is called. 34 {}
- 应用:做成统一接口
1 # 不用 __setitem__ 的情况 2 class Foo: 3 def __init__(self,name): 4 self.name = name 5 def __setitem__(self, key, value): 6 print('__setitem__ is called.') 7 self.__dict__[key] = value 8 f = Foo('standby') 9 10 # 没有 __setitem__ 方法的话,就得这样写: 11 def func(obj,key,value): 12 if isinstance(obj,dict): 13 obj[key] = value 14 else: 15 setattr(obj,key,value) 16 print(f.__dict__) 17 func(f,'name','liulixin') 18 print(f.__dict__) 19 20 --- 21 {'name': 'standby'} 22 {'name': 'liulixin'}
1 # 用 __setitem__ 的情况 2 class Foo: 3 def __init__(self,name): 4 self.name = name 5 def __setitem__(self, key, value): 6 print('__setitem__ is called.') 7 self.__dict__[key] = value 8 f = Foo('standby') 9 10 # 有 __setitem__ 方法,就可以统一成如下接口: 11 def func(obj,key,value): 12 obj[key] = value 13 print(f.__dict__) 14 func(f,'name','liulixin') 15 print(f.__dict__) 16 17 --- 18 {'name': 'standby'} 19 __setitem__ is called. 20 {'name': 'liulixin'}
- 4.二次加工标准类(包装)
- 利用类的继承和派生实现
python为大家提供了标准数据类型,以及丰富的内置方法;
其实在很多场景下我们都需要基于标准数据类型来定制我们自己的数据类型,新增/改写方法;
这就用到了我们刚学的继承/派生知识(其他的标准类型均可以通过下面的方式进行二次加工)- 示例:列表类的继承与派生
1 # 重写一个List类,继承了原来的 list类 2 class List(list): 3 def __init__(self,item,flag=False): 4 super().__init__(item) 5 self.flag = flag 6 # 重写了list的 append函数,要去在append前判断元素类型,只有是str才可以append 7 def append(self,item): 8 if not isinstance(item,str): 9 raise TypeError('%s must be str' % item) 10 # super().append(item) 11 super().append(item) 12 # 返回列表的中间元素 13 @property 14 def mid(self): 15 mid_index = len(self)//2 16 return self[mid_index] 17 # 清空列表,操作之前需要判断权限标识位:flag 18 def clear(self): 19 if not self.flag: 20 raise PermissionError('Permission Deny!') 21 super().clear() 22 self.flag = False 23 24 l = List([1,2,3,]) 25 print(l) 26 # l.append(9) # 报错:TypeError: 9 must be str 27 l.append('hello') # 派生 28 print(l) 29 l.insert(0,7777) # 继承原来list的insert方法 30 print(l) 31 print(l.mid) # 调用property 32 # l.clear() # 报错:PermissionError: Permission Deny! 33 l.flag = True 34 l.clear() # 派生 35 print(l) 36 37 ---结果--- 38 [1, 2, 3] 39 [1, 2, 3, 'hello'] 40 [7777, 1, 2, 3, 'hello'] 41 2 42 []
- 授权方式(函数)实现
授权是包装的一个特性, 包装一个类型通常是对已存在的类型的一些定制;
这种做法可以新建、修改或删除原有产品的功能,其它的则保持原样。
应用:针对某些功能不是类,例如 open(),是一个函数,而不是类:
如果要定制自己的open()函数,就不能用继承的方式了;
授权的过程:
即是所有更新的功能都是由新类的某部分来处理;
但已存在的功能就授权给对象的默认属性;
实现授权的关键点就是覆盖__getattr__方法- 示例:open函数的授权,关键在与 __getattr__函数的实现;
1 import time 2 class Open(): 3 def __init__(self,filepath,mode='r',encoding='utf-8'): 4 self.filepath = filepath 5 self.mode = mode 6 self.encoding = encoding 7 # 本质上还是调用原来的 open()函数打开文件 8 self.f = open(self.filepath,mode=self.mode,encoding=self.encoding) 9 # 这里,我们重写了write函数,在写入的内容前加上了操作的时间 10 def write(self,msg): 11 t = time.strftime('%Y-%m-%d %X') 12 self.f.write('%s : %s' % (t,msg)) 13 # 找不到 attr 就会执行 __getattr__函数 14 # 利用这个特性,拿到 self.f.item (read、close、seek...) 15 def __getattr__(self, item): 16 print('--->>> %s' % item) 17 return getattr(self.f,item) 18 obj = Open(r'1.txt',mode='w+',encoding='utf-8') 19 obj.write('11111\n') 20 obj.write('aaa\n') 21 obj.write('+++1213\n') 22 obj.seek(0) # Open类里没有重写seek,read以及close函数,所以在通过 'obj.attr' 方式调用的时候,就会触发 __getattr__函数; 23 res = obj.read() # getattr(self.f,item) 即调用了真是的open函数的句柄: obj.f.read() 24 print(res) 25 print('----------------->>>') 26 print(type(obj),obj) # obj 是 Open类的对象 27 print(type(obj.f),obj.f) # obj.f 才是文件句柄,即原来的open()的对象 28 obj.close() # obj.f.close() 29 30 ---结果--- 31 --->>> seek 32 --->>> read 33 2017-06-20 22:48:06 : 11111 34 2017-06-20 22:48:06 : aaa 35 2017-06-20 22:48:06 : +++1213 36 37 ----------------->>> 38 <class '__main__.Open'> <__main__.Open object at 0x00000000010824E0> 39 <class '_io.TextIOWrapper'> <_io.TextIOWrapper name='1.txt' mode='w+' encoding='utf-8'> 40 --->>> close
