





如何设计一个友好于硬件的网络,以实现更好的准确性-速度平衡?解读应用在YOLOv6上的卷积神经网络结构EfficientRep。
自从VGG在图像分类任务中取得成功以来,卷积神经网络设计已经引起了学术界和工业界的广泛关注。目前已经提出了大量经典网络,如Inception和Resnet等。这些精心设计的架构使得图像分类的准确性越来越高。除了手动设计之外,最近神经网络架构搜索也自动设计出了几个代表性的网络,如Nasnet和AmoebaNet等。虽然复杂的网络为视觉任务(如图像分类、目标检测和分割)带来了成功,但这些网络在部署硬件上可能无法获得适当的准确度-速度平衡。
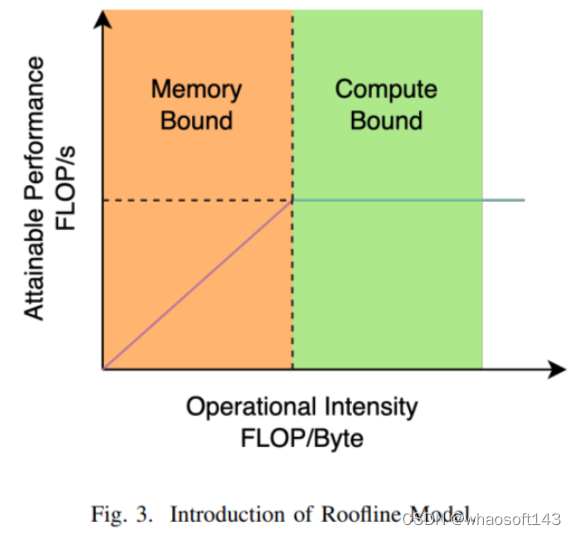
深度学习网络设计和部署以提高硬件效率一直是研究的重点。传统的推断效率评估指标是浮点运算(FLOPs)和参数数量。然而,这些指标不能代表与硬件的关系,例如内存访问成本和I/O吞吐量。图3展示了计算能力与内存资源之间的关系。因此,本文面临一个重要的问题:如何设计一个友好于硬件的网络,以实现更好的准确性-速度平衡?
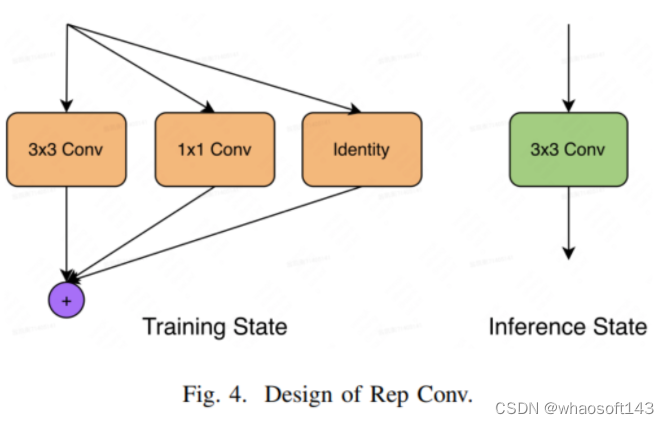
为了解决这个问题,本文探索了一些新颖的架构,这些架构在YOLOv6目标检测框架中表现出了竞争力并且被应用。RepVGG 是一种新颖的网络,具有高度优化的3x3卷积核,可以在GPU或CPU上通过Winograd算法进行优化。单路径模型可以在GPU等设备上快速训练和推断。图4展示了rep conv在训练状态和推断状态之间的转换。在训练状态下,通过额外的1x1卷积和身份映射,rep conv可以在训练过程中保证准确性。在推断状态下,重新参数化结构可以等效地转换为推断状态。
