







欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。
技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。
前面三篇写了线性回归,lasso,和LARS的一些内容,这篇写一下决策树这个经典的分类算法,后面再提一提随机森林。关于决策树的内容主要来自于网络上几个技术博客,本文中借用的地方我都会写清楚出处,写这篇[整理文章]的目的是对决策树的概念原理、计算方法进行梳理。本文主要参考文献的[1][2]的图片和例子。另外,[3]写的也比较仔细,有代码可以参考,可以看看。不过如果只想简单了解一下原理,看本文即可。
决策树
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果[1]。
下面先来看一个小例子,看看决策树到底是什么概念(这个例子来源于[2])。
决策树的训练数据往往就是这样的表格形式,表中的前三列(ID不算)是数据样本的属性,最后一列是决策树需要做的分类结果。通过该数据,构建的决策树如下:
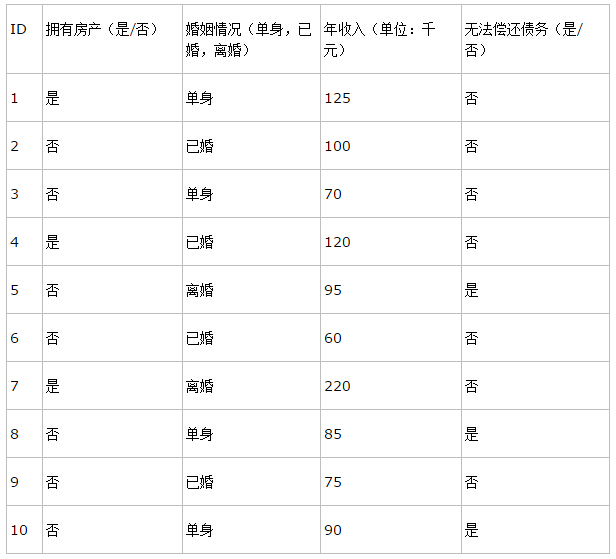
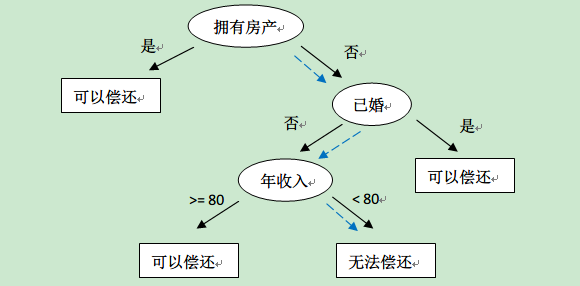
有了这棵树,我们就可以对新来的用户数据进行是否可以偿还的预测了。
决策树最重要的是决策树的构造。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况[1]:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
决策树的属性分裂选择是”贪心“算法,也就是没有回溯的。
ID3.5
好了,接下来说一下教科书上提到最多的决策树ID3.5算法(是最基本的模型,简单实用,但是在某些场合下也有缺陷)。
信息论中有熵(entropy)的概念,表示状态的混乱程度,熵越大越混乱。熵的变化可以看做是信息增益,决策树ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
设D为用(输出)类别对训练元组进行的划分,则D的熵表示为:
其中 pi表示第i个类别在整个训练元组中出现的概率,一般来说会用这个类别的样本数量占总量的占比来作为概率的估计;熵的实际意义表示是D中元组的类标号所需要的平均信息量。熵的含义可以看我前面写的 PRML ch1.6 信息论的介绍。
如果将训练元组D按属性A进行划分,则A对D划分的期望信息为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6854
6854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