- 5.__str__,__repr__,__format__
str函数或者print函数--->obj.__str__()
repr或者交互式解释器--->obj.__repr__()
如果__str__没有被定义,那么就会使用__repr__来代替输出
注意:这俩方法的返回值必须是字符串,否则抛出异常;- __str__ 和 __repr__
- 改变对象的字符串显示;
- 示例1:没有定义 __str__,定义了 __repr__,则会用 __repr__来代替输出
1 class School: 2 def __init__(self,name,addr,type): 3 self.name=name 4 self.addr=addr 5 self.type=type 6 def __repr__(self): 7 return 'School(%s,%s)' %(self.name,self.addr) 8 s1=School('Peking University','北京','公立') 9 print('from repr: ',repr(s1)) 10 print('from str: ',str(s1)) 11 print(s1) 12 13 --- 14 from repr: School(Peking University,北京) 15 from str: School(Peking University,北京) 16 School(Peking University,北京)
- 示例2:__str__ 和 __repr__ 都定义了的情况
1 class School: 2 def __init__(self,name,addr,type): 3 self.name=name 4 self.addr=addr 5 self.type=type 6 def __repr__(self): 7 return 'School(%s,%s)' %(self.name,self.addr) 8 def __str__(self): 9 return '(%s,%s)' %(self.name,self.addr) 10 11 s1=School('Peking University','北京','公立') 12 print('from repr: ',repr(s1)) # 触发 __repr__ 13 print('from str: ',str(s1)) # 触发 __str__ 14 print(s1) # 触发 __str__ 15 16 --- 17 from repr: School(Peking University,北京) 18 from str: (Peking University,北京) 19 (Peking University,北京)
- __format__
- 自定义格式化字符串;
1 format_dict={ 2 'nat':'{obj.name}-{obj.addr}-{obj.type}',#学校名-学校地址-学校类型 3 'tna':'{obj.type}:{obj.name}:{obj.addr}',#学校类型:学校名:学校地址 4 'tan':'{obj.type}/{obj.addr}/{obj.name}',#学校类型/学校地址/学校名 5 } 6 class School: 7 def __init__(self,name,addr,type): 8 self.name=name 9 self.addr=addr 10 self.type=type 11 def __format__(self, format_spec): 12 if not format_spec or format_spec not in format_dict: 13 format_spec='nat' 14 fmt=format_dict[format_spec] 15 return fmt.format(obj=self) 16 s1=School('Peking University','北京','公立') 17 print(format(s1,'nat')) 18 print(format(s1,'tna')) 19 print(format(s1,'tan')) 20 print(format(s1,'asfdasdffd')) 21 22 --- 23 Peking University-北京-公立 24 公立:Peking University:北京 25 公立/北京/Peking University 26 Peking University-北京-公立
- 6.__next__ 和 __iter__ 实现迭代器协议
重写 __next__ 和 __iter__ 实现迭代器协议
迭代器协议:必须具有 __next__ 和 __iter__
可迭代对象有 __iter__ 方法,执行__iter__方法得到的就是迭代器
- 示例:
1 from collections import Iterator 2 class Foo: 3 def __init__(self,n,end): 4 self.n = n 5 self.end = end 6 def __next__(self): 7 if self.n >= self.end: 8 raise StopIteration # 因为for循环捕捉的就是StopIteration,所以需要在迭代到边界值的时候抛出这个异常; 9 tmp = self.n 10 self.n += 1 11 return tmp 12 def __iter__(self): 13 return self 14 f = Foo(5,10) 15 print(isinstance(f,Iterator)) # 如果Foo类中不写 __iter__ 函数就不是迭代器 16 print(next(f)) # next(f) 等价于 f.__next__() 17 print(next(f)) 18 print('--->') 19 for item in f: # 会捕捉到 StopIteration 异常,如果不加限制会导致无限递归!!! 20 print(item) 21 22 ---结果--- 23 True 24 5 25 6 26 ---> 27 7 28 8 29 9
- 应用:斐波那契数列
class Fibonacci:
def __init__(self):
self._a = 0
self._b = 1
def __iter__(self):
return self
def __next__(self):
self._a,self._b = self._b,self._a + self._b
return self._a
fib = Fibonacci()
for i in fib:
if i > 100:
break
print('%s ' % i, end='')
---结果---
1 1 2 3 5 8 13 21 34 55 89 - 7.__del__ (析构函数)
- 当对象在内存中被释放时,自动触发执行;(关闭到跟对象有关的链接,做一些清理操作)
- 此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行;
- 所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的;
class Foo:
def __init__(self,name,age):
self.name=name
self.age=age
def __del__(self): #析构方法
print('执行了析构函数...')
obj=Foo('egon',18)
del obj.name
print('=============>')
del obj
print('=============>')
---结果---
=============>
执行了析构函数...
