






上个月初,在Percona的博客中看到一篇关于计算存储的性能测试文章(详见文末的链接),其中提到的一些特性,引起了我的一些兴趣,于是,又扩展研究了一下计算存储相关的技术,突然发现计算存储这块对数据库系统来说,或许能多多少少解决一些瓶颈与痛点、甚至还能够在不影响性能的前提下大幅度降低TCO。是什么样的特性有如此魔力呢?
这里先卖个关子,文中提到的内容我们稍后再说,我们先来看看数据库系统的生命周期管理中,可能碰到哪些瓶颈与痛点。然后,再介绍计算存储是如何系统性地化解这些瓶颈与痛点的。
PS:以下内容仅代表个人观点。另外,由于本人对MySQL比较熟悉,下面以MySQL InnoDB引擎为例简单列举几个典型的痛点进行阐述
1、数据库系统中典型的瓶颈与痛点有哪些?
数据库性能的两个关键指标:(latency)与事务的并行数量(tps),两者相辅相成,且成反比,事务的latency越低,则允许tps就越高,反之,事务的latency越高,则允许的tps就越低。越高的tps就代表着越好的性能,反之就代表越低的性能。数据库对IO的响应延迟非常敏感,其直接影响着事务的响应延迟,而事务的响应延迟则在很大程度上决定着数据库的tps高低。因此,在一个硬件规格配置合理的服务器中运行MySQL数据库,且MySQL的索引使用比较规范的场景中,我们常常能够看到最先达到瓶颈的就是IO子系统
围绕着这2个关键指标,我这里罗列了4个可能出现瓶颈与痛点的典型场景,如下
1.1. 单台数据库服务器存储能力不足
存储容量不足
传统解决方案
* 时间紧迫时,可通过频繁删除文件来腾挪空间来临时解决
* 预算充足时,可更换更大容量的存储设备,做数据全量迁移
* 预算、时间充足时,可添加更多服务器做数据拆分
存储负载过高(吞吐量过高)
传统解决方案:
* 时间紧迫时,可以通过杀死存储吞吐量消耗最大的进程来临时解决
* 预算充足时,更换更高吞吐带宽的存储设备,做数据全量迁移
* 预算、时间充足时,可添加更多服务器做数据拆分
缺点:
临时解决方案需要频繁关注存储的负载情况,而且常常顾此失彼
更换配件需要增加额外的成本,做数据拆分更是增加了业务的复杂度和维护成本、而且还引入了一些新的问题(详见"1.4. 并发查询数过高导致数据库实例负载过高"中提到的缺点)
1.2. 数据库服务器内存不足
