






写在前面
面向对象(OOP)是一种思维方法,不同于面向过程的程序设计思想,面向对象思维在诸多方面提供了新的思考问题的方法:审视问题域--对象而不是行为,抽象原则,封装和重用等等。OOP在现代程序设计中的地位不言而喻,并且在实际工程中也大放异彩。
本文主要总结OO课程第一单元所学知识,实践体会,以及技术注记,以备后用。
第一次作业
第一次作业实现了一个仅支持幂函数和组合规则的简单多项式求导,目的在于初步掌握JAVA语言的特性,同时体会基本的OOP思想:组合、封装、行为抽象
一、类图
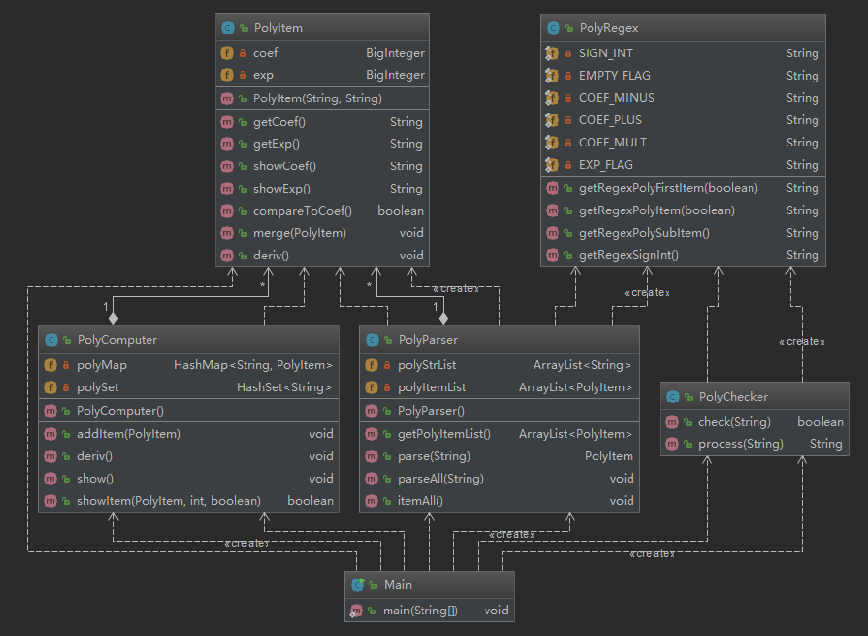
第一次作业比较简单,即使使用面向过程的程序框架也没有实现上的难度,但出于练习java和oo思想的初衷,本次作业根据行为抽象的原则,尽量抽象出了几个类:
PolyChecker:表达式输入格式检测器PolyRegex:正则表达式模式管理器PolyParser:表达式输入解析器PolyComputer:表达式求导计算器PolyItem:表达式项
从类图上来看,类与类之间的耦合度不高,调用关系比较直接单一,看起来似乎还行,但是从下面的代码度量环节还是能发现一些问题。
二、代码度量
(度量符号说明参见注记)
代码统计

类度量
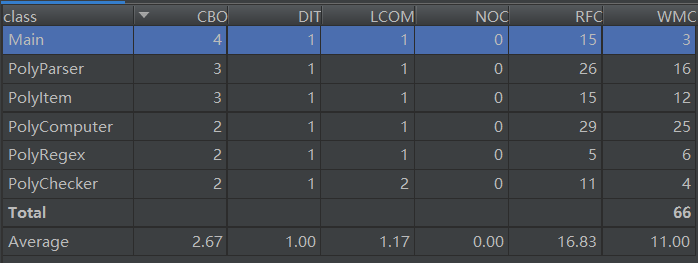
类复杂度度量
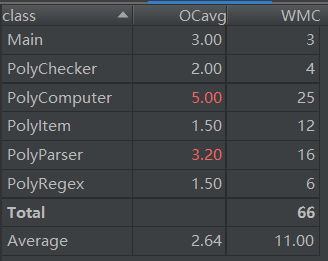
方法复杂度度量
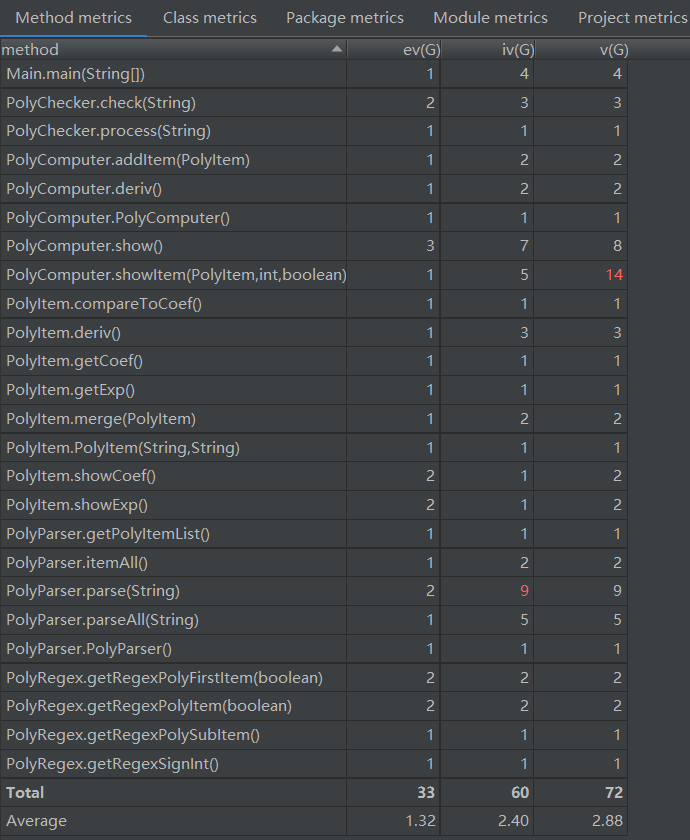
由上述类复杂度分析可以看出,PolyComputer类和PolyParser类的复杂度较高,结合方法复杂度分析表同样可以看到,以下两个方法的复杂度是主要影响因素:
PolyParser.parse:表达式输入解析器的解析方法PolyComputer.show:表达式求导结果的输出方法
Code review后可以清楚地看到,.parse方法由于需要处理表达式项的符号、系数、指数,因此逻辑较多,功能较为复杂;.show方法由于嵌入了表达式输出结果的优化算法,同样提高了复杂度。
简而言之,可以将上述不足总结为以下几点:
- 单一方法的逻辑需要精简:尽管代码风格检查限制了类方法的长度不超过60行,但是仍然可能存在逻辑耦合的现象(如
.parse方法),在不影响可读性的情况下,尽量将方法逻辑抽取为单一逻辑。 - 类行为抽象需要秉承“高内聚,低耦合”原则:
.show方法显然可以抽象为一个拥有输出行为的类,不应该让PolyComputer既运算,又输出。内聚和耦合的关系需要牢记在心。
三、Bug分析
在中测和强测均得到满分,暂时未发现bug
补充说明:(自测过程中的发现)
正则匹配栈溢出问题:
在初步实现时未考虑到此问题。首先采取的策略是使用单个正则表达式匹配整个输入字符串,但未考虑到正则表达式NFA贪婪模式的特点,在特殊样例下测出了栈溢出的问题;之后采取的办法是部分匹配的方式,其他同学也有使用正则表达式独占模式的方法来防止溢出。
四、反思
第一次作业比较友好,主要是起铺垫作用,整个实现过程也比较顺利,耗时较短。同时自己也初步尝试了用oop的思想进行程序设计,不过很明显可以看出,只有形似而无神似,需要进一步改进:
行为抽象和类抽象需要进一步体会提高
冗余代码可以进一步重构