=============>- 8.__enter__ 和 __exit__ 实现上下文管理
- 我们知道在操作文件对象的时候可以这么写:
with open('a.txt') as f:
'代码块'
- 上述叫做上下文管理协议,即with语句;
- 为了让一个对象兼容with语句,必须在这个对象的类中声明__enter__和__exit__方法;
- __exit__() 中的三个参数分别代表 异常类型,异常值和追溯信息, with语句中代码块出现异常,则with后的代码都无法执行;
- 示例1:
1 class Foo: 2 def __init__(self, name): 3 self.name = name 4 def __enter__(self): 5 print('__enter__') 6 return self 7 def __exit__(self, exc_type, exc_val, exc_tb): 8 print('__exit__') 9 with Foo('standby') as x: # 出现 with语句,则对象的 __enter__函数被触发,返回值则赋给as声明的变量 10 print(x) 11 print('=>') 12 print('==>') 13 print('===>') # with里的代码块执行完毕,则触发 __exit__函数执行 14 15 --- 16 __enter__ 17 <__main__.Foo object at 0x00000000007334E0> 18 => 19 ==> 20 ===> 21 __exit__
- 示例2: __exit__ 里不加 return True
1 class Open: 2 def __init__(self,name,mode='r',encoding='utf-8'): 3 self.name = name 4 self.mode = mode 5 self.encoding = encoding 6 self.f = open(self.name,mode=self.mode,encoding=self.encoding) 7 def __enter__(self): 8 print('__enter__') 9 return self.f 10 def __exit__(self, exc_type, exc_val, exc_tb): 11 print('__exit__') 12 print(exc_type) 13 print(exc_val) 14 print(exc_tb) 15 self.f.close() 16 with Open('666.txt',mode='w+') as f: 17 print(type(f),f) 18 1/0 19 print('The end.') # 1/0 异常抛出, 导致 with后的代码没有执行; 20 21 --- 22 __enter__ 23 <class '_io.TextIOWrapper'> <_io.TextIOWrapper name='666.txt' mode='w+' encoding='utf-8'> 24 __exit__ 25 <class 'ZeroDivisionError'> 26 division by zero 27 <traceback object at 0x00000000010615C8> 28 Traceback (most recent call last): 29 File "D:/soft/work/Python_17/day08/blog.py", line 301, in <module> 30 1/0 31 ZeroDivisionError: division by zero
- 示例3: __exit__ 末尾有 return True
1 class Open: 2 def __init__(self,name,mode='r',encoding='utf-8'): 3 self.name = name 4 self.mode = mode 5 self.encoding = encoding 6 self.f = open(self.name,mode=self.mode,encoding=self.encoding) 7 def __enter__(self): 8 print('__enter__') 9 return self.f 10 def __exit__(self, exc_type, exc_val, exc_tb): 11 print('__exit__') 12 print(exc_type) 13 print(exc_val) 14 print(exc_tb) 15 self.f.close() 16 return True 17 with Open('666.txt',mode='w+') as f: # Open(...) 触发 __init__的执行, with Open(...) 触发 __enter__的执行 18 print(type(f),f) 19 1/0 # 1/0 抛出异常,但是由于 __exit__末尾 'return True',导致异常被清空了,所以后面的代码都可以照常执行; 20 print('The end.') 21 22 --- 23 __enter__ 24 <class '_io.TextIOWrapper'> <_io.TextIOWrapper name='666.txt' mode='w+' encoding='utf-8'> 25 __exit__ 26 <class 'ZeroDivisionError'> 27 division by zero 28 <traceback object at 0x00000000010925C8> 29 The end.
- 9.__call__
- 对象后面加括号,触发执行对象所属的类的 __call__方法执行(实现对象加括号,变成可调用的);
- 所有的可调用,到最后都要转化成函数(__call__)去运行;
- 构造方法的执行是由创建对象触发的,即:对象 = 类名() ;
- 而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()();
- 示例1:
1 class Foo: 2 def __init__(self): 3 print('Foo.__init__ is called.') 4 print(type(self),self) 5 def __call__(self, *args, **kwargs): 6 print('Foo.__call__ is called.') 7 print(type(self), self) 8 9 print('--->>>') 10 Foo() # 相当于实例化了一个对象 11 print('---+++') 12 Foo()() # 1.Foo()得到一个对象obj 2.obj加括号执行(obj()),触发了__call__函数 13 14 --- 15 --->>> 16 Foo.__init__ is called. 17 <class '__main__.Foo'> <__main__.Foo object at 0x000000000103A898> 18 ---+++ 19 Foo.__init__ is called. 20 <class '__main__.Foo'> <__main__.Foo object at 0x000000000103A898> 21 Foo.__call__ is called. 22 <class '__main__.Foo'> <__main__.Foo object at 0x000000000103A898>
- 示例2:
1 class Foo: 2 def __init__(self): 3 print('Foo.__init__ is called.') 4 print(type(self),self) 5 def __call__(self, *args, **kwargs): 6 print('Foo.__call__ is called.') 7 print(type(self), self) 8 9 obj = Foo() # 执行 Foo.__init__(obj) 10 obj() # 执行 Foo.__call__(obj) 11 print(type(obj),obj) 12 print(type(Foo),Foo) 13 14 --- 15 Foo.__init__ is called. 16 <class '__main__.Foo'> <__main__.Foo object at 0x00000000007CA978> 17 Foo.__call__ is called. 18 <class '__main__.Foo'> <__main__.Foo object at 0x00000000007CA978> 19 <class '__main__.Foo'> <__main__.Foo object at 0x00000000007CA978> 20 <class 'type'> <class '__main__.Foo'>
- 示例3:
1 class Foo: 2 def __call__(self, *args, **kwargs): 3 print('======>') 4 5 obj=Foo() # obj是Foo类实例化得到,是Foo类的对象 6 print('++++++++') 7 obj() # obj(),即 '对象+()' 执行的时候就是触发了其所属的类的 __call__方法的执行; 8 print(type(Foo),Foo) 9 print(type(obj),obj) 10 11 --- 12 ++++++++ 13 ======> 14 <class 'type'> <class '__main__.Foo'> 15 <class '__main__.Foo'> <__main__.Foo object at 0x0000000000B0A940>
- 10.metaclass(元类)
- 1.exec和eval介绍
- 2.创造类的两种方法
- 3.创建类相关的三个方法
- 1.__call__
- 2.__new__
- 3.__init__
- 4.元类(metaclass)
关于元类,就把握一个原则:
A() 找的就是产生A的那个类的 __call__方法
__call__() 做三件事:
1.__new__ 造一个对象
2.__init__ 初始化这个对象
3.返回这个对象
更多细节参见:egon老师面向对象进阶
二、socket网络编程
- 1.网络基础
- 网络基础参见:
http://www.cnblogs.com/linhaifeng/articles/5937962.html
http://linux.vbird.org/linux_server/0110network_basic.php
- 互联网的本质就是一系列的协议;通过这些协议标准,使得不同国家不同种族的人们之间可以相互沟通;
- 互联网协议的功能:定义计算机如何接入internet,以及接入internet的计算机通信的标准;
- 2.socket是什么?
