






4. 条件推理的学习
正如因果推理是条件推理的一种形式,因果学习也是如此:发现事物之间持久的因果过程或因果属性。在认知科学中“推理”和“学习”的界线是分不清的。我们常常认为对一些对象或过程的条件推理学习可以潜在地产生无限的数据序列或结果集,而且只有其中一部分数据能够在任何时刻观察得到。在给定一定的观测数据子集的条件下,我们能对有关对象或过程推导出什么?当增加了观测数据集的大小时,我们又能多学到多少?学习曲线是什么样的?
为了将学习表达为条件推理,我们需要一个程序来描述能产生观测数据的所有可能的假设空间,每个假设是一个高阶函数(假设生成器)的可能值。该高阶函数表达了在任何观测数据前我们有的该过程如何工作的先验知识,然后,我们再根据观测数据运用条件推理修正我们的知识。
4.1 例子:硬币的学习
学习的一个简单例子,假设一个朋友从口袋里拿出一个硬币给你翻转。你投掷了五次,并观察到都是正面。
(H H H H H)
这个看起来奇怪吗?对大多数人来说,翻转连续五个正面是一个小巧合没什么可兴奋,但是假设你再投掷5次,并继续观测到正面,现在的数据集看起来像这样:
(H H H H H H H H H H)
大多数人会觉得这个巧合非常可疑,并开始怀疑他们的朋友已经对这个硬币做了弊--也许这是一个两面重量不一样的硬币,不管你怎么投掷它总是正面。这一推测可能强烈或也可能微弱,当然,这取决于你是否相信你的朋友或者他的行为;难道她为你投出正面比反面多下了一个大赌注?现在你继续投掷五次,再次观察只有正面--这样数据集是现在的15正面组成的一行:
(H H H H H H H H H H H H H H H)
无论您以前是怎么想的,现在你几乎无法抗拒该硬币被作弊的想法。
这种“学习曲线”反映了条件推理是一个高度的系统性的和理性的过程,下面将描述它如何使用概率程序。以前我们使用的随机函数没有输入或形实转换来描述权重不同的硬币,每个这样的函数就代表一个产生我们的观察的假设。下面的程序中,coin函数就体现了这些假设,而高阶函数make-coin需要一个weight参数,并返回一个由weight定义的coin函数。
简单起见,我们只考虑两种假设,即两个可能的硬币义,一个代表公平的硬币,一个95%时间出现正面的作弊硬币;还有一个先验概率,即一个朋友提供作弊硬币的可能性有多少?当然这没有客观的或通用的答案,为了演示起见我们假设一个作弊硬币先验概率是1/1000,一个公平硬币是999/1000。这些概率确定的权重被传递给make-coin函数,接下来来推理:
(define observed-data '(h h h h h))
(define num-flips (length observed-data))
(define samples
(mh-query
500 10
(define fair-prior 0.999)
(define fair-coin? (flip fair-prior))
(define make-coin (lambda (weight) (lambda () (if (flip weight) 'h 't))))
(define coin (make-coin (if fair-coin? 0.5 0.95)))
fair-coin?
(equal? observed-data (repeat num-flips coin))
)
)
(hist samples "Fair coin?")
