






* 转载请注明出处 - yosql473 - 格物致知,经世致用
mysql -> HBase + Phoenix
1.总体方案有哪些?
1)通过Sqoop直接从服务器(JDBC方式)抽取数据到HBase中
因为数据量非常大,因此优先考虑用Sqoop和MR抽取。
使用Sqoop抽取数据有一个问题,就是Phoenix插入的数据和HBase插入的数据是不同的:
例如,使用Phoenix插入这么一条数据:
upsert into tb_collector_log_143 values ( '2018-07-02 18:34:52_c37b03789c5e43ddb800ff90c27e5a44','2182a29047f3435885fc3fb9f7212189','server','server','2018-07-02 18:34:52','2018-07-02 18:34:52','8a5381604b4443ecb1b73d362f756483','c37b03789c5e43ddb800ff90c27e5a44','0560337357604a258a19adb8cc8849c6','2018-07-02 18:34:52','1','02','117.61.15.14:45067','4da7408331794910aa3523b6a9741df5');
在HBase中“2018-07-02 18:34:52”这个字段值(在phoenix中是date类型)就是字节码“\x80\x00\x01d\x5CF\xA8\xE0“:
2018-07-02 18:34:52_c37b03789c5e43ddb800ff90c27e5a44 column=0:OPERATER_DATE, timestamp=1541250071138, value=\x80\x00\x01d\x5CF\xA8\xE0
因此如果直接向HBase put数据,也会出现Phoenix无法识别的问题。经过反复的验证,发现只有Phoenix的字符串类型(varchar和char)才能保持HBase中直接存储这个值。
* 因此,为了让在Phoenix中插入字符串“aaa"与在HBase中插入”aaa"等价,被插入的这个字段只能是char或者是varchar类型。 这也就意味着使用Sqoop直接从原服务器抽取数据,新的表结构只能是全字符串类型。这也就意味着原来的JDBC的查询可能会遭遇不顺,因为期望被迁移的表有int和date等字段,如果JDBC对字段类型不一致的查询不兼容的话,这事就不太好说。
2)通过MapReduce进行批量插入。
如果直接跑SQL文件效率会非常低,因为是一条一条插入的,先不说导入数据的过程,即使开高并发,服务器上的数据也难以导出成sql文件。因此PASS掉导出文件的方式,只能是直接抽取。

