






JobProgressListener类是Spark的ListenerBus中一个很重要的监听器,可以用于记录Spark任务的Job和Stage等信息,比如在Spark UI页面上Job和Stage运行状况以及运行进度的显示等数据,就是从JobProgressListener中获得的。另外,SparkStatusTracker也会从JobProgressListener中获取Spark运行信息。外部应用也可以通过Spark提供的status相关API比如AllJobResource, AllStagesResource, OneJobResource, OneStageResource获取到Spark程序的运行信息。
JobProgressListener类的继承关系,以及该类中重要的属性和方法,见下图
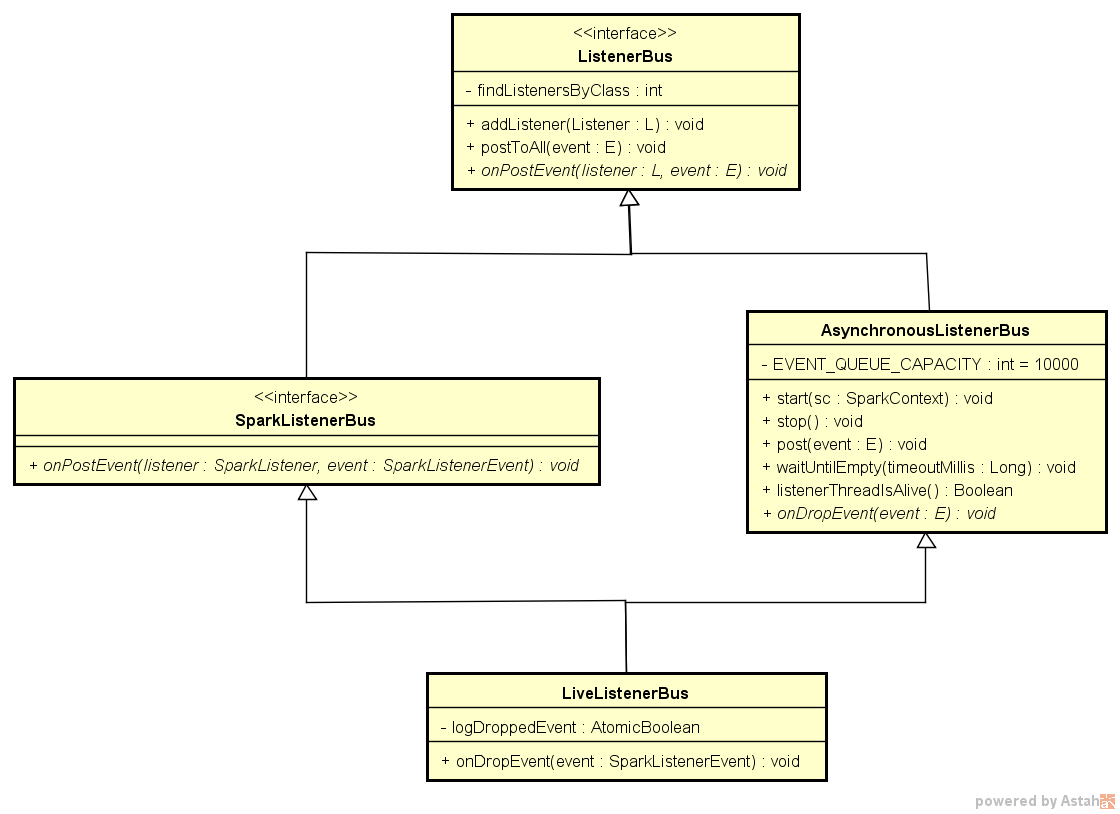
在Spark-1.6.0中,JobProgressListener对象生成后,会被add到一个LiveListenerBus类型的ListenerBus中。LiveListenerBus类的基础关系,以及该类中重要方法和属性见下图
文章接下来分析在一个Spark Application中JobProgressListener的生命周期,以及其数据接收和传递的过程。

一、JobProgressListener生成和数据写入
1、JobProgressListener生成
在源代码中,JobProgressListener在SparkContext对象创建时就生成了,
private[spark] val listenerBus = new LiveListenerBus //listenerBus
private var _jobProgressListener: JobProgressListener = _ //定义
...
