






上一章地址 英伟达的GPU(4) (qq.com)
我们之前讲过了GPU的kernel,线程划分,内存管理
这节我们讲一下多个GPU的通信
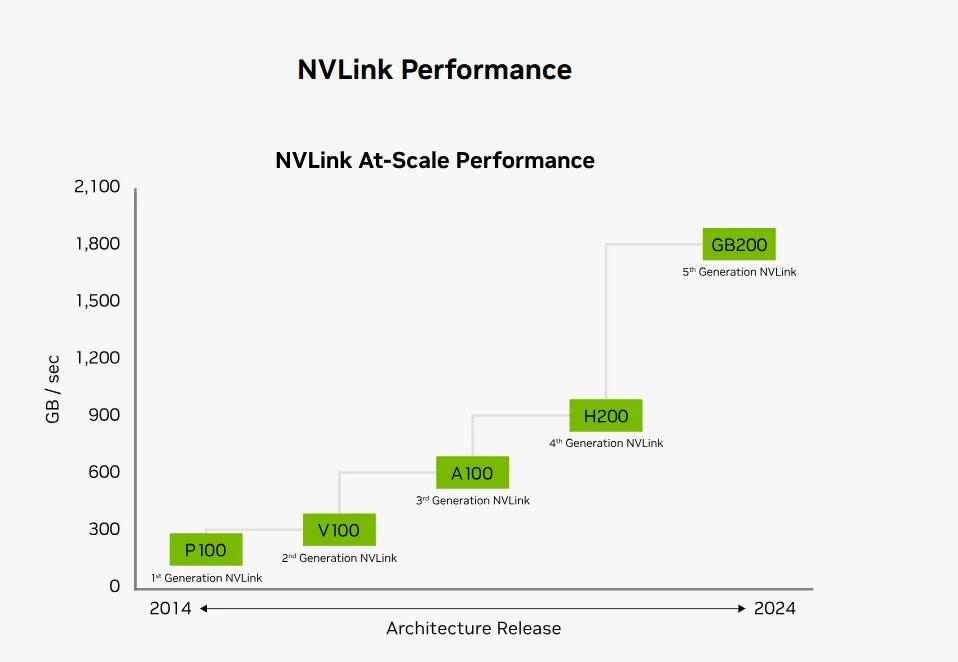
从这张 NVLink 性能发展的图表可以看出,NVLink 技术自 2014 年以来经历了多次升级,性能不断提高。以下是各代 NVLink 的发展和性能提升情况:
NVLink 性能发展历程
- P100 (1st Generation NVLink):
- 发布年份:2014
- 性能:第一代 NVLink,数据传输速率在 300 GB/sec 。
- V100 (2nd Generation NVLink):
- 性能:第二代 NVLink,相比第一代有显著提升,数据传输速率约为 600 GB/sec。
- A100 (3rd Generation NVLink):
- 性能:第三代 NVLink,再次提升,数据传输速率约为 600 GB/sec。
- H200 (4th Generation NVLink):
- 性能:第四代 NVLink,进一步提升,数据传输速率在 900 GB/sec 。
- GB200 (5th Generation NVLink):
- 性能:第五代 NVLink,最新一代 NVLink,数据传输速率约为 1800 GB/sec。

这里面保不齐有学通信的兄弟就会问了,你这为啥用B,也就是byte,正常描述带宽都是用bit啊
但NVlink这东西它也不是要跟以太网,或者SDH啥的比,人家是跟PCIE比。
我们来看一下PCIE的发展史(我都四舍五入了,看个整,比如PCIE3是985M,这误差写1G了也不耽误看):
- PCIe 1.0 (2003)
- 每通道带宽:250 MB/s
- 双向带宽:500 MB/s
- 总带宽(16通道):4 GB/s(单向)
- 特点:首次引入,替代旧的PCI和AGP接口。
- PCIe 2.0 (2007)
- 每通道带宽:500 MB/s
- 双向带宽:1 GB/s
- 总带宽(16通道):8 GB/s(单向)
- 特点:带宽翻倍,支持改进的电源管理功能。
- PCIe 3.0 (2010)
- 每通道带宽:1 GB/s
- 双向带宽:2 GB/s
- 总带宽(16通道):16 GB/s(单向)
- 特点:进一步翻倍,改进信号编码,提高数据传输效率。
- PCIe 4.0 (2017)
- 每通道带宽:2 GB/s
- 双向带宽:4 GB/s
- 总带宽(16通道):32 GB/s(单向)
- 特点:带宽再次翻倍,适应高速存储和图形需求。
- PCIe 5.0 (2019)
- 每通道带宽:4 GB/s
- 双向带宽:8 GB/s
- 总带宽(16通道):64 GB/s(单向)
- 特点:显著提升带宽,以满足下一代计算和数据需求,如AI和大数据分析。
- PCIe 6.0 (预计2024)
- 每通道带宽:8 GB/s
- 双向带宽:16 GB/s
- 总带宽(16通道):128 GB/s(单向)
- 特点:带宽翻倍,采用PAM-4调制技术,提高传输效率和可靠性。
- 明年预计的7.0估计单通道双向30GB/s, 16通道也能到小500GB/s(双向)
后来就出了Nvswitch这种板载的交换芯片,就是替换上图的PCIE switch的。