其他:在之前的实验中,我曾用12W条记录的upsert插入sql文件进行插入,结果在插入5W+行的时候发生了堆溢出。这说明使用$SQOOP/bin/psql.py xxx.sql的命令时会在Jvm跑一个进程,每个运行脚本的插入数有限制。
因此可以考虑通过MapReduce进行批量的插入过程,但其实只需要Map任务就可以了,相当于自己写了一个特殊的Sqoop的实例,满足这种特殊的数据抽取需求。
2.几个核心的点:
1)服务器上的数据怎么导出
刚才分析过了,只能通过Sqoop或者手码MR程序
2)数据如何导入HBase,并且使得Phoenix能够顺利识别?
一种方法是全部字段使用字符串,然后使用HBase的put
一种方法是走Phoenix进行插入,这么插入就必须写MR了
3)rowkey怎么设计?
rowkey是Phoenix表的主键,而且根据HBase的特性,Phoenix表按照主键自动排序,这样就存在一个问题,如何设计rowkey?
注意:一般将时间作为rowkey的排在最前面的指标,如果不这么做,数据就完全按照ID分散了。在ID为随机值的情况下,本来紧挨在一起的(按照时间)的数据完全分散,因此这个地方特别需要注意。
因此我将 `<CRETAE_TIME>_<DATA_ID>`做为rowkey,这对于范围查询是非常好的设计。
3.MySQL(未优化)和Phoenix(未优化)的性能查询测试
PS:其实HBase的查询性能,在数据量为百万时,与中型数据库Mysql是持平的,可能Mysql还会更优秀一些。但当数据到达千万的级别的时候,HBase的查询优势就非常明显了。
1)11W+条数据的测试:
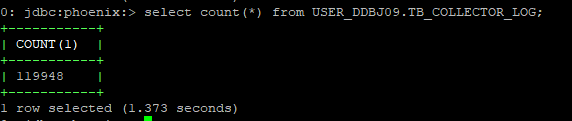
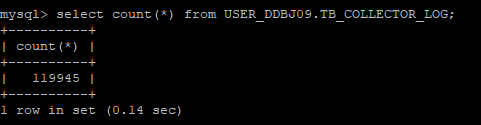
1.1) 非rowkey查询
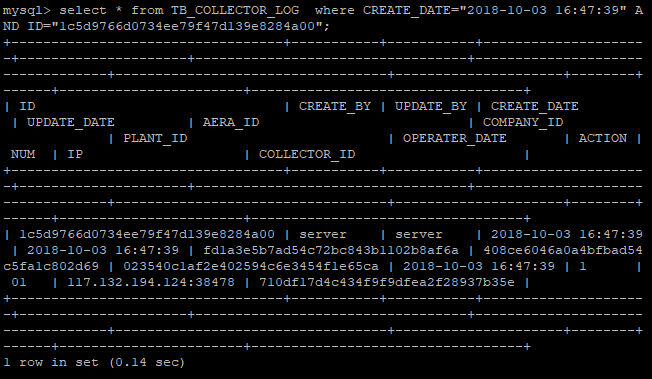
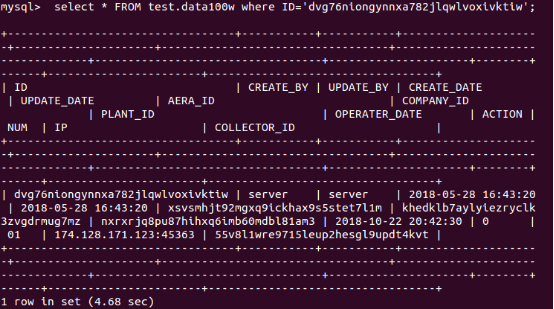
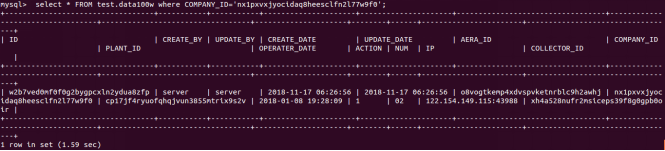
从50000行左右随机抽取一个ID:
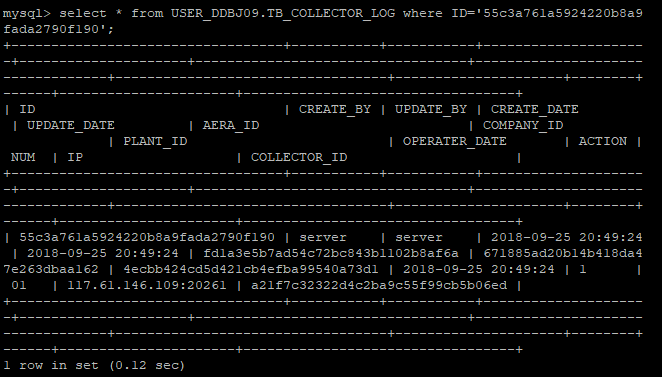
不使用rowkey(相当于不使用一级索引)进行查询:
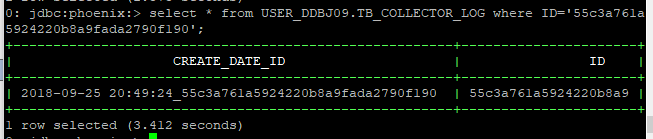
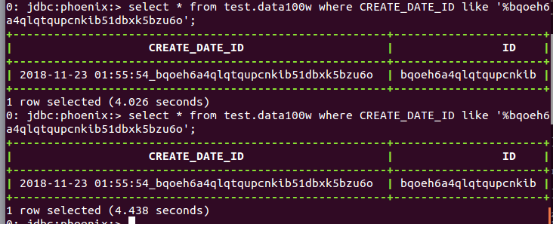
如果采用rowkey进行模糊匹配:

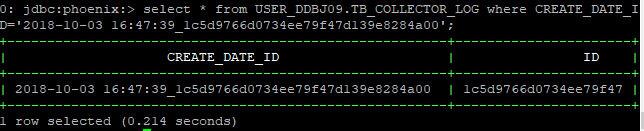
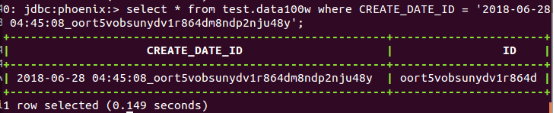
1.2)基于rowkey的查询(基于CRETAE_TIME和ID字段)
从70000行左右随机抽取一个ID和CREATE_TIME,因为我设计的rowkey是”<CREATE_TIME>_<ID>"的格式:
2).百万级别数据量测试
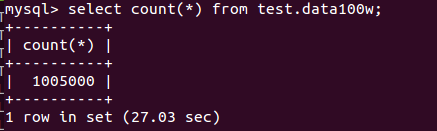
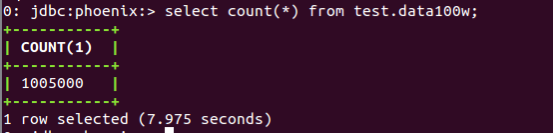
通过Sqoop 从mysql向HBase迁移100W条数据(单Map Task)的时间为:
269.6587 seconds (0 bytes/sec) 不到5分钟
机器配置: 3G 全伪分布式 , Hadoop HBase Zookeeper主从全在一台机器上
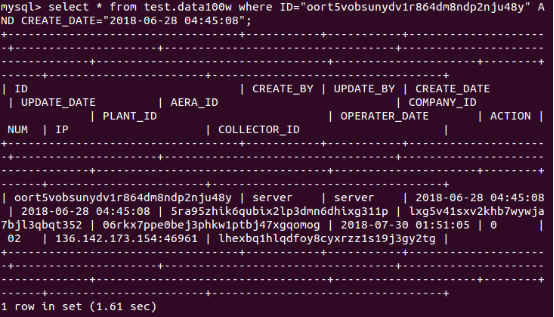
MySQL:
HBase(Phoneix):
2.1)非rowkey的查询

2.2) rowkey查询















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