传统解决方案:
临时清理不需要的表数据或者调小MySQL在各种缓存分配上的参数值,以便腾出更多的内存来使MySQL Server能够做更多的事情
增加物理内存,并调大MySQL的各种缓冲分配参数值
缺点:
临时解决方案需要持续关注内存使用量,且需要频繁地操作,而且,这是挖东墙补西墙的做法
增加物理内存,除了增加成本之外,还会对业务造成一定影响(服务器需要关机)
1.3. 单个事务过大导致查询性能低下
传统解决方案:将大事务拆分成小事务
无法拆分的大事务,在硬件规格不变的前提下,可以对读写事务分别做一些优化。例如:写可以在执行前,会话级别将binlog格式修改为statement,以减少主从实例之间传输的binlog日志量;读事务可以拆分到只读从库中,以减少主库的访问压力
缺点:
将大事务拆分成小事务,并不会让原本大事务需要完成的工作任务少做一些,而是拆分成小事务之后,降低对其他并行事务的影响(例如:大事务可能长时间的持有锁、二进制日志文件句柄资源等,从而导致长时间的阻塞其他并行事务,导致并行事务执行失败)
1.4. 并发查询数过高导致数据库实例负载过高
传统解决方案:
杀死高负载查询会话、后续优化慢查询
读写分离,并增加只读从库,扩展只读能力
数据拆分,将数据分散到多个数据库实例中,扩展读/写能力。
* 对大表做数据拆分,先做垂直拆分(按业务拆分,将不同业务的字段拆分到不同的表、或不同的数据库、甚至不同的实例中),然后做水平拆分(对于无法继续拆分字段的表,如果数据量仍然大到影响性能,则可能还需要以不超过1000W行数据量的标准继续对大表执行拆分,即就是我们常说的数据分片)
缺点:无论是垂直拆分还是水平拆分,都需要应用配合相应的改造,而且,数据拆分之后,会引入新的痛点,类似如下(虽然这些痛点可以通过技术改造来解决,但成本过高,而且需要较长时间来磨合才能够使其达到稳定,另外,可能需要和业务深度契合改造,不同的客户可能需要做不一样的改造):跨分片访问,导致不得不启用分布式事务来保证跨分片访问的数据一致性,而分布式事务本身除了实现起来有一定工程量之外,应用本身也需要配合改造
如果分片跨了不同的实例,则无法做到数据的全局一致性备份,要实现跨实例多数据分片的全局数据一致性备份,需要中间件、数据库都做一些改造
