






1.1 多核处理器定义
多内核处理器架构是指:芯片设计工程师在单个处理器中集成两个或多个 “执行内核(即计算引擎)”。多内核处理器可直接插入到单一处理器基座中。但是,操作系统会把它的每个执行内核作为独立的逻辑处理器,为其分配相应的执行资源。要利用多核处理器的运算能力,需要改写操作系统和编译器,广泛使用的vista, vin7 等都能支持多核体系架构。
1.2 多核发展趋势
首先思考一个问题: 为什么微处理器要从单核转向多核?
答案是: 功耗问题限制了单核不断提高性能的发展途径.
有几个简单的公式可以说明这个问题:
1) 处理器性能 = 主频 * IPC , 主频是指每秒时钟周期数,比如1Ghz,是每秒10亿个时钟周期。IPC 是每个时钟周期可以执行的指令数。
2) 处理器功耗 正比 电流*电压^2*主频, 而主频正比电压,所以
处理器功耗 正比 主频^3 ,通过主频提升性能,要面临功耗以3次方的指数增长问题。所以主频发展到一定程度后,自然转到重点依靠提高ipc来提升性能,提升IPC可以通过提高指令的并行度实现,提高并行度,一是提高微处理器微架构的并行度,二是采用多核架构,(参考 : http://blogs.intel.com/china/2007/06/03/post_5/)前者已经发展了很多年,提升空间和投入产出比明显不如后者,所有多核处理器是未来的方向。
下面两张图看出家庭版PC和手机核心数目也很快突破10个。目前最新的mac pro 已经配备12个核心
图1 : 目前最新的mac pro 已经配备12个核心

图2 三星也推出了8核手机处理器

虽然商用多核(multicore)和众核(many-core)系统越来越普遍,成本也越来越低,游戏设备、手机等移动设备也具备越来越多的核心,并发和并行越来越成为必要的技术手段,但多核程序的发展依然没有跟上硬件的发展,很多游戏引擎和网络引擎都还是单线程的。原因就是第一章提到的多核编程的难度。
1.3 一个多核处理器架构例子
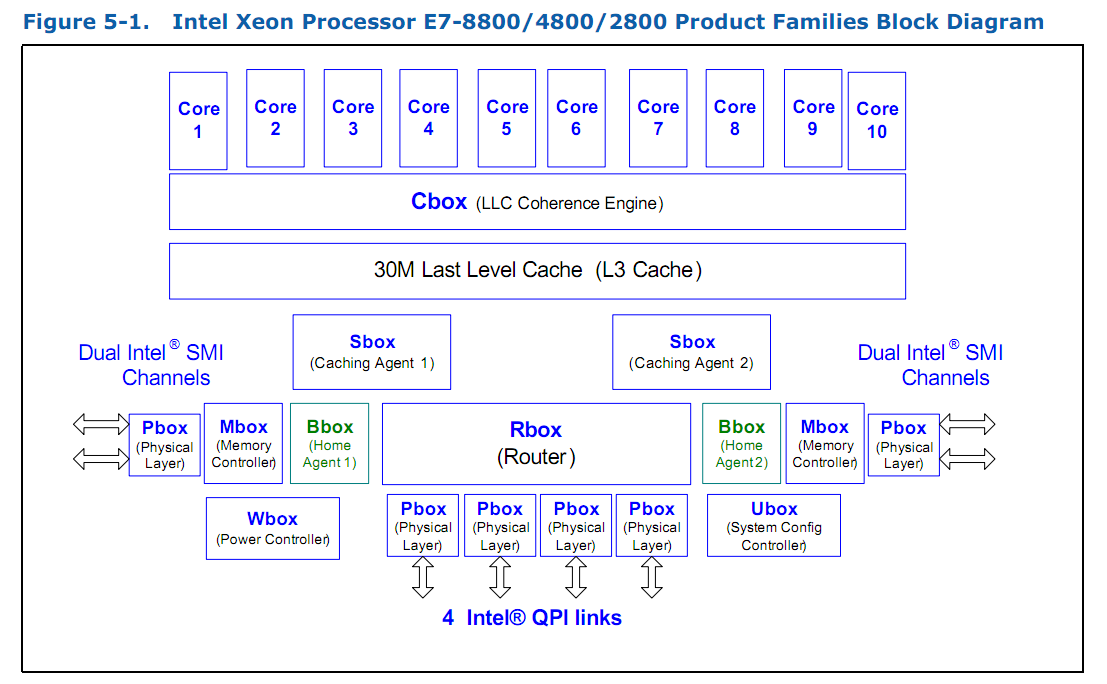