PolyRegex类是一个行为抽象类,作用是根据不同的方法调用返回不同的正则匹配模式。但在实现过程中部分正则匹配模式过于冗余,即不同的方法返回的匹配模式的部分子串是相同的,因此可以将类内方法的共用元素抽象为类数据,减少冗余性。可以基于设计模式(Design Pattern)进行重写
第二次作业
第二次作业在第一次作业的基础上增加了sin(x)和cos(x)两个与幂函数相同地位的函数,同时增加了乘法组合规则和因子的概念,难度比第一次作业增加了一些。
一、类图
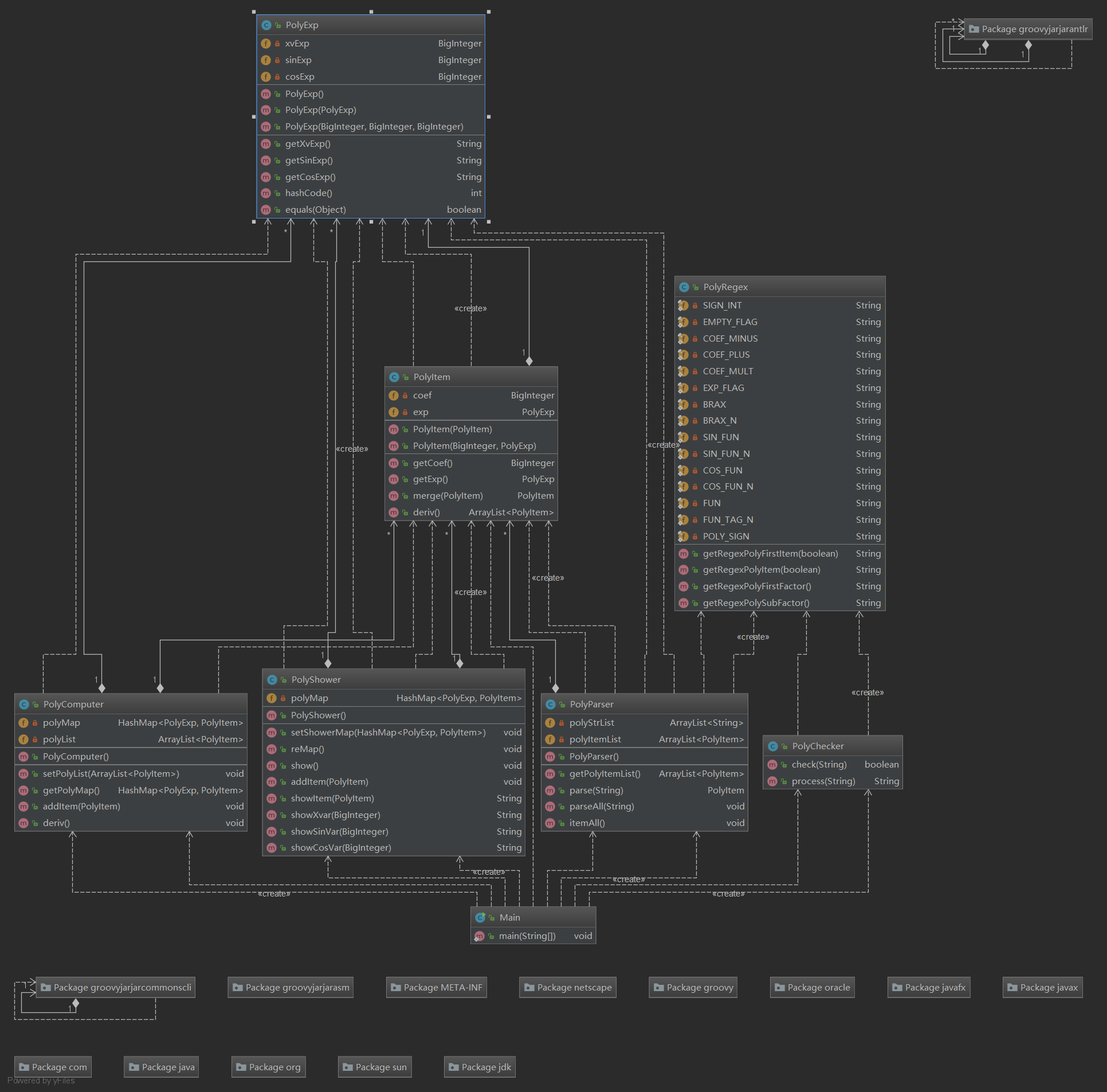 第二次作业的基本框架沿袭了第一次作业,同样是基于行为抽象,同时处理了部分第一次作业冗余的问题。
新增了以下类:
PolyShower:求导结果输出器PolyExp:因子指数类
总的来说,框架较为清晰,实现也较为方便快捷,但此次作业暴露出了另一个问题,即代码的可扩展性。本单元作业共有三次编程作业,且是逐层递进的。而本次作业基于上次作业仅增添了两个同类函数和乘法规则,因此出现了以下两种思路:
- 三元组:将每一项看作
x sin(x) cos(x)的三元组,各组由指数标识- 优点:易于实现,且优化算法可方便接入功能逻辑
- 缺点:可扩展性差
- 表达式树:将规则(加法、乘法)和因子看作可求导对象,基于链式求导法则建立表达式树。
- 优点:逻辑清晰,架构完善,可扩展性强
- 缺点:实现复杂,优化算法接入需要大量冗余代码
在第三次作业中实现了后一种思路,并且可以看到oop思想的巧妙使用。
二、代码度量
(度量符号说明参见注记)
代码统计

类度量
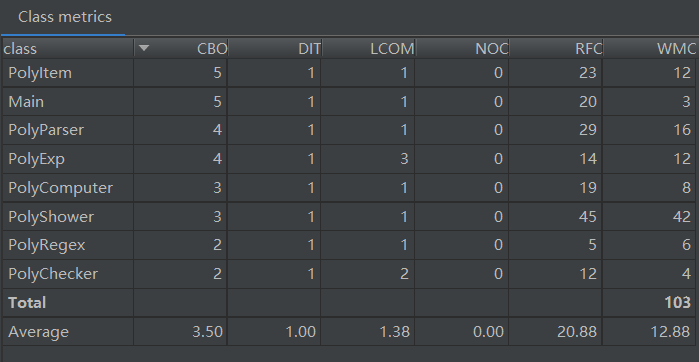
类复杂度度量
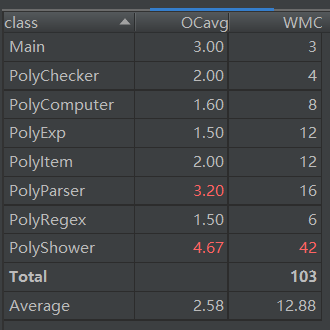
方法复杂度度量
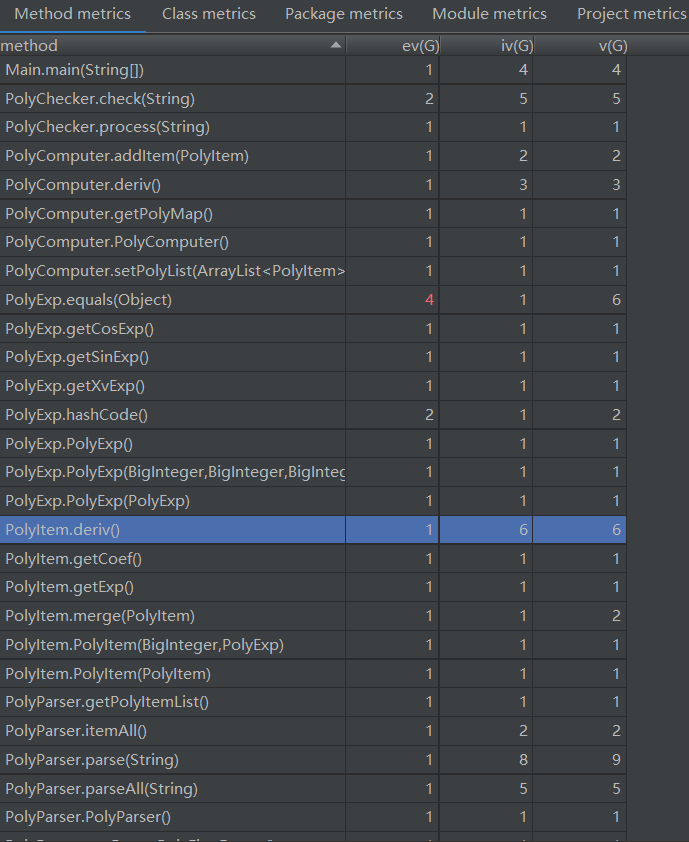
