






QString编码:UTF-16
QString内部保存的数据就是QChar数组,是Unicode编码(utf16),在字符显示,操作的时候都是基于Unicode。
QString构造时默认采用Latin-1编码转为Unicode保存。
所以如果字符数据不是Latin-1编码,那么就需要使用QString::from***函数来构造然后转为Unicode存储。
也可以使用强大的QTextCodec,首先QTextCodec肯定知道自己所负责的编码的,当你把一个char串送给它,就能正确将其转成Unicode
QString QTextCodec::toUnicode ( const char * chars ) const
QString的内部编码Unicode就是采用的UTF16,下面可以佐证:
inline QString &QString::setUtf16(const ushort *autf16, int asize)
{ return setUnicode(reinterpret_cast<const QChar *>(autf16), asize); }
QStringLiteral
直接创建Unicode的字符串,其实是使用了c++11的特性支持:lamda表达式+C++11的Unicode字符串:u"这是Unicode"。的方式。因为该lamda是编译时执行的,所以性能更高。
local8Bit:
在简体中文Windows下,local8Bit是GBK
通过QTextCodec *QTextCodec::codecForLocale()进行到Unicode的转换。在Windows就依赖system local。
也就是QTextCodec::codecForName("System")
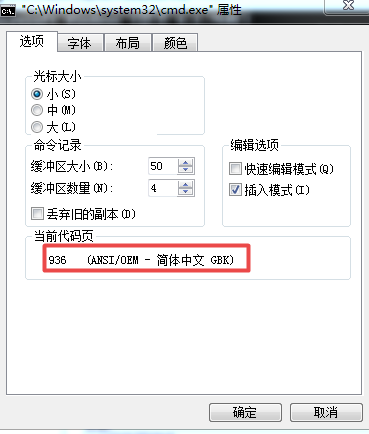
这个值可以改。所以这就是转换为系统的编码格式。
C11与Unicode
在C11(ISO/IEC 9899:2011)标准中引入了对UTF8、UTF16以及UTF32字符编码的支持。
其中,UTF8字符直接通过char来定义,字面量前缀使用u8。比如:
char c = u8'你';
const char *s = u8"你好";
而UTF16字符直接通过char16_t来定义,字面量前缀使用u。比如:
#include <uchar.h>
char16_t c = u'你';
const char16_t *s = "你好";
而UTF32字符直接通过char32_t来定义,字面量前缀使用U。比如:
#include <uchar.h>
char32_t c = U'你';
const char32_t *s = U"你好";
C++11也支持Unicode
string literal
C++ C++ language Expressions
Syntax
" (unescaped_character|escaped_character)* " (1)
L " (unescaped_character|escaped_character)* " (2)
u8 " (unescaped_character|escaped_character)* " (3) (since C++11)
u " (unescaped_character|escaped_character)* " (4) (since C++11)
U " (unescaped_character|escaped_character)* " (5) (since C++11)
prefix(optional) R "delimiter( raw_characters )delimiter" (6) (since C++11)
Explanation
unescaped_character - Any valid character except the double-quote ", backslash \, or new-line character
escaped_character - See escape sequences
prefix - One of L, u8, u, U
delimiter - A character sequence made of any source character but parentheses, backslash and spaces (can be empty, and at most 16 characters long)
raw_characters - Any character sequence, except that it must not contain the closing sequence )delimiter"
1) Narrow multibyte string literal. The type of an unprefixed string literal is const char[].
2) Wide string literal. The type of a L"..." string literal is const wchar_t[].
3) UTF-8 encoded string literal. The type of a u8"..." string literal is const char[].
4) UTF-16 encoded string literal. The type of a u"..." string literal is const char16_t[].
5) UTF-32 encoded string literal. The type of a U"..." string literal is const char32_t[].
6) Raw string literal. Used to avoid escaping of any character. Anything between the delimiters becomes part of the string. prefix, if present, has the same meaning as described above.
QTextCodec
提供的是 字符串 和 字节流 之间的相互转换(也就是字符的编解码)。支持的编码有:
Big5
Big5-HKSCS
CP949
EUC-JP
EUC-KR
GB18030
HP-ROMAN8
IBM 850
IBM 866
IBM 874
ISO 2022-JP
ISO 8859-1 to 10
ISO 8859-13 to 16
Iscii-Bng, Dev, Gjr, Knd, Mlm, Ori, Pnj, Tlg, and Tml
KOI8-R
KOI8-U
Macintosh
Shift-JIS
TIS-620
TSCII
UTF-8
UTF-16
UTF-16BE
UTF-16LE
UTF-32
UTF-32BE
UTF-32LE
Windows-1250 to 1258
KOI8-R编码转Unicode
QByteArray encodedString = "...";
QTextCodec *codec = QTextCodec::codecForName("KOI8-R");
QString string = codec->toUnicode(encodedString);
Unicode编码转KOI8-R
QString string = "...";
QTextCodec *codec = QTextCodec::codecForName("KOI8-R");
QByteArray encodedString = codec->fromUnicode(string);
字符编码
ASCII:(不是ASC2)
标准ASCII只用了0x00~0x7f,也就是低7位。而后来把高位也用上了,扩展了128个,也叫做扩展ACSII码。
扩展ASCII
不是国际标准。
Latin-1:(相当于ASCII+标准的扩展ASCII)
即ISO-8859-1的别名,编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。比ASC多了西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。所以中文字符会显示为是西欧等字符"ÎÒÊÇ"
ANSI:也是ascII的一种扩展,不同国家不一样
ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,即扩展的ASCII编码。
不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。
在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;
在繁体中文Windows操作系统中,ANSI编码代表Big5;
在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码.
