






数据读取结构 - DataFrame
- Series (collection of values)
- DataFrame (collection of Series objects)
- Panel (collection of DataFrame objects)
DataFrame 可以理解为一个矩阵结构, 每一列都是一个 Series
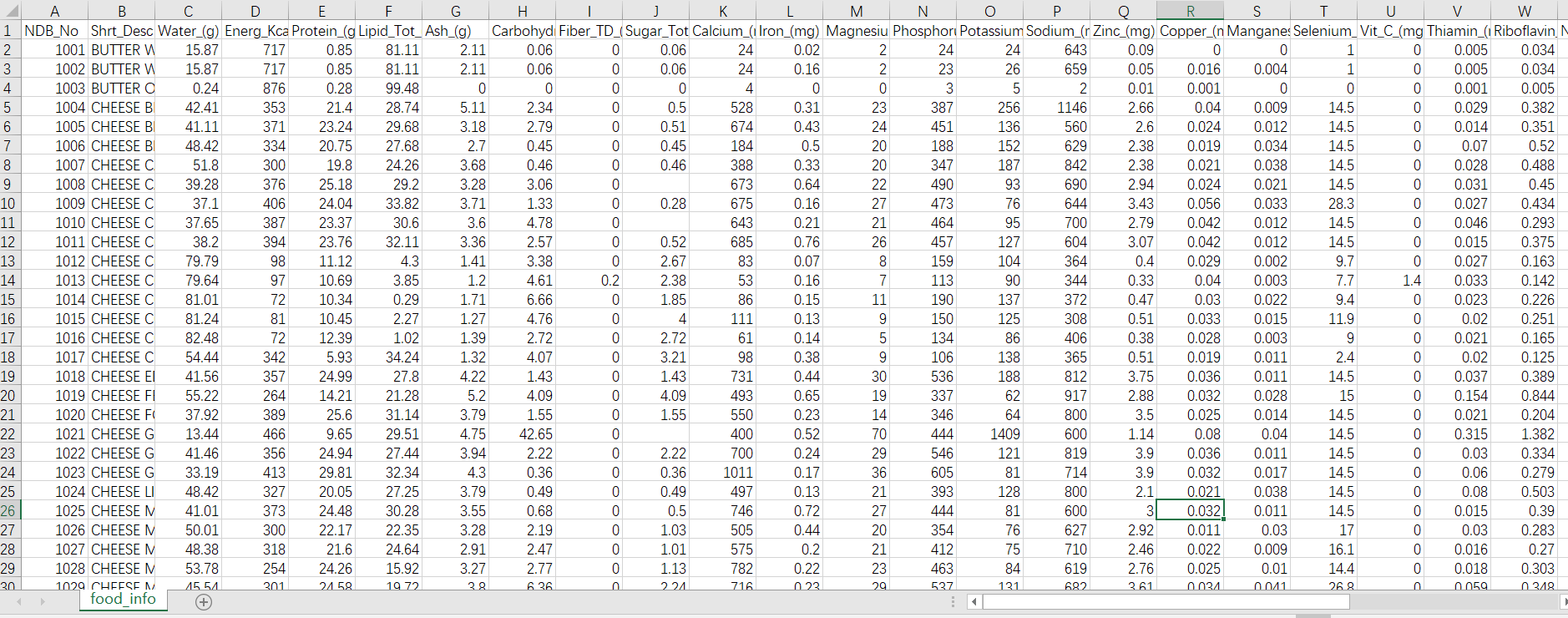
样本文件 food_info.csv
表示食品中的各种营养素指标
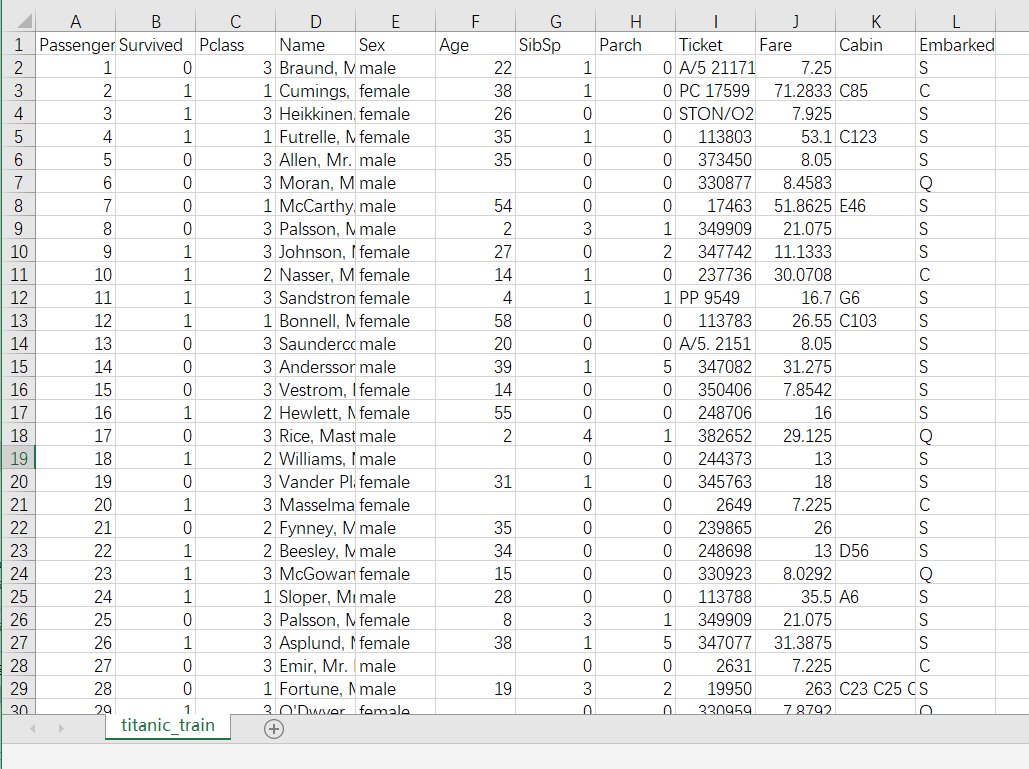
样本文件 titanic_train.csv
泰坦尼克号船员获救案例
属性
.dtypes 属性
查看 DataFrame 结构的内部数据类型
常见的属性值