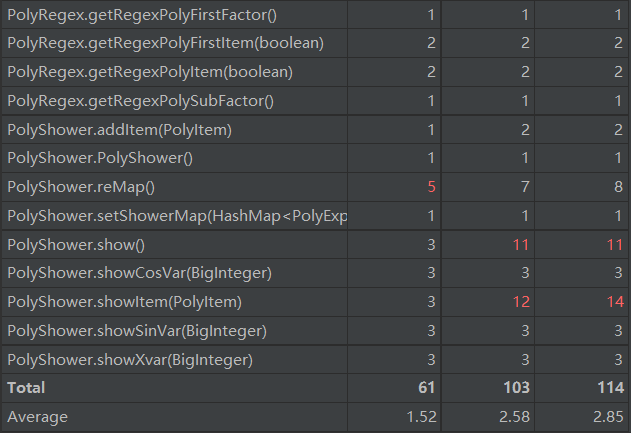
与第一次作业一样,个别类的和类的方法的复杂度较高:
PolyShower类:输出结果类.remap方法:重新排序求导结果以及基于sin(x)^2+cos(x)^2=1简单化简.show方法:输出结果
此次的复杂度仍然是输出逻辑的问题,同时还有优化实现与工程设计的trade-off,还是由于抽象的不够彻底导致的。
三、Bug分析
在中测和强测中均通过正确性,优化方面由于个人选择只做了初步优化,后续有兴趣可以回过头来重新设计优化方法。
四、反思
第二次作业在第一次作业的基础上进一步扩展了表达式支持的因子类型和组合规则,相当于扩大了面向对象思考的问题域,意味着可供应用面向对象思想的空间也扩大了。因此,本次作业的主要设计模式有两类,一类是三元组类型,一类是表达式树类型,一定程度上反映了本次作业的设计需求--代码结构的重要性。
对于三元组类型,个人认为基于作业的角度来看是一个性价比较高的架构,牺牲可扩展性以换取功能的易实现;而对于表达式树类型,则是保证了可扩展性,但在功能(此处指输出结果优化)实现上难度远高于前者。
因此,本次作业实际上就是一个在代码结构、时间精力投入上的trade-off,无论采取哪种类型,都应该再回过头去思考另一种方式的优点,取其精华去其糟粕。本次作业采取的是三元组形式,但同时也思考了表达式树的实现方式,于是在第三次作业进一步扩展功能后,可以较及时的重写架构实现功能。
第三次作业
第三次作业进一步增加了求导功能,支持嵌套规则和表达式因子,因此需要进一步抽象层次关系:之前重点实践的是行为抽象,本次作业则进一步上升到类型抽象和层次抽象,并辅以JAVA特性,真正体会了OOP思想的妙处。