不受事务控制的DDL语句,无法通过分布式事务来保证数据的全局一致性,因此,还需要额外的机制来保证数据的全局一致性
如果分片数据出现倾斜、或者访问负载出现倾斜,则还可能需要频繁地做分片数据的迁移(将大数据量的分片、高负载实例中的分片,迁移到较为空闲的实例中)
2、计算存储是如何解决数据库的瓶颈与痛点的?
针对计算存储,我这里列出3个我认为比较重要的特性,先对其原理做简单的介绍(关于相关原理的详细介绍,可参考文末的链接),然后再说说这些特性是如何解决上述数据库的瓶颈与痛点的
第一个重要的特性:存储支持硬件级别的原子写
数据库为何需要原子写?
* InnoDB 数据文件默认的Page Size为16k,文件系统默认的块大小为4k,也就是说,InnoDB数据文件的最小IO操作单位是16k,文件系统最小IO操作单位是4k,当InnoDB数据文件写入一个16k的页到文件系统时,文件系统需要将其分解成4个4k大小的块,再写入到存储设备中。由于大部分的文件系统并不支持原子写,如果文件系统在写入存储设备期间,发生了意外(例如掉电),则可能导致InnoDB的Page Size发生部分写(损坏),进而导致MySQL Server无法正常启动
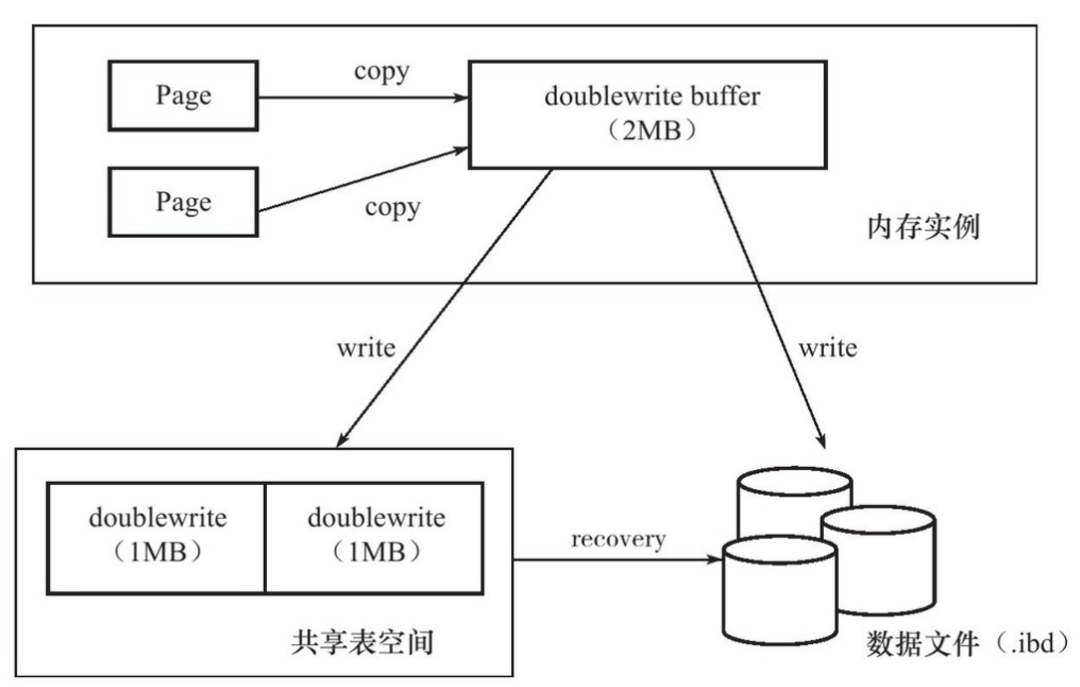
* 为了避免这个问题,InnoDB引入了doublewrite特性,doublewrite用来做什么的呢?当有数据需要写入数据文件时(即刷脏),先写入doublewrite(MySQL 8.0.20版本之前,doublewrite位于共享表空间ibdata1中,8.0.20版本开始,使用独立的文件存储,且支持多个文件,但文件的最大数量是buffer pool instance的2倍,即每个buffer pool instance有2个doublewrite文件),每次1MB连续写入,数据页写入doublewrite成功之后,再将数据页写入到数据文件中,这样一来,如果发生意外导致数据页发生损坏,则在数据库执行Crash Recovery期间,会尝试从doublewrite中找到发生损坏的页进行覆盖修复,修复之后即可正常启动MySQL Server(注:Redo虽然能够支持数据恢复,但它记录的是数据页的增量修改内容,并不是记录的完整的数据页,但doublewrite中的数据页是完整的,所以,可以使用doublewrite中的完整数据页恢复损坏的数据页,然后就能够正常应用Redo)