- socket是在应用层和传输层之间的一个抽象层(ip+port);
我们知道两个进程如果需要进行通讯最基本的一个前提能能够唯一的标示一个进程,
在本地进程通讯中我们可以使用PID来唯一标示一个进程,
但PID只在本地唯一,网络中的两个进程PID冲突几率很大,这时候我们需要另辟它径了;
我们知道IP层的ip地址可以唯一标示主机,
而TCP层协议和端口号可以唯一标示主机的一个进程,
这样我们可以利用ip地址+协议+端口号唯一标示网络中的一个进程。
能够唯一标示网络中的进程后,它们就可以利用socket进行通信了;
什么是socket呢?
我们经常把socket翻译为套接字,socket是在应用层和传输层之间的一个抽象层,
它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信。 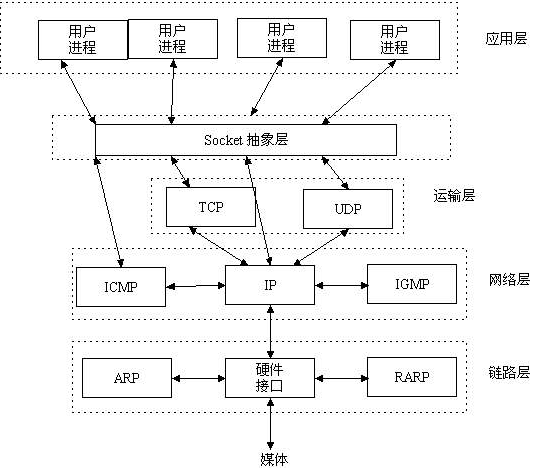
socket起源于UNIX,
在Unix一切皆文件哲学的思想下,socket是一种"打开—读/写—关闭"模式的实现;
服务器和客户端各自维护一个"文件",
在建立连接打开后,可以向自己文件写入内容供对方读取或者读取对方内容,
通讯结束时关闭文件。- 3.socket套接字分类
套接字起源于 20 世纪 70 年代加利福尼亚大学伯克利分校版本的 Unix,即人们所说的 BSD Unix。
因此,有时人们也把套接字称为“伯克利套接字”或“BSD 套接字”。
一开始,套接字被设计用在同 一台主机上多个应用程序之间的通讯。
这也被称进程间通讯,或 IPC。
套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的。
1.基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,
两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
2.基于网络类型的套接字家族
套接字家族的名字:AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现;
所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET)- 4.socket套接字工作流程
- 以使用TCP协议通讯的socket为例:
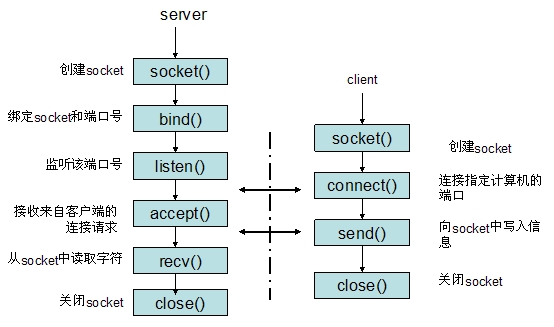
服务器根据地址类型(ipv4,ipv6)、socket类型、协议创建socket
服务器为socket绑定ip地址和端口号
服务器socket监听端口号请求,随时准备接收客户端发来的连接,这时候服务器的socket并没有被打开
客户端创建socket
客户端打开socket,根据服务器ip地址和端口号试图连接服务器socket
服务器socket接收到客户端socket请求,被动打开,开始接收客户端请求,直到客户端返回连接信息。这时候socket进入阻塞状态,所谓阻塞即accept()方法一直到客户端返回连接信息后才返回,开始接收下一个客户端谅解请求
客户端连接成功,向服务器发送连接状态信息
服务器accept方法返回,连接成功
客户端向socket写入信息
服务器读取信息
客户端关闭
服务器端关闭
- 常用方法:
服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字
s.listen() 开始TCP监听
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
s.close() 关闭套接字
面向锁的套接字方法
s.setblocking() 设置套接字的阻塞与非阻塞模式
s.settimeout() 设置阻塞套接字操作的超时时间
s.gettimeout() 得到阻塞套接字操作的超时时间
面向文件的套接字的函数
s.fileno() 套接字的文件描述符
s.makefile() 创建一个与该套接字相关的文件- 5.基于TCP的套接字
tcp服务器端
ss = socket() #创建服务器套接字
ss.bind() #把地址绑定到套接字
ss.listen() #监听链接
inf_loop: #服务器无限循环
cs = ss.accept() #接受客户端链接
comm_loop: #通讯循环
cs.recv()/cs.send() #对话(接收与发送)
cs.close() #关闭客户端套接字
ss.close() #关闭服务器套接字(可选)
tcp客户端
cs = socket() # 创建客户套接字
cs.connect() # 尝试连接服务器
comm_loop: # 通讯循环
cs.send()/cs.recv() # 对话(发送/接收)
cs.close() # 关闭客户套接字
- 6.基于UDP的套接字
参见另一片博客:http://www.cnblogs.com/standby/p/7107519.html
- 7.recv与recvfrom的区别
- 8.粘包的产生和解决办法
- 粘包产生原因
- socket收发消息的原理示意图:
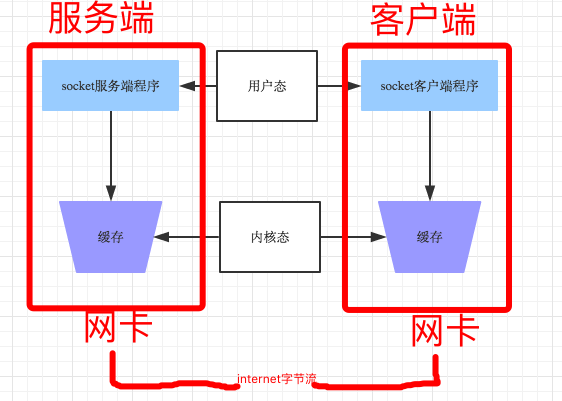
- 粘包原因
发送端可以是一K一K地发送数据,而接收端的应用程序可以两K两K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据;
也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。
而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。
怎样定义消息呢?可以认为对方一次性write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区。
例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
- 扩展
此外,发送方引起的粘包是由TCP协议本身造成的:
TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。
若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据;
1.TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,
因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。
这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
2.UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务,不会使用块的合并优化算法;
由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息);
这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
3.tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住;
而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头;- 1.只有TCP有粘包现象,UDP永远不会粘包;
- 2.所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性应该提取多少字节的数据所造成的;
- 3.TCP是面向连接的、面向流的;面向流的通信是无消息保护边界的;
- 4.UDP是无连接的、面向消息的;面向消息的通讯是有消息保护边界的;
- 两种情况下会产生粘包:
- 发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包);
- 接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包);
- 粘包示例
- Server端
