






1、分布式数据库特点
说到数据库,我们最熟悉的是类似于mysql这样的关系型数据库,称为RDBMS。关系型数据库作为一种数据存储和数据检索的关键技术,它支持SQL语言的结构化查询,但是它天生不是为大规模的数据设计的,面对海量数据很难实现横向的扩展。
另一方面,我们熟知的关系型数据库有很强的约束,要求事务必须满足ACID四大特性,即原子性、一致性、隔离性、持久性。扩展到分布式的相应理论上,由于分布式的特点,容易发生单点故障和部分失败等问题,很难严格满足这四大特性,分布式CAP理论也告诉我们一致性、可用性、分区容忍性三者不可能同时满足,最多满足其中的两个。
因此,在分布式存储上,我们追求的目标由严格的ACID转变为对应的BASE,即基本可用、软状态和最终一致性。
2、从bigTable说起
HBase的前身是BigTable,BigTable谷歌的一个分布式存储系统,利用谷歌提出的MapReduce分布式并行计算模型来处理海量数据,使用谷歌分布式文件系统GFS作为底层数据存储,采用Chubby提供协同服务管理,可以扩展到PB级别的数据和上千台机器,具备广泛应用性、可扩展性、高性能和高可用性等特点。
谷歌的许多项目都存储在BigTable中,包括搜索、地图、财经、打印、社交网站Orkut、视频共享网站YouTube和博客网站Blogger等。
HBase由BigTable发展而来,2007年随着Hadoop 0.15.0的发布,第一版的HBase诞生,2010年,HBase项目从Hadoop的子项目升级成为了Apache的顶层项目,至今,已成为一种广泛应用于各个行业的成熟技术。
| BigTable | HBase | |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | Zookeeper |
3、HBase基础
HBase是一个基于HDFS开发的面向列(面向列族)的分布式数据库,它主要用于超大规模的数据集存储,从而可以实现对超大规模数据的实时随机访问。
HBase自底向上的进行构建,解决了原有数据库横向扩展难的问题,使用Hbase可以简单的通过增加节点来达到横向扩展,扩大存储规模,也就是在廉价普通的硬件构成的集群上管理超大规模的稀疏表。
在整个Hadoop生态中,HBase的位置如图所示。
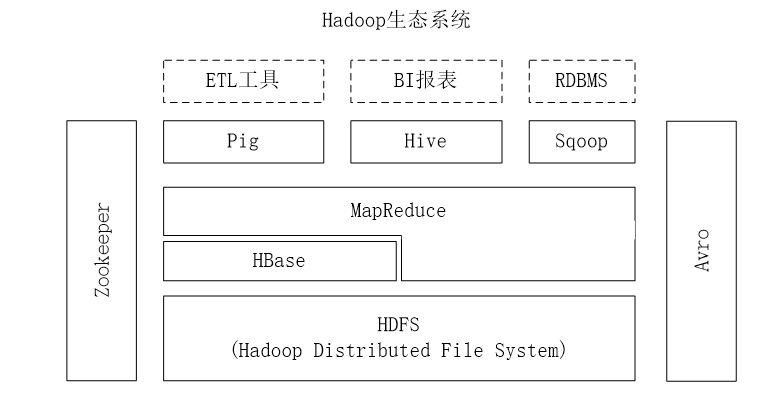
需要注意的是:HBase不是关系型数据库,它是NoSQL数据库的一个典型代表,并不支持SQL查询,它所使用的查询语言是基于键值的一种特殊语法,有些地方也称为:HQL。
(1)HBase数据模型相关概念
表:HBase的数据同样是用表来组织的,表由行和列组成,列分为若干个列族,行和列的坐标交叉决定了一个单元格。
行:每个表由若干行组成,每个行有一个行键作为这一行的唯一标识。访问表中的行只有三种方式:通过单个行键进行查询、通过一个行键的区间来访问、全表扫描。
列族:一个HBase表被分组成许多“列族”的集合,它是基本的访问控制单元。
列修饰符(列限定符):列族里的数据通过列限定符(或列)来定位
单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
