






网络抓取系统分为核心和扩展组件两部分。核心部分是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。目标是尽量的模块化,并体现爬虫的功能特点。这部分提供简单、灵活的API,在基本不改变开发模式的情况下,编写一个爬虫。
扩展组件部分提供一些扩展的功能,内置了一些常用的组件,便于对爬虫进行功能扩展。
蜘蛛主要功能模块如下:
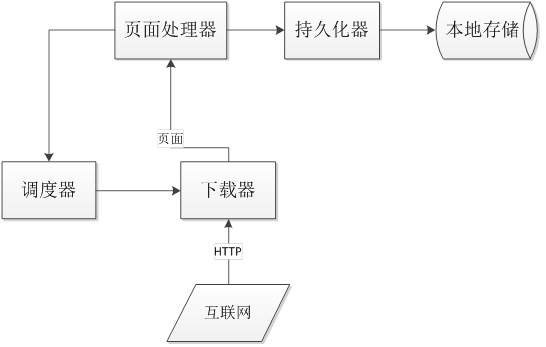
调度器
调度器负责管理待抓取的URL,以及去重的工作。调度器使用内存队列来管理URL,并进行去重。
下载器
下载器是爬虫的基础。下载页面之后才能进行其他后续操作。
页面处理器
一般来说,我们最终需要的都不是原始的HTML页面。我们需要对爬到的页面进行分析,转化成结构化的数据,并存储下来
持久化器
持久化器负责抽取结果的处理,包括计算、持久化到文件、数据库等。















 9566
9566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









