






在对nutch源代码运行ant runtime后,会创建一个runtime的目录,在runtime目录下有deploy和local 2个目录。
[jediael@jediael runtime]$ ls
deploy local
这2个目录分别代表nutch的2种运行方式:部署模式及本地模式。
1、nutch.sh中关于2种运行方式的执行
if $local; then
# fix for the external Xerces lib issue with SAXParserFactory
NUTCH_OPTS="-Djavax.xml.parsers.DocumentBuilderFactory=com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl $NUTCH_OPTS"
EXEC_CALL="$JAVA $JAVA_HEAP_MAX $NUTCH_OPTS -classpath $CLASSPATH"
else
# check that hadoop can be found on the path
if [ $(which hadoop | wc -l ) -eq 0 ]; then
echo "Can't find Hadoop executable. Add HADOOP_HOME/bin to the path or run in local mode."
exit -1;
fi
# distributed mode
EXEC_CALL="hadoop jar $NUTCH_JOB"
fi
# run it
exec $EXEC_CALL $CLASS "$@“2、在deploy目录下执行命令即为deploy模式,local目录下执行命令即为local模式。
以下以inject为例,示范2种运行模式。
一、本地模式
1、基本用法:
$ bin/nutch inject
Usage: InjectorJob <url_dir> [-crawlId <id>]用法一:未指定id
liaoliuqingdeMacBook-Air:local liaoliuqing$ bin/nutch inject urls
InjectorJob: starting at 2014-12-20 22:32:01
InjectorJob: Injecting urlDir: urls
InjectorJob: Using class org.apache.gora.hbase.store.HBaseStore as the Gora storage class.
InjectorJob: total number of urls rejected by filters: 0
InjectorJob: total number of urls injected after normalization and filtering: 1
Injector: finished at 2014-12-20 22:32:15, elapsed: 00:00:14用法二:指定id
$ bin/nutch inject urls -crawlId 2
InjectorJob: starting at 2014-12-20 22:34:01
InjectorJob: Injecting urlDir: urls
InjectorJob: Using class org.apache.gora.hbase.store.HBaseStore as the Gora storage class.
InjectorJob: total number of urls rejected by filters: 0
InjectorJob: total number of urls injected after normalization and filtering: 1
Injector: finished at 2014-12-20 22:34:15, elapsed: 00:00:142、数据库中的数据变化
上述命令将在hbase数据库中新建一个表,表名为${id}_webpage,若未指定id,则表名为webpage.
然后将urls目录中的文件内容写入表中,作为爬虫种子。
hbase(main):003:0> scan 'webpage'
ROW COLUMN+CELL
com.163.www:http/ column=f:fi, timestamp=1419085934952, value=\x00'\x8D\x00
com.163.www:http/ column=f:ts, timestamp=1419085934952, value=\x00\x00\x01Jh
\x1C\xBC7
com.163.www:http/ column=mk:_injmrk_, timestamp=1419085934952, value=y
com.163.www:http/ column=mk:dist, timestamp=1419085934952, value=0
com.163.www:http/ column=mtdt:_csh_, timestamp=1419085934952, value=?\x80\x0
0\x00
com.163.www:http/ column=s:s, timestamp=1419085934952, value=?\x80\x00\x00
1 row(s) in 0.6140 seconds当再次执行inject命令时,会增加新的url进入表中。
3、其它运行脚本
where COMMAND is one of:
inject inject new urls into the database
hostinject creates or updates an existing host table from a text file
generate generate new batches to fetch from crawl db
fetch fetch URLs marked during generate
parse parse URLs marked during fetch
updatedb update web table after parsing
updatehostdb update host table after parsing
readdb read/dump records from page database
readhostdb display entries from the hostDB
elasticindex run the elasticsearch indexer
solrindex run the solr indexer on parsed batches
solrdedup remove duplicates from solr
parsechecker check the parser for a given url
indexchecker check the indexing filters for a given url
plugin load a plugin and run one of its classes main()
nutchserver run a (local) Nutch server on a user defined port
junit runs the given JUnit test
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.可以逐步运行一个完整抓取流程中的各个步骤,形成一个整体的流程。
当使用crawl命令进行抓取任务时,其基本流程步骤如下:
(1)InjectorJob
开始第一个迭代
(2)GeneratorJob
(3)FetcherJob
(4)ParserJob
(5)DbUpdaterJob
(6)SolrIndexerJob
开始第二个迭代
(2)GeneratorJob
(3)FetcherJob
(4)ParserJob
(5)DbUpdaterJob
(6)SolrIndexerJob
开始第三个迭代
具体每个步骤的执行,请见http://blog.csdn.net/jediael_lu/article/details/38591067
4、nutch封装了一个crawl脚本,将各个关键步骤进行了封装,从而无需逐步运行抓取流程。
[jediael@jediael local]$ bin/crawl
Missing seedDir : crawl <seedDir> <crawlID> <solrURL> <numberOfRounds>如:
[root@jediael44 bin]# ./crawl seed.txt TestCrawl http://localhost:8983/solr 2
二、部署模式
1、使用hadoop命令运行
注意:必须先启动hadoop及hbase。
[jediael@jediael deploy]$ hadoop jar apache-nutch-2.2.1.job org.apache.nutch.crawl.InjectorJob file:///opt/jediael/apache-nutch-2.2.1/runtime/deploy/urls/
14/12/20 23:26:50 INFO crawl.InjectorJob: InjectorJob: starting at 2014-12-20 23:26:50
14/12/20 23:26:50 INFO crawl.InjectorJob: InjectorJob: Injecting urlDir: file:/opt/jediael/apache-nutch-2.2.1/runtime/deploy/urls
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.3.2-1031432, built on 11/05/2010 05:32 GMT
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:host.name=jediael
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:java.version=1.7.0_51
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:java.home=/usr/java/jdk1.7.0_51/jre