一、类图
第三次作业采用表达式树结构进行设计,同时面向接口编程,将求导(以及输出)这一行为进行抽象:
public interface Element {
Element deriv();
String show();
String type();
}
- 因子类:
PolyConstant:常数PolyPow:幂函数PolySinCos:三角函数PolyFactorPoly:表达式因子
- 组合规则类:
PolyRuleMerge:加法减法规则PolyRuleMult:乘法规则
上述类均有自己的求导规则,但求导行为均是生成一个新的可求导类型,正好可应用接口的思想,一切均是接口类型,递归下降分析时创建表达式树;求导时从根调用,递归遍历树;输出时也从根调用,递归遍历树。因此抽象后的逻辑极其简练。
二、代码度量
(度量符号说明参见注记)
代码统计

类度量
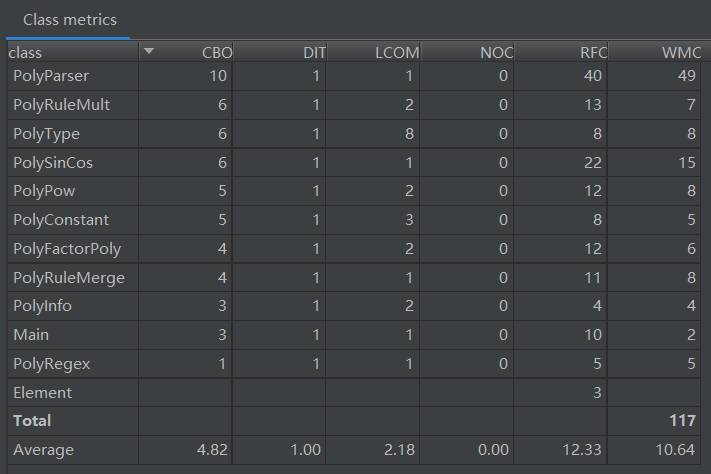
类复杂度度量
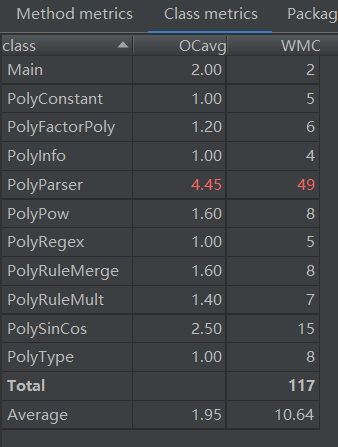
方法复杂度度量
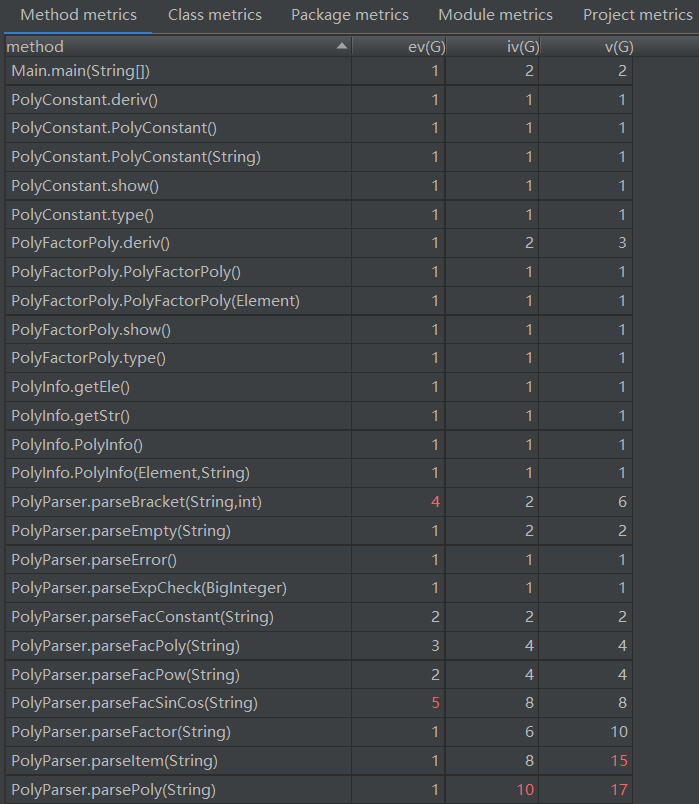
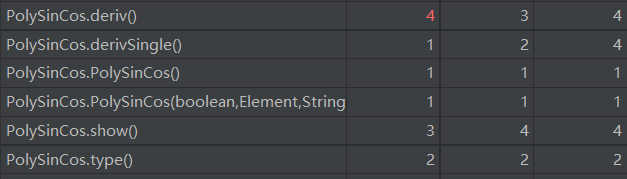

可以发现,本次作业不管是类复杂度还是方法复杂度均低于前一次作业,说明接口的实现和抽象层次的运用确实提高了程序的“高内聚,低耦合”程度。除了
PolyParser类(递归下降输入解析)的复杂度较高外,其他类的复杂度均较低,耦合度低。PolyParser类在递归下降方法的实现过程中可以进一步抽取逻辑降低复杂度,并且在解析-生成实例过程可以运用设计模式--工厂模式,降低类间耦合度。