* doublewrite分成2个部分,内存中有2M的doublewrite buffer,磁盘文件中也有2个1M的连续doublewrite空间,引入doublewrite之后的数据写入简单示意图如下,从图中我们可以看到,脏数据要成功写入到数据文件中,需要写2次磁盘(一次写入到doublewrite中,一次写入到数据文件中)
计算存储支持原子写,对数据库的收益是什么呢?
* 既然存储支持硬件级别的原子写,那么,也就是说,数据库层面的doublewrite特性就可以关掉了,关掉之后,脏数据写入到数据文件只需要一次写磁盘即可,从而节省了一半的刷脏流量。即,在能保证数据页不发生部分写的情况下,直接就能缓解存储吞吐能力不足的燃眉之急!
第二个重要的特性:数据透明压缩/解压
数据库为何需要压缩/解压?
* 简单来说,就是在数据量达到一定程度之后,大幅度节省存储成本,降低存储的TCO
什么是数据透明压缩/解压?我们可以从目前几种主流的压缩/解压方式的角度着手来理解
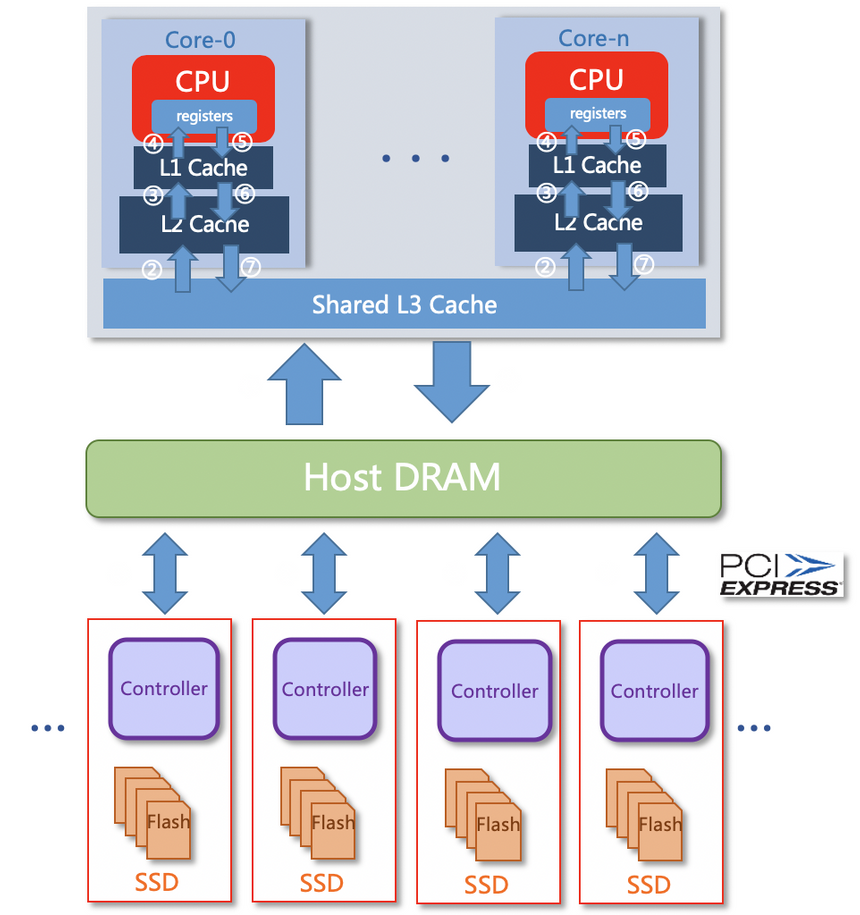
* 软压缩/解压(即CPU压缩):如下图所示,依赖主机CPU执行压缩与解压运算,存在大量数据复制且复制链路长,且压缩与解压运算逻辑需要应用程序自行实现与控制
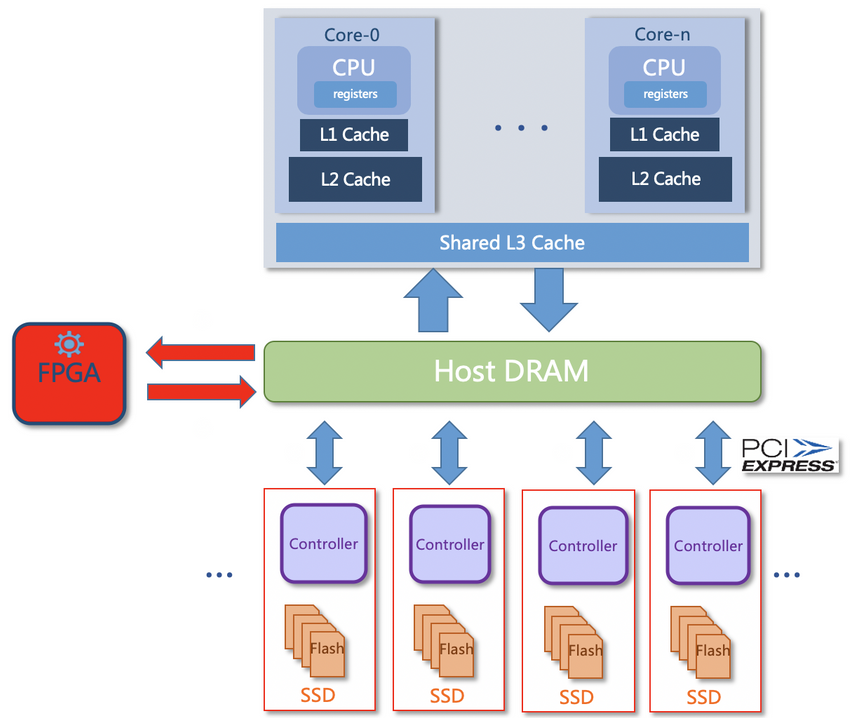
* 硬件压缩/解压(压缩卡):如下图所示,依赖占用PCI插槽的专用压缩卡执行压缩与解压运算,虽然释放了主机CPU资源,但仍然需要在主机内存与压缩卡之间大量拷贝数据,占用大量的主机带宽资源
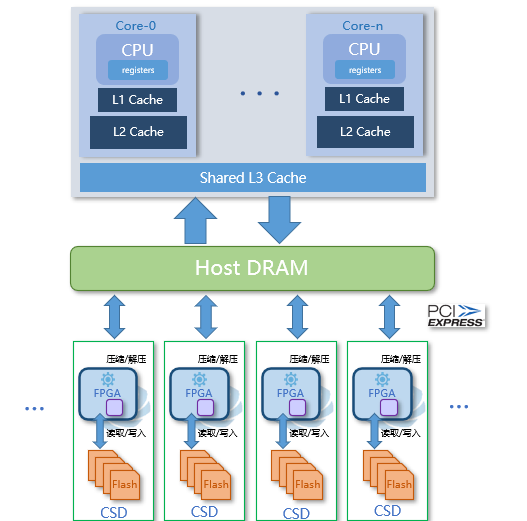
* 透明压缩/解压:如下图所示,压缩/解压的运算工作,直接由存储卡上集成的计算单元执行,对应用完全透明,数据的压缩与解压完全是在盘内执行,释放主机CPU资源的同时,也释放了主机带宽资源,也不需要在主机内存与压缩卡之间大量拷贝数据(零拷贝),而且,扩展存储卡时可同时扩展压缩/解压的计算单元,能够同时实现并行的压缩/解压运算
计算存储支持透明的压缩/解压,对数据库的收益是什么呢?