试试不同的投掷次数和观测到的正面次数,你能直观地重现上面的学习曲线。连续观察到5次正面就认为是作弊硬币是不够的,但它确实提示了这种可能性:现在的机率是百分之几,大约30倍于千分之一的基本几率;连续观察到10次正面后,作弊硬币和公平硬币的几率是现在大致相当,但仍是公平硬币的可能性大点;在观察到没有任何反面的15个正面后,作弊硬币的可能性就很强了。
下面研究这条学习曲线如何依赖于fair-prior取值。如果我们把fair-prior取值为0.5,两个假设几率相同,那么,只要连续5次正面就足以认定是作弊硬币;如果fair-prior为99/100,那么连续10次正面也就足够了;如果我们大幅增大fair-prior,那么在连续15正面前,都不足以证明是个作弊硬币:即使在fair-prior= 0.9999时,15次连续正面仍能证明一个作弊硬币,这是因为随着数据集的增加,证明作弊硬币的事实以指数级累积,每连续一个正面将增加近2倍。
学习一向就是从一个知识状态转移到另一个状态,而转移速度提供了一种方法来判断学习者对初始知识的信念。
事实上,连续10次至15次正面足以使大多数人相信是个作弊硬币,对于大多数人来说碰到一枚作弊硬币的先验概率为1/100至1/10000 – 是个合理的范围。
当然,如果你一开始就怀疑任何朋友从口袋里提供你一个硬币可能是作弊硬币的话,那么,只要连续看到五个正面应该已经让你很怀疑了—我们把fair-prior取值设为0.9就可以看到。
4.2 例子:连续参数的学习(或无限假设空间的学习)
前面的例子也许代表了可以想到的最简单的学习。典型的人类认知或人工智能的学习问题要在许多方面更加复杂。其一,学习者可能在他们的观察中几乎总是面临着两个以上的关于因果结构的假设空间,事实上,学习的假设空间往往是无限的。传统上依赖于“离散”或“符号”的领域的知识模型的学习会遇到可计数的无限假设空间,语言习得中的语法假设空间就是一个典型的例子。传统上被认为较“持续”的学习领域,如感知或马达控制学习的假设空间通常是不可数的,参数化为一个或连续的维度。在因果关系学习中,离散和连续的假设空间通常都会出现;在统计和机器学习中,在连续假设空间给出数据的条件推理通常被称为参数估计。
稍微丰富一下我们投掷硬币的例子,就可以变成连续假设空间学习的一个基本案例。
假设我们的假设生成器make-coin,不是简单地抛硬币来决定使用哪个权重,而是可以选择0和1之间的任意权重。为此,除了输出布尔真值的flip以外,我们还需要引进一个新的XRP,它能输出[0,1]之间的实数,对应于硬币的权重。
Church中最简单的XRP是uniform,它能在一个给定上限和下限的区间内均匀地输出一个随机实数。下面的程序就是用uniform来描述硬币权重的先验概率再在给定观察数据集条件下进行推理的。
(define observed-data '(h h h h h))
(define num-flips (length observed-data))
(define num-samples 1000)
(define prior-samples (repeat num-samples (lambda () (uniform 0 1))))
(define samples
(mh-query
num-samples 10
(define coin-weight (uniform 0 1))
(define make-coin (lambda (weight) (lambda () (if (flip weight) 'h 't))))
(define coin (make-coin coin-weight))
coin-weight
(equal? observed-data (repeat num-flips coin))
)
)
(truehist (append '(0) '(1) prior-samples) "Coin weight, prior to observing data")
(truehist (append '(0) '(1) samples) "Coin weight, conditioned on observed data")
由于推理输出的是满足条件的样本集,每个样本是从不可数区间[0,1]中取值的,因此我们不能指望,这些样本与硬币权重或最可能的值完全一致。
