






1、词频统计
(1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本
挖掘的重要手段。它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其变化趋势。
(2)安装jieba库
安装说明
代码对 Python 2/3 均兼容
全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
通过 import jieba 来引用
示例、全自动安装
在命令行下输入指令:
pip install jieba
(2) 安装进程:

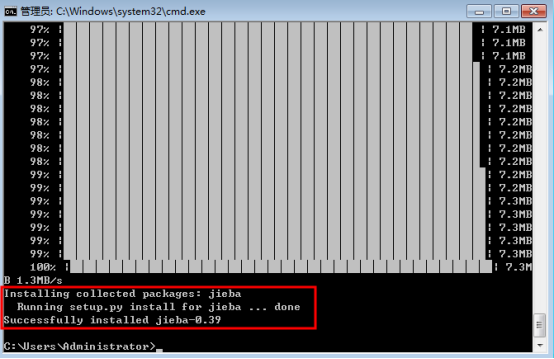
2、调用库函数
1、输入import jieba与使用其中函数
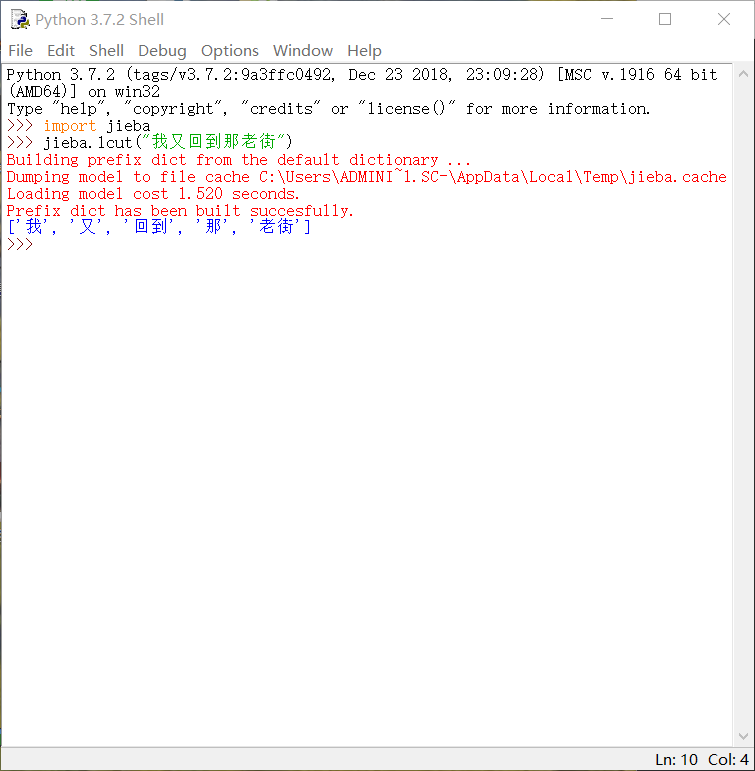
3、python代码
#! python3 # -*- coding: utf-8 -*- import os, codecs import jieba from collections import Counter def get_words(txt): seg_list = jieba.cut(txt) #对文本进行分词 c = Counter() for x in seg_list: #进行词频统计 if len(x)>1 and x != '\r\n': c[x] += 1 print('常用词频度统计结果') for (k,v) in c.most_common(20): #遍历输出高频词 