






一套11.2.0.4的RAC,节点时间采用ntpdate使用cron job的方式进行同步。
节点1因硬件故障宕机之后,集群服务久久不能启动。连上主机,采用crsctl stop has -f,crsctl start has的方式进行重启,
同时采用crsctl stat res -t -init的方式查看集群基础服务启动的状态。发现CTSS启动时有报错,最终呈现offline的状态。
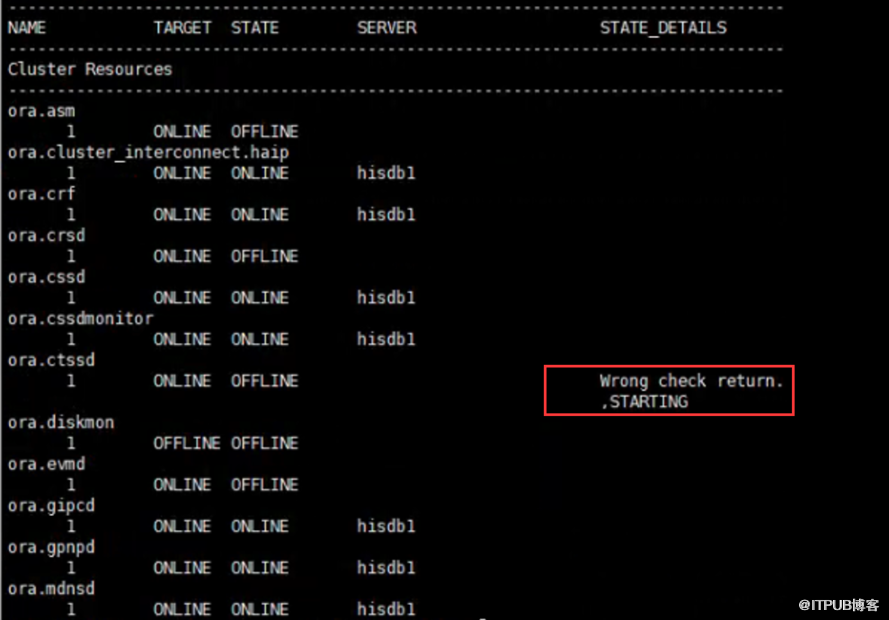
采用如下命令删除了oracle集群相关的一些文件,之后,重启HAS,问题依旧
rm -rf /usr/tmp/.oracle/* /var/tmp/.oracle/* /tmp/.oracle/*
查看octssd.log, 发现存在如下信息:
2020-05-26 10:25:06.738: [ CTSS][149128960]ctssslave_msg_handler4_1: Waiting for slave_sync_with_master to finish sync process. sync_state[3].
2020-05-26 10:25:06.738: [ CTSS][142825216]ctssslave_swm2_3: Received time sync message from master.
2020-05-26 10:25:06.738: [ CTSS][142825216]ctssslave_swm: The magnitude [86413682462 usec] of the offset [86413682462 usec] is larger than [86400000000 usec] sec which is the CTSS limit.
2020-05-26 10:25:06.738: [ CTSS][142825216]ctsselect_monitor_steysync_mode: Failed in clsctssslave_sync_with_master [12]: Time offset is too much to be corrected
2020-05-26 10:25:06.738: [ CTSS][149128960]ctssslave_msg_handler4_3: slave_sync_with_master finished sync process. Exiting clsctssslave_msg_handler
2020-05-26 10:25:07.485: [ CTSS][166291200]ctss_checkcb: clsdm requested check alive. checkcb_data{mode[0xd0], offset[86413682 ms]}, length=[8].
2020-05-26 10:25:07.485: [ CTSS][142825216]ctsselect_monitor_steysync_mode: CTSS daemon exiting [12].
2020-05-26 10:25:07.485: [ CTSS][142825216]CTSS daemon aborting
于是采用ntpdate的方式,强制同步了两个节点的时间/usr/sbin/ntpdate *.*.*.* && /sbin/hwclock
重启HAS, 集群顺利启动
参考:















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