象truelist那样将采样归类, 这样我们可以得到硬币权重落在[0,1]那个区间的一个有意义的估计。我们将条件推理出来的采样分布称为条件分布,或有时称为后验分布,以示于表达原来知识的先验分布的区别。上面的代码用1000个样本的直方图显示了先验和条件分布。 (我们为0和1各添加一个样本使直方图覆盖[0,1]整个范围。)
尝试不同的数据集,不同次数的投掷和不同的正反面比例,条件分布的形状会如何改变呢?其峰值的位置反映了合理的硬币权重的“最佳猜测”,大约等于观察到的正面的比例,反映了一个事实即我们的先验知识基本上是盲目的,任何coin-weight的值先验都是一样可能的。该条件分布的形态反映了我们对硬币权重的看法的信心度,当我们观察到更多的数据时,分布会变成尖峰,因为每次独立采样的投掷都会提供更多关于未知参数的证据。
当然,最贴近实际生活的参数估计或连续参数因果模型的学习问题,都远远复杂于这个简单例子。它们通常涉及同一时间多个参数的联合推理和更复杂功能依赖的结构;它们还经常需要有关参数更强大和更结构化的的先验知识,而不是仅仅假设初始均匀分布;然而无论如何,还是运用同样的条件推理基本逻辑来学习。
如果我们有些有益的先验知识,再想了解一个硬币的权重或一个因果模型的任意参数,那么很容易看到,以前的Church程序并没有掌握硬币的先验知识,至少不太符合日常的情景。
想象一下,你刚从一个商店拿回25分硬币,或更好的你是刚从银行的一卷硬币中拿回25分硬币的,这时你对硬币的先验期望几乎肯定认定是公平的,
如果投掷10次得到7次正面,你会不以为然,这很容易发生在一个公平的硬币上,所以,没有理由怀疑这一特定硬币的权重不是0.5,但在均匀分布的先验知识上运行查询的话,你会猜到在这种情况下硬币权重大约为0.7。
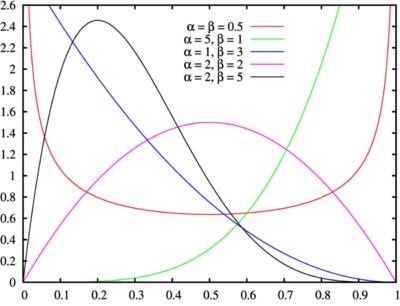
我们的假设生成函数需要不仅能产生均匀分布的硬币权重,而能用其它一些函数对硬币是否公平、倾向正面还是反面的期望值等等进行各种编码。我们使用Beta分布,使用beta XRP编程,它和uniform一样是一个随机过程输出一个位于[0,1]区间的实数,实际上它以一种自然方式一般化了uniform,这是最常见的关于硬币权重或在统计建模和机器学习中参数学习的先验分布,它有两个参数称为假计数,因为它们可以被看作是假设(想象成投掷前设置)的先验的正反面次数。下面是不同参数选择下beta输出的几个例子:
图中每条曲线的高度代表了在beta函数伪参数范围相对应的x-value时硬币权重的相对概率。
为了了解伪计数如何工作,请注意伪计数的比例可以倾向于正面也倾向于反面,这样Beta分布变得向硬币权重的方向更倾斜。当伪计数是对称时,分布的高峰值在0.5;由于伪计数的总和越大时,分布就会变得越来越陡;比如Beta(2,2)和Beta(10,10),期望值都在0.5,但后者要更陡。请注意,Beta(1,1)就是在(0,1)区间均匀分布。当伪计数小于1时,分布峰值变得更加接近0和1。
还有一种更深了解beta分布家庭的方法,以及为什么我们叫它的参数为伪计数。在一定意义上的,全部信念空间可自然参数化一个硬币的翻转,因为每个设置是相当于你观察一组硬币翻转学习一样。这种信念空间在条件推理下是闭集:如果你将先验知识描述成一个Beta分布并且根据条件推断更新你的信念的话,你的信念状态保证会在同一个空间(另一个Beta分布)。
在一个中等强度的公平或接近公平的硬币的先验假设下,下面的Church程序计算了的10次投掷观察出7次正面的条件推理。
(define observed-data '(h h h t h t h h t h))
(define num-flips (length observed-data))
(define num-samples 1000)
(define pseudo-counts '(10 10))
(define prior-samples (repeat num-samples (lambda () (first (beta (first pseudo-counts) (second pseudo-counts))))))
(define samples
(mh-query
num-samples 10
(define coin-weight (first (beta (first pseudo-counts) (second pseudo-counts))))
(define make-coin (lambda (weight) (lambda () (if (flip weight) 'h 't))))
(define coin (make-coin coin-weight))