虽然说Nvswitch不会增强物理信号的带宽,但是,它让任何两块卡都是点到点的一跳通信了(跟交换机的CLos系统一样,无阻塞通信),极大的提升了通信效率
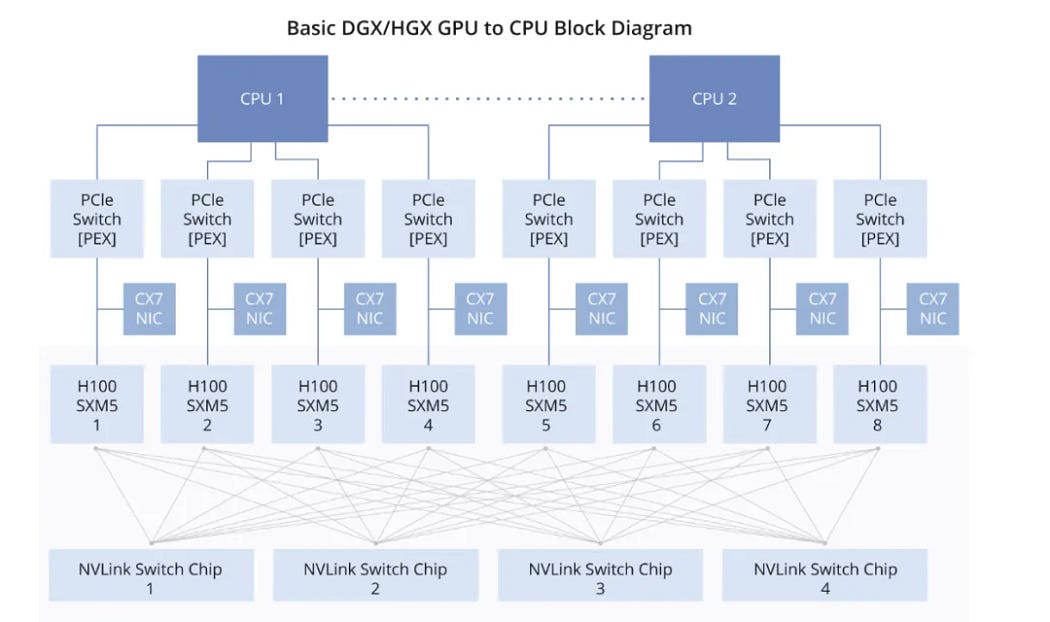
但是我们发现GPU和GPU之间的通信问题解决了,但是GPU到CPU之间还是走得PCIE,也就是说比如你要CPU和GPU之间的通信(分模型,分训练数据,写checkpoint啥的)还是要来回转通信介质,同时速度也不成。
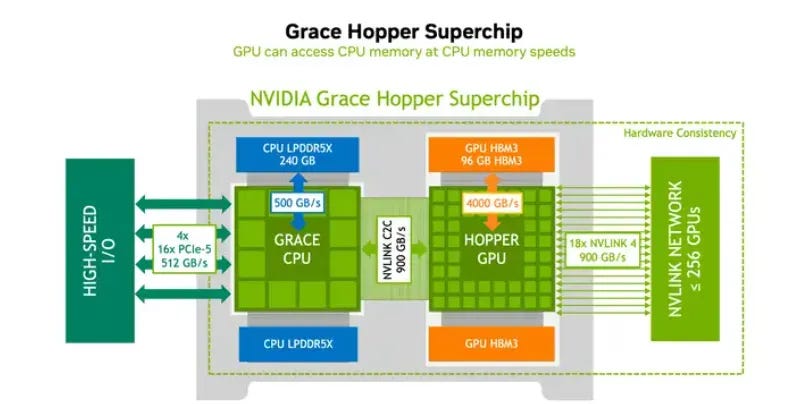
这个问题在GH架构里也给解决了,Grace CPU和HGPU,直接NVlink通信了,可别小看块,真正很多模型训练慢,很多问题还真是在这块,不信你试试。
在第5代Nvlink,也就是B系列之前,Nvlink都是玩内部通信的,所以你们看它的能力也就是8。
从Blackwell开始,NVlink出圈了,不只在机器里面待着,要出去大干一票(抢IB和RoCE的地盘了)
大概长这样 GB200 NVL72

这一个东西含有36个Grace CPU,72个B GPU,全部都有Nvlink来通信,后面还有更大的扩展,最大支持576个GPU,明眼人一看这基本就不给RoCE活路了,RoCE以后就在非NV的平台上玩吧(IB毕竟NV自己在主推,而且超过500的GPU,不还是得IB)。
这样你GPU跨多个机箱甚至机柜,这些GPU和CPU到彼此也就是一跳而已,而且也不用转信号,Nvlink到PCIE,也不占通信时钟,所有的时钟全留给计算,通信就交给Nvlink就完事了。
从某种程度上我个人觉得,这个才是后面NV系列GPU的最大的竞争力。
















 3442
3442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









