






本着交流和学习的心态和大家分享本人的第一篇博客(客套话就不说了,其实就是说说自己编写的思路和及对问题的解决办法)。
先说说技术路线,选择docker,scrapy,scrapy_redis 的原因很简单,省钱又方便。(苦比的大四党并不享用云主机优惠)
本爬虫主要抓取了豆瓣movie,book,music分类中的资源。
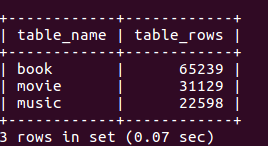
先看看最后抓取的数据量(大概12万的数据(爬虫待优化))
好了,下面就讲讲我的心路历程。
思路:
url分析 --> 分析待抓取项 --> 编写 item --> 构建mysql数据表 --> 解析待抓取项--> 编写spider -->
编写pipeline --> 构建ip_pool --> 构建ua_pool --> 编写middleware -->调用scrapy_redis -->
配置setting --> 配置mysql,redis --> docker部署 -->crawl
(大概就这样吧)
详解过程:
1.url分析,分析待抓取项,编写item,构建mysql,解析待抓取项
主要就规范了spider编写的思路以及通过re,xpath对内容进行提取规则(可使用scrapy shell 或者写个test),没啥可以详细写的。
2.编写spider
由于book,music,movie各自的数据提取规则和url规则并不一样,movie自身有json形式的数据,而其他俩个是html,所以需要在spider中对其进行分类编写。
if 'movie' in response.url: #豆瓣movie,由于豆瓣的movie自身是个api,只需要将这些url交给下一层提取url的函数处理 movie_api_list =['https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=0', 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E8%A7%86%E5%89%A7&start=0', 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%BB%BC%E8%89%BA&start=0', 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E5%8A%A8%E7%94%BB&start=0', 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%9F%AD%E7%89%87&start=0' ] for movie_api in movie_api_list: yield Request(url=movie_api, callback=self.parse_detial) else: #处理书籍和音乐,将分类页面中所有可用的url都提取出来交给下一层处理 all_urls = response.xpath('//a/@href').extract() if all_urls: all_urls = list(set([parse.urljoin(response.url,i) for i in all_urls])) for this_url in all_urls: key_url = re.compile('(.*douban\.com/tag/.*)',re.DOTALL).findall(this_url) if key_url: key_url = key_url[0] yield Request(url=key_url, callback=self.parse_detial)
接下来为了提取二级分类,需要在url中提取数据,并将详细数据页面的url交给下个函数处理,下一页则递归(以movie为例子)
#处理movie api if 'movie' in response.url: tag1='movie' movie_json = json.loads(response.text) movie_tag = re.compile('.*&tags=(.*?)&.*').findall(response.url) if movie_tag: #将url中的字符转换成可识别的字符串 movie_tag = parse.unquote(movie_tag[0]) else: movie_tag="None" for detial_url in movie_json["data"]: detial_url = detial_url["url"] #判断此api接口是否有数据 if detial_url: yield Request(url =detial_url,callback=self.get_data,meta={'tag1':tag1,'tag2':'{0}'.format(movie_tag)}) start = re.match(r'.*start=(\d+)',response.url) if start: num = str(int(start.group(1))+20) page =re.compile('start=\d+') next_movie_api =page.sub('start={0}'.format(num),response.url) if next_movie_api: yield Request(url=next_movie_api,callback=self.parse_detial)
详细数据页面的提取使用了itemloader(以movie为例,简单的截个图吧) 
spider的编写就结束了。
3.编写pipeline
pipeline主要将数据写入到mysql中,担心mysql堵塞的问题,就借用了twisted异步插入mysql。
#通过twisted异步将数据插入mysql中,防止堵塞 class MysqlTwistedPipeline(object): #通过twisted框架调用adbapi实现异步的数据写入 def __init__(self,dbpool): self.dbpool = dbpool @classmethod def from_settings(cls,settings): #通过settings中设置的数据库信息,将数据库导入到pool中 dbparms =dict( host = settings["MYSQL_HOST"], db = settings["MYSQL_DBNAME"], user = settings["MYSQL_USER"], password = settings["MYSQL_PASSWORD"], charset = "utf8mb4", cursorclass = pymysql.cursors.DictCursor, use_unicode = True, ) dbpool = adbapi.ConnectionPool("pymysql",**dbparms) return cls(dbpool) def process_item(self,item,spider): #调用twisted的api实现异步插入 query = self.dbpool.runInteraction(self.do_insert,item) query.addErrback(self.handle_err,item,spider) print(">>>insert into mysql") def handle_err(self,failure,item,spider): print(failure) def do_insert(self,cursor,item): #具体的插入函数 #根据不同的item,构建不同的sql语句,并且插入到mysql中 #plan1 if item.__class__.__name__ =="ArticleItem" (通过item的名字来区别sql语句的写入) #plan 2 见items insert_sql,params =item.get_sql() # print(params[2])