coin-weight
(equal? observed-data (repeat num-flips coin))
)
)
(truehist (append '(0) '(1) prior-samples) "Coin weight, prior to observing data")
(truehist (append '(0) '(1) samples) "Coin weight, conditioned on observed data")
将上述先验分布和条件分布与那些使用均匀分布先验知识得出的结果进行对比。先验分布对权重接近0.5表示出更多的信心,只在10次投掷观察到7次正面后其峰值才略略微离开0.5,该条件分布的峰值大致在(7 +10)/(7 +3 +10 +10)= 17/30≈0.567,这中间有有以beta(10,10)编码的我们先验想象的正反面和实际观察到的正反面,这似乎直觉上是合理的:除非我们有充分的理由怀疑一个作弊硬币,否则10次投掷观察到7次正面并非很巧合,应该不会使我们的推理动摇。
如果我们是投掷一枚刚从银行一卷硬币中拿出来的25分硬币,我们想精确捕捉先验知识的话,我们或许应该考虑一个信心相当强的先验知识,如beta(100,100)或甚至beta(1000,1000)。用一个更强的beta先验,尝试重新运行上面的代码,你会看到10次投掷观察到7次正面后,硬币的权重难以改变 –正如直觉。
Beta分布家族足以表达关于硬币权重的人们直观的先验知识吗?这对数学非常有吸引力,但不幸的是人类的直觉太丰富了,无法用一个beta分布来概括。想知道为什么吗?想像一下你投掷一枚从刚银行拿来的25分硬币25次,每次都是正面!用伪计数对100,100或1000,1000的beta先验,1000似乎可以合理地解释为什么投掷10次7次正面而权重的条件估计并没有比先验的0.5改变多少,但这显然无法符合我们投掷25次25次正面的情况。
尝试用beta(100,100)分布的硬币权重运行上面的程序并观察到连续25次正面没有一次反面的情况。最有可能的条件推理结果是硬币权重稍微倾向于正面,但它远不及你的想像(相当惊讶!)。无论你最初对这枚从银行整卷拿出的硬币的公平性的信念有多强,你会想:“连续25正面没有一次反面?不可能是一枚公平的硬币,这里有鬼…这硬币几乎肯定会一直是正面!“不太可能有人有意或无意在银行新的一卷25分硬币中放个作弊硬币,但这和抛一个公平硬币25次不太可能没有一次反面的情况有一点点不同。
想象一下你的学习曲线,投掷一枚从银行拿回的硬币并观察到连续5次正面...然后连续10次正面...接着15次正面...等等。你对“公平硬币”的“作弊硬币”假设的转移似乎是离散的,而不是以连续的0.5和1之间的硬币权重顺序平稳变化。
很显然,这个“作弊硬币”想法,不仅仅是一个硬币总是(或几乎总是)正面的假设,就像在本节第一个简单例子中,我们比较两个权重为0.5、0.95的硬币一样。假设你投掷从银行拿回的一枚25分硬币100次,85次正面头和15次反面。虽然你事先相信这个硬币是多么公平,但这种硬币也不会公平。如果先验知识使用强beta分布的话(例如,beta(100,100)或beta(1000,1000)),硬币权重仍会接近0.5(分别为0.52和0.62),与直觉不符。如果在硬币权重只有0.5和0.95两种, 权重0.95更有可能。但是这些选择都不符合直觉,那可能接近于观察到的频率:“这显然是不公平的硬币,因为100次里有85次正面,我最好的猜测是,将来它投出正面的概率是大约85%。“
比较一下这些异常序列,一个崭新硬币出现25次投掷25次正面或者100次投掷85次正面的话,事实证据似乎让我们从最初对公平硬币的强烈相信(象beta(1000,1000)先验概率)变成了另一个不同的离散假设的强烈信念,是一个权重未知的作弊硬币(更像均匀分布或beta(1,1)分布)。一旦我们过渡到是作弊硬币的假设,我们可以有效地凭经验估算硬币的权重,似乎我们推理时我们关于硬币权重的先验知识能从强对称性的beta分布切换到更为均匀的分布。
稍后我们将看到如何来解释这样一种信仰的轨迹--我们将看到一些学习,感知和推理的现象有这种特点。关键是要能比通常统计上我们使用单一XRP来表达一个分布的方法,使用更具表达力的程序来描述人们的先验知识。我们对世界的直觉理论结构上更抽象,包含在层次结构或多或少更复杂的心理模型中。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}