






在实际项目中,我们经常会遇到大数据量查询的问题,尤其是大数据量的有条件查询,因为代价过高的全文检索,往往利用通常的方法会导致数据库端的查询超时。在这里,我们仅仅是说当查询的数据表满足一定的条件,并且查询的条件也符合一定的要求时,我们的解决方案才算是恰当的。那接下来,我们先说明一下该解决方案的前提条件。
前提条件:
1.数据表有主键 (PK) ,并且为整形。
2.数据表有时间数据列作为查询条件,并且排序规则与主键一致。
3.除了时间数据列作为查询条件,可能还有其他类型的查询条件。
| DATA_ID | DATA_TIME | CONDITION_A | CONDITION_B |
| … | … | … | … |
方案思路:
1.在客户端,根据用户指定的时间段通过Web service或者WCF向服务端请求需要查询的数据的最小,最大PK值,我们认为这是查询的准备工作。
目的:根据时间查询条件,缩小查询范围,并且该查询相对速度较快。
2.客户端在取得最小,最大PK以后,判断查询可行性,并随同其他查询条件,向服务端请求查询数据。
3.在服务端,对于数据的查询,我们需要细分几项工作:
第一,为了平衡从数据库端提取数据的性能,我们设定一个PK的范围,每次我们都用最小PK值,以及最小PK值 + PK范围从数据库取数据,并且条件仅仅是用PK。
第二,根据PK从数据库取回的数据,我们用代码的方式在内存中用其他条件过滤(如果Framework为3.0及以上,可巧妙的利用LinQ技术作过滤,代码较为简洁),这样从这个PK段取得的数据即为目标数据。
第三,在取得了目标数据以后,我们需要将刚才的最小PK + PK范围设置为当前最小PK值。作为再次查询的PK条件。
第四,尽管我们已经取得了目标数据,但是我们说可能过滤出来的数据为0,或者已经有很多数据。假设过滤出来的数据为0,并且多次查询的结果均是如此,那客户端与服务端这样的多次通信将是没有太多意义的,并且会增加Web server的负担,所以,在这里,对数据返回客户端需要提出条件。首先我们设置一个返回数据量的最大值,另外我们设定一个查询条件查询数据库的最大查询次数,也就是说达到查询次数,或者达到返回数据量的最大值,服务端才会返回目标数据回客户端。这样做的目的很明确,减少客户端对服务端的Service调用,提高服务端数据返回的有效性。
4.需要注意的是,每次客户端的数据查询,我们总要往返PK的最小,最大值以及其他查询条件,并且这个最小值会随着查询的进度作相应的变化。
为了更好地理解这个方案,大家可以参考以下的设计图:
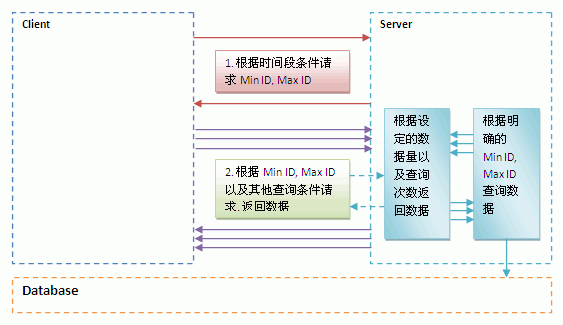
在所提到的前提条件下,通过以上的方案,我们成功解决了在大数据量表中作条件查询产生查询超时的问题。但是,应该注意的是,这样的查询,在客户端,我们建议采用异步方式,这样做的好处就是从服务器端返回一批数据你就可以呈现给客户,获得较好的客户体验。如果有进度侦测的需要,根据PK范围,相信也非常容易解决。
这个解决方案,仅仅是针对我们项目中产生的问题应运而生的,并不代表一定适合你的。但是,我相信,数据库查询+内存查询的结合,以及合理的代码优化,会让你在项目实施中获得一些意想不到的效果。















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