_jobProgressListener = new JobProgressListener(_conf) //生成
private[spark] def jobProgressListener: JobProgressListener = _jobProgressListener //使用
listenerBus.addListener(jobProgressListener) //使用 从上面的代码中看到,jobProgressListener在生成后,spark将其存入了LiveListenerBus对象中,其他任何接收到listenerBus的地方都能从中获取到这个jobProgressListener对象。另外在创建SparkUI对象时,使用到了_jobProgressListener对象,使得Spark UI页面能够从该对象中获取Spark应用程序的运行时数据。或者也可以像SparkStatusTracker对象那样,直接从SparkContext对象中获取jobProgressListener。
最后,在SparkContext中调用setupAndStartListenerBus()方法,启动和初始化listenerBus。我们可以看到,在该方法中最后调用了listenerBus.start(this)方法真正启动listenerBus。
2、JobProgressListener接收事件
(1)事件进入LiveListenerBus
LiveListenerBus继承自AsynchronousListenerBus,可以看到这里是多线程的方式。里面维持了一个大小为10000的eventQueue,LinkedBlockingDeque类型。这个可以和DAGScheduler中提到的EventLoop类中的eventQueue对比分析。
eventQueue接收事件调用的是post方法,这里调用的是LinkedBlockingDeque.offer方法,而EventLoop中调用的是LinkedBlockingDeque.put,可以比较这两者的区别。
def post(event: E) {
if (stopped.get) {
// Drop further events to make `listenerThread` exit ASAP
logError(s"$name has already stopped! Dropping event $event")
return
}
val eventAdded = eventQueue.offer(event) // 向eventQueue提交event
if (eventAdded) {
eventLock.release() // 如果提交成功则释放锁
} else {
onDropEvent(event) // 否则丢弃该事件
}
} 所以说,各类事件都是调用AsynchronousListenerBus.post方法传入eventQueue中的。比如,在DAGScheduler类中,可以看到总共有14个调用的地方,下面列举出其中12个不同的。
| DAGScheduler方法 | SparkListenerEvent事件 | 描述 |
|---|---|---|
| executorHeartbeatReceived | SparkListenerExecutorMetricsUpdate | executor向master发送心跳表示BlockManager仍然存活 |
| handleBeginEvent | SparkListenerTaskStart | task开始执行事件 |
| cleanUpAfterSchedulerStop | SparkListenerJobEnd | Job结束事件 |
| handleGetTaskResult | SparkListenerTaskGettingResult | task获取结果事件 |
| handleJobSubmitted | SparkListenerJobStart | Job开始事件 |
| handleMapStageSubmitted | SparkListenerJobStart | Job开始事件 |
| submitMissingTasks | SparkListenerStageSubmitted | Stage提交事件 |
| handleTaskCompletion | SparkListenerTaskEnd | Task结束事件 |
| handleTaskCompletion | SparkListenerJobEnd | Job结束事件 |
| markStageAsFinished | SparkListenerStageCompleted | Stage结束事件 |
| failJobAndIndependentStages | SparkListenerJobEnd | Job结束事件 |
| markMapStageJobAsFinished | SparkListenerJobEnd | Job结束事件 |
分析到这里,各种SparkListenerEvent事件传递到了eventQueue中,那么如何进一步传递到JobProgessListener中呢?接下来JobProgressListener作为消费者,从eventQueue中消费这些SparkListenerEvent。
(2)事件进入到JobProgressListener
从SparkContext中启动LiveListenerBus线程开始,LiveListenerBus继承自AsynchronousListenerBus的run方法便一直在多线程运行。在run中有一段主要逻辑,
val event = eventQueue.poll
if (event == null) {
// Get out of the while loop and shutdown the daemon thread
if (!stopped.get) {
throw new IllegalStateException("Polling `null` from eventQueue means" +
" the listener bus has been stopped. So `stopped` must be true")
}
return
}
postToAll(event) 从eventQueue取出事件后,调用LiveListenerBus的postToAll方法,将事件分发到各Listener中。
具体看一下LiveListenerBus的postToAll方法,这个方法从ListenerBus继承。
