






线性逼近:
相比较于非线性逼近,线性逼近的好处是只有一个最优值,因此可以收敛到全局最优。其中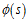 为状态s处的特征函数,或者称为基函数。
为状态s处的特征函数,或者称为基函数。
常用的基函数的类型为:
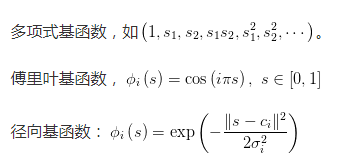
增量式方法参数更新过程随机性比较大,尽管计算简单,但样本数据的利用效率并不高。而批的方法,尽管计算复杂,但计算效率高。
批处理方法:

深度强化学习:

离策略:是指行动策略(产生数据的策略)和要评估的策略不是一个策略。在图Q-learning 伪代码中,行动策略(产生数据的策略)是第5行的\varepsilon -greedy策略,而要评估和改进的策略是第6行的贪婪策略(每个状态取值函数最大的那个动作)。
所谓时间差分方法,是指利用时间差分目标来更新当前行为值函数。在图1.1 Q-learning伪代码中,时间差分目标为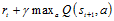 。
。














 9691
9691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