三、Bug分析
在中测和强测均通过正确性,但是没有实现优化算法。
四、反思
本次作业加深了对抽象的理解,并通过运用JAVA语法特性进一步实践,收获良多,并进一步体会到OOP的妙用:层次管理和抽象。
但是对于优化层面的工作,还有待进一步探索,第二次作业提到的trade-off仍然存在,如何把握其中的balance因人而异,但最主要的是do something, learn something。
技术总结
一、面向对象思维
多态与接口--抽象与层次管理
本单元作业最大的收获在于抽象思维的建立和代码逻辑层次管理的实践,特别是第三次作业,复杂的表达式项、因子类型和多重组合规则以及可递归的嵌套规则,但在复杂的背后是共性,是可抽象的层次。一旦想到用接口特性进行层次抽象、行为抽象,复杂也随即变得微不足道。
- 对象定位
- 在容器中找到所关注的对象
- 通过传递的共享引用
- 归一化管理
- 通过上层抽象类或接口来无差别引用和使用相关的对象
- 协作结构/模式
- 对象定位
其他(Java库)
BigInteger大整数类,有效防止整数溢出
ArrayList可变长度List容器,巧妙利用JAVA内存管理由JVM实现的特点,避开内存开辟回收的繁琐和内存滥用的风险。
HashMap<key,value>按键索引类型,在表达式管理表达式项和因子时可减轻工作量(简化合并同类项的实现)
注释:提醒自己之后的作业应该勤写注释
二、测试技术初步
黑盒测试
- 生成数据
- 覆盖测试
前三次作业仅第一次作业体验式地使用了Xegex生成正则表达式,做了一些简单的对拍,希望在后续作业能够进一步使用对拍保证正确性。
白盒测试 -- 静态检查
- 类规模大小适中,方法实现的代码量适中
- 循环变量不允许在循环体内进行处理和修改
