






1. 检索API
注意:本章节内容,依赖于上一章节批量导入的数据。
参考: https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-search.html
1.1 ES支持两种检索方式:
1. REST请求 + 查询字符串
GET bank/_search?q=*
2. REST请求 + 请求体
GET bank/_search
{
"query": {
"match_all": { }
}
}
这种方式称之为:Query DSL(领域特定语言),注意,这个例子中,DSL是从第2行开始,到第6行结束的,并不包含第一行。
1.2 排序
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance": {
"order": "desc"
}
}
]
}
1.3 分页
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 5,
"size": 5
}
1.4 筛选字段
GET bank/_search
{
"query": {
"match_all": {}
},
"_source": ["account_number", "balance", "age"]
}
1.5 math 匹配查询
精确匹配:如果match中所写的字段,是一个非字符串字段,则当前的查询就是“精确匹配”。因为不涉及分词操作。
GET bank/_search
{
"query": {
"match": {
"account_number": "44"
}
}
}
模糊匹配:如果match中所写的字段,是一个字符串字段,则当前的查询就是“模糊匹配”。因为涉及分词操作。
GET bank/_search
{
"query": {
"match": {
"address": "Kings Baycliff"
}
}
}
匹配结果如下:
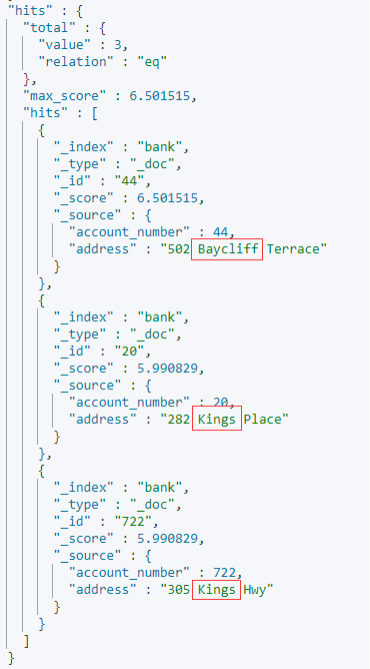
注意,分词操作,会发生在两个时机:索引文档时,会对文档内容进行分词,以便创建倒排索引;模糊匹配时,会对查询条件进行分词,再拿着经过分词处理的条件,与倒排索引中的索引进行匹配。所以这两个时机使用的分词器是一定肯定必须是一致的!
思考
我们已经知道,有用户的住址为“Kings”,那么按照“ing”来匹配的话,以下查询是否有结果?
GET bank/_search
{
"query": {
"match": {
"address": "ing"
}
},
"_source": ["account_number", "address"]
}
1.6 multi_match 多字段匹配
如下,state字段,或address字段中,包含经过分词处理的“mill MT”的内容,就算作匹配
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill MT",
"fields": ["state", "address"]
}
},
"_source": ["state", "address"]
}
1.7 范围查询
GET bank/_searchu
{
"query": {
"range": {
"age": {
"gte": "18",
"lte": "30"
}
}
}
}
1.8 bool 复合查询
must,多个条件必须同时满足
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "F"
}
},
{
"match": {
"state": "PA"
}
}
]
}
}
}
过程推测:先查找出所有gender为"F"的文档id,假设这是一个集合A;再找出所有state为"PA"的文档id,假设设置一个集合B;最后计算A集合和B集合的交集,这个交集为C,C就是最终要展示的结果
must_not,多个条件必须都不满足
GET bank/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"gender": "F"
}
},
{