在YOLOv6-1.0中,基于基本的rep conv,本文设计了纯regvgg风格的架构,命名为EfficientRep骨干网络和Rep-PAN颈部网络,以有效利用GPU的计算资源。在YOLOv6-2.0中,为了平衡计算和内存资源,本文探索了一种名为Bep(啤酒杯)单元和BepC3(或称CSPStackRep)块的新型结构。与rep conv相比,本文发现Bep单元在某些情况下是一种更有效的基本神经网络单元。尽管RepVGG提出了rep风格的多分支训练可以达到与原始多分支训练(如resnet)相当的性能,但本文发现rep风格网络的准确性和速度之间的权衡在大规模情况下会降低,这将在第III节中展示。因此,本文设计了CSPBep骨干网络和CSPRepPAN颈部网络,应用于YOLOv6-2.0,具有上述Bep单元和BepC3块的结构。
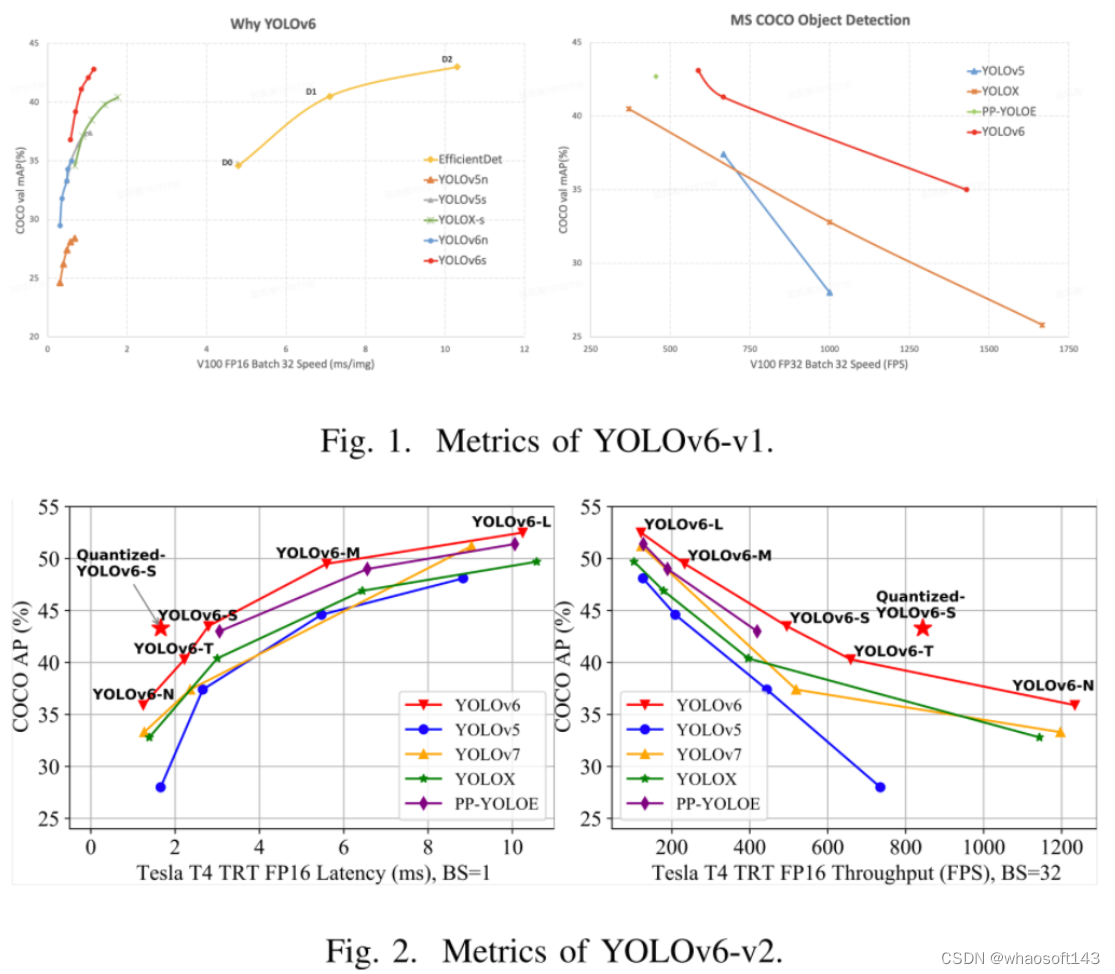
基于以上考虑,本文在YOLOv6中应用混合策略,即在小尺寸下选择单分支模型,在大尺寸下选择多分支模型。图1和图2描述了与其他目标检测器相当的准确性和速度权衡。
A. 网络设计
VGG 网络在ImageNet分类任务中取得了70%以上的top-1准确率,许多相关的创新被提出,例如GoogLeNet和Inception网络采用了多分支结构。ResNet是一种代表性的双分支网络,被广泛应用于工业领域。直到repvgg的提出,单路径网络在某些设备上表现出了高效率。
B. 网络结构搜索
神经网络架构搜索(NAS)是一种新颖的技术,旨在自动设计网络,与手动设计相比。在手动设计空间设计的基础上,NAS可以自动生成大量的网络,但需要巨大的资源成本。目前,为了节省计算资源,已经提出了低成本的神经网络搜索方法,例如One-For-All 等。
C. 硬件感知网络结构设计
最近,提出了一些新颖的网络,例如MobileOne [5]和TRT-VIT [6]。这些网络是手动设计的,考虑了在设备上的性能。除了准确性或参数等指标外,同时考虑推断速度,这被称为硬件感知的神经网络设计。
