






1. 二分图
二分图(Bipartite Graph):简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。准确地说,把一个图的顶点划分为两个不相交集\(U\)和\(V\),使得每一条边都分别连接\(U\)、\(V\)中的顶点。如果存在这样的划分,则此图为一个二分图。下图中图2是一个二分图,图1也是一个二分图,仔细观察会发现,这两个图其实是完全一样的。

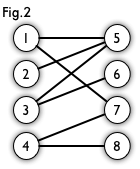
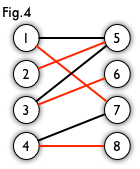
- 匹配(Matching):在图论中,一个“匹配”是一个边的集合,其中任意两条边都没有公共顶点。例如,图3、图4中红色的边就是图2的匹配。
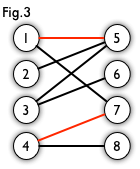
- 我们定义匹配点、匹配边、未匹配点、非匹配边,它们的含义非常显然。例如图 3 中 1、4、5、7 为匹配点,其他顶点为未匹配点;(1,5)、(4,7)为匹配边,其他边为非匹配边。
- 最大匹配(Maximum Matching):一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。图4是一个最大匹配,它包含4条匹配边。
完美匹配(Perfect Matching):如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。图4是一个完美匹配。显然,完美匹配一定是最大匹配,但并非每个图都存在完美匹配。
2. 二分图最大匹配 Hungary算法
- 交错路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边…形成的路径叫交错路。
增广路:从一个未匹配点出发,走交替路,终点为另一个未匹配点的路径。图5中的一条增广路如图6所示,匹配边和匹配点用红色标出。
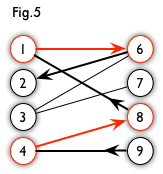
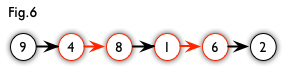
- 性质:非匹配边比匹配边多一条。因此,研究增广路的意义是改进匹配。只要把增广路中的匹配边和非匹配边的身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏匹配的性质。交换后,图中的匹配边数目比原来多了1条。
- 定理:我们可以通过不停地找增广路来增加匹配中的匹配边和匹配点。找不到增广路时,达到最大匹配。匈牙利算法正是这么做的。
匈牙利算法:依次从左边集合的每个点出发DFS寻找增广路,一旦找到,就反转这条路径上的匹配边和未匹配边,并且计数器加一。在对左边集合每个点都处理过一遍后,保证图中不再有增广路。
Code
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long ll;
const int INF = 0x3f3f3f3f;
const int N = 1e3 + 10;
const int M = 1e3 + 10;
struct Edge
{
int to, next;
} edge[M];
int adj[N], no;
int n, m;
void init()
{
memset(adj, -1, sizeof(adj));
no = 0;
}
void add(int u, int v)
{
edge[no].to = v;
edge[no].next = adj[u];
adj[u] = no++;
}
int left, right;
int match[N];
bool vis[N];
bool dfs(int u)
{
for (int i = adj[u]; i != -1; i = edge[i].next)
{
int v = edge[i].to;
if (vis[v]) continue;
vis[v] = true;
if (match[v] == -1 || dfs(match[v]))
{
match[v] = u;
return true;
}
}
return false;
}
int hungary(int x, int y)
{
left = x; right = y;
int ans = 0;
memset(match, -1, sizeof(match));
for (int u = 1; u <= left; u++)
{
memset(vis, false, sizeof(vis));
if (dfs(u)) ans++;
}
return ans;
}
int main()
{
int n, m, e;
scanf("%d%d%d", &n, &m, &e);
init();
while (e--)
{
int u, v;
scanf("%d%d", &u, &v);
add(u, v);
}
int ans = hungary(n, m);
printf("%d\n", ans);
return 0;
}Input
第一行给出三个整数\(n\),\(m\)和\(e\),分别表示左右集合的大小和边数。
接下来的\(e\)行,每行给出两个整数\(u\)和\(v\),表示左边集合中的u点与右边集合中的\(v\)点之间有一条边相连。左边集合结点编号从\(1\)到\(n\),右边集合结点编号从\(1\)到\(m\)。
Output
输出一个整数,表示最大匹配数。
Sample Input
5 4 8
1 1
2 1
2 2
3 3
3 4
4 2
5 1
5 4Sample Output
4














 2721
2721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









