






# 20155322 2017-2018-1《信息安全系统设计》第五周 学习总结
[博客目录]
- 教材学习内容总结
- 教材学习中的问题和解决过程
- 代码调试中的问题和解决过程
- 本周结对学习情况
- 代码托管
- 学习进度条
参考资料
教材学习内容总结
教材内容第三章《程序的机器级表示》的自主学习,复习了汇编的相关知识,记录了一些汇编指令以备不时之需:
参考资料
数据传送指令
mov — Move (Opcodes: 88, 89, 8A, 8B, 8C, 8E, ...)
mov指令将第二个操作数(可以是寄存器的内容、内存中的内容或值)复制到第一个操作数(寄存器或内存)。mov不能用于直接从内存复制到内存,其语法如下所示:
mov <reg>,<reg>
mov <reg>,<mem>
mov <mem>,<reg>
mov <reg>,<const>
mov <mem>,<const>实例:
mov eax, ebx //将ebx的值拷贝到eax
mov byte ptr [var], 5 //将5保存找var指示内存中的一个字节中push— Push stack (Opcodes: FF, 89, 8A, 8B, 8C, 8E, ...)
push指令将操作数压入内存的栈中,栈是程序设计中一种非常重要的数据结构,其主要用于函数调用过程中,其中ESP只是栈顶。在压栈前,首先将ESP值减4(X86栈增长方向与内存地址编号增长方向相反),然后将操作数内容压入ESP指示的位置。其语法如下所示:
push <reg32>
push <mem>
push <con32>实例:
push eax //将eax内容压栈
push [var] //将var指示的4直接内容压栈pop— Pop stack
pop指令与push指令相反,它执行的是出栈的工作。它首先将ESP指示的地址中的内容出栈,然后将ESP值加4. 其语法如下所示:
pop <reg32>
pop <mem>实例:
pop edi //pop the top element of the stack into EDI.
pop [ebx] //pop the top element of the stack into memory at the four bytes starting at location EBX.lea— Load effective address
lea实际上是一个载入有效地址指令,将第二个操作数表示的地址载入到第一个操作数(寄存器)中。其语法如下所示:
lea <reg32>,<mem>实例:
lea eax, [var] //var指示的地址载入eax中.
lea edi, [ebx+4*esi] // ebx+4*esi表示的地址载入到edi中,这实际是上面所说的寻址模式的一种表示方式.算术和逻辑指令
add— Integer Addition
add指令将两个操作数相加,且将相加后的结果保存到第一个操作数中。其语法如下所示:
add <reg>,<reg>
add <reg>,<mem>
add <mem>,<reg>
add <reg>,<con>
add <mem>,<con>实例:
add eax, 10 //EAX ← EAX + 10
add BYTE PTR [var], 10 //10与var指示的内存中的一个byte的值相加,并将结果保存在var指示的内存中sub— Integer Subtraction
sub指令指示第一个操作数减去第二个操作数,并将相减后的值保存在第一个操作数,其语法如下所示:
sub <reg>,<reg>
sub <reg>,<mem>
sub <mem>,<reg>
sub <reg>,<con>
sub <mem>,<con>实例:
sub al, ah // AL ← AL - AH
sub eax, 216 //eax中的值减26,并将计算值保存在eax中inc, dec— Increment, Decrement
inc,dec分别表示将操作数自加1,自减1,其语法如下所示:
inc <reg>
inc <mem>
dec <reg>
dec <mem>实例:
dec eax //eax中的值自减1.
inc DWORD PTR [var] //var指示内存中的一个4-byte值自加1imul— Integer Multiplication
整数相乘指令,它有两种指令格式,一种为两个操作数,将两个操作数的值相乘,并将结果保存在第一个操作数中,第一个操作数必须为寄存器;第二种格式为三个操作数,其语义为:将第二个和第三个操作数相乘,并将结果保存在第一个操作数中,第一个操作数必须为寄存器。其语法如下所示:
imul <reg32>,<reg32>
imul <reg32>,<mem>
imul <reg32>,<reg32>,<con>
imul <reg32>,<mem>,<con>实例:
imul eax, [var] //eax→ eax * [var]
imul esi, edi, 25 // ESI → EDI * 25idiv— Integer Division
idiv指令完成整数除法操作,idiv只有一个操作数,此操作数为除数,而被除数则为EDX:EAX中的内容(一个64位的整数),操作的结果有两部分:商和余数,其中商放在eax寄存器中,而余数则放在edx寄存器中。其语法如下所示:
idiv <reg32>
idiv <mem>实例:
idiv ebx
idiv DWORD PTR [var]
and, or, xor— Bitwise logical and, or and exclusive or逻辑与、逻辑或、逻辑异或操作指令
用于操作数的位操作,操作结果放在第一个操作数中。其语法如下所示:
and <reg>,<reg>
and <reg>,<mem>
and <mem>,<reg>
and <reg>,<con>
and <mem>,<con>
or <reg>,<reg>
or <reg>,<mem>
or <mem>,<reg>
or <reg>,<con>
or <mem>,<con>
xor <reg>,<reg>
xor <reg>,<mem>
xor <mem>,<reg>
xor <reg>,<con>
xor <mem>,<con>实例:
and eax, 0fH //将eax中的钱28位全部置为0,最后4位保持不变.
