






一、DataFrame的数据查询 / 提取
1、对单列、多列进行访问读取
-- 对单列数据的访问:DataFrame的单列数据为一个Series。根据DataFrame的定义可以知晓DataFrame 是一个带有标签的二维数组,每个标签相当每一列的列名;如:df.a df['a']
-- 对多列数据访问:访问DataFrame多列数据可以将多个列索引名称视为一个列表,df[['a','b']]
2、对多行进行访问读取
(1)如果只是需要访问DataFrame某几行数据的实现方式则采用数组的选取方式,使用“:”。
(2)head和tail也可以得到多行数据,但是用这两种方法得到的数据都是从开始或者末尾获取的连续数据;默认参数为访问5行,只要在方法后方的“()”中填入访问行数即可实现目标行数的查看。
3、查看访问DataFrame中的数据——loc,iloc方法介绍
(1)loc方法是针对DataFrame索引名称的切片方法,如果传入的不是索引名称,那么切片操作将无法执行;利用loc方法,能够实现所有单层索引切片操作。
loc方法使用方法:DataFrame.loc[ 行索引名称或条件 , 列索引名称 ] # 闭区间(含最后一个值)
(2)iloc和loc区别:是iloc接收的必须是行索引和列索引的位置。
iloc方法的使用方法:DataFrame.iloc[ 行索引位置 , 列索引位置 ] # 开区间(不含最后一个值)
(3)注意点:
-- 使用loc方法和iloc实现多列切片,其原理的通俗解释就是将多列的列名或者位置作为一个列表或者数据传入。
-- 使用loc,iloc方法可以取出DataFrame中的任意数据。
-- loc内部还可以传入表达式,结果会返回满足表达式的所有值。
- - loc更加灵活多变,代码的可读性更高,iloc的代码简洁,但可读性不高。具体在数据分析工作中使用哪一种方法,根据情况而定,大多数时候建议使用loc方法。
-- 在loc使用的时候内部传入的行索引名称如果为一个区间,则前后均为闭区间;iloc方法使用时内部传入的行索引位置或列索引位置为区间时,则为前闭后开区间。
4、查看访问DataFrame中的数据——切片方法之ix
(1)ix方法更像是loc和iloc两种切片方法的融合。ix方法在使用时既可以接收索引名称也可以接收索引位置。
(2)其使用方法:DataFrame.ix[ 行索引的名称或位置或者条件, 列索引名称或位置 ]
(3)控制ix方法需要注意以下几点:
Ø 使用ix方法时,当索引名称和位置存在部分重叠时,ix默认优先识别名称。
Ø 尽量使用列索引名称,而非列索引位置,主要用来保证代码可读性。
Ø 使用列索引位置时,需要注解,同样保证代码可读性。
Ø 除此之外ix方法还有一个缺点,就是在面对数据量巨大的任务的时候,其效率会低于loc和iloc方法,所以在日常的数据分析工作中建议使用loc和iloc方法来执行切片操作。
代码1:
import pandas as pd print("-------创建一维Series数据------------") # 创建方式1: # s1=pd.Series([90,86,70],index=['leo','kate','john']) # print(s1) # 创建方式2: dict={'leo':90,'kate':86,'john':70} s1=pd.Series(dict) print(s1) print("-----绝对位置查找----") print(s1[0]) print("-----标签查找-----") print(s1['kate']) print("-----列表标签查找----") print(s1[['john','kate']]) print("----条件表达式查找----") print(s1[s1>80])
结果图:

代码2:
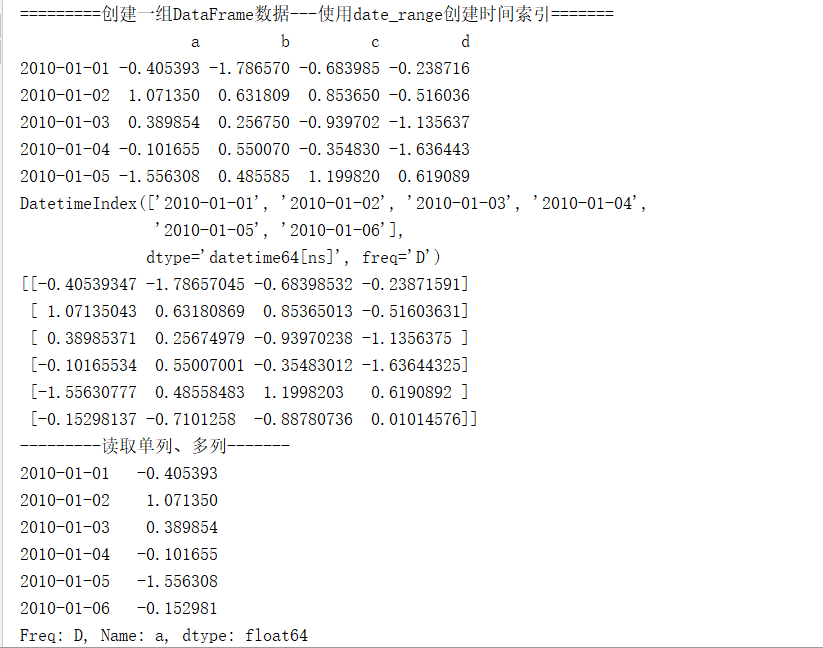
import pandas as pd print("=========创建一组DataFrame数据---使用date_range创建时间索引=======")
date=pd.date_range('20100101',periods=6)
df=pd.DataFrame(np.random.randn(6,4), index=date,
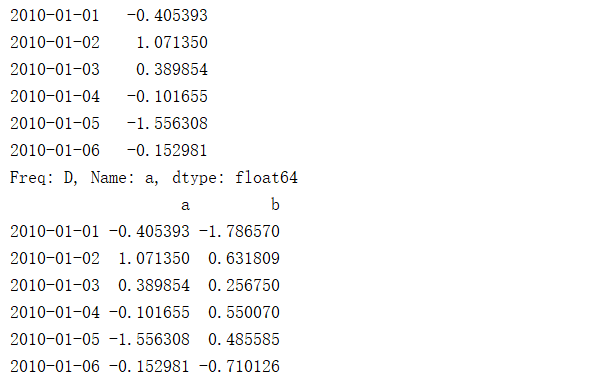
columns=list('abcd')) print(df.head()) print(df.index) # 打印数据框的索引 print(df.values) # 打印数据框内的元素值 print("---------读取单列、多列-------") print(df.a) print(df['a']) print(df[['a','b']]) # 读取多列 print("------读取多行-----------") print(df[0:4]) print(df.head(3)) # 打印前3行数据 print("------读取多行、多列-----------") print(df.loc['2010-01-01':'2010-01-04',['a','b']]) # loc是闭区间,尾部包含 print(df.iloc[:4,[0,1]]) # iloc是开区间,尾部不包含 print(df.ix[:4,['a','b']]) # ix 是开区间,尾部不包含 print(df.loc[df.index<'20100105',['a','b']]) # loc 第一个参数可以用条件提取
结果图:


代码3:
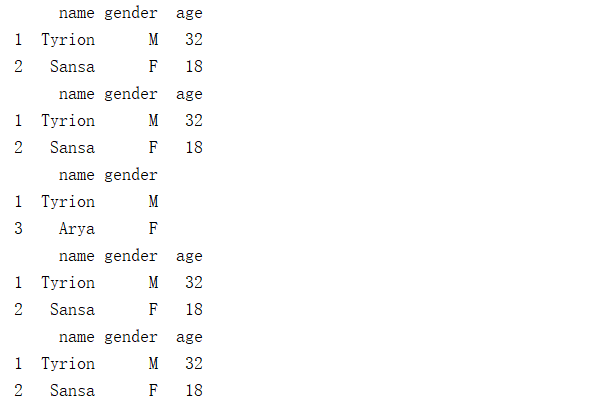
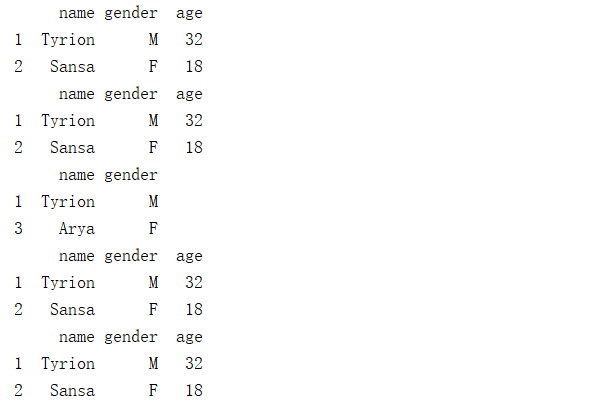
import pandas as pd # 创建DataFrame df = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],['Arya','F',14]], columns=['name','gender','age']) print(df) print("----------提取多行、多列-----------") print(df[['gender','age']]) print(df.loc[1:3,['gender','age']]) # loc是闭区间,尾部包含 print(df.iloc[1:3,[1,2]]) # iloc是开区间,尾部不包含 print(df.iloc[:,1:3]) # 读取第1行到第2行的数据 print(df[1:3]) print(df.iloc[1:3]) #读取第1行和第3行,第0列到第2列,不包括第二列 print(df.iloc[[1,3],0:2]) #读取倒数第3行到倒数第1行的数据,iloc不包含最后一行 print(df[-3:-1]) print(df.iloc[-3:-1])
结果图:
















 1130
1130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