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:java.class.path=/opt/jediael/hadoop-1.2.1/libexec/../conf:/usr/java/jdk1.7.0_51/lib/tools.jar:/opt/jediael/hadoop-1.2.1/libexec/..:/opt/jediael/hadoop-1.2.1/libexec/../hadoop-core-1.2.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/asm-3.2.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/aspectjrt-1.6.11.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/aspectjtools-1.6.11.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-beanutils-1.7.0.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-beanutils-core-1.8.0.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-cli-1.2.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-codec-1.4.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-collections-3.2.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-configuration-1.6.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-daemon-1.0.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-digester-1.8.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-el-1.0.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-httpclient-3.0.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-io-2.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-lang-2.4.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-logging-1.1.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-logging-api-1.0.4.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-math-2.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/commons-net-3.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/core-3.1.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/hadoop-capacity-scheduler-1.2.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/hadoop-fairscheduler-1.2.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/hadoop-thriftfs-1.2.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/hsqldb-1.8.0.10.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jackson-core-asl-1.8.8.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jackson-mapper-asl-1.8.8.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jasper-compiler-5.5.12.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jasper-runtime-5.5.12.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jdeb-0.8.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jersey-core-1.8.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jersey-json-1.8.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jersey-server-1.8.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jets3t-0.6.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jetty-6.1.26.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jetty-util-6.1.26.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jsch-0.1.42.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/junit-4.5.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/kfs-0.2.2.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/log4j-1.2.15.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/mockito-all-1.8.5.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/oro-2.0.8.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/servlet-api-2.5-20081211.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/slf4j-api-1.4.3.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/slf4j-log4j12-1.4.3.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/xmlenc-0.52.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jsp-2.1/jsp-2.1.jar:/opt/jediael/hadoop-1.2.1/libexec/../lib/jsp-2.1/jsp-api-2.1.jar
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/opt/jediael/hadoop-1.2.1/libexec/../lib/native/Linux-amd64-64
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:os.version=2.6.32-431.17.1.el6.x86_64
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:user.name=jediael
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:user.home=/home/jediael
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Client environment:user.dir=/opt/jediael/apache-nutch-2.2.1/runtime/deploy
14/12/20 23:26:52 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=localhost:2181 sessionTimeout=180000 watcher=hconnection
14/12/20 23:26:52 INFO zookeeper.ClientCnxn: Opening socket connection to server localhost/127.0.0.1:2181
14/12/20 23:26:52 INFO zookeeper.ClientCnxn: Socket connection established to localhost/127.0.0.1:2181, initiating session
14/12/20 23:26:52 INFO zookeeper.ClientCnxn: Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x14a5c24c9cf0657, negotiated timeout = 40000
14/12/20 23:26:52 INFO crawl.InjectorJob: InjectorJob: Using class org.apache.gora.hbase.store.HBaseStore as the Gora storage class.