.columns 属性
查看 DataFrame 的列名 (对应样本文件的每个营养素指标,得到一个 list 结构
也可以继续执行 .tolist() 方法返回一个列表


.shape 属性
查看维度, 空间结构表示 (行, 列)
用于查看规模

操作方法
read_csv 方法
读取 csv 文件转为为 DataFrame 类型

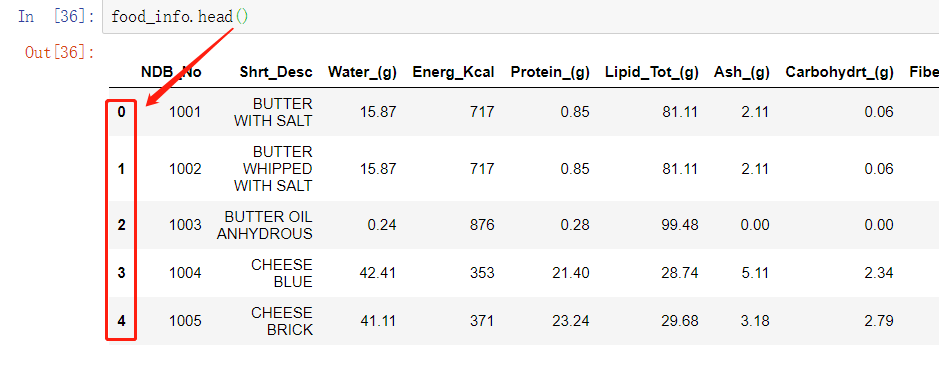
head 方法 / tail 方法
输出 头 / 尾 n 行数据
传入参数 count(int) 未指定时, 默认输出 5 行, 制定后输入指定行数