xor edx, edx //设置edx中的内容为0.not— Bitwise Logical Not
位翻转指令,将操作数中的每一位翻转,即0->1, 1->0。其语法如下所示:
not <reg>
not <mem>实例:
not BYTE PTR [var] — 将var指示的一个字节中的所有位翻转.neg— Negate
取负指令。语法为:
neg <reg>
neg <mem>实例:
neg eax // EAX → - EAXshl, shr— Shift Left, Shift Right
位移指令,有两个操作数,第一个操作数表示被操作数,第二个操作数指示位移的数量。其语法如下所示:
shl <reg>,<con8>
shl <mem>,<con8>
shl <reg>,<cl>
shl <mem>,<cl>
shr <reg>,<con8>
shr <mem>,<con8>
shr <reg>,<cl>
shr <mem>,<cl>实例:
shl eax, 1 // Multiply the value of EAX by 2 (if the most significant bit is 0),左移1位,相当于乘以2
shr ebx, cl //Store in EBX the floor of result of dividing the value of EBX by 2n where n is the value in CL.控制转移指令
X86处理器维持着一个指示当前执行指令的指令指针(IP),当一条指令执行后,此指针自动指向下一条指令。IP寄存器不能直接操作,但是可以用控制流指令更新。
一般用标签(label)指示程序中的指令地址,在X86汇编代码中,可以在任何指令前加入标签。如:
mov esi, [ebp+8]
begin: xor ecx, ecx
mov eax, [esi]如第二条指令用begin指示,这种标签的方法在某种程度上简化了汇编程序设计,控制流指令通过标签实现程序指令跳转。
jmp — Jump
控制转移到label所指示的地址,(从label中取出执行执行),如下所示:
jmp <label>实例:
jmp begin //Jump to the instruction labeled begin.jcondition— Conditional Jump
条件转移指令,条件转移指令依据机器状态字中的一些列条件状态转移。机器状态字中包括指示最后一个算数运算结果是否为0,运算结果是否为负数等。机器状态字具体解释请见微机原理、计算机组成等课程。语法如下所示:
je <label> (jump when equal)
jne <label> (jump when not equal)
jz <label> (jump when last result was zero)
jg <label> (jump when greater than)
jge <label> (jump when greater than or equal to)
jl <label> (jump when less than)
jle <label>(jump when less than or equal to)实例:
cmp eax, ebx
jle done //如果eax中的值小于ebx中的值,跳转到done指示的区域执行,否则,执行下一条指令。cmp— Compare
cmp指令比较两个操作数的值,并根据比较结果设置机器状态字中的条件码。此指令与sub指令类似,但是cmp不用将计算结果保存在操作数中。其语法如下所示:
cmp <reg>,<reg>
cmp <reg>,<mem>
cmp <mem>,<reg>
cmp <reg>,<con>实例:
cmp DWORD PTR [var], 10
jeq loop,比较var指示的4字节内容是否为10,如果不是,则继续执行下一条指令,否则,跳转到loop指示的指令开始执行
call, ret— Subroutine call and return
这两条指令实现子程序(过程、函数等意思)的调用及返回。call指令首先将当前执行指令地址入栈,然后无条件转移到由标签指示的指令。与其它简单的跳转指令不同,call指令保存调用之前的地址信息(当call指令结束后,返回到调用之前的地址)。
ret指令实现子程序的返回机制,ret指令弹出栈中保存的指令地址,然后无条件转移到保存的指令地址执行。
call,ret是函数调用中最关键的两条指令。具体细节见下面一部分的讲解。语法为:
call <label>
ret教材学习中的问题和解决过程
- 问题:如何理解逆向?