(2)HBase数据模型
HBase将数据存放在带有标签的表中,表由行和列组成,行和列交叉确定一个单元格,单元格有版本号,版本号自动分配,为数据插入该单元格时的时间戳。单元格的内容没有数据类型,所有数据都被视为未解释的字节数组。
表格中每一行有一个行键(也是字节数组,任何形式的数据都可以表示成字符串,比如数据结构进行序列化之后),整个表根据行键的字节序来排序,所有对表的访问必须通过行键。
表中的列又划分为多个列族(column family),同一个列族的所有成员具有相同的前缀,具体的列由列修饰符标识,因此,列族和列修饰符合起来才可以表示某一列,比如:info:format、cotents:image
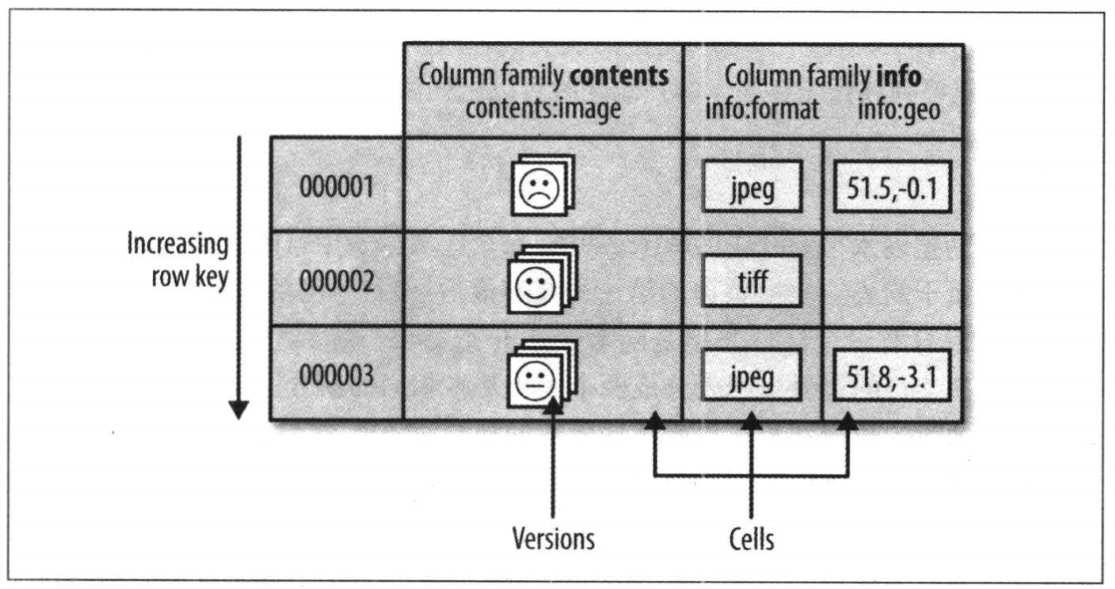
在创建一个表的时候,列族必须作为模式定义的一部分预先给出,而列族是支持动态扩展的,也就是列族成员可以随后按需加入。物理上,所有的列族成员一起存放在文件系统上,所以实际上说HBase是面向列的数据库,更准确的应该是面向列族,调优和存储都是在列族这个层次上进行的。一般情况下,同一个列族的成员最后具有相同的访问模式和大小特征。
总结起来,HBase表和我们熟知的RDBMS的表很像,不同之处在于:行按行键排序,列划分为列族,单元格有版本号,没有数据类型。
(3)HBase数据坐标
HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此,可以视为一个“四维坐标”,即[行键, 列族, 列限定符, 时间戳]。
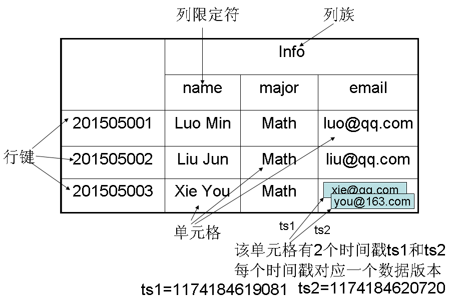
对于上图这样一个HBase表,其数据坐标举例如下:
| 键 | 值 |
|---|---|
| [“201505003”, “Info”, “email”, 1174184619081] | “xie@qq.com” |
| [“201505003”, “Info”, “email”, 1174184620720] | “you@163.com” |
(4)HBase区域
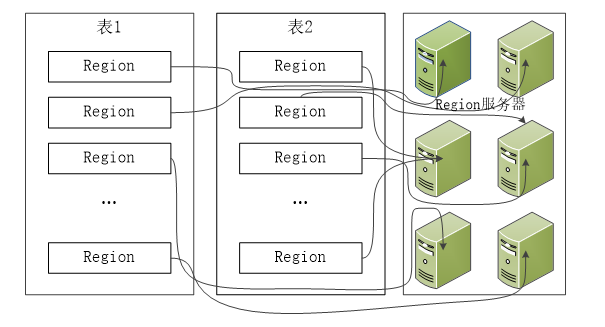
HBase自动把表水平划分为区域(Region),每个区域都是有若干连续行构成的,一个区域由所属的表、起始行、终止行(不包括这行)三个要素来表示。
一开始,一个表只有一个区域,但是随着数据的增加,区域逐渐变大,等到它超出设定的阈值大小,就会在某行的边界上进行拆分,分成两个大小基本相同的区域。然后随着数据的再增加,区域就不断的增加,如果超出了单台服务器的容量,就可以把一些区域放到其他节点上去,构成一个集群。也就是说:集群中的每个节点(Region Server)管理整个表的若干个区域。所以,我们说:区域是HBase集群上分布数据的最小单位。
总结
本文介绍了HBase的基本概念,基本的数据模型及其基础知识,实际上Hbase还是比较容易理解的,后续我们再来介绍它的运行机制和集群架构。















 5342
5342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