* 在对应用透明、不占用主机任何资源的前提下,大幅度降低存储成本
* 在存储卡的存储单元中,存放的数据是经过压缩的,因此,大幅度减少存储数据量,对于固态存储元器件来讲,就意味着可以大幅度降低写放大,而写放大的降低能够让固态存储元器件最大化地发挥性能优势,降低IO响应延迟。因此,对于数据库来说,在实现了数据压缩的情况下,能够不影响性能,甚至性能还能有一定提高(尤其是MySQL数据库,在数据量达到一定大小之后,随着压缩比的提升,使用计算存储的透明压缩 + 关闭doublewrite,在某些场景下性能甚至有大幅度的提高)
* 因为压缩功能使得binlog占用物理空间减少,从而也降低因为存储空间不足,清理binlog的频率,同时,由于压缩/解压功能是在盘内进行(写入数据时先由盘内的计算算元进行压缩,然后再存入存储单元;读取时先从存储单元中读取,然后再由盘内的计算单元进行解压),也进一步降低了对存储设备的吞吐带宽的占用
* InnoDB的Buffer Pool主要是用于减少IO操作的,读写IO响应延迟的降低,意味着对主机内存的依赖也就随之减少,也就是说,InnoDB的Buffer Pool可以设置得更小,也就是说,可以进一步释放主机的内存资源,将其更多地用于处理用户的连接请求
第三个重要的特性:计算下推到存储(当然,不同业务需要下推的计算逻辑可能有所不同,因此,不通用的计算逻辑下推,可能需要联合研发)
数据库为何需要将计算下推到存储?
* 生产环境中实际的查询类型,非等值查询(如:非唯一索引查询、联结表查询等)往往占比较高,而这些查询(尤其是查询条件涉及到多列时),在没有类似MySQL的ICP特性支持的情况下,从存储引擎读取的数据量往往会超过它们真实需要的数据量(例如:满足所有查询条件的数据可能只有10行,而实际上从存储引擎读取的数据量是100行),这是因为MySQL在执行查询时,会选择一个条件列在存储引擎中做数据的检索,将检索到的数据返回到MySQL Server,再用其余的条件列做数据过滤,过滤出满足所有条件的数据,然后再返回给客户端。这个过程中,被过滤掉的数据,其实是一种浪费,如果使用了类似MySQL ICP的特性,则可以将所有的条件列都下推到存储引擎层,直接返回满足所有条件列的数据,就不需要读取不满足所有条件的数据了。
* 虽然MySQL ICP的特性,能够避免从存储引擎读取的不必要的数据,但是,存储引擎层的过滤计算也仍然需要消耗主机CPU资源,能不能够将计算量进一步下推到存储设备呢?能!