- 解决:通过在百度搜索,我在百度百科中找到了答案:逆向工程(又称逆向技术),是一种产品设计技术再现过程,即对一项目标产品进行逆向分析及研究,从而演绎并得出该产品的处理流程、组织结构、功能特性及技术规格等设计要素,以制作出功能相近,但又不完全一样的产品。逆向工程源于商业及军事领域中的硬件分析。其主要目的是在不能轻易获得必要的生产信息的情况下,直接从成品分析,推导出产品的设计原理。软件逆向工程有多种实现方法,主要有三:
- 1.分析通过信息交换所得的观察。
最常用于协议逆向工程,涉及使用总线分析器和数据包嗅探器。在接入计算机总线或网络的连接,并成功截取通信数据后,可以对总线或网络行为进行分析,以制造出拥有相同行为的通信实现。此法特别适用于设备驱动程序的逆向工程。有时,由硬件制造商特意所做的工具,如JTAG端口或各种调试工具,也有助于嵌入式系统的逆向工程。对于微软的Windows系统,受欢迎的底层调试器有SoftICE。 - 2.反汇编,即使用反汇编器,把程序的原始机器码,翻译成较便于阅读理解的汇编代码。这适用于任何的计算机程序,对不熟悉机器码的人特别有用。流行的相关工具有OllyDebug和IDA。
- 3.反编译,即使用反编译器,尝试从程序的机器码或字节码,重现高级语言形式的源代码。
- 1.分析通过信息交换所得的观察。
- 问题:指令集体系结构(Instruction-Set Architecture, ISA)
- 解决:通过阅读CSDN上的博客我找到相关知识辅助我理解:
一个处理器支持的指令和指令的字节级编码就是这个处理器的ISA,包括很多个部分:- 指令集
- 指令集编码
- 基本数据类型
- 一组编程规范
- 寄存器
- 寻址模式
- 存储体系
- 异常事件处理
- 中断
- 外部I/O
- 作用:ISA在编译器编写者(CPU软件)和处理器设计人员(CPU硬件)之间提供了一个抽象层:
- 处理器设计者:依据ISA来设计处理器
- 处理器使用者(如:写编译器的牛*程序员):依据ISA就知道CPU选用的指令集,就知道自己可以使用哪些指令以及遵循哪些规范
- 定义处理器上的软件如何构建,这是ISA的最重要内涵,现代处理器都是支持高级语言编程、操作系统等等特性,ISA要定义出指令集内的指令是如何支撑起C语言里堆栈、过程调用,操作系统里异常、中断,多媒体平台里数字图像处理、3D加速等等。
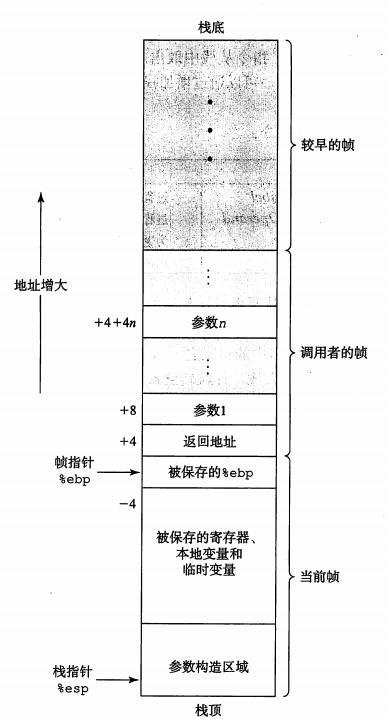
- 问题:在汇编中如何调用函数
- 解决:如果要调用一个函数,实现将数据和控制代码从一个部分到另一个部分的跳转。我们如何来分配执行函数的变量空间,并在返回的时候释放空间,将返回值返回。下面是一张图,非常便于理解:
代码调试中的问题和解决过程
无
返回目录
本周结对学习情况
- 结对学习博客
20155302 - 结对学习图片

- 结对学习内容
- 教材第三章
代码托管
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 10/10 | |
| 第二周 | 0/0 | 0/1 | 10/20 | |
| 第三周 | 200/200 | 2/3 | 10/30 | |
| 第四周 | 100/300 | 1/4 | 10/40 | |
| 第五周 | 200/500 | 2/5 | 10/50 |
- 计划学习时间:10小时
- 实际学习时间:10小时














 55
55











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