传给参数后会简化输出结果

取行 - loc 方法
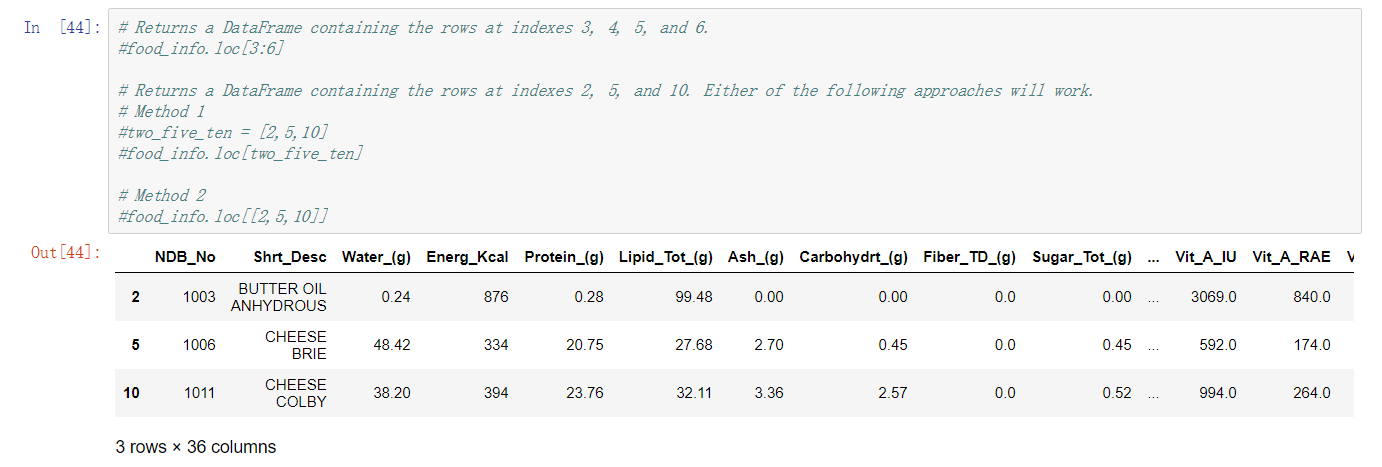
指定索引取值, 此处不直接使用索引而是用 loc 方法再次封装了一下
传入参数为 索引号, 当然指定不存在的索引是会报错的

