






 本文详细介绍了如何使用火车采集器将爬取的数据保存为本地的word、excel、html、txt文件,并解决了文件乱码问题。主要步骤包括选择正确的文件模板和编码设置,例如将txt模板设置为ANSI或UTF-8编码,确保发布设置与模板编码一致。此外,还提到了文件命名和编码选择的注意事项,如UTF-8和GBK的选择。
本文详细介绍了如何使用火车采集器将爬取的数据保存为本地的word、excel、html、txt文件,并解决了文件乱码问题。主要步骤包括选择正确的文件模板和编码设置,例如将txt模板设置为ANSI或UTF-8编码,确保发布设置与模板编码一致。此外,还提到了文件命名和编码选择的注意事项,如UTF-8和GBK的选择。
火车采集器保存为本地word、excel、html、txt文件方法及文件模板_爬虫软件技术与爬虫软件网页数据采集器门户
2018 年 10 月 27 日
火车采集器如何将采集到的数据发布到本地的文件 TXT 或者CSV 等格式乱码
解决办法:
模版文件,用txt格式打开,然后 文件—另存为,选择ansi编码 然后发布设置那里 选择GBK 编码,或者
文件—另存为,选择utf-8编码 然后发布设置那里 选择UTF-8 发布即可
1、 我们以软件自带的火车采集器采集规则 搜狐新闻 为例子
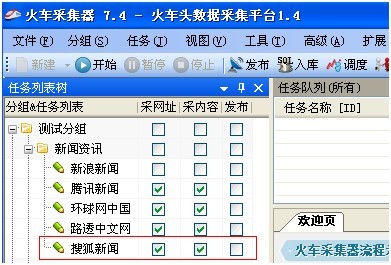
2、 双击火车采集器采集规则,打开 搜狐新闻 这个规则

第三步:发布内容设置勾选 “方式二”的启用保存文件格式(自己可根据需要来选择)
3、 保存位置,这里就不做说明了,想保存到哪里就保存到哪里你的地盘你自个做主~
4、 文件模版,简单的说就是你保存到文件的具体模版样式。
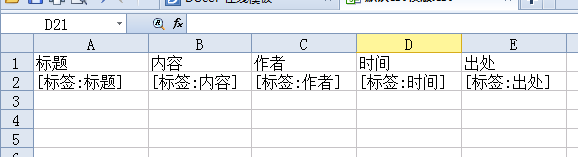
以 “搜狐新闻”为例做txt文件模版
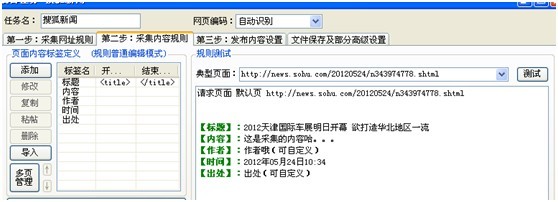
有5个标签
所以txt模版对应写上就可以了
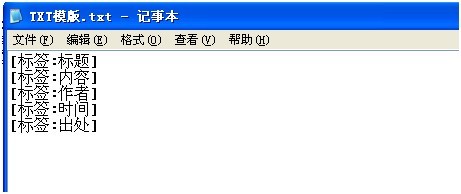
模版会自动提取相应的标签内容。
Html 模版也是一样的
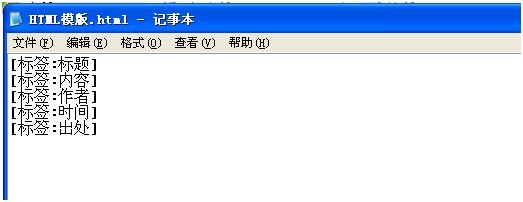
csv模版
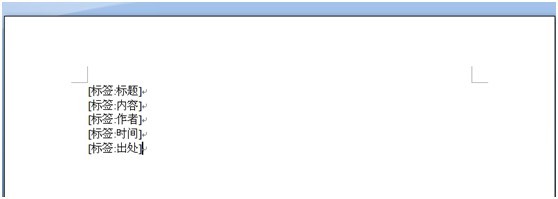
Word模版亦是如此
5、 火车采集器文件名格式
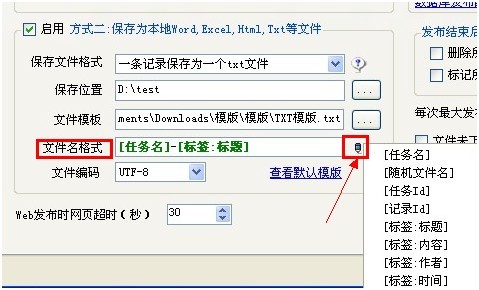
点击这个按钮,可出现一个选择列表,这里可以任意选择匹配,给文件命名。
6、 火采集器文件编码
有utf-8和 gb2312 两种。 发布后 如果显示是乱码 ,就可能是你的编码没设置正确,换一种 应该就可以了。
嗯 就这些了,写的非常的直白,应该都可以看懂~~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