本文的贡献如下:
- 提出了Bep unit、Repblock和BepC3 block等新型结构。
- 提出了EfficientRep、Rep-PAN、CspBep和CSPRepPAN等新型网络。
- 提出了一种硬件感知神经网络设计方法,实现了计算能力和内存带宽平衡,并针对不同模型大小提供了多种策略。
方法论
本节介绍了EfficientRep系列卷积网络的设计方法和训练策略。
A. 纯Repvgg-style的高效网络设计
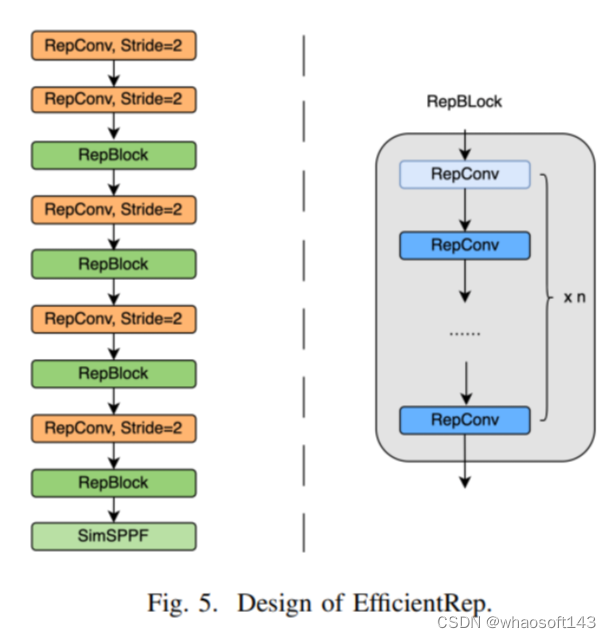
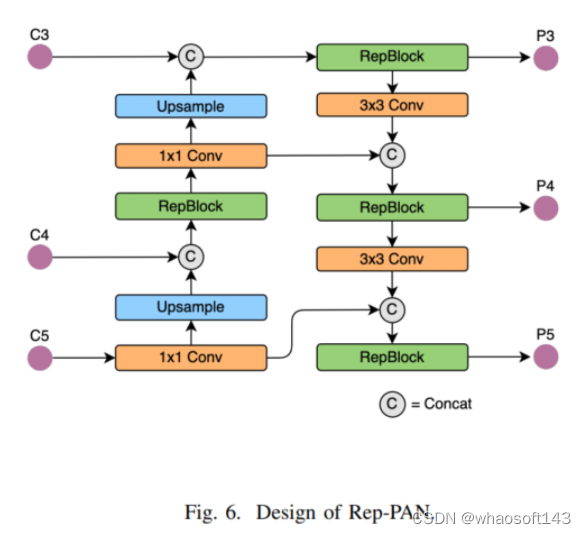
repvgg风格卷积具有3x3卷积结构,紧随其后的是ReLU激活函数,可以高效地利用硬件计算。在训练状态下,Repvgg风格卷积由3x3分支,1x1分支和身份映射(见图4)组成。通过重新参数化,多分支结构在推断状态下转换为单分支3x3卷积。如图5和图6所示,本文设计了名为EfficientRep骨干网络和Rep-PAN颈部网络的Repvgg风格网络,这些网络对GPU友好,并应用于YOLOv6检测框架(YOLOv6-v1)。
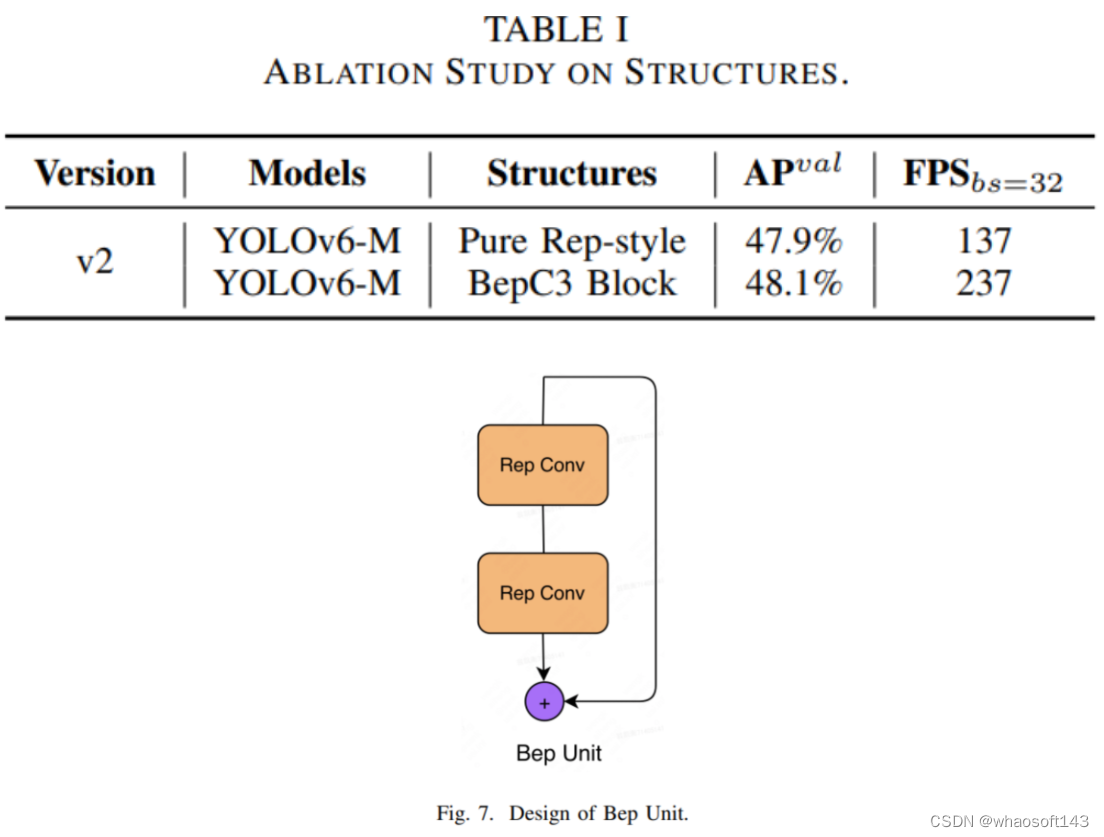
然而,当YOLOv6-v1增长到中等大小时,推断速度下降过快,准确性与csp风格的YOLO系列相比没有竞争力。如表I所示,纯repvgg风格的YOLOv6m无法达到可比的准确性和速度权衡。因此,本文探索了适用于大型模型的多路径等新型结构。
B. 多路径高效设计
