






一、hadoop集群环境配置
参见:《Hadoop2.6集群环境搭建(HDFS HA+YARN)原来4G内存也能任性一次.》
Win7环境:

登录用户名:hadoop , 与Hadoop集群中的Linux环境用户统一。
a.在SY-0130节点上修改hdfs-site.xml加上以下内容 ,并同步修改到其他节点。
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
旨在取消权限检查,原因是为了解决我在windows机器上配置eclipse连接hadoop服务器时,配置map/reduce连接后报以下错误,org.apache.hadoop.security.AccessControlException: Permission denied.
重启Hadoop集群。
二. windows基础环境准备
windows7(x64),jdk(64位),ant,eclipse(64位),hadoop2.6.0
1.jdk环境配置
jdk-6u45-windows-x64.exe 安装后好后配置相关JAVA_HOME环境变量,并将bin目录配置到path . 在此不要用JDK7或JDK8,后续说明为什么。
下载地址:http://pan.baidu.com/s/1kTn9mIj
2.eclipse环境配置
eclipse-jee-luna-SR1a-win32-x86_64.zip解压到D:\hadoop2.6\eclipse-jee-luna-SR1a-win32-x86_64
下载地址:http://pan.baidu.com/s/1dD5wv0P
3.ant环境配置
apache-ant-1.9.4-bin.zip解压到D:\hadoop2.6\apache-ant-1.9.4,配置环境变量ANT_HOME,并将bin目录配置到path
下载地址:http://mirror.bit.edu.cn/apache//ant/binaries/apache-ant-1.9.4-bin.zip
4.下载hadoop-2.6.0.tar.gz
http://pan.baidu.com/s/1kTpBenX
5.下载hadoop-2.6.0-src.tar.gz
http://pan.baidu.com/s/1o6yYzma
6.下载hadoop2x-eclipse-plugin-master.zip
https://github.com/winghc/hadoop2x-eclipse-plugin
我测试时候的版本:http://pan.baidu.com/s/12KD3o
7.下载hadoop-common-2.2.0-bin-master.zip
https://github.com/srccodes/hadoop-common-2.2.0-bin