1 #!/usr/bin/python3 2 # -*- coding:utf-8 -*- 3 4 import time 5 import socket 6 import subprocess 7 phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 8 # Address already in use 9 phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) 10 phone.bind(('127.0.0.1',8090)) 11 phone.listen(10) # tcp 半连接池 12 13 while True: 14 print('Starting...') 15 conn,addr = phone.accept() 16 print('conn is %s' % conn) 17 print('addr is:', addr) 18 19 print('Ready to reveice msg...') 20 while True: 21 try: 22 cmd = conn.recv(1024) # 写死每次取1024容易造成粘包现象 23 if not cmd: # for linux platform 24 break 25 t = time.strftime('%Y-%m-%d %X') 26 print('Time: %s\tClient CMD: %s' %(t, cmd.decode('utf-8'))) 27 res = subprocess.Popen(cmd.decode('utf-8'),shell=True, 28 stdout=subprocess.PIPE, 29 stderr=subprocess.PIPE) 30 err = res.stderr.read() 31 if err: 32 cmd_res = err # 如果执行出错,则返回错误信息 33 else: 34 cmd_res = res.stdout.read() # 否则返回执行的结果信息 35 conn.send(cmd_res) 36 except Exception as e: 37 print('Exception: %s' % e) 38 break 39 conn.close() 40 phone.close()
- Client端
1 #!/usr/bin/python3 2 # -*- coding:utf-8 -*- 3 4 import socket 5 6 phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 7 8 phone.connect(('127.0.0.1',8090)) 9 while True: 10 cmd = input('>>>:\t').strip() 11 if not cmd: 12 print('不允许空消息!') 13 continue 14 phone.send(cmd.encode('utf-8')) 15 cmd_res = phone.recv(1024) # 写死每次取1024容易造成粘包现象 16 print('%s Result:\n%s' % (cmd,cmd_res.decode('gbk'))) 17 18 phone.close()
- 粘包解决办法
- Server端
1 #!/usr/bin/python3 2 # -*- coding:utf-8 -*- 3 4 import time 5 import socket 6 import subprocess 7 import json 8 import struct 9 10 phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 11 # Address already in use 12 phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) 13 phone.bind(('10.0.0.9',8080)) 14 phone.listen(5) # tcp 半连接池 15 16 while True: 17 print('Starting...') 18 conn,addr = phone.accept() 19 print('conn is %s' % conn) 20 print('addr is:', addr) 21 print('Ready to reveice msg...') 22 while True: 23 try: 24 cmd = conn.recv(1024) 25 if not cmd: # for linux platform 26 break 27 t = time.strftime('%Y-%m-%d %X') 28 print('Time: %s\tClient CMD: %s' % (t, cmd.decode('utf-8'))) 29 res = subprocess.Popen(cmd.decode('utf-8'),shell=True, 30 stdout=subprocess.PIPE, 31 stderr=subprocess.PIPE) 32 cmd_res = res.stderr.read() 33 if not cmd_res: 34 cmd_res = res.stdout.read() 35 # 自定义数据报头 36 head_dic = {'filename': None, 'hash': None, 'total_size': len(cmd_res)} 37 head_json = json.dumps(head_dic) 38 head_byte = head_json.encode('utf-8') 39 # 先发送数据报头的大小 40 conn.send(struct.pack('i',len(head_byte))) 41 # 再发送数据报头 42 conn.send(head_byte) 43 # 最后发送真实的数据体 44 conn.send(cmd_res) 45 except Exception as e: 46 print('Exception: %s' % e) 47 break 48 conn.close() 49 phone.close()
- Client端
1 #!/usr/bin/python3 2 # -*- coding:utf-8 -*- 3 4 import socket 5 import struct 6 import json 7 8 phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 9 phone.connect(('10.0.0.9',8080)) 10 11 while True: 12 cmd = input('>>>:\t').strip() 13 if not cmd: 14 print('不允许空消息!') 15 continue 16 phone.send(cmd.encode('utf-8')) 17 # cmd_res = phone.recv(1024) # 写死1024会造成粘包现象 18 # 先收报头大小 19 head_struct = phone.recv(4) 20 head_len = struct.unpack('i',head_struct)[0] 21 # 再接收数据报头 22 head_byte = phone.recv(head_len) 23 head_json = head_byte.decode('utf-8') 24 head_dict = json.loads(head_json) 25 # 从head_dict中获取真实的数据的大小 26 total_size = head_dict['total_size'] 27 # 不能一次都接收完,要每次接收一部分,分多次接收 28 reve_size = 0 29 data = b'' 30 while reve_size < total_size: 31 tmp = phone.recv(1024) 32 data += tmp 33 reve_size += len(tmp) 34 print('%s Result:\n%s' % (cmd,data.decode('gbk'))) 35 phone.close()
- 不足:
经过在CentOS-6.6上测试存在几个问题:
1.在客户端执行查看大文件的时候会卡死(客户端+服务端),例如执行: cat /etc/services
2.不支持并发接收用户请求并处理
- 需要注意的几点:
1.需要关闭CentOS上的 getenforce
2.需要关闭iptables,或者插入一条过滤规则:
iptables -I INPUT -s 10.0.0.0/8 -p tcp --dport 8080 -j ACCEPT
3.如果出现这个错误:OSError: [Errno 98] Address already in use
需要在 bind() 操作前加入一行代码:
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
4.在Linux平台上,针对用户的输入要进行非空判断(在客户端/服务端判断):
if not cmd: # for linux platform
break
如果不判断会造成卡死状态
5.subprocess执行命令相关细节很重要!