什么是计算下推到存储?下面用三个图简单说明计算下推到存储的实现逻辑
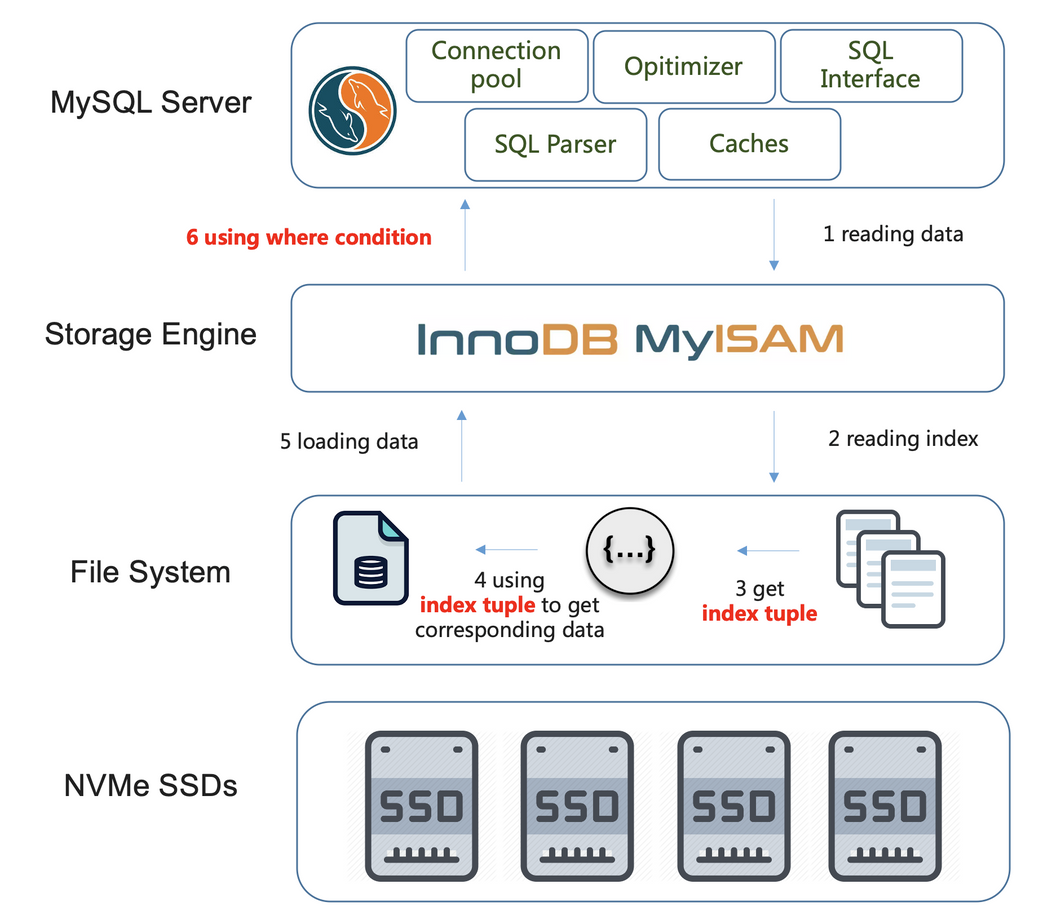
* 假设某个存在多个条件列的查询(注:这里假设多个条件列都是索引列,下不赘述),在没有类似MySQL ICP特性支持的情况下,查询执行的流程大致如下图(注意红色字体,下不赘述)。假设查询能够使用到多列索引,则会先使用索引顺序的第一个列进行数据检索(检索列),从存储引擎获取数据,然后,在MySQL Server层使用其余的条件列(过滤列),过滤出满足所有条件的数据