我测试时候下载的版本:http://pan.baidu.com/s/1o6HptNW
分别将hadoop-2.6.0.tar.gz、hadoop-2.6.0-src.tar.gz、hadoop2x-eclipse-plugin-master.zip、hadoop-common-2.2.0-bin-master.zip
下载解压到D:\hadoop2.6下
如图:
SY-0130 192.168.249.130
SY-0131 192.168.249.131
SY-0132 192.168.249.132
SY-0133 192.168.249.133
SY-0134 192.168.249.133
三、编译hadoop-eclipse-plugin-2.6.0.jar 配置
win7下操作
1.添加环境变量HADOOP_HOME=D:\hadoop2.6\hadoop-2.6.0
追加环境变量path内容:%HADOOP_HOME%/bin
2.修改编译包及依赖包版本信息
修改D:\hadoop2.6\hadoop2x-eclipse-plugin-master\ivy\libraries.properties
hadoop.version=2.6.0 (我测试的时候,下载的文件中,该设置已经为2.6.0)
3.ant编译
进入CMD 命令行:
D:\hadoop2.6\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin>
ant jar -Dversion=2.6.0 -Declipse.home=D:\hadoop2.6\eclipse-jee-luna\eclipse -Dhadoop.home=D:\hadoop2.6\hadoop-2.6.0
编译好后hadoop-eclipse-plugin-2.6.0.jar会在D:\hadoop2.6\hadoop2x-eclipse-plugin-master\build\contrib\eclipse-plugin\目录下
四、eclipse环境配置
1.将编译好的hadoop-eclipse-plugin-2.6.0.jar拷贝至eclipse的plugins目录下,然后重启eclipse
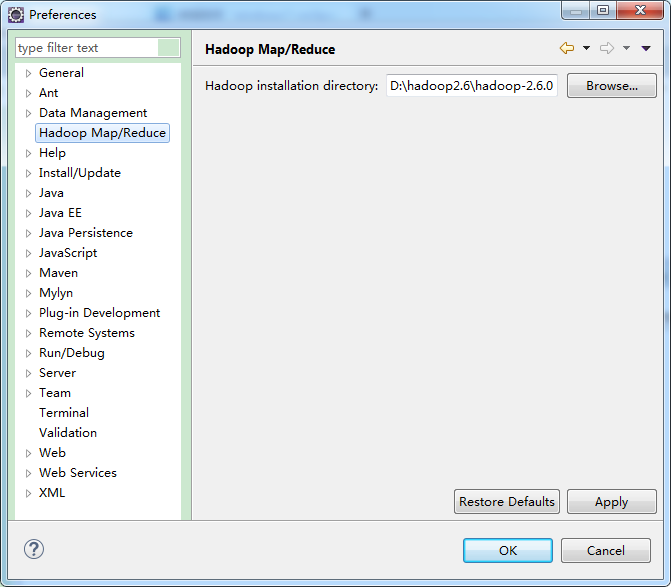
2.打开菜单Window--Preference--Hadoop Map/Reduce进行配置,如下图所示:
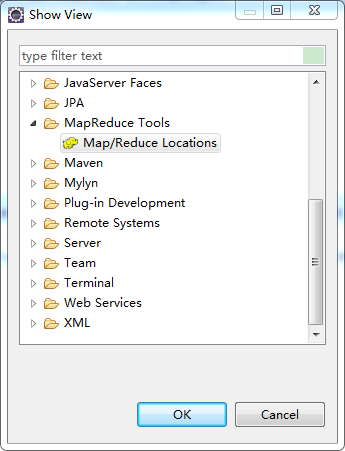
3.显示Hadoop连接配置窗口:Window--Show View--Other-MapReduce Tools,如下图所示:
4.配置连接Hadoop,如下图所示:

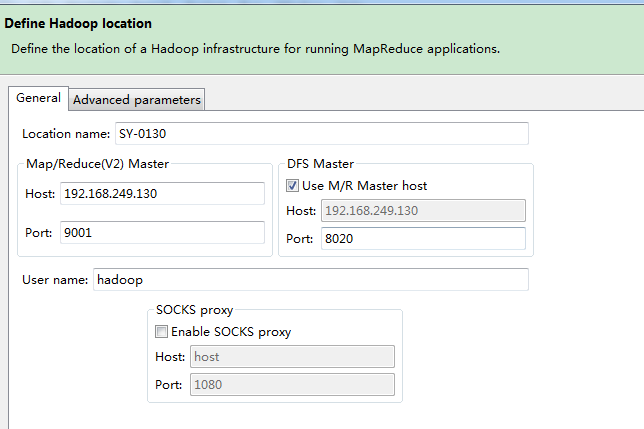
DFS Master : 就是core-site.xml文件中配置的