"match": {
"state": "PA"
}
}
]
}
}
}
过程推测:先查找出所有gender为"F"的文档id,假设这是一个集合A;再找出所有state为"PA"的文档id,假设这是一个集合B;最后计算集合A、集合B的并集C,再拿全集减去这个C集合,得到这个差集为D,D就是最终要展示的结果。
should,单独使用should,效果与or是一致的
GET bank/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"lastname": "Duke"
}
},
{
"match": {
"lastname": "Bates"
}
}
]
}
}
}
当should与must连用时,should并不会影响查询出哪些文档,它仅仅是在es根据must中的条件查出文档之后,对文档的相关性得分有所影响,满足should条件的,就给相关性得分加分,否则就不加分
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
}
],
"should": [
{
"match": {
"lastname": "Adams"
}
}
]
}
}
}
过程推测:先查询出gender为M的文档,存入集合A中,在数据收集完毕后,再判断集合A中的文档是否满足should指定的条件,如果满足,则加分。 如果不满足,也不做任何处理。
"minimum_should_match"
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
}
],
"should": [
{
"match": {
"address": "282 Kings Place"
}
},
{
"range": {
"age": {
"gte": 30
}
}
}
]
"minimum_should_match": 1
}
},
"from": 0,
"size": 213
}
must和should对结果的相关性得分有影响,这意味着,分数越高,结果越与must和should中的条件越匹配!反观must_not,它对相关性得分没有任何影响。
1.9 过滤器
过滤器,用于过滤结果,也就是计算完结果的相关性得分之后,才使用过滤器对结果进行过滤
GET bank/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"age": {
"gte": 18,
"lte": 20
}
}
}
]
}
}
}
过滤器与范围查询的区别:
1. 范围查询,是根据指定的某个字段的范围,搜索文档的过程,该过程中会计算结果的相关性得分,而对于过滤器,是在搜索文档结束之后,在所有结果的相关性得分确定下来之后,再次对这些结果进行物理上的过滤,不会影响相关性得分!
2.范围查询可以直接编写在"query"中,而过滤器必须使用在“bool”复合查询中
举一反三,下面的例子演示出了,filter编写的位置与 must 、 must_not、should是平级的,也就是说,在bool下可以写:must、must_not、should、filter。
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "F"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 18,
"lte": 20
}
}
}
]
}
}
}
1.10 term
首先,我们查询一个“_id”为151的文档
GET bank/_search
{
"query": {
"match": {
"_id": 151
}
}
}
查询结果如下,可以看到该文档中的address字段的值
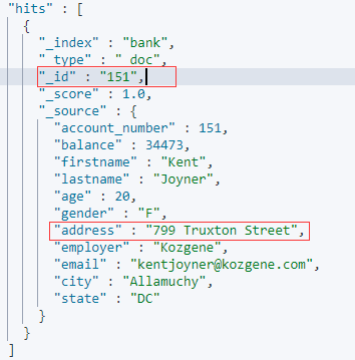
然后,我们反过来以这个文档的address的值来查询该文档:
使用match,会查出多个结果,因为在查询时,es会对查询条件进行分词
GET bank/_search
{
"query": {
"match": {
"address": "799 Truxton Street"
}
}
}