6.struct.pack() 和 struct.unpack() 的使用很重要;
7.报文头字典的定义要合理- 9.认证客户端的链接合法性
- 10.socketserver实现并发
- 扩展:
- tcp半链接池
tcp 半连接池,挂起几个链接;
如果同时有多个请求链接过来,但是服务端不能同时都服务;
服务端把暂时不能服务的连接挂起,到半连接池;- tcp保活机制
双方建立交互的连接,但是并不是一直存在数据交互;
有些连接会在数据交互完毕后,主动释放连接,而有些不会;
那么在长时间无数据交互的时间段内,交互双方都有可能出现掉电、死机、异常重启等各种意外;
当这些意外发生之后,这些TCP连接并未来得及正常释放,
那么,连接的另一方并不知道对端的情况,它会一直维护这个连接;
长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,
为了解决这个问题,在传输层可以利用TCP的保活报文来实现。- struct
- struc.pack
- struct.unpack
- attr 和 item 一些用法
- 创建类的三要素
# 1 类名
# 2 继承的父类
# 3 类体
三、练习
要求:

代码实现:


1 ftp 2 │ config.py 3 │ ftp_server.py 4 │ readme.txt 5 │ run.py 6 │ user.py 7 │ 8 ├─accounts 9 │ ├─egon 10 │ │ .pwd 11 │ │ 1.txt 12 │ │ a.txt 13 │ │ 14 │ ├─liu 15 │ │ .pwd 16 │ │ 1.txt 17 │ │ a.txt 18 │ │ b.txt 19 │ │ haha.py 20 │ │ haha1.py 21 │ │ 22 │ └─standby 23 │ .pwd 24 │ a.txt 25 │ 26 └─public 27 1.txt 28 123.txt 29 666.txt 30 a.txt 31 b.txt 32 haha.py
1 #!/usr/bin/python 2 # -*- coding:utf-8 -*- 3 4 PWD_FILE = '.pwd' 5 BASE_DIR = r"D:\soft\work\Python_17\day08\homework\accounts" 6 PUBLIC_DIR = r"D:\soft\work\Python_17\day08\homework\public" 7 DONE = b'file_send_done' 8 PUT_OK = b'PUT_OK' 9 PUT_ERR = b'PUT_ERR' 10 TOTAL_AVAILABLE_SIZE = 1000000 11 12 INFO = """ 13 ======================= 14 Welcome to ftp system 15 1.Login. 16 2.Register new account. 17 ======================= 18 """ 19 FTP_INFO = """ 20 1.List all the file you possessed. 21 2.Show available space. 22 3.List all public file. 23 4.Get/Put one file. 24 """
1 #!/usr/bin/python 2 # -*- coding:utf-8 -*- 3 4 import os,pickle 5 from config import * 6 7 class User(): 8 def __init__(self,name,passwd,capacity): 9 self.name = name 10 self.passwd = passwd 11 self.capacity = capacity 12 def save(self): 13 user_path = r"%s%s%s" % (BASE_DIR,os.sep,self.name) 14 os.mkdir(user_path,700) 15 pwd_file = r"%s%s%s" % (user_path, os.sep, PWD_FILE) 16 pickle.dump(self, open(pwd_file, 'wb')) 17 def show_all_file(self): 18 file_list = os.listdir(r"%s%s%s" % (BASE_DIR, os.sep, self.name)) 19 print('\n%s have files below:' % self.name) 20 for file in file_list: 21 if file.startswith('.'): 22 continue 23 print(file) 24 # 获取用户家目录可用空间大小(单位是字节 byte) 25 @property 26 def available_space(self): 27 used_size = 0 28 path = r"%s%s%s%s" % (BASE_DIR,os.sep,self.name,os.sep) 29 try: 30 filename = os.walk(path) 31 for root, dirs, files in filename: 32 for fle in files: 33 size = os.path.getsize(path + fle) 34 used_size += size 35 return int(self.capacity) - used_size 36 except Exception as err: 37 print(err)
- FTP Server 端
#!/usr/bin/python
# -*- coding:utf-8 -*-
import os,time,socket,json,struct,hashlib
from config import *
class Ftp_Server:
def __init__(self,ip,port):
self.ip = ip
self.port = port
@staticmethod
def get(conn,filename):
print('Start to download the %s' % filename)
public_file_list = Ftp_Server.get_all_public_file()
# 判断文件是否存在
if filename not in public_file_list:
print("%s does't exist, exit." % filename)
file_dict = {
'flag': False,
'filename': filename,
'hash_value': None,
'file_total_size': None
}
file_json = json.dumps(file_dict)
file_byte = file_json.encode('utf-8')
conn.send(struct.pack('i', len(file_byte)))
conn.send(file_byte)
return
# 先传输文件的属性:文件大小、文件hash值;
file_total_size = os.path.getsize(r'%s%s%s' % (PUBLIC_DIR,os.sep,filename))
with open(r'%s%s%s' % (PUBLIC_DIR,os.sep,filename),mode='rb') as rf:
md5_obj = hashlib.md5()
md5_obj.update(rf.read())
file_hash = md5_obj.hexdigest()
file_dict = {
'flag': True,
'filename': filename,
'hash_value': file_hash,
'file_total_size': file_total_size
}
file_json = json.dumps(file_dict)
file_byte = file_json.encode('utf-8')
conn.send(struct.pack('i', len(file_byte)))
conn.send(file_byte)
# 开始传输真正的文件内容
with open(r'%s%s%s' % (PUBLIC_DIR,os.sep,filename),mode='rb') as rf:
while True:
data = rf.read(100)
if not data:
time.sleep(0.1)
conn.send(DONE)
break
else:
conn.send(data)
# print('>>>>>>>>>>>>>>>>>>>>>>>>>>>')
print('data send done')
@staticmethod
def put(conn,filename):
print('Start to upload the %s' % filename)
# 接收 file_struct + file_dict
file_struct = conn.recv(4)
file_len = struct.unpack('i', file_struct)[0]
