 Scrapy爬虫框架教程
Scrapy爬虫框架教程




 本文介绍了如何使用Scrapy爬虫框架创建一个简单的爬虫项目,并详细解释了项目目录结构及Item定义的方法。
本文介绍了如何使用Scrapy爬虫框架创建一个简单的爬虫项目,并详细解释了项目目录结构及Item定义的方法。
1.安装好Scrapy爬虫框架
2.切换到F盘的wooyun目录下执行:scrapy startproject zentao
这个命令会在当前目录下创建一个新目录zentao,它的结构如下:
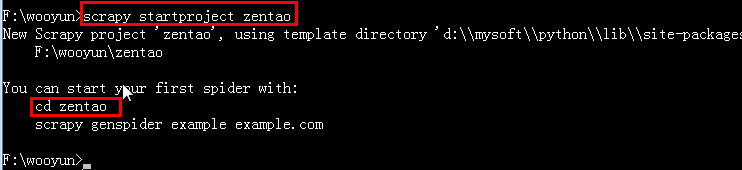
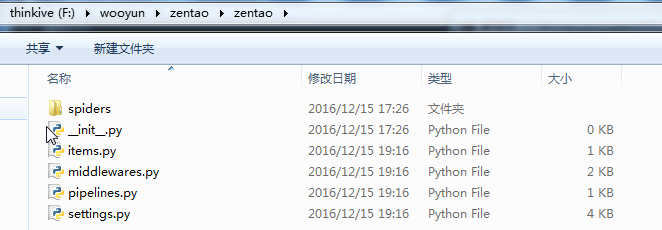
3.通过tree /f命令查看目录结果
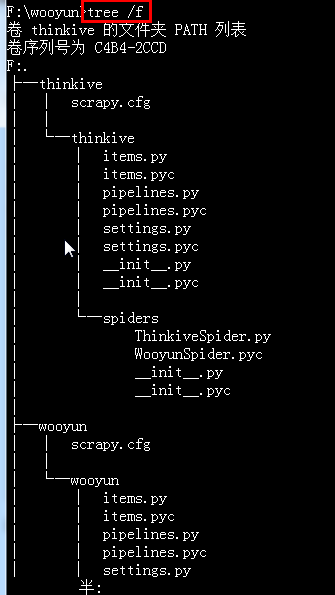
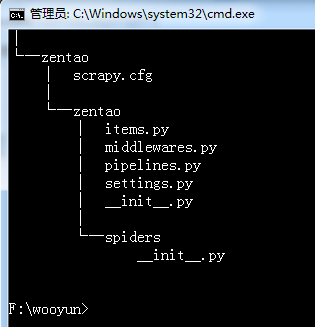
这些文件主要是:
- scrapy.cfg: 项目配置文件
- zentao/: 项目python模块, 呆会代码将从这里导入
- zentao/items.py: 项目items文件
- zentao/pipelines.py: 项目管道文件
- zentao/settings.py: 项目配置文件
- zentao/spiders: 放置spider的目录
定义Item
Items是将要装载抓取的数据的容器,它工作方式像python里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误。
它通过创建一个scrapy.item.Item类来声明,定义它的属性为scrpy.item.Field对象,就像是一个对象关系映射(ORM).
我们通过将需要的item模型化,来控制从dmoz.org获得的站点数据,比如我们要获得站点的名字,url和网站描述,我们定义这三种属性的域。要做到这点,我们编辑在tutorial目录下的items.py文件,我们的Item类将会是这样
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
刚开始看起来可能会有些困惑,但是定义这些item能让你用其他Scrapy组件的时候知道你的 items到底是什么。

















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