<name>fs.defaultFS</name>
<value>hdfs://SY-0130:8020</value>
查看是否连接成功,能看到如下信息,则表示连接成功:
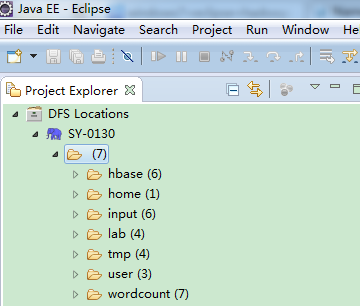
六、创建一个Map/Reduce Project
1.新建项目 File--New--Other--Map/Reduce Project 命名为MR1,
然后创建类org.apache.hadoop.examples.WordCount,从hadoop-2.6.0-src中拷贝覆盖
(D:\hadoop2.6\hadoop-2.6.0-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples\WordCount.java)
2.创建log4j.properties文件
在src目录下创建log4j.properties文件,内容如下:
log4j.rootLogger=debug,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.logger.com.codefutures=DEBUG
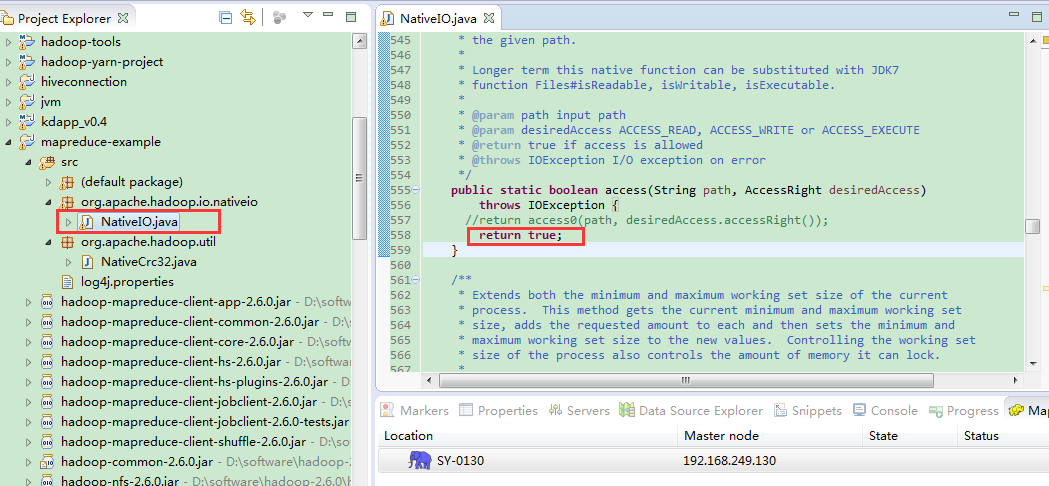
3.解决java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)异常问题
(由于你的环境和我的可能不一致,可以在后面出现相关问题后再进行修改)
拷贝源码文件org.apache.hadoop.io.nativeio.NativeIO到项目中
然后定位到access方法,直接修改为return true;
如下图所示:
需要hadoop.dll,winutils.exe
直接拷贝D:\hadoop2.6\hadoop-common-2.2.0-bin-master\bin目录下内容,覆盖D:\hadoop2.6\hadoop-2.6.0\bin
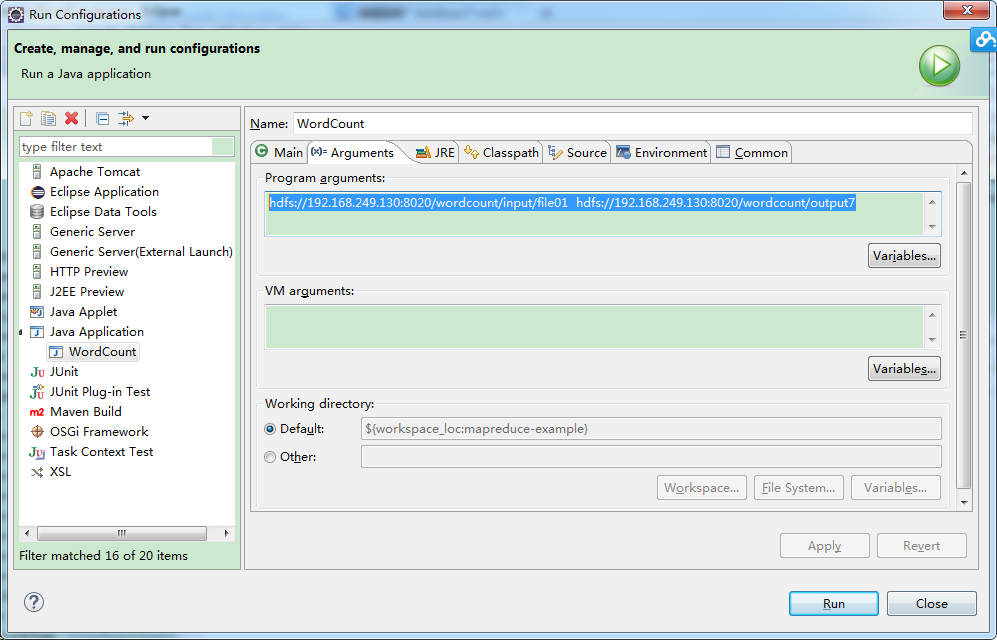
在eclipse中点击WordCount.java,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹
hdfs://192.168.249.130:8020/wordcount/input/file01 hdfs://192.168.249.130:8020/wordcount/output7
如下图所示:
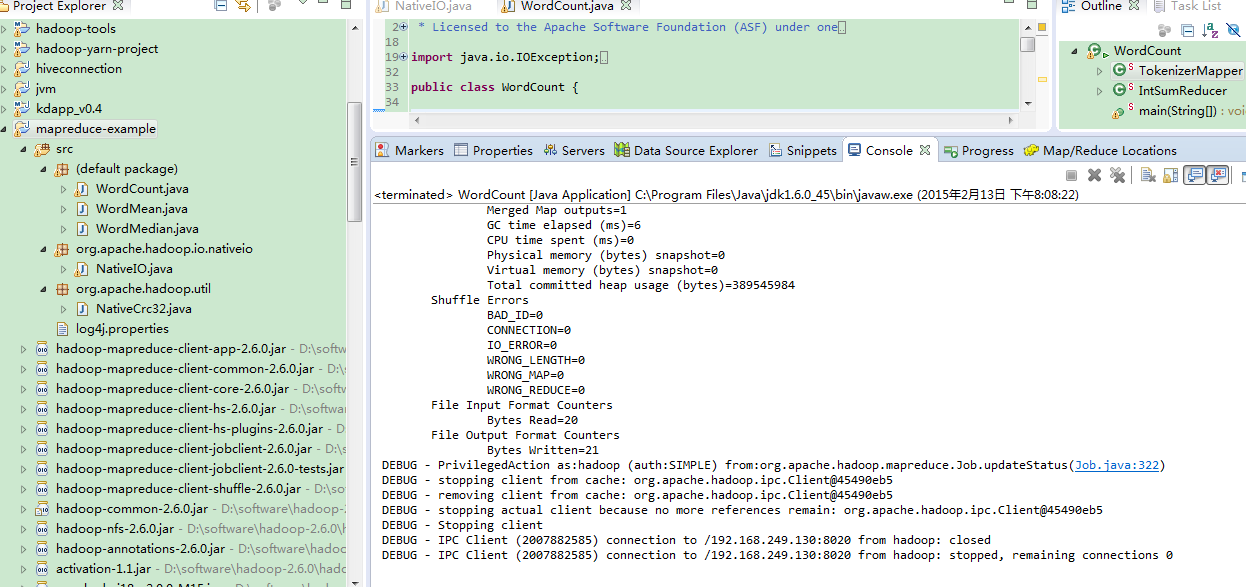














 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