file_byte = conn.recv(file_len)
file_json = file_byte.decode('utf-8')
file_dict = json.loads(file_json)
# 循环接收 file_byte 并写入到文件
with open(r'%s%s%s' % (PUBLIC_DIR,os.sep,filename), mode='wb') as wf:
data = conn.recv(100)
while True:
# print(data)
if DONE == data:
break
wf.write(data)
data = conn.recv(100)
# 获取并比较文件大小和md5值
recv_file_total_size = os.path.getsize(r'%s%s%s' % (PUBLIC_DIR,os.sep,filename))
with open(r'%s%s%s' % (PUBLIC_DIR,os.sep,filename), mode='rb') as rf:
md5_obj = hashlib.md5()
md5_obj.update(rf.read())
recv_file_hash = md5_obj.hexdigest()
if recv_file_hash == file_dict['hash_value'] and recv_file_total_size == file_dict['file_total_size']:
conn.send(PUT_OK)
else:
conn.send(PUT_ERR)
print('%s %s done.' % (input_list[0], input_list[1]))
@classmethod
def get_all_public_file(cla):
return os.listdir(PUBLIC_DIR)
def start(self):
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# Address already in use
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind((self.ip, self.port))
phone.listen(5) # tcp 半连接池
while True:
print('Starting...')
conn,addr = phone.accept()
print('conn is %s' % conn)
print('addr is:', addr)
print('Ready to reveice cmd...')
while True:
try:
cmd_struct = conn.recv(4)
cmd_len = struct.unpack('i', cmd_struct)[0]
cmd_byte = conn.recv(cmd_len)
cmd_json = cmd_byte.decode('utf-8')
cmd_dict = json.loads(cmd_json)
t = time.strftime('%Y-%m-%d %X')
print('User: %s\tTime: %s\tCMD: %s' % (cmd_dict['user'], t, cmd_dict['cmd']+" "+cmd_dict['filename']))
# 反射到Ftp_Server的get/put方法
func = getattr(Ftp_Server, cmd_dict['cmd'])
func(conn,cmd_dict['filename'])
except Exception as e:
print('Exception: %s' % e)
break
conn.close()
phone.close()
if __name__ == '__main__':
ftp_server = Ftp_Server('127.0.0.1', 8095)
ftp_server.start()
- Client端
#!/usr/bin/python
# -*- coding:utf-8 -*-
import os,sys,time,pickle,getpass,json,struct,socket,hashlib
from config import *
from user import User
from ftp_server import *
def client_to_run(user_obj, input_list):
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
phone.connect(('127.0.0.1', 8095))
cmd_dict = {
'user':user_obj.name,
'cmd':input_list[0],
'filename':input_list[1]
}
cmd_json = json.dumps(cmd_dict)
cmd_byte = cmd_json.encode('utf-8')
phone.send(struct.pack('i', len(cmd_byte)))
phone.send(cmd_byte)
# 从公共目录下载文件到自己的家目录
if 'get' == input_list[0].lower():
# 接收 file_struct + file_dict
file_struct = phone.recv(4)
file_len = struct.unpack('i', file_struct)[0]
file_byte = phone.recv(file_len)
file_json = file_byte.decode('utf-8')
file_dict = json.loads(file_json)
# 判断文件是否存在
if not file_dict['flag']:
print("%s does't exist, exit." % file_dict['filename'])
return
# 判断用户家目录可用空间是否大于要下载的文件大小
if user_obj.available_space < file_dict['file_total_size']:
print('You are have %s byte available only\n%s is %s, download failed.' % (user_obj.available_space,input_list[1],file_dict['file_total_size']))
return
recv_size = 0
# 循环接收 file_real_byte 并写入到文件
with open(r'%s%s%s%s%s' % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]),mode='wb') as wf:
data = phone.recv(100)
f = sys.stdout
while True:
if DONE == data:
break
# print(data)
wf.write(data)
recv_size += len(data)
# 设置下载进度条
pervent = recv_size / file_dict['file_total_size']
percent_str = "%.2f%%" % (pervent * 100)
n = round(pervent * 60)
s = ('#' * n).ljust(60, '-')
f.write(percent_str.ljust(8, ' ') + '[' + s + ']')
f.flush()
# time.sleep(0.1)
f.write('\r')
data = phone.recv(100)
f.write('\n')
recv_file_total_size = os.path.getsize(r'%s%s%s%s%s' % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]))
with open(r'%s%s%s%s%s' % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]),mode='rb') as rf:
md5_obj = hashlib.md5()
md5_obj.update(rf.read())
recv_file_hash = md5_obj.hexdigest()
# print(recv_file_total_size)
# print(file_dict['file_total_size'])
# print(recv_file_hash)
# print(file_dict['hash_value'])
print('%s %s done.' %(input_list[0],input_list[1]))
if recv_file_total_size == file_dict['file_total_size'] and recv_file_hash == file_dict['hash_value']:
print('%s md5 is ok.' % input_list[1])
else:
print('%s md5 err.' % input_list[1])