使用此方法也可以基于索引进行切片,
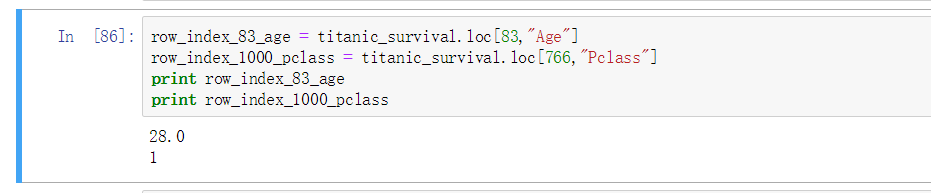
也可以直接定位到属性值而不是一行的样本, 格式如图, 先写行号在写属性名
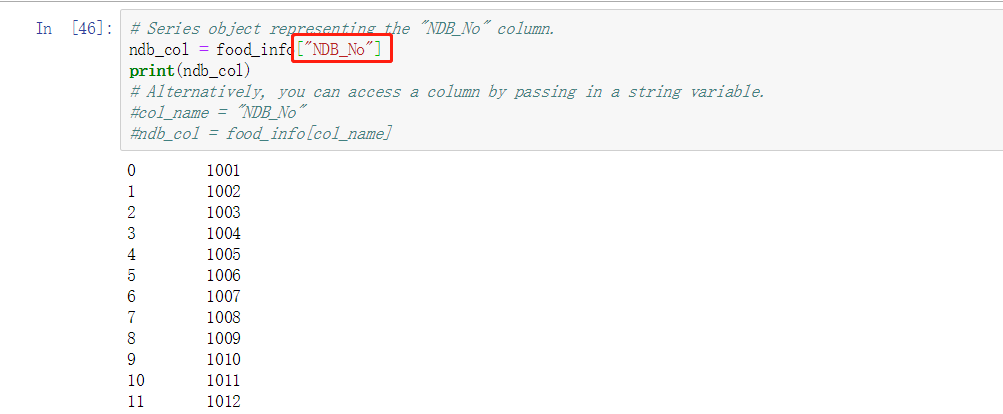
取列 - ["..."]
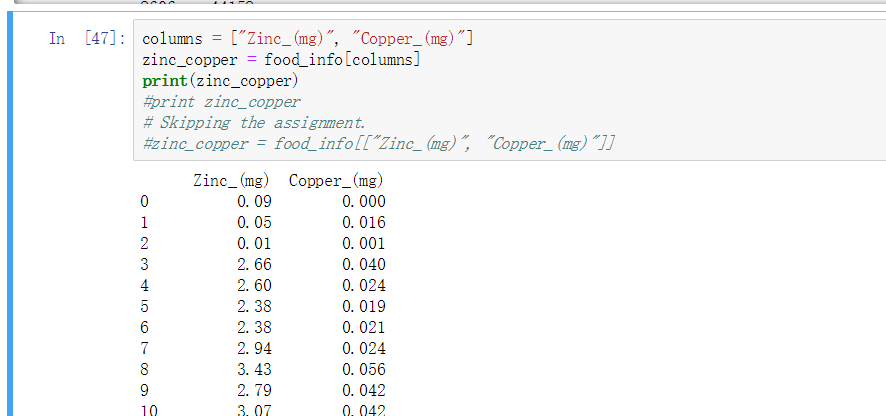
按照字段字符串来取这一列的值, 想取多个列就传入多个值
运算
类似于 numpy 中的运算, 都是对一列全部的数据进行运算


如果运算值也是列. 则列之间如果数据对应(维度一样)的话则每行的多列进行运算
运算后的结果可以再保存进去, 但是必须要求维度一致

运算函数
取到列之后进行函数调用, 可以进行最大值 .max , 最小值 .min , 均值 .mean 等运算


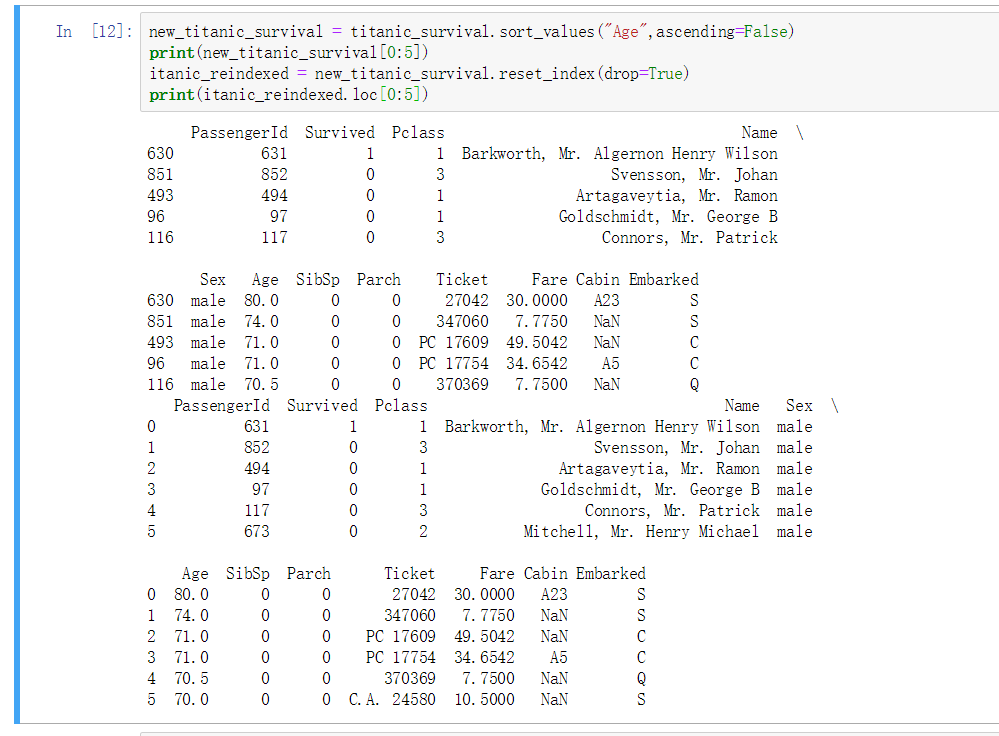
排序操作 - sort_values
参数 :
列名,
inplace - 在原有基础上还是新拿出来
ascending - 升序, 默认是True表示升序, 把 NaN 放在最后面