* 如果上述查询,有类似MySQL ICP特性支持的情况下,那么查询就能够避免从存储引擎中读取不满足所有条件的数据了,如下图,将所有的条件列(必须是索引列)都下推到存储引擎层,只读取匹配所有条件列的数据,就不再需要在MySQL Server层做数据过滤了 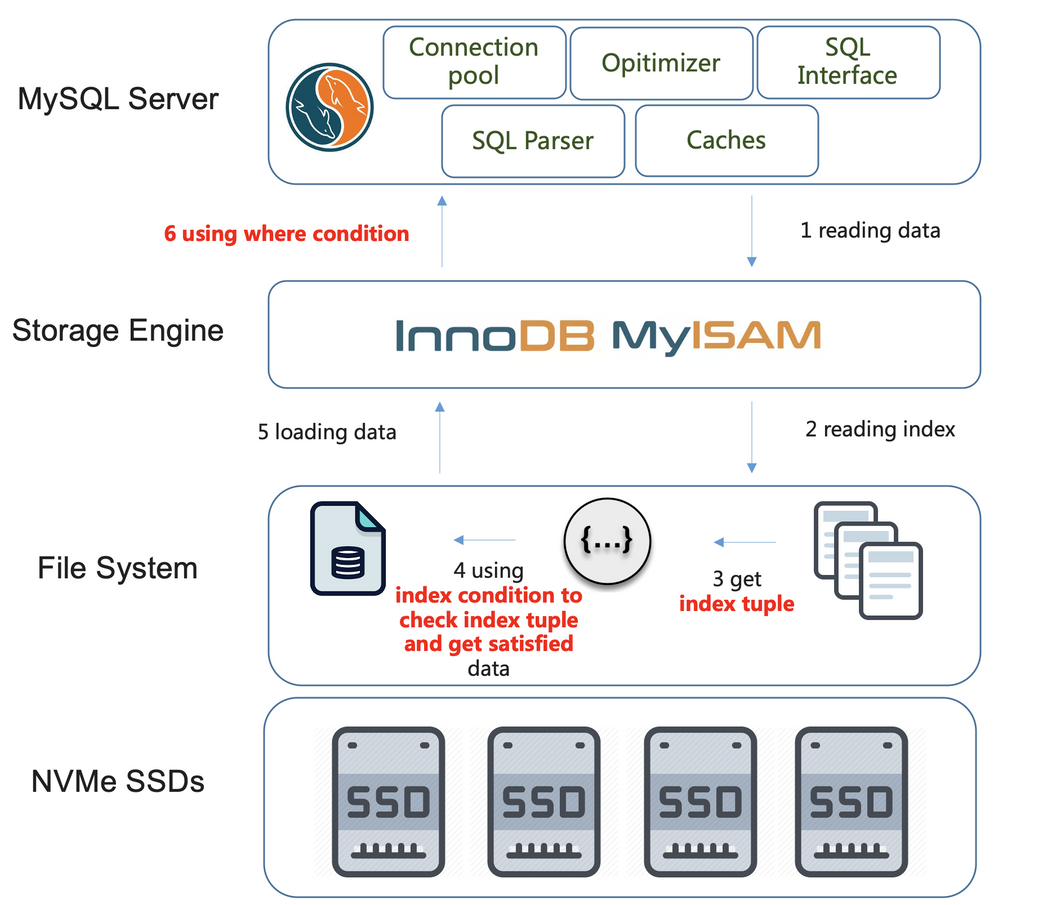
* 计算下推到存储设备,指的就是在类似MySQL ICP的特性上进一步优化,将计算逻辑下推到存储设备上,进一步释放主机CPU资源和主机的带宽资源,如下图
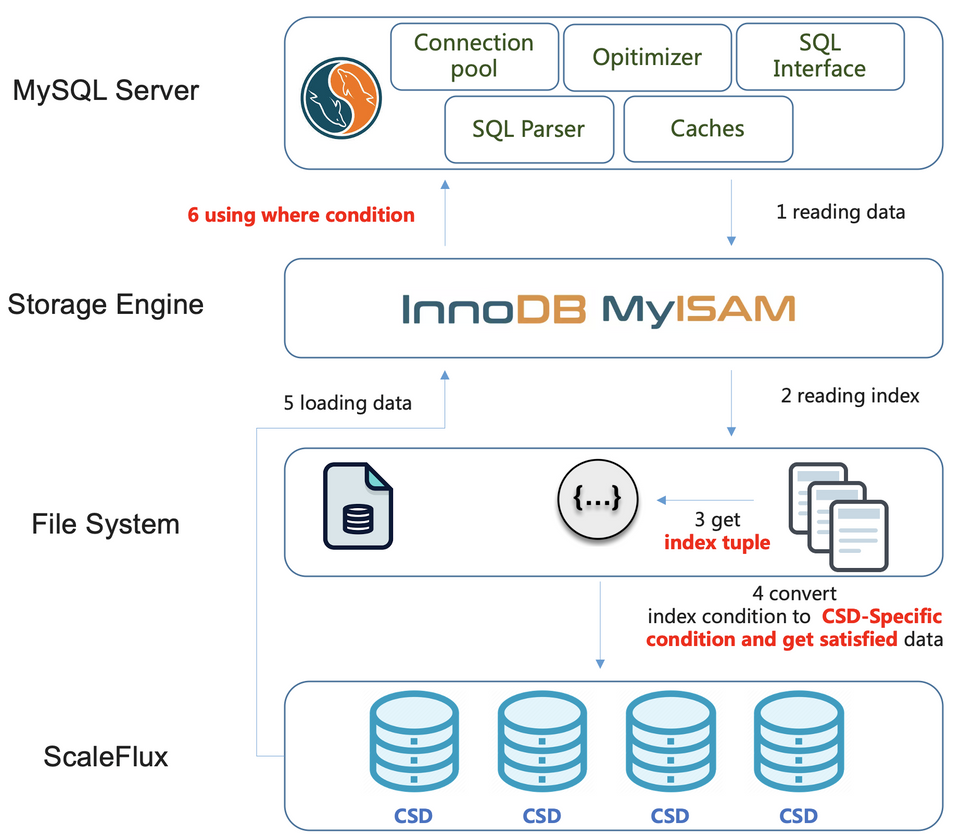
计算存储支持将计算下推到存储设备,对数据库的收益是什么呢?