private[spark] trait ListenerBus[L <: AnyRef, E] extends Logging {
// 维持一个Array来存储add到该bus中的所有listener
private[spark] val listeners = new CopyOnWriteArrayList[L]
/**
* 调用addListener方法会把传入的listener对象存入listeners中
*/
final def addListener(listener: L) {
listeners.add(listener)
}
/**
* spark通过调用这个方法,spark的各种事件都会触发listenerBus中所有listener对该事件作出响应
*/
final def postToAll(event: E): Unit = {
val iter = listeners.iterator
while (iter.hasNext) {
val listener = iter.next()
try {
/**
* onPostEvent方法在SparkListenerBus类中具体实现,针对不同的事件采取不同的方法
* 比如stageSubmitted, stageCompleted, jobStart, jobEnd, taskStart,
* applicationStart, blockManagerAdded,executorAdded等事件
* 分别调用SparkListener中不同方法进行处理
*/
onPostEvent(listener, event)
} catch {
case NonFatal(e) =>
logError(s"Listener ${Utils.getFormattedClassName(listener)} threw an exception", e)
}
}
}
}2、JobProgressListener对各种事件的响应
那么接下来,从JobProgressListener对各种事件的响应方法出发,对其状态变更逻辑作一个简要梳理,很多方法从其命名上就能看出其主要功能,有需要的可以进入具体方法中做进一步的研究。JobProgressListener能做出响应的所有SparkListenerEvent事件,基本上都列在前面的表格中了。各类事件基本上都是从DAGScheduler中传入的,可以参考Spark Scheduler模块源码分析之DAGScheduler
(1)Job级别信息
这里主要涉及到Job开始和结束的两个方法
- onJobStart(SparkListenerJobStart)
在Job开始时,获取job的一些基本信息,比如参数spark.jobGroup.id确定的JobGroup。然后生成一个JobUIData对象,用于在Spark UI页面上显示Job的ID,提交时间,运行状态,这个Job包含的Stage个数,完成、跳过、失败的Stage个数。以及总的Task个数,以及完成、失败、跳过、正在运行的Task个数。该Job中包含的所有Stage都存入pendingStages中。 - onJobEnd(SparkListenerJobEnd)
在Job完成时,根据该Job的最终状态是成功还是失败,分别把该job的相关信息存入completedJob对象和failedJobs对象中,同时把成功或者失败的job数加一。然后循环处理该Job的每一个Stage,将该Stage对应的当前Job移除,如果移除后发现该Stage再没有其他Job使用了,就把该Stage从activeStage列表中移除。接下来,如果这个Stage的提交时间为空,则表示该Stage被跳过执行,更新一下skipped的Stage个数,以及skipped的Task个数。(成功和失败的Stage的逻辑在下面一小节中)
(2)Stage级别信息
有关Stage的状态变更处理逻辑,这里也有Stage的submit和complete方法
- onStageSubmitted(SparkListenerStageSubmitted)
在Stage提交后,将该Stage存入activeStages中,并且从pendingStages中移除该Stage。首先获得当前的调度池名称,如果是FIFO模式,则是default(实际上不起任何作用),然后根据该调度池,将这个Stage放入调度池中。然后把所属job的numActiveStages加一, onStageCompleted(SparkListenerStageCompleted)
在Stage完成后,从调度池中将该Stage移除,同时也从activeStages中移除。根据该Stage是成功还是失败,继续更新completedStages或failedStages,并更新这类Stage的统计数。然后把对应Job中activeStages值减一,如果这个Stage是成功的(判断依据是failureReason为空),则把对应job的成功Stage数加一,否则把对应Job的失败Stage数加一。
(3)Task级别信息
有关Task的方法有task开始,结束两个方法onTaskStart(SparkListenerTaskStart)
当一个Task开始运行时,会把对应Stage中active状态的Task计数加一,并且把这个Task相关的信息记入对应Stage中,同时更新该Task所属Job中Active状态Task的个数。- onTaskEnd(SparkListenerTaskEnd)
当一个Task运行完成时,获取该Task对应Stage的executorSummary信息,这个executorSummary中记录了每个Executor对应的ExecutorSummary信息,其中包括task开始时间,失败task个数,成功task个数,输入输出字节数,shuffle read/write字节数等。然后根据这个Task所属的executorId,找到当前Task的运行统计信息execSummary。如果这个Task运行成功,就将成功task个数加一,否则就将失败task个数加一。然后根据Task运行状态,更新对应Stage中失败或成功Task个数。进一步,更新对应Job中失败或成功的Task个数。
二、SparkUI页面从JobProgressListener读取数据
JobProgressListener主要用在向Spark UI页面传递数据上。















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









