






Blog:https://blog.csdn.net/linchuhai/article/details/84677249
GitHub:https://github.com/huoyijie/AdvancedEAST
自然场景文本检测
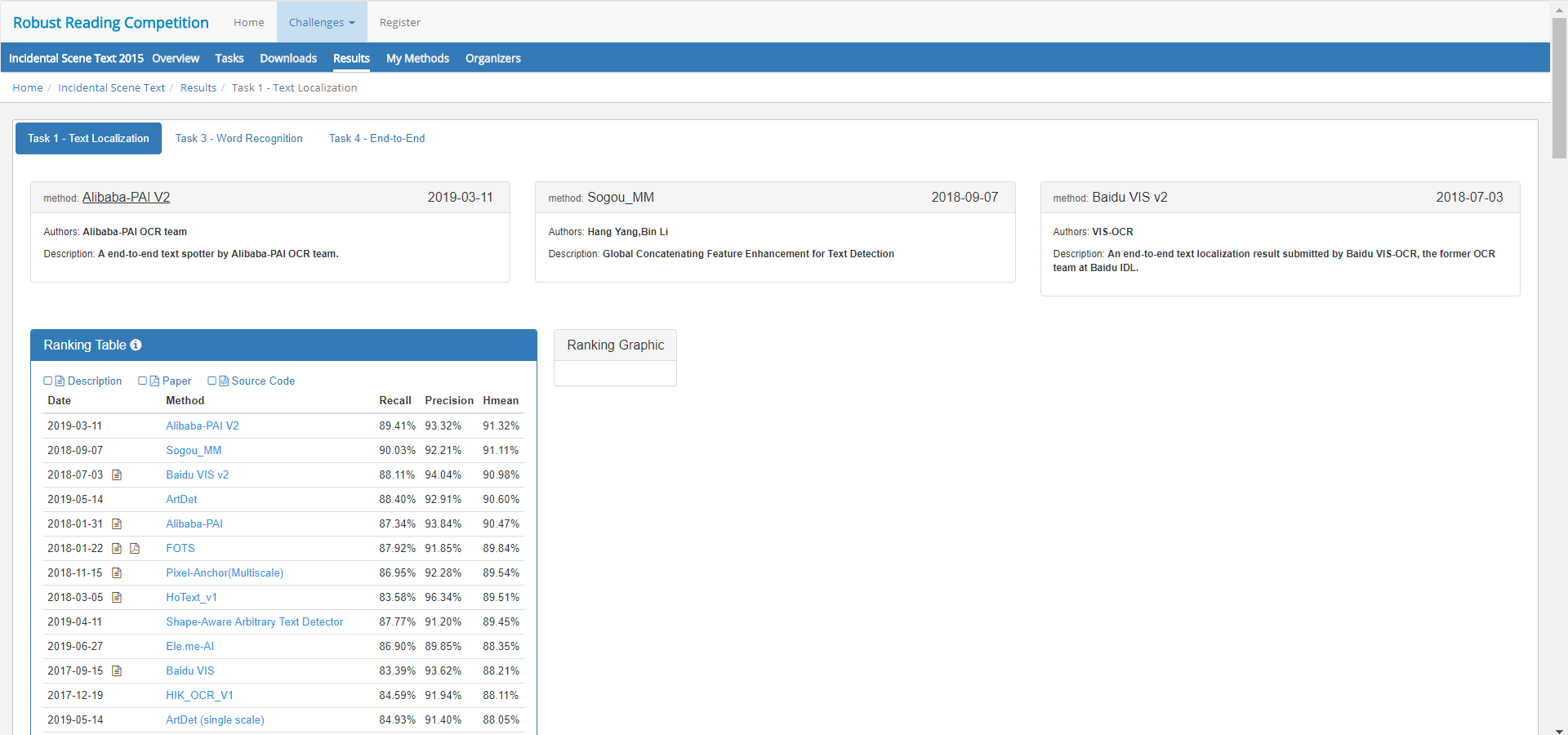
自然场景文字是图像高层语义的一种重要载体,自然场景文本检测是图像处理的核心模块,近年来ICDAR的历界比赛成绩不断提升:
Result:http://rrc.cvc.uab.es/?ch=4&com=evaluation&task=1>v=1
EAST
论文:旷视 - CVPR2017 - EAST: An Efficient and Accurate Scene Text Detector
开源:https://github.com/argman/EAST
优点:
1)步骤简化:传统的文本检测方法和一些基于深度学习的文本检测方法,大多是Multi-stage,在训练时需要对多个Stage调优,这势必会影响最终的模型效果,而且非常耗时。针对上述存在的问题,EAST提出了端到端的文本检测方法,消除中间多个Stage(如候选区域聚合,文本分词,后处理等),直接预测文本行,其架构就是下图中对应的E部分,跟前面的方法比起来的确少了比较多的过程。(类似于经典的CTPN架构)
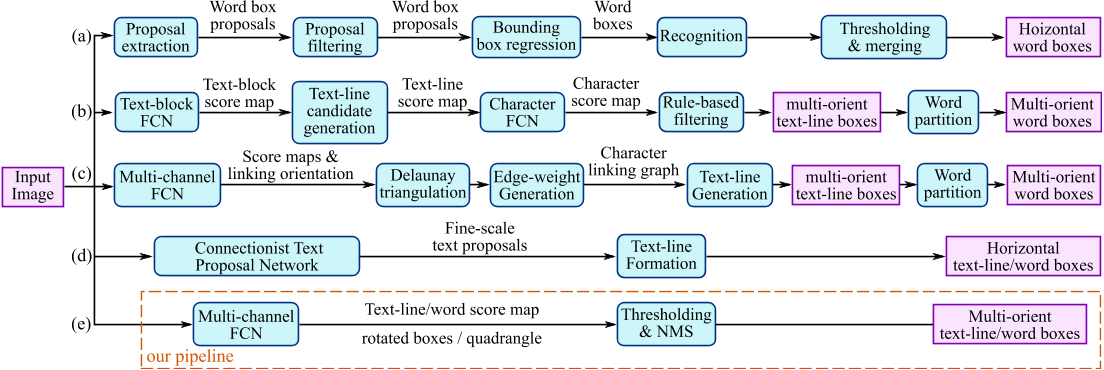
2)多方向文本定位:虽然CTPN方法在水平文本的检测方面效果比较好,但是对于竖直文本或者倾斜的文本,该方法的检测就很差,而EAST能支持多方向文本的定位。














 3786
3786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