使用term,查不出任何一个结果,因为在查询时,es不会对查询条件进行分词
GET bank/_search
{
"query": {
"term": {
"address": "799 Truxton Street"
}
}
}

记住,分词用在两个地方:索引文档时,和搜索数据时,而索引文档的时候,会把“799 Truxton Street”分成“799”、“Truxton”、“Street”来存储,导致使用term搜索时,“799 Truxton Street”找不到对应的分词,从而查不出任何一个结果。
那么term有什么价值呢?由于使用term方法搜索文档时,不需要分词器对搜索词进行分词,所以效率高,当搜索条件中使用的字段是非字符串时,term将会工作得很好!
对比:match 和 term,match会对搜索词进行分词,term不会对搜索词进行分词!所以term就要搭配*.keyword索引来查询... 补充:当match搭配keyword索引时,也不会对搜索词进行分词。
小结:
GET bank/_search
{
"query": {
"term": {
"address": "abc xyz"
}
}
}
term | match | |
address | 对搜索词不分词找分词的索引结果一个都没有 | 对搜索词分词找分词的索引结果有多个 |
address.keyword | 对搜索词不分词找不分词的索引结果只有一个 | 对搜索词不分词找不分词的索引结果只有一个 |
只要term出现,搜索词绝对不分词
match是跟着索引走。
1.11 match_phrase 短语匹配
GET bank/_search
{
"query": {
"match_phrase": {
"address": "799 Truxton Street"
}
}
}
查询结果
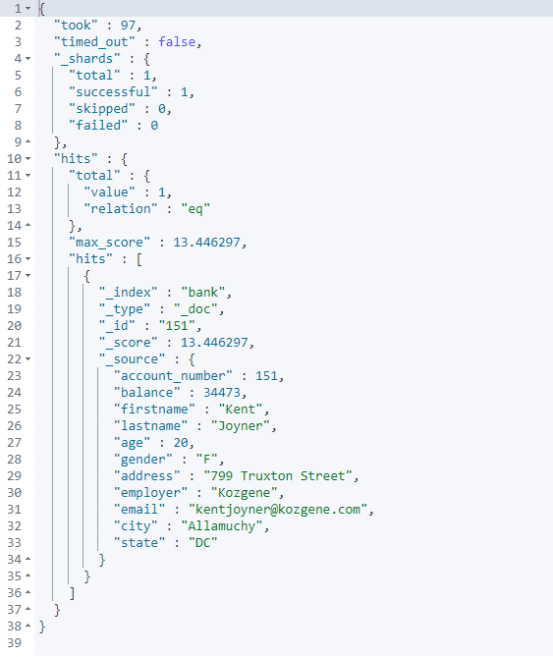
term vs match_phrase
1. term,若一个字段的值是12345,那么搜索词不论是1234还是123456都不会命中这个12345。
2. match_phrase,若一个字段的值是12345,
☐ 那么搜索词是1234的话,就会命中。
☐ 那么搜索词是345的话,就会命中。
☐ 是123456的话就不会命中这个12345。
2. 聚合API
Es中的聚合操作,与Mysql中的分组操作比较相似,但是仍然有不同的地方,让我们通过一个例子来体会一下吧。
2.1 简单例子
查询balance在10000和20000之间的用户
GET bank/_search
{
"query": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
}
}
查询balance在10000和20000之间的用户中,每个年龄有多少人
GET bank/_search
{
"query": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
},
"aggs": {
"terms_age": {
"terms": {
"field": "age"
}
}
}
}

Es中的聚合 vs mysql中的聚合
在Mysql中,也是会先根据条件查询出一个结果集,然后再对这个结果集进行分组、聚合操作,在分组聚合操作之后,原始的结果集已经不存在了,所以返回给客户端的,就只有分组聚合之后的数据了。
|
|
|


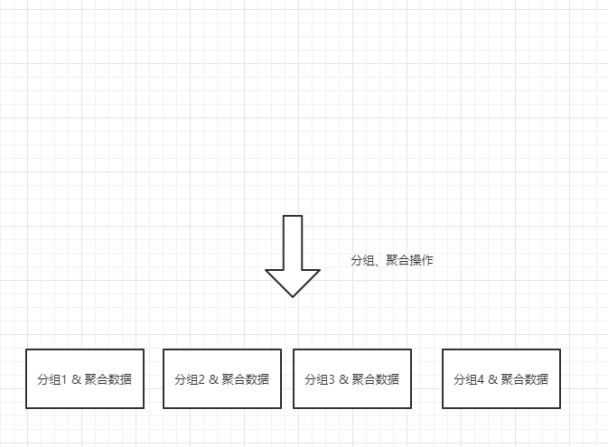
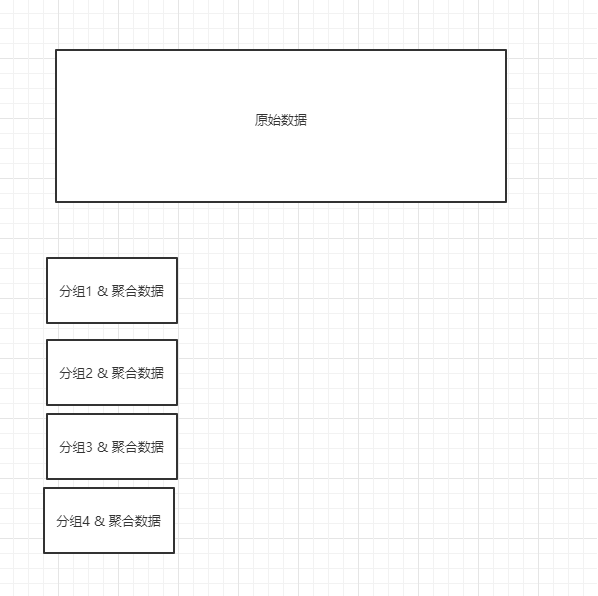
在es中,会根据条件搜索出原始数据,然后对原始数据进行聚合操,在对原始数据进行聚合操作之后,还是会保留原始数据的,所以返回给客户端的结果是:原始数据 + 聚合数据。
|
|
|