14/12/20 23:26:55 INFO input.FileInputFormat: Total input paths to process : 1
14/12/20 23:26:55 INFO util.NativeCodeLoader: Loaded the native-hadoop library
14/12/20 23:26:55 WARN snappy.LoadSnappy: Snappy native library not loaded
14/12/20 23:26:56 INFO mapred.JobClient: Running job: job_201412202325_0002
14/12/20 23:26:57 INFO mapred.JobClient: map 0% reduce 0%
14/12/20 23:27:15 INFO mapred.JobClient: map 100% reduce 0%
14/12/20 23:27:17 INFO mapred.JobClient: Job complete: job_201412202325_0002
14/12/20 23:27:18 INFO mapred.JobClient: Counters: 20
14/12/20 23:27:18 INFO mapred.JobClient: Job Counters
14/12/20 23:27:18 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=14058
14/12/20 23:27:18 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
14/12/20 23:27:18 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
14/12/20 23:27:18 INFO mapred.JobClient: Rack-local map tasks=1
14/12/20 23:27:18 INFO mapred.JobClient: Launched map tasks=1
14/12/20 23:27:18 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0
14/12/20 23:27:18 INFO mapred.JobClient: File Output Format Counters
14/12/20 23:27:18 INFO mapred.JobClient: Bytes Written=0
14/12/20 23:27:18 INFO mapred.JobClient: injector
14/12/20 23:27:18 INFO mapred.JobClient: urls_injected=3
14/12/20 23:27:18 INFO mapred.JobClient: FileSystemCounters
14/12/20 23:27:18 INFO mapred.JobClient: FILE_BYTES_READ=149
14/12/20 23:27:18 INFO mapred.JobClient: HDFS_BYTES_READ=130
14/12/20 23:27:18 INFO mapred.JobClient: FILE_BYTES_WRITTEN=78488
14/12/20 23:27:18 INFO mapred.JobClient: File Input Format Counters
14/12/20 23:27:18 INFO mapred.JobClient: Bytes Read=149
14/12/20 23:27:18 INFO mapred.JobClient: Map-Reduce Framework
14/12/20 23:27:18 INFO mapred.JobClient: Map input records=6
14/12/20 23:27:18 INFO mapred.JobClient: Physical memory (bytes) snapshot=106311680
14/12/20 23:27:18 INFO mapred.JobClient: Spilled Records=0
14/12/20 23:27:18 INFO mapred.JobClient: CPU time spent (ms)=2420
14/12/20 23:27:18 INFO mapred.JobClient: Total committed heap usage (bytes)=29753344
14/12/20 23:27:18 INFO mapred.JobClient: Virtual memory (bytes) snapshot=736796672
14/12/20 23:27:18 INFO mapred.JobClient: Map output records=3
14/12/20 23:27:18 INFO mapred.JobClient: SPLIT_RAW_BYTES=130
14/12/20 23:27:18 INFO crawl.InjectorJob: InjectorJob: total number of urls rejected by filters: 0
14/12/20 23:27:18 INFO crawl.InjectorJob: InjectorJob: total number of urls injected after normalization and filtering: 3
14/12/20 23:27:18 INFO crawl.InjectorJob: Injector: finished at 2014-12-20 23:27:18, elapsed: 00:00:27三、附带使用eclipse运行nutch的方式
此方法本质上是与部署模式一致的。
使用eclipse运行InjectorJob

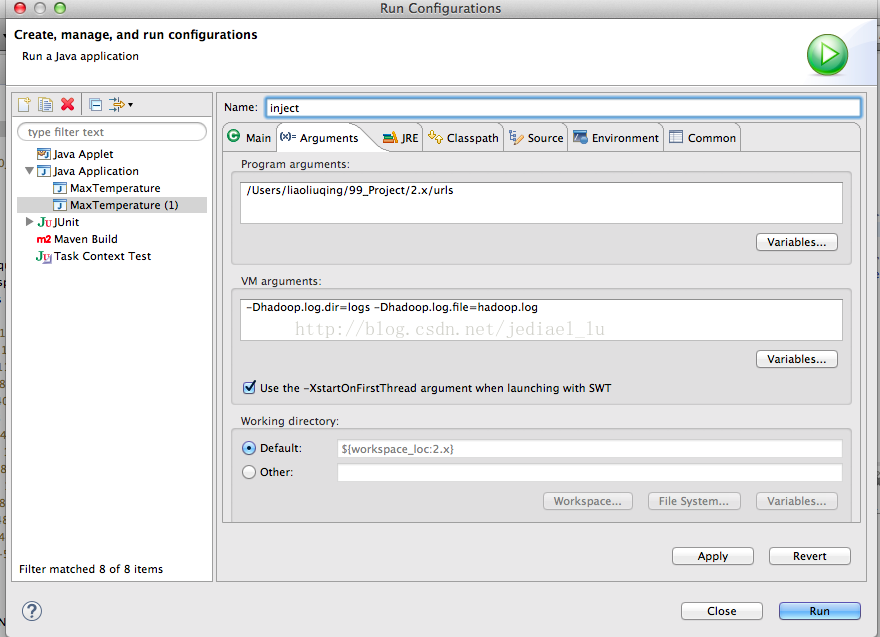
eclipse输出内容:
InjectorJob: starting at 2014-12-20 23:13:24
InjectorJob: Injecting urlDir: /Users/liaoliuqing/99_Project/2.x/urls
InjectorJob: Using class org.apache.gora.hbase.store.HBaseStore as the Gora storage class.
InjectorJob: total number of urls rejected by filters: 0
InjectorJob: total number of urls injected after normalization and filtering: 1
Injector: finished at 2014-12-20 23:13:27, elapsed: 00:00:02














 4104
4104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