排序序号 - reset_index
使用 sort_values 后的指定的列排序成功了. 但是序号会按照之前的行号来处理. 看起来很不方便
使用 此函数进行 index 重新处理, 参数 drop 表示丢弃之前的序号
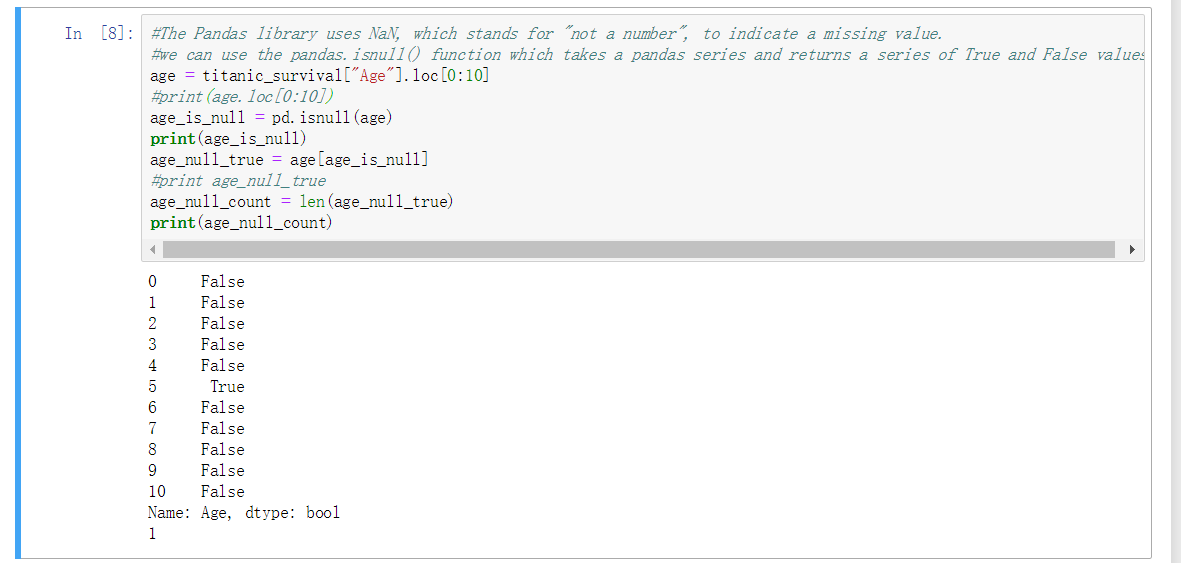
判断空值(缺失值) - isnull
pd.isnull( ) 传入一列, 进行判断空值输出 True/False 的列名映照序列
在 [] 中使用可以取出反向过滤非空值及行号, 也可以进行统计
丢弃指定值 - dropna
指定列的指定值进行丢弃
axis 指定丢弃值
subset 指定丢弃列