每个国家(非拉丁语系国家)自己制定自己的文字的编码规则,并得到了ANSI认可,符合ANSI的标准,全世界在表示对应国家文字的时候都通用这种编码就叫ANSI编码。换句话说,中国的ANSI编码和在日本的ANSI的意思是不一样的,因为都代表自己国家的文字编码标准。比如中国的ANSI对应就是GBK标准,日本就是JIT标准,香港,台湾对应的是BIG5标准等等.
那么到底ANSI是多少位呢?这个不一定!比如在GB2312和GBK,BIG5中,是两位!但是其他标准或者其他语言如果不够用,就完全可能不止两位!那么到底ANSI是多少位呢?这个不一定!比如在GB2312和GBK,BIG5中,是两位!但是其他标准或者其他语言如果不够用,就完全可能不止两位!
ANSI有个致命的缺陷,就是每个标准是各自为阵的,不保证能兼容。换句话说,要同时显示中文和日本文或者阿拉伯文,就完全可能会出现一个编码两个字符集里面都有对应,不知道该显示哪一个的问题,也就是编码重叠的问题。显然这样的方案不好,所以Unicode才会出现!
MBCS(Multi-Byte Chactacter System(Set))
多字节字符系统或者字符集,基于ANSI编码的原理上,对一个字符的表示实际上无法确定他需要占用几个字节的,只能从编码本身来区分和解释。因此计算机在存储的时候,就是采用多字节存储的形式。也就是你需要几个字节我给你放几个字节,比如A我给你放一个字节,比如"中“,我就给你放两个字节,这样的字符表示形式就是MBCS。在基于GBK的windows中,不会超过2个字节,所以windows这种表示形式有叫做DBCS(Double-Byte Chactacter System),其实算是MBCS的一个特例。C语言默认存放字符串就是用的MBCS格式。从原理上来说,这样是非常经济的一种方式。
CodePage
代码页,最早来自IBM,后来被微软,oracle ,SAP等广泛采用。因为ANSI编码每个国家都不统一,不兼容,可能导致冲突,所以一个系统在处理文字的时候,必须要告诉计算机你的ANSI是哪个国家和地区的标准,这种国家和标准的代号(其实就是字符编码格式的代号),微软称为Codepage代码页,其实这个代码页和字符集编码的意思是一样的。告诉你代码页,本质就是告诉了你编码格式。但是不同厂家的代码页可能是完全不同,哪怕是同样的编码,比如, UTF-8字符编码 在IBM对应的代码页是1208,在微软对应的是65001,在德国的SAP公司对应的是 4110 。所以啊,其实本来就是一个东西,大家各自为政,搞那么多新名词,实在没必要!所以标准还是很重要的!!!
比如GBK的在微软的代码页是936,告诉你代码页是936其实和告诉你我编码格式是GBK效果完全相同。那么处理文本的时候就不会有问题,不会去考虑某个代码是显示的韩文还是中文,同样,日文和韩文的代码页就和中文不同,这样就可以避免编码冲突导致计算机不知如何处理的问题。当然用这个也可以很容易的切换语言版本。但是这都是治标不治本的方法,还是无法解决同时显示多种语言的问题,所以最后还是都用unicode吧,永远不会有冲突了。
Unicode:
Unicode只是一种编码规范,而实现方式就有:utf8,utf16,utf32等。
因为Unicode并不涉及字符是怎么在字节中表示的,它仅仅指定了字符对应的数字,仅此而已。
Unicode只是一个用来映射字符和数字的标准。它对支持字符的数量没有限制,也不要求字符必须占两个、三个或者其它任意数量的字节。
参考:http://www.freebuf.com/articles/others-articles/25623.html
目前Unicode编码范围是:0-0x10FFFF,可以容纳1114112个字符,100多万啊。全世界的字符根本用不完了。Unicode 5.0版本中,才用了238605个码位。所以足够了。因此从码位范围看,严格的unicode需要3个字节来存储。但是考虑到理解性和计算机处理的方便性,理论上还是用4个字节来描述Unicode出现了。Unicode编码范围是:0-0x10FFFF,可以容纳1114112个字符,100多万啊。全世界的字符根本用不完了,Unicode 5.0版本中,才用了238605个码位。所以足够了。因此从码位范围看,严格的unicode需要3个字节来存储。但是考虑到理解性和计算机处理的方便性,理论上还是用4个字节来描述。
关于BOM:
编码的BOM是用于确定数据的字节序,编码方式的。对于UTF-8是没有必要用BOM的,因为字节宽度是1字节,而大于1B的都是有规定存储编码的。(微软使用UTF8+BOM是为了明确区分UTF8与ASC码,标准UTF8是无BOM)。BOM头只是建议添加,不是强制的。
下表是各种UTF编码的BOM(LE就是小端):
| UTF编码 | Byte Order Mark (BOM) |
| UTF-8 without BOM | 无 |
| UTF-8 with BOM | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
UTF-8:
这个方案的意思以8位为单位来标识文字,注意并不是说一个文字用8位标识。他其实是一种MBCS方案,可变字节的。到底需要几个字节表示一个符号,这个要根据这个符号的unicode编码来决定,最多4个字节。
编码规则如下:杨
Unicode编码(16进制) ║ UTF-8 字节流(二进制)
000000 - 00007F ║ 0xxxxxxx
000080 - 0007FF ║ 110xxxxx 10xxxxxx
000800 - 00FFFF ║ 1110xxxx 10xxxxxx 10xxxxxx
010000 - 10FFFF ║ 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。
UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位
UTF16:
绝大部分2个字节就够了,但是不能绝对的说所有字符都是2个字节。这个要看字符的unicode编码处于什么范围而定,有可能是2个字节,也可能是4个字节
UTF-32
这个就简单了,和Unicode码表基本一一对应,固定四个字节(因为目前Unicode只定义了21位的数据,4B足够)。















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