* 通过上面的介绍,我想,将类似MySQL ICP的计算下推到存储设备上的收益是什么已经无需多言!如果能够将更多的计算逻辑下推到存储设备,那么,必然能够进一步释放主机的CPU、带宽,甚至是内存资源,让主机的资源能够更多地用于接受与处理用户的业务请求,从而进一步提高数据库的性能!
3、对计算存储的未来展望
计算存储的诸多优良的特性,使得它能够系统性地一次性缓解、解决多个数据库的瓶颈与痛点,而不是像传统方法那样,费时费力费财不说、还常常是顾此失彼
虽然说条条大路通罗马,没有解决不了的技术难题,不使用计算存储,也肯定还有其他多种多样的解决方式,但我们也要看具体是如何解决的,如果有近一点的大路,为什么要舍近求远呢?
个人认为计算存储,是数据库领域一个具有前瞻性的发展方向,当然,并不是说用了计算存储就可以一劳永逸,但至少,你的数据量没有达到计算存储都吃不消的地步时,就可以或多或少避开或者延缓上文中提到的一些瓶颈与痛点。另外,还有一点很重要,对于单台服务器的TCO成本下降可能不痛不痒,但如果你的服务器规模较大,能够节省的成本不可小觑哦!
至于以后,计算存储能发展成什么样,天知道,但我想,来自底层可通用的技术突破,比起在应用层做一些难以通用的技术改造更加合算,因此,我相信只要有强烈的需求存在,就必然有勇夫会持续去突破!
PS:以上内容,是根据一些已公开发表的文章整理得出(详见文末的链接),需要详细了解的读者,请移驾文末的参考链接,其中包括了更多的细节说明和完备的性能测试数据,希望在大家的数据库之旅的路上,本文能够对大家或多或少有所帮助!
4、参考链接
Percona 博客中关于ScaleFlux CSD 2000(一款来自ScaleFlux的高性能计算存储产品)的介绍:https://www.percona.com/blog/2020/08/06/how-can-scaleflux-handle-mysql-workload/技术白皮书(包含更多的CSD 2000的测试结论和数据):https://learn.percona.com/hubfs/Collateral/Whitepapers/Testing-the-Value-of-ScaleFlux.pdf
微信公众号"yangyidba"中的"翻译|MySQL 基于ScaleFlux SSD性能测试":https://mp.weixin.qq.com/s/MNBNKlxiBBXGSOyzm5HGdQ
微信公众号"老叶茶馆"中的"可计算存储:数据压缩和数据库计算下推":https://mp.weixin.qq.com/s/iAg64XNrrZxRCLdlRJjFCQ
微信公众号"ScaleFlux"中的"可计算存储: 透明压缩,数据库IO模型和SSD寿命":https://mp.weixin.qq.com/s/jh4JzyXSGhxldT01paCPvw
微信公众号"SSDFans"中的"太强大了!NVMe SSD变身内存":https://mp.weixin.qq.com/s/niZmq170l4HDnfyw0rmRFg
MariaDB 中关于实现自动原子写的介绍:https://mariadb.com/kb/en/atomic-write-support/
https://mariadb.com/kb/en/mariadb-1055-changelog/
作者介绍:罗小波@ScaleFlux,《千金良方——MySQL性能优化金字塔法则》作者之一。
熟悉MySQL体系结构,擅长数据库的整体调优,喜好专研开源技术,并热衷于开源技术的推广,在线上线下做过多次公开的数据库专题分享,发表过近100篇数据库相关的研究文章。














 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