为了解决纯repvgg风格网络无法达到预期准确性和速度权衡的问题,本文提出了一种新型Bep单元结构。Bep单元的细节如图7所示,多个rep conv线性连接并带有额外的shortcut。通过Bep单元,本文分别设计了一种新型骨干网络和颈部网络,分别命名为CSPBep和CSPRepPAN。本文将上述结构应用于YOLOv6-v2,并实现了更好的准确性和速度权衡。
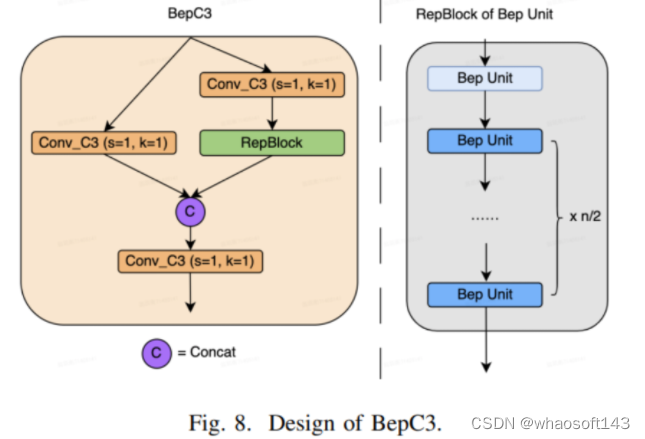
CSP风格是YOLO系列框架中广泛使用的高效设计,例如YOLOv5,PPYOLOE等。CSP风格结构使用交叉阶段部分网络,实现了更丰富的梯度组合,同时减少了计算量。本文将Bep单元与CSP风格结合,设计了一种新型结构,命名为BepC3块,以平衡准确性和推断速度。BepC3的设计如图8所示,由CSP风格结构和Bep单元的Repblock组成。如表I所示,BepC3块的改进效果很好,准确性和速度得到了预期的平衡。
基于BepC3块,本文分别设计了CSPBep骨干网络和CSPRepPAN颈部网络,得到了YOLOv6-v2模型。对于YOLO系列中的CSP风格网络,默认的部分比率为1/2。在本文为YOLOv6-v2的设计中,对于YOLOv6m采用了2/3的部分比率,对于YOLOv6l采用了1/2的部分比率,旨在获得更好的性能。
C. 缩放策略
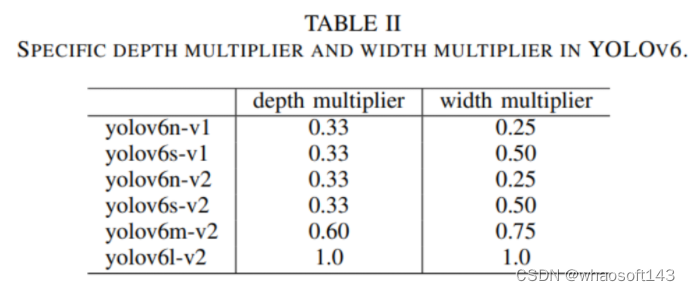
继承YOLOv5的做法,本文使用深度倍增器和宽度倍增器的比例策略来生成不同大小的模型。在YOLOv6-v1和YOLOv6-v2中,基础骨干的深度设置都为[1, 6, 12, 18, 6],宽度设置分别为[64, 128, 256, 512, 1024]。基础颈部的深度设置都为[12, 12, 12, 12],宽度设置分别为[256, 128, 128, 256, 256, 512]。表II展示了YOLOv6中应用的具体深度倍增器和宽度倍增器。
实验结果
