






基于bs4库的HTML遍历方法
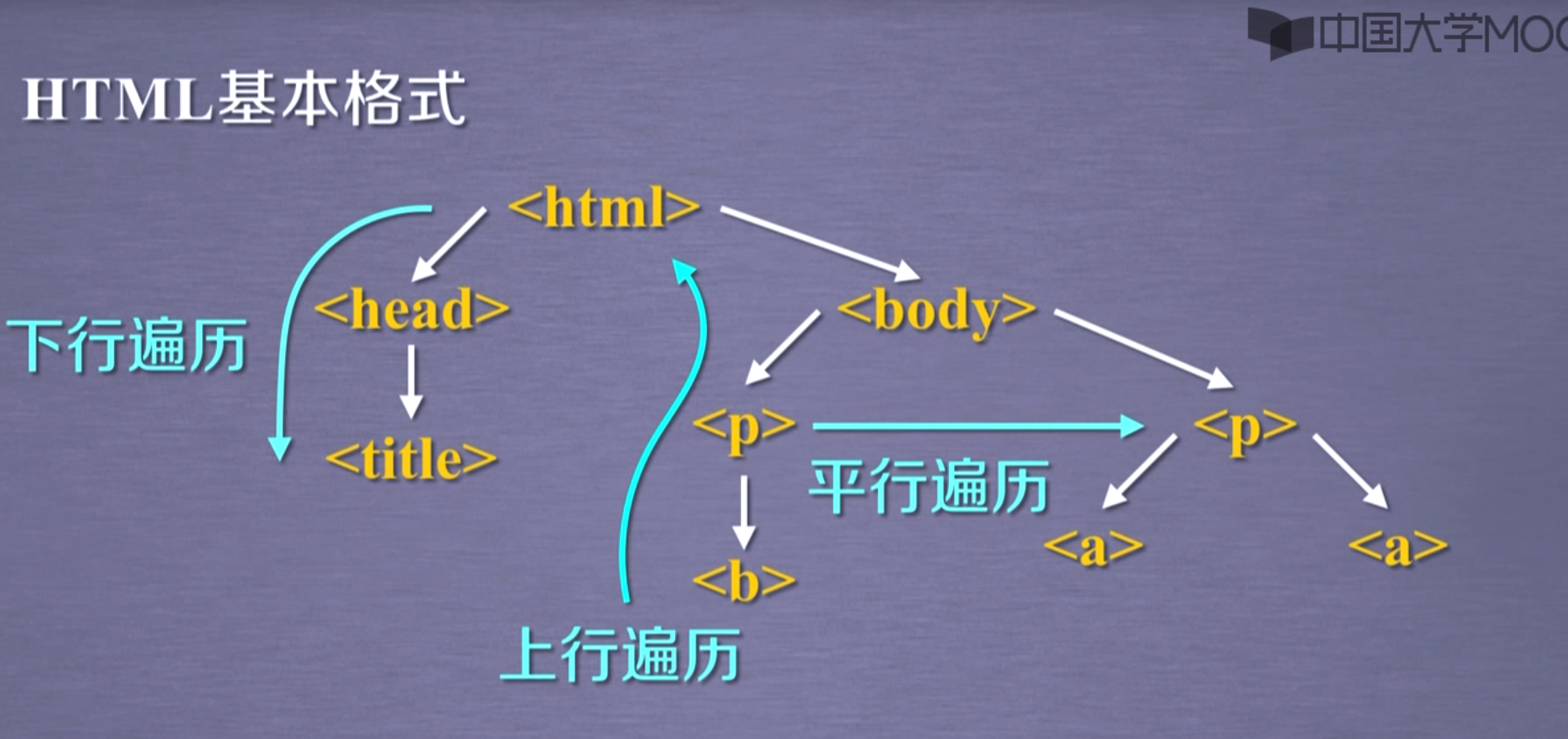
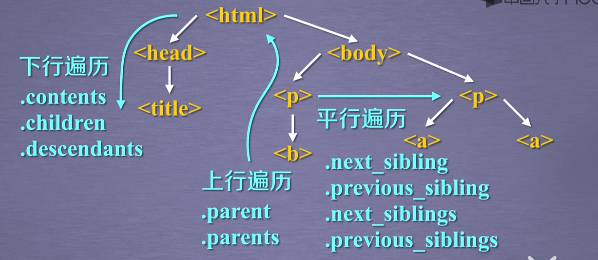
标签树的下行遍历