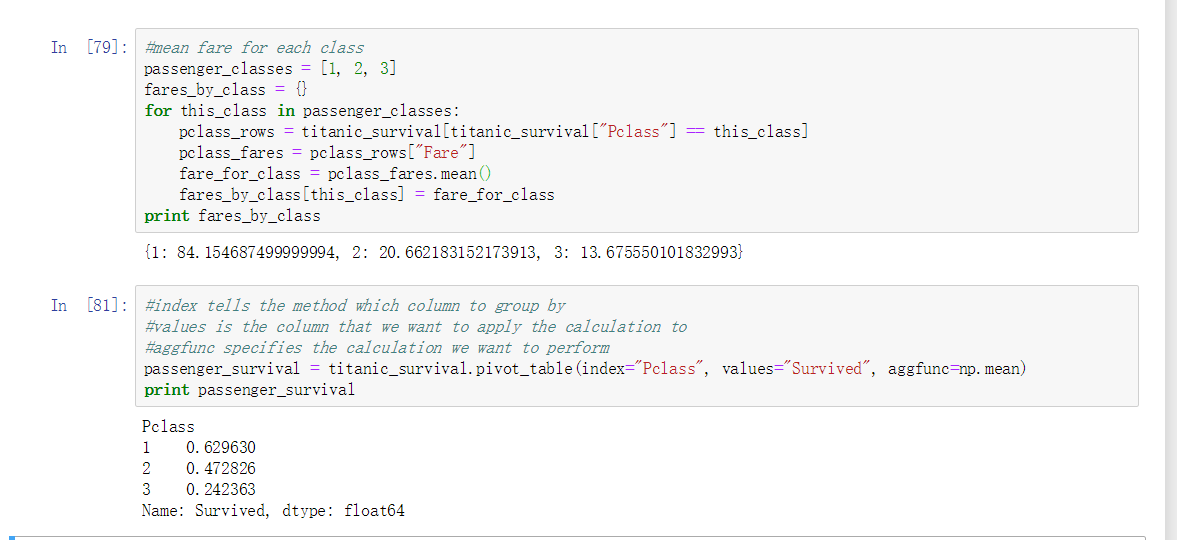
列关系运算 - pivot_table
正常思路按照 python 中的语法要进行比较繁琐的操作, 而 pandas 中进行了相应的封装
参数:
index 按照分类的列名, 基准, 不可以填入多个值
values 统计结果所用的变量, 可以填入多个值
aggfunc 统计结果的方式, 默认是 mean 均值方式
此处的案例: 求分析不同 Pclass (船舱等级) 的 Survived (获救人数) 的几率
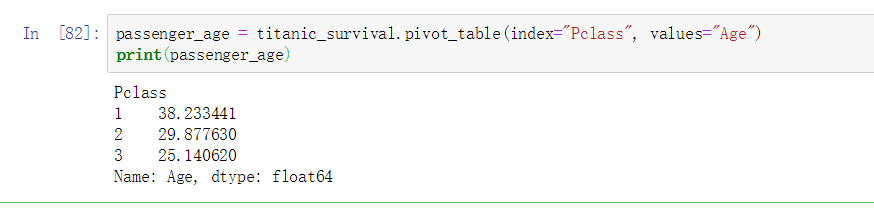
此处的案例: 求分析不同 Pclass (船舱等级) 的 Age (年龄) 的平均值
此处的案例: 求分析不同码头之间的船票价格以及获救与否之间的关系