在本节中,本文展示了实验结果和细节。对于目标检测,实验在包含80个类别和118k张图像的MS COCO2017训练集上进行训练。本文在包含5000张图像的MS COCO-2017验证集上使用标准的COCO AP指标。
A. 目标检测实验细节
对于本文在YOLOv6中应用的网络设计,本文在COCO train2017上进行总共300个epoch的训练,其中包括3个epoch的预热。本文的训练策略是采用随机梯度下降(SGD)进行训练,初始学习率为0.01,采用余弦学习率调度器。在本文的设置中,权重衰减为5e-4。对于8个GPU设备,默认的批量大小为256。本文还采用了Mosaic和Mixup数据增强以及指数移动平均(EMA)技术进行训练。
B. 与其他检测器比较
为了展示本文的网络设计的效果,表III展示了在MS-COCO测试集上,与其他最先进的目标检测器相比,YOLOv6模型的性能表现。通过本文优化的模型和其他改进,YOLOv6-N/S/M/L模型呈现出更好的准确性和速度的权衡。本文使用TensorRT 7.2版本,在NVIDIA Tesla T4 GPU上,采用FP16精度进行推断速度评估。

总结
在本报告中,作者介绍了本文在应用于YOLOv6的神经网络优化。本工作设计了Bep单元、BepC3-block/Repblock、EfficientRep/CspBep骨干网络和RepPAN/CSPRepPAN颈部网络。结合其他改进,本文实现了比其他目标检测器更好的YOLOv6-N/S/M/L模型。同时,本文提出了一种混合网络设计策略,适用于各种大小的模型,旨在实现更好的准确性和速度的权衡。此外,本文提出了一种计算和内存平衡的新型硬件神经网络设计,应用于YOLOv6框架开发中。希望以上提议能够为开发和研究人员提供启示。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