- 与循环无关的计算放在循环体外
- 不在循环体内对常数求值
- 清楚无效的可执行代码
- 明确数值的上/下溢
- 任何调用都测试被调用者返回的状态
自测过程中主要使用的是白盒测试,因为前三次作业的逻辑没有过于复杂,因此读代码检查逻辑的效率也较高。在之后的作业应该加强黑盒测试,进行测试数据生成和对拍。
单元测试
前三次作业没有用到单元测试,但在讨论区和样例代码中看到了
JUnit的使用,因此在此处mark,希望在后续作业中增加测试的多样性和比重。
三、设计模式思考
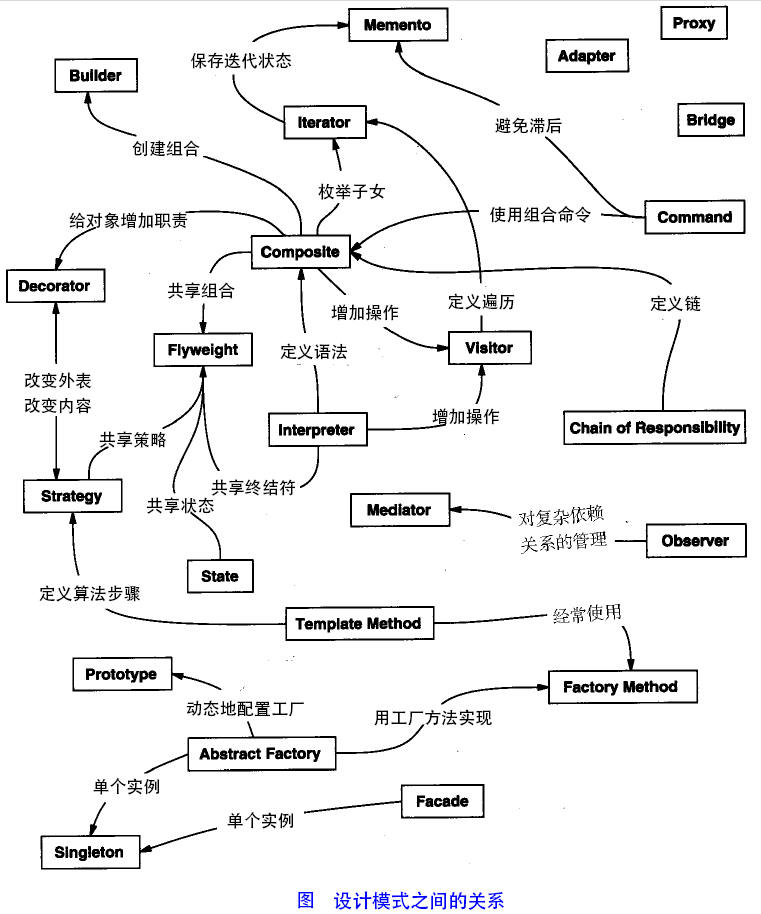
设计模式原则--总原则:开闭原则
开闭原则就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,而是要扩展原有代码。即是为了使程序的扩展性好,易于维护和升级。
- 单一职责原则
- 里氏替换原则
- 依赖倒转原则
- 接口隔离原则
- 迪米特原则(最少知道原则)
- 合成复用原则
设计模式初步--创建模式
下面列出了基本的创建模式,并对前三次作业程序可能可以应用的地方进行了简要说明,具体的设计模式介绍可见注记。
简单工厂模式
工厂方法模式
抽象工厂模式
第三次作业使用了求导接口,并在求导实现过程灵活利用了多态的思想,现在看来,如果在语法分析器创建类实例时使用工厂模式,可以让
PolyParser类的耦合度降低,即减少代码逻辑的复杂度。单例模式
建造者模式
原型模式
原型模式主要强调深浅拷贝的应用,第一二次作业中的
PolyItem类实际上是可变类型,处于安全性考虑,应该使用深拷贝,即实现Cloneable接口。
注记
一、代码度量工具说明
- 使用工具
- IDEA 插件:Metric Reloaded
- 使用:安装完成后,Help --> Find Action --> Calculate Metrics
- 两类分析工具说明
- Chidamber-Kemerer metrics
- CBO: 类间耦合度
- DIT: 继承树深度
- LCOM: 类内聚度
- RFC:类响应度
- Complexity metrics
- Class metrics
- OCavg : 类方法的平均循环复杂度
- WMC:类方法权重(可理解为方法数量等)
- Method metrics
- ev(G): 基本复杂度
- iv(G): 模块设计复杂度
- v(G): 模块判定结构复杂度
- Class metrics
- Chidamber-Kemerer metrics
二、正则表达式生成器
前三次OO作业主要侧重于输入格式导向的测试设计和设计结构导向的测试设计,结合实际问题来看,三次多项式求导作业在输入处理方面要求较繁多且严格,因此是project不好处理和容易出错的模块。整个实现过程中用到了正则表达式技术,思想是实例-->模式。反向思考,秉持模式-->实例的思想,使用正则表达式生成器根据写好的pattern来生成数据,正好是测试的利器。
- Java Class: Xeger
- Python package:
pip install xeger
三、设计模式学习
- 《深入浅出设计模式》
- Design Pattern website: https://www.oodesign.com/















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