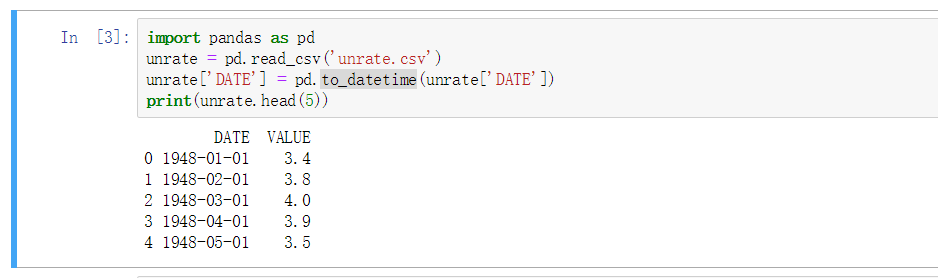
转换时间格式 - to_datetime
原有的时间格式是 1948/01/01 使用此函数可以转换为更标准时间格式
自定义函数 - apply
pandas 内置的函数不能满足自己的需求的时候可以自自定义函数来使用 apply 来进行调用处理
即再一次的封装使用更加方便
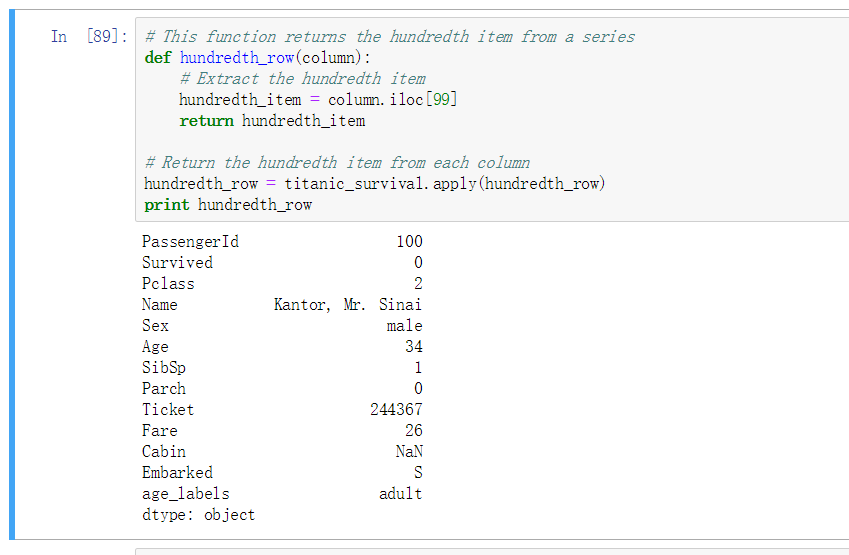
案例: 返回第100行数据
案例: 返回所有字段空值的计数

案例: 字段数据替换

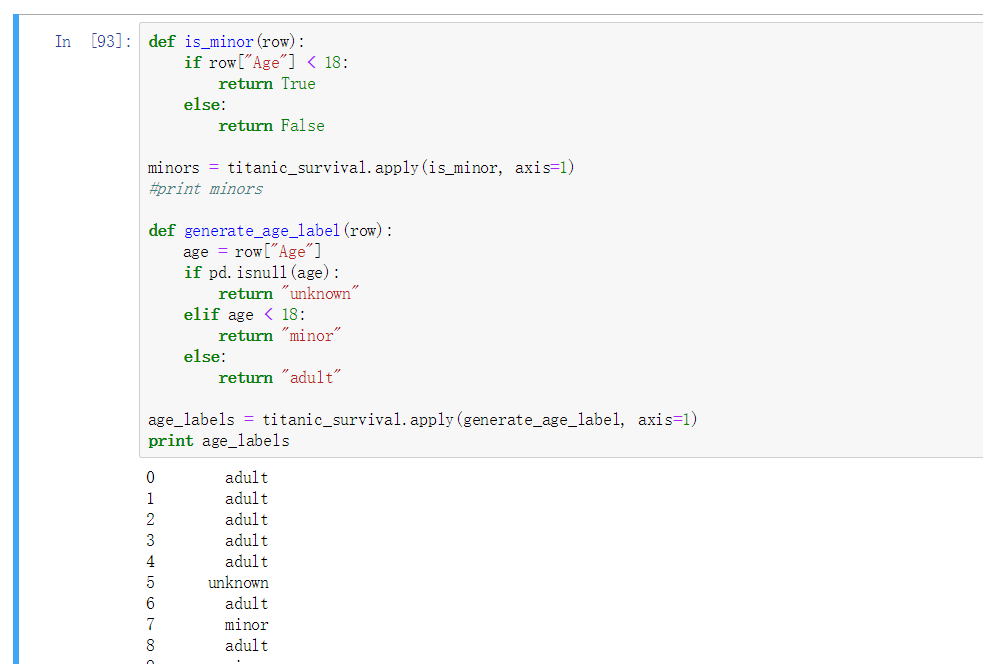
案例: 年龄判断
数据读取结构 - Series
DataFrame 中的每一列都是一个 Series