来手打栗子,依然是用上一节的demo
import requests
from bs4 import BeautifulSoup
r=requests.get('https://python123.io/ws/demo.html')
demo=r.text
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())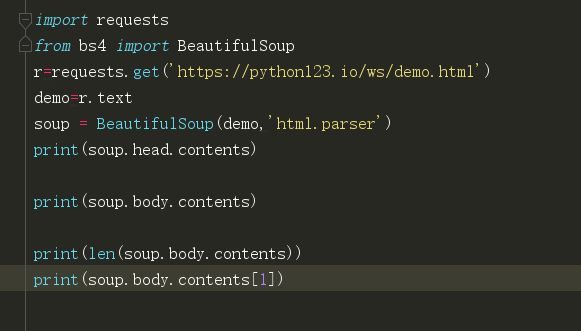
contents打印出了所有子标签,存在列表里展示
也可以通过索引取值。

标签树的上行遍历

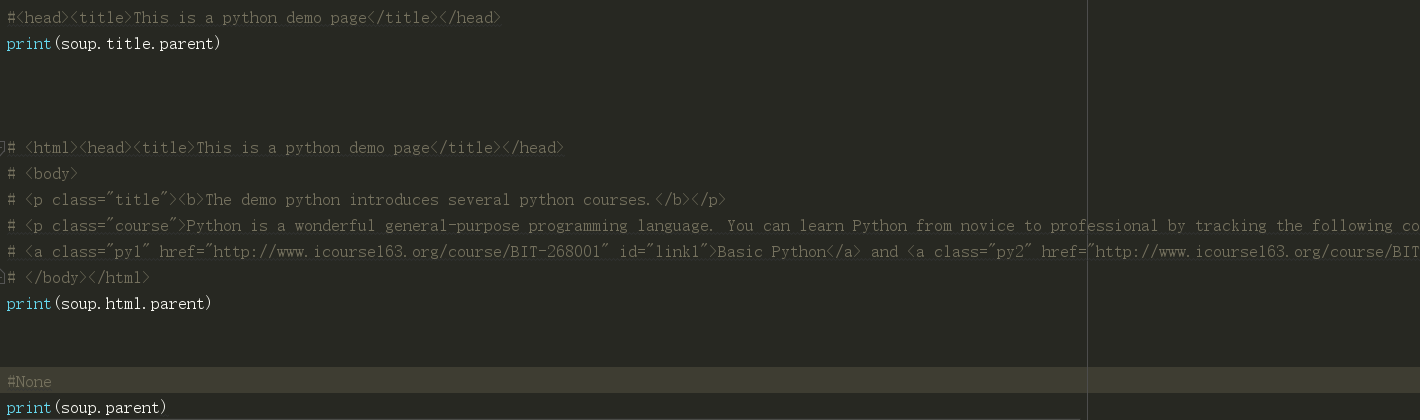
html已经是html的最高级标签了,没有父标签,所以他的父标签就是它本身。
因为 soup的父节点没有,所以返回了一个空
标签树的上行遍历

这里拿出了一个parents,注意不是parent,所以这里是以上所有的父标签,放入一个列表之中,就可以迭代了,他就会每次都输出一个父标签的名字了。
标签树的平行遍历

需要注意的是,平行遍历只发生在同一个父亲节点之下,若是另一个节点之下的标签,是不算他的平行节点的。
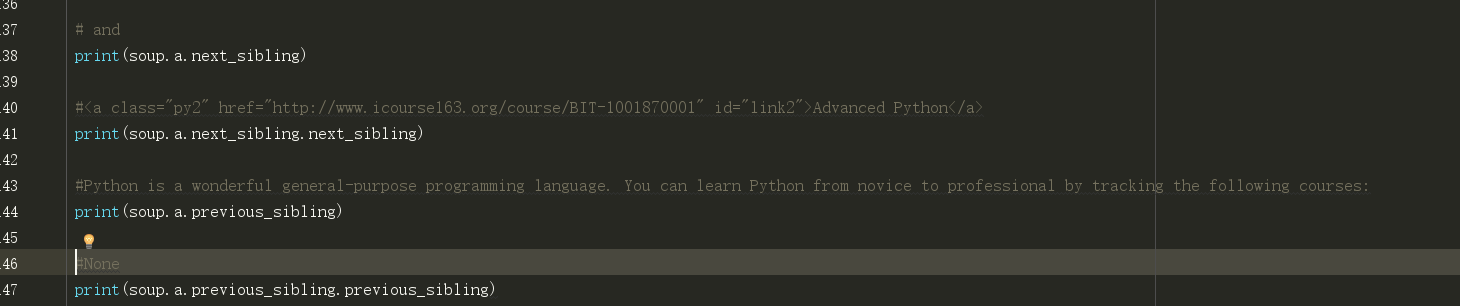
最后一个打印结果为None,因为他的上上个已经没有平行节点了,所以为空。

这个平行遍历就不多讲了。就是这样实现的,和遍历父节点是一个原理。















 3657
3657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