经过es和mysql的这个对比,对于理解后续的内容会很有帮助的!
2.2 对原始数据进行各种不同的聚合
搜索balance在10000和2000之间的用户
GET bank/_search
{
"query": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
}
}
搜索balance在10000和2000之间的用户,以及他们的平均薪资
GET bank/_search
{
"query": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
},
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
}
搜索balance在10000和2000之间的用户,每个age都有多少人
GET bank/_search
{
"query": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
},
"aggs": {
"terms_age": {
"terms": {
"field": "age"
}
}
}
}
搜索balance在10000和20000之间的用户,以及他们的平均薪资,以及每个age都有多少人
GET bank/_search
{
"query": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
},
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
},
"terms_age": {
"terms": {
"field": "age"
}
}
}
}
关键之处在于,我们已经对原始数据进行了平均余额的聚合,对原始数据已经按照余额进行了聚合!若不是原始数据仍然存在,我们怎么还可以再次统计原始数据中的每个age都有多少人呢?
所以,在es中,在一次查询中,可以对一个搜索出来的原始数据,反复进行各种不同的聚合操作!
2.3 对于text类型的字段,不能进行terms聚合操作
以下示例对text类型的address进行了terms聚合操作,也就是把address相同的文档分为一组,然后计算每个组的文档个数。
GET bank/_search
{
"query": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
},
"aggs": {
"terms_address": {
"terms": {
"field": "address"
}
}
}
}
但是,运行结果是错误的:

翻译:对Text类型的字段进行聚合或者排序操作时,性能不是很好!所以对Text类型进行聚合或者排序的操作是被禁止的!取而代之,你可以使用“keyword”字段来完成这个操作。
为什么针对于text类型的字段,进行聚合操作时,性能不是很好呢(进而被禁止呢)?我们就拿address字段来说明,address字段的倒排索引如下:
Term | Posting List |
西安 | 1,2 |
西安市 | 1,2 |
大街 | 1,2,3 |
北京 | 3 |
北京市 | 3 |
北大街 | 1 |
南大街 | 2 |
东大街 | 3 |
如果此时查询按address进行聚合操作的话:
“西安”组 | 1,2 |
“大街”组 | 1,2,3 |
很容易发现,西安组有2人,大街组有3人,其中“1,2”被重复使用了,在两个组中都有。所以这种数据结构是无法做出聚合分组操作的。
思考
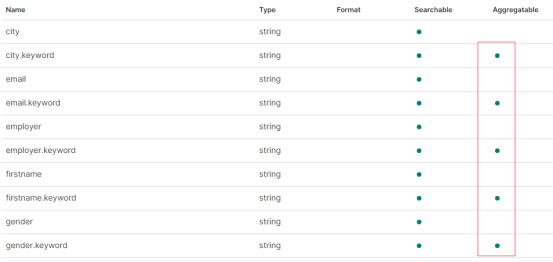
根据"address.keyword"进行聚合操作是否可以?















 6403
6403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