print('%s%s %s %d' % (' '*(5-len(k)), k, '*'*int(v/2), v)) if __name__ == '__main__': with codecs.open('梦里花落知多少.txt', 'r', 'utf8') as f:
txt = f.read() get_words(txt)
• •显示效果
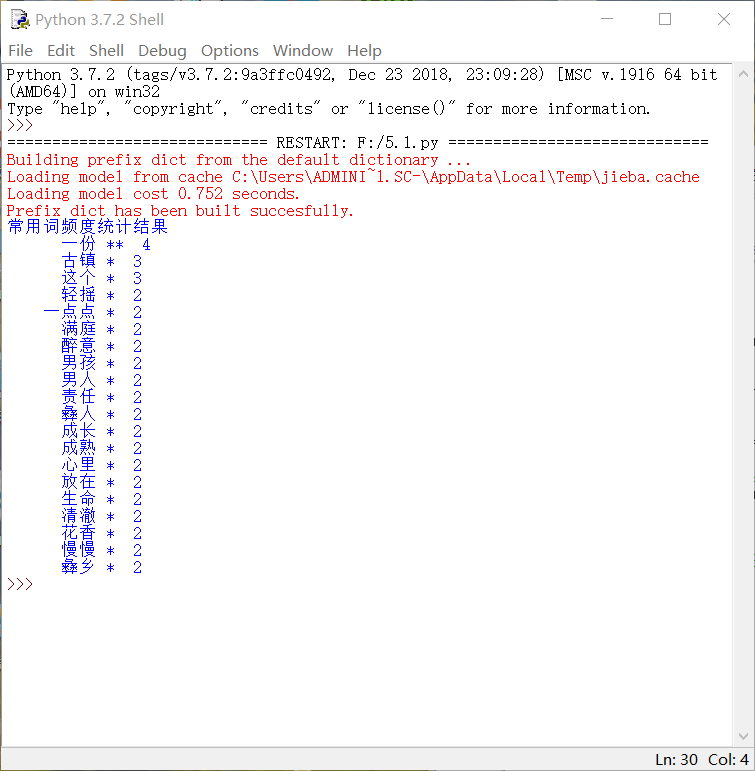
4、词云
import jieba import wordcloud f = open("梦里花落知多少.txt","r",encoding = "utf-8") #打开文件 t = f.read() #读取文件,并存好 f.close() ls = jieba.lcut(t) #对文本分词 txt = " ".join(ls) #对文本进行标点空格化 w = wordcloud.WordCloud(font_path = "msyh.ttc",width = 1000,height = 700,background_color = "white") #设置词云背景,找到字体路径(否则会乱码) w.generate(txt) #生成词云 w.to_file("govermentwordcloud.png") #保存词云图
• 词云显示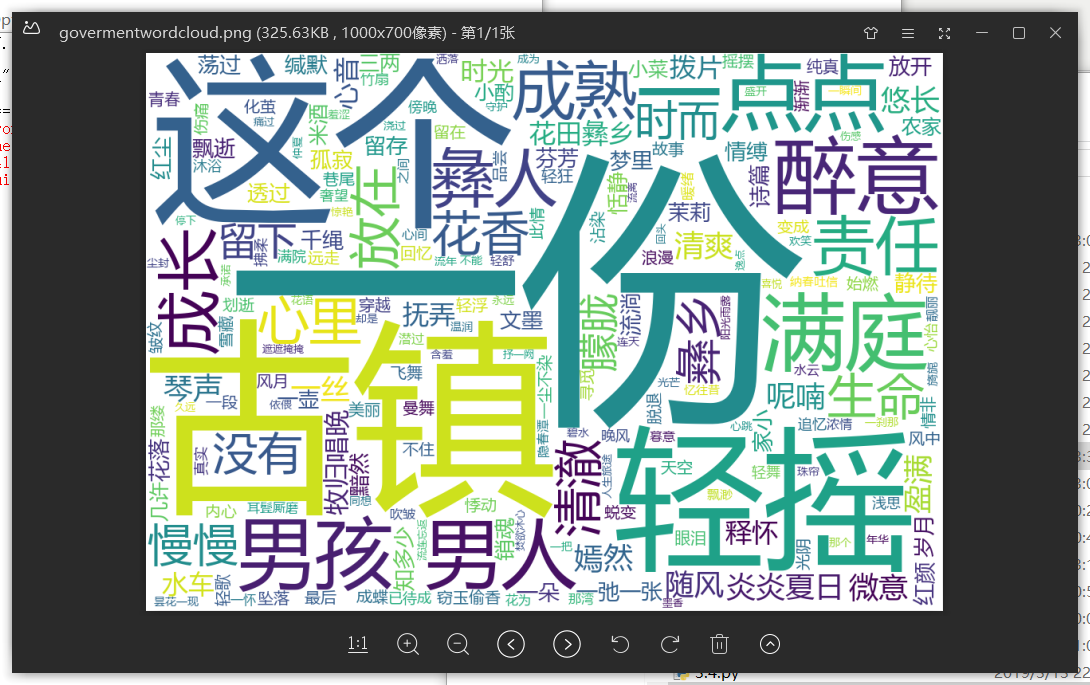















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









