






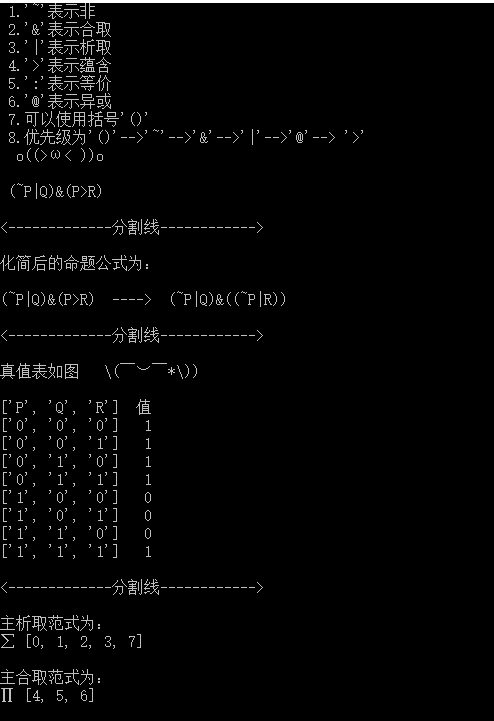
1 #coding=utf-8 2 3 my_input = '' #输入字符串,即输入的原始命题 4 all_letters = [] #命题中所有的字母 5 my_parse = '' 6 hequ_result=[] 7 xiqu_result=[] 8 9 def getInput(): 10 global my_input 11 print u'\n 请输入任意一个命题,规则如下:' 12 print u" 1.'~'表示非" 13 print u" 2.'&'表示合取" 14 print u" 3.'|'表示析取 " 15 print u" 4.'>'表示蕴含 " 16 print u" 5.':'表示等价 " 17 print u" 6.'@'表示异或" 18 print u" 7.可以使用括号'()'" 19 print u" 8.优先级为'()'-->'~'-->'&'-->'|'-->'@'--> '>'" 20 print u' o((>ω< ))o\n' 21 my_input = raw_input(' ') 22 23 def check(): #判断是否存在非法字符和查找所有字符并排序 24 global my_input,all_letters 25 all_letters=[] 26 for c in my_input: 27 if c>='A'and c<='Z' or c>='a' and c<='z': 28 if c not in all_letters: 29 all_letters.append(c) 30 elif c not in ['~','&','|','(',')','>',':','@']: 31 print u'\n ( ̄ε(# ̄)☆╰╮( ̄▽ ̄///)\n' #存在非法字符返回警告 32 print u' 非法字符知道吗, o(* ̄▽ ̄*)o \n' 33 return 0 34 all_letters = sorted(all_letters) # 字母按字典序排列 35 return 1 36 37 def getPriority(c): #获取字符的优先级 38 if c is '~': 39 return 1 40 if c is '&': 41 return 2 42 if c is '|': 43 return 3 44 if c is '@': 45 return 4 46 if c is '>': 47 return 5 48 if c is ':': 49 return 6 50 if c in ['(',')']: 51 return 7 52 return 0 53 54 def parseChar(c): #解析 联结词 将其转化为与或非形式 55 global my_parse 56 p_len = len(my_parse) 57 for i in range(0,p_len): 58 fore = '' #联结词 前面的命题 59 back = '' #联结词 后面的命题 60 if my_parse[i] is c: 61 j=i-1 62 flag = 0 63 while j>=0 and (getPriority(my_parse[j])<getPriority(c) or my_parse[j] == ')'): 64 if my_parse[j] is ')': #如果存在括号,将括号内的整个式子作为命题 65 flag+=1 66 while flag>0: 67 fore= my_parse[j]+fore 68 if my_parse[j] is '(': 69 flag-=1 70 j-=1 71 else: 72 fore= my_parse[j]+fore 73 j-=1 74 j=i+1 75 flag = 0 76 while j<p_len and (getPriority(my_parse[j])<getPriority(c) or my_parse[j] == '('): 77 if my_parse[j] is '(': #如果存在括号,将括号内的整个式子作为命题 78 flag+=1 79 while flag>0: 80 back= back+my_parse[j] 81 if my_parse[j] is ')': 82 flag-=1 83 j+=1 84 else: 85 back= back+my_parse[j] 86 j+=1 87 if c is '>': #转换蕴含联结词 88 my_parse = my_parse.replace(fore+'>'+back,'('+'~'+fore+'|'+back+')') 89 elif c is ':':#转换等价联结词 90 my_parse = my_parse.replace(fore+':'+back,'('+fore+'&'+back+')|(~'+fore+'&~'+back+')') 91 elif c is '@': #转换异或联结词 92 my_parse = my_parse.replace(fore+'@'+back,'~('+'('+fore+'&'+back+')|(~'+fore+'&~'+back+')'+')') 93 94 def parseInput(): #解析所有联结词 95 global my_input,my_parse 96 my_parse = my_input 97 parseChar('>') 98 parseChar(':') 99 parseChar('@') 100 101 def getValueSheet(): #获取真值表 102 global my_parse,all_letters,hequ_result,xiqu_result 103 letter_len = len(all_letters) #所有的字母个数 104 all_values = 2**letter_len #产生的真值表的行数 105 106 107 #判断是否存在非法命题,或者错误语法 108 check_string = my_parse 109 for k in range(0,letter_len): 110 check_string = check_string.replace(all_letters[k],'0') 111 try: 112 result = eval(check_string) & 1 113 except Exception,e: 114 return 0 115 116 print u'\n<-------------分割线------------>\n' 117 print u'化简后的命题公式为:\n' 118 print my_input,' ----> ',my_parse 119 print u'\n<-------------分割线------------>\n' 120 print u'真值表如图 \( ̄︶ ̄*\))\n' 121 print list(map(str,all_letters)),u' 值' 122 for i in range(0,all_values): 123 j=i 124 value = [] 125 for k in range(0,letter_len): 126 value.append(0) 127 k=0 128 while j>0: 129 value[k]=j%2 130 j = j/2 131 k +=1 132 value.reverse() 133 this_parse = my_parse 134 for k in range(0,letter_len): 135 this_parse = this_parse.replace(all_letters[k],str(value[k])) 136 result = eval(this_parse) & 1 137 print list(map(str,value)),' ',result 138 if result ==1: 139 xiqu_result.append(i) 140 else: 141 hequ_result.append(i) 142 return 1 143 144 def printAll(): #打印命题公式,输出结果 145 print u'\n<-------------分割线------------>\n' 146 print u'主析取范式为:' 147 print u'∑',xiqu_result 148 print u'\n主合取范式为:' 149 print u'∏',hequ_result 150 print u'\n┣G┻F┳ε=ヽ(* ̄▽ ̄)ノ┻W┫' 151 152 def main(): 153 getInput() 154 while check()!=1: #如果命题不合法,重新输入 155 getInput() 156 parseInput() 157 while getValueSheet()!=1: #如果语法错误,重新输入 158 print u'\n哼哼,你命题公式不正确,检查一下吧\n' 159 printAll() 160 getInput() 161 while check()!=1: 162 getInput() 163 parseInput() 164 printAll() 165 166 main()














 2987
2987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