其中插入语句都写在item中(数据的精加工在Utill中):
def get_sql(self): insert_sql = ''' insert into movie( url,url_id,movie,classify,director,scriptwriter, actor,score,comments_num,screen_time,movie_type,country_areas,language, hot_comments,crawl_time )values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ''' url = "".join(self.get("movie_url","")) url_id = "".join(self.get("movie_url_id","")) movie = get_ration_element(self.get("movie","")) classify = get_ration_element(self.get("movie_classify","")) director = get_ration_element(self.get("movie_director","")) scriptwriter = get_ration_element(self.get("movie_scriptwriter","")) actor = get_ration_element(self.get("movie_actor","")) type = get_ration_element(self.get("movie_type","")) country_areas = get_ration_element(self.get("movie_country_areas","")) language = get_ration_element(self.get("movie_language","")) screen_time = get_date(self.get("movie_screen_time","")) score = get_num2(self.get("movie_score","")) comments_num = get_num1(self.get("movie_comments_num","")) hot_comments = get_hot_comments(self.get("movie_hot_comments","")) crawl_time = now() params = (url,url_id,movie,classify,director,scriptwriter, actor,score,comments_num,screen_time,type,country_areas,language, hot_comments,crawl_time) return insert_sql,params
4.构建ip_pool
使用了代理ip商提供的ip,将ip保存至本地文件中,定时更换,确保ip的效用。(墙裂推荐蘑菇代理,便宜又高效)。
5.构建ua_pool
fake-useragent包有250个ua,可以pip安装使用。见文档 https://github.com/hellysmile/fake-useragent
6.编写Middleware
只需要编写随机ua和代理ip,settings中关闭默认middleware,开启自己写的即可。
#随机生成ua并调用 class RandomUAMiddlerware(object): def __init__(self,crawler): super(RandomUAMiddlerware,self).__init__() self.ua = ua() @classmethod def from_crawler(cls,crawler): return cls(crawler) def process_request(self,spider,request): request.headers.setdefault(b'User-Agent',self.ua) #调用ippool池中的proxy并形成request class RandomProxyIPMiddlware(object): def process_request(self, request, spider): proxy =product_ip() print("this_ip:"+str(proxy)) request.meta["proxy"] = proxy
7.scrapy_redis
scrapy_redis的使用很方便,直接附上其github https://github.com/rmax/scrapy-redis
记得跟换spider的超类为RedisSpider,并设置redis_key 。settings中需要的设置见文档即可,很详细实用
from scrapy_redis.spiders import RedisSpider class BasicDoubanSpider(RedisSpider): name = 'basic_douban' redis_key = 'DouBan:start_urls'#设置redis的起始key # allowed_domains = ['www.douban.com'] # start_urls = [ 'https://music.douban.com/tag/', # 'https://movie.douban.com/tag/#/', # 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all', #]
8.配置settings
settings中需要关闭cookie,禁止REDIRECT,开启延迟,retry_code,retry次数,retry的优先级等等。不贴代码了,见我github吧
9.redis和mysql的配置
redis:进入redis.conf文件将bind更改为主机doker的ip (终端ifconfig查看)
mysql:1 进入配置文件注释bind,使本地mysql可以访问
2 添加用户并赋予权限 :mysql中 grant all privileges on *.* to "name"@"%" indetified by password;
10.docker 部署
宿主机共享文件夹(共享ip-pool和spider) 创建contianer时 docker run -tiv 主机文件path:docker path image_id
11 可以开始crawl啦
往scrapy_redis 中添加start-urls lpush your redis_key+your start_url
好了,详细的过程就是这样子,具体代码见我的github吧。https://github.com/kilort/douban















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