# print(file_dict['filename'],file_dict['hash_value'],file_dict['file_total_size'])
# 把自己家目录的文件上传到公共目录
elif 'put' == input_list[0].lower():
# 先判断是否存在要上传的文件
if not os.path.exists(r'%s%s%s%s%s' % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1])):
print('%s not exist, please check.' % input_list[1])
return
# 先传输文件的属性:文件大小、文件hash值;
file_total_size = os.path.getsize(r'%s%s%s%s%s' % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]))
with open(r'%s%s%s%s%s' % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]), mode='rb') as rf:
md5_obj = hashlib.md5()
md5_obj.update(rf.read())
file_hash = md5_obj.hexdigest()
file_dict = {
'flag': True,
'filename': input_list[1],
'hash_value': file_hash,
'file_total_size': file_total_size
}
file_json = json.dumps(file_dict)
file_byte = file_json.encode('utf-8')
phone.send(struct.pack('i', len(file_byte)))
phone.send(file_byte)
send_size = 0
# 开始传输真正的文件内容
with open(r'%s%s%s%s%s' % (BASE_DIR,os.sep,user_obj.name,os.sep,input_list[1]),mode='rb') as rf:
while True:
data = rf.read(100)
if not data:
time.sleep(0.1)
phone.send(DONE)
break
phone.send(data)
# print('上传 +1 次')
send_size += len(data)
# 设置上传进度条
f = sys.stdout
pervent = send_size / file_dict['file_total_size']
percent_str = "%.2f%%" % (pervent * 100)
n = round(pervent * 60)
s = ('#' * n).ljust(60, '-')
f.write(percent_str.ljust(8, ' ') + '[' + s + ']')
f.flush()
# time.sleep(0.1)
f.write('\r')
f.write('\n')
print('File upload done')
upload_res = phone.recv(1024)
if upload_res == PUT_OK:
print('%s upload ok.' % input_list[1])
elif upload_res == PUT_ERR:
print('%s upload err.' % input_list[1])
else:
print('ERROR: %s' % upload_res)
phone.close()
# 字节bytes转化kb\m\g
def format_size(bytes):
try:
bytes = float(bytes)
kb = bytes / 1024
except:
print("传入的字节格式不对")
return "Error"
if kb >= 1024:
M = kb / 1024
if M >= 1024:
G = M / 1024
return "%fG" % (G)
else:
return "%fM" % (M)
else:
return "%fkb" % (kb)
def ftp_run(user_obj):
while True:
print(FTP_INFO)
option = input('Input your choice, q/Q to exit>>>\t').strip()
if 'Q' == option.upper():
print('See you, %s' % user_obj.name)
break
elif option.isdigit() and 1 == int(option):
user_obj.show_all_file()
elif option.isdigit() and 2 == int(option):
available_space = format_size(user_obj.available_space)
print(available_space)
elif option.isdigit() and 3 == int(option):
public_file_list = os.listdir(PUBLIC_DIR)
print('==========Public file===========')
for file in public_file_list:
print(file)
print('================================')
elif option.isdigit() and 4 == int(option):
input_cmd = input('[get/put] filename>>>\t').strip()
input_list = input_cmd.split()
if 2 != len(input_list):
print('Input invalid, input like this:\nget file\nput file\n')
else:
if hasattr(Ftp_Server, input_list[0]):
client_to_run(user_obj, input_list)
else:
print('No %s option.' % input_list[0])
else:
print('Input invalid, bye...')
# start here...
print(INFO)
option = input('Input option number>>>\t').strip()
if option.isdigit() and 1 == int(option):
user_name = input('Input your name>>>\t').strip()
user_list = os.listdir(BASE_DIR)
if user_name not in user_list:
print('No user: %s exist.' % user_name)
exit(2)
user_obj_file = r"%s%s%s%s%s" % (BASE_DIR,os.sep,user_name,os.sep,PWD_FILE)
user_obj = pickle.load(open(user_obj_file,'rb'))
user_pwd = getpass.getpass('Input your passwd>>>\t').strip()
if user_pwd == user_obj.passwd:
print('\nWelcome %s' % user_obj.name)
print('Your leave space is %s' % user_obj.capacity)
ftp_run(user_obj)
else:
print('Password is incorrect')
exit(2)
elif option.isdigit() and 2 == int(option):
name = input('Input your name>>>\t').strip()
pwd = getpass.getpass('Input your passwd>>>\t').strip()
capacity = input('Input your capacity, unit is Byte>>>\t').strip()
if not capacity.isdigit():
print('Capacity input invalid.')
exit(2)
user_list = os.listdir(BASE_DIR)
user = User(name, pwd, capacity)
if user.name not in user_list:
user.save()
print('%s created successfully' % user.name)
else:
print('%s already exist...' % user.name)
else:
print('Input invalid.')














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