这是基于共享缓存的多核体系架构的一个例子,一共有10个核心,不需要深入了解,这张图唯一的目的就是给大家一个概念,现代的处理器架构已经比几十年前的冯诺依曼体系复杂多了(各种box),里边稍微值得关注的是Cbox ,Bbox ,这两个组件是缓存控制器,负责非常核心的功能:缓存一致性。缓存一致性会在后续文章描述。
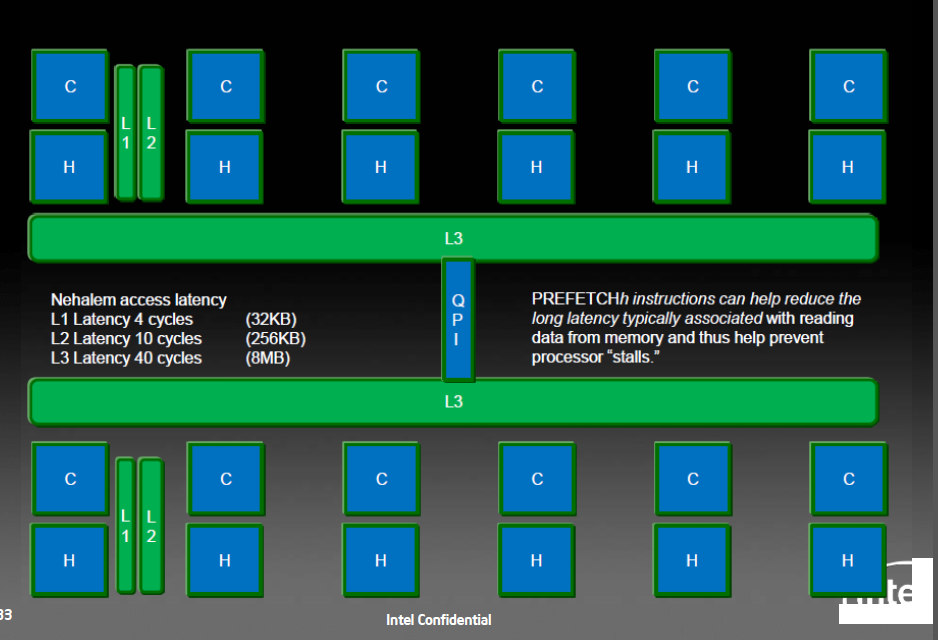
这张图是intel多核体系架构(双路)的缓存示意图,每个core拥有自己的L1和L2缓存,属于一个物理CPU的core共享L3缓存。不同cpu之间通过QPI交互L3数据。每个CPU有自己的内存控制器。对多核编程而言,缓存是非常重要的底层概念。
1.4 Linux 线程核绑定
这么多核具体到编程是如何使用的?
在linux平台提供了核亲和性机制,进程和线程都可以通过设置亲和性绑定到不同的核心上。
进程版本:
#include <sched.h>
void setProcessToCPU(int _cpuID)
{
cpu_set_t mask;
cpu_set_t get;
CPU_ZERO(&mask);
CPU_SET(_cpuID, &mask);
if (sched_setaffinity(0, sizeof(mask), &mask) < 0) {
cout << "set process affinity failed\n" << endl;
}
CPU_ZERO(&get);
if (sched_getaffinity(0, sizeof(get), &get) < 0) {
cout << "get process affinity failed\n" << endl;
}
}
线程版本:
#include <pthread.h>
#include <sched.h>
void setThreadToCPU(int _cpuID)
{
cpu_set_t mask;
cpu_set_t get;
CPU_ZERO(&mask);
CPU_SET(_cpuID, &mask);
if (pthread_setaffinity_np(pthread_self(), sizeof(mask), &mask) < 0) {
cout << "set thread affinity failed\n" << endl;
}
CPU_ZERO(&get);
if (pthread_getaffinity_np(pthread_self(), sizeof(get), &get) < 0) {
cout << "get thread affinity failed\n" << endl;
}
}














 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