创建 Series
创建需要引入 Series 以及使用此类进行实例化
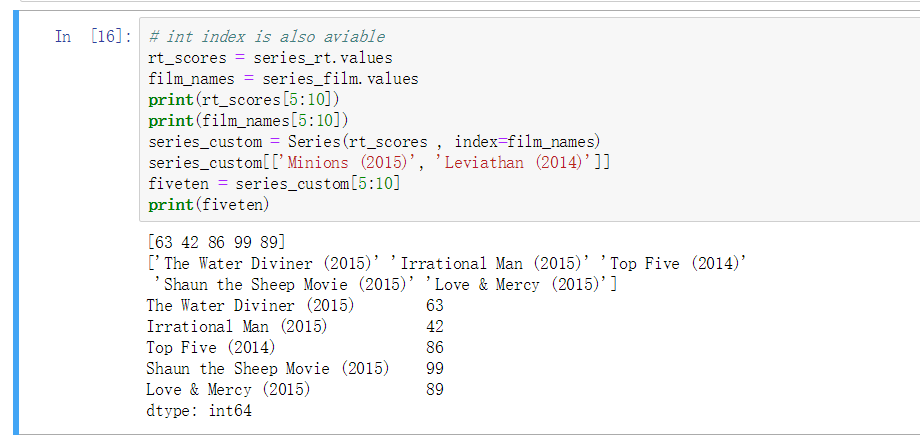
参数传递为 值以及 index 序号, index 可以设置为 字符串
通过 index 设置的字符串可以实现索引操作
属性
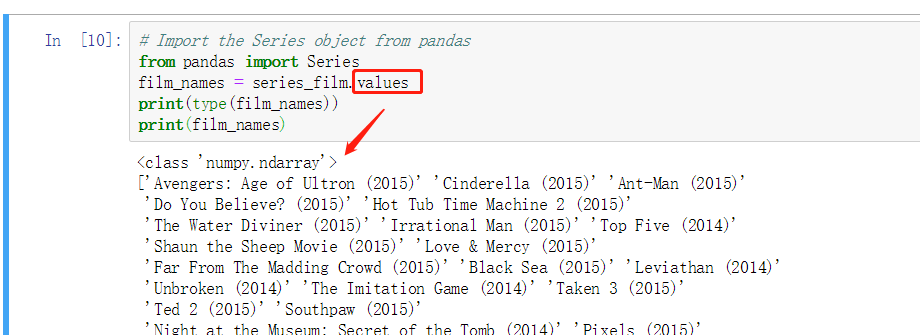
.values 查看所有值
类型本质为 ndarray
方法
排序
基本上很少用, 很少会对 Series 进行排序
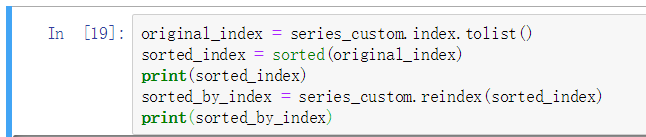

运算
相同维度的 Series 彼此可以直接运算
















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









