






第七章YDB基本使用详解
一、如何与YDB对接(交互)
目前延云YDB提供如下几种方式
l命令行的方式
lWeb http接口的方式
lJDBC接口的方式
通过Java编程接入
通过可视化SQL分析统计接入
通过报表分析工具接入
二、命令行接入
进入ya100的安装目录的bin目录
1.直接执行 ./conn.sh 即可。
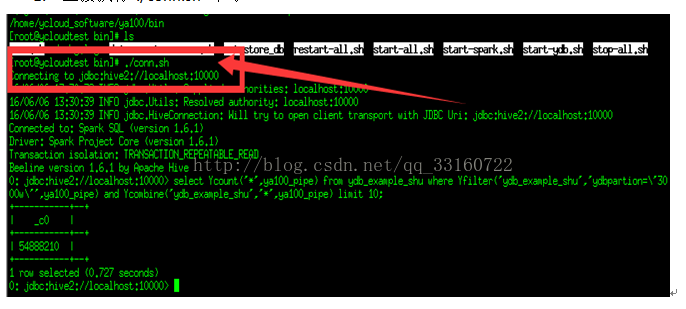
2.通过./sql.sh -f xxx.sql 直接执行文件中的SQL
三、WEB接入
WEB接口主要是为了给那些不支持HDBC访问的程序提供接口支持,如PHP。
1.图形SQL 提交地址
http://xxx.xx.xx.xx:1210/sparkview

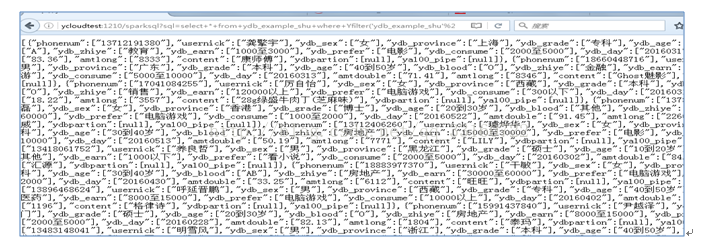
2.Json接口
http://xxx.xx.xx.xx:1210/sparksql?sql=?
SQL参数可以GET方式提交,也可以POST方式提交
四、JDBC接口
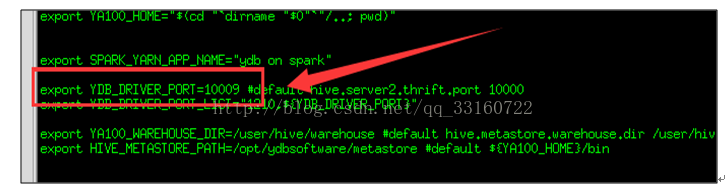
1.JDBC接入方式连接字符串
Connection conn = DriverManager.getConnection("jdbc:hive2://ydbmaster:10009/default", "hdfs", "");
l10009表示JDBC的端口号,配置的值在ya100_evn.sh里面可以找到
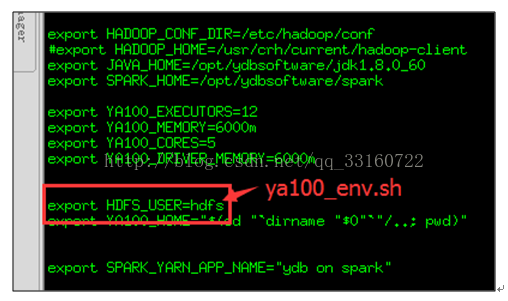
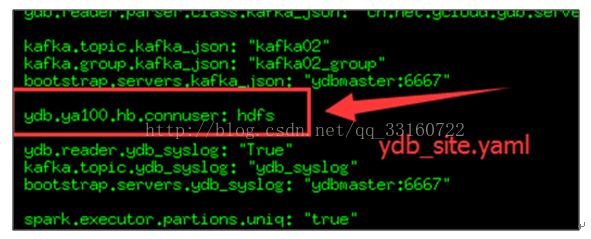
lhdfs表示连接时所使用的Hadoop账号,大家也要跟配置文件中一致,以免其他未知账号产生垃圾文件没有及时的清理掉,以及造成Hadoop权限问题。
这个账号的配置目前存在两个位置,请大家配置一致,使用同一个账号。
2.JAVA编程接口
Class.forName("org.apache.Hive.jdbc.HiveDriver");
Connection conn = DriverManager.getConnection("jdbc:hive2://ydbmaster:10009/default", "hdfs", "");
Statement smst = conn.createStatement();
ResultSet rs = smst.executeQuery("/*ydb.pushdown('->')*/ select * from ydb_example_shu where ydbpartion = '3000w' limit 10 /*('<-')pushdown.ydb*/");
ResultSetMetaData m = rs.getMetaData();
int columns = m.getColumnCount();
for (int i = 1; i <= columns; i++) {
System.out.print(m.getColumnName(i));
System.out.print("\t\t");
}
while (rs.next()) {
for (int i = 1; i <= columns; i++) {
System.out.print(rs.getString(i));
System.out.print("\t\t");
}
System.out.println();
}
rs.close();
conn.close();
依赖的JDBC客户端jar包可以从这个地址获取,本质上就是HIVE的thrift接口,依赖的jar包也是Hive的jar包
http://url.cn/42R4CG8
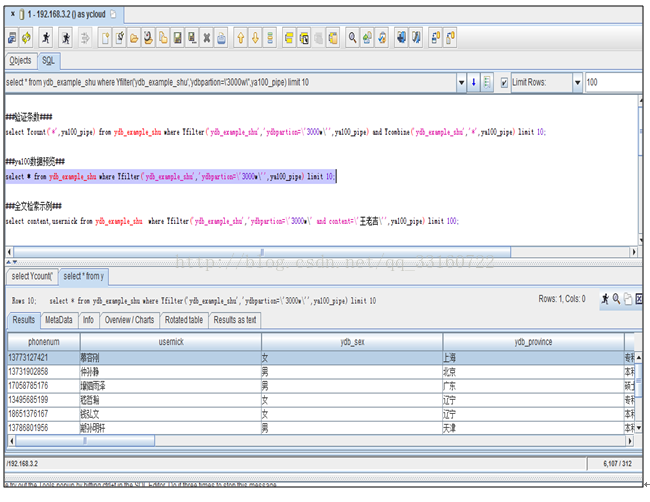
3.通过可视化SQL分析统计接入
SQL分析工具有很多,只要支持HIVE接口即可,免费的有Squirrel、收费的有DbVisualizer等
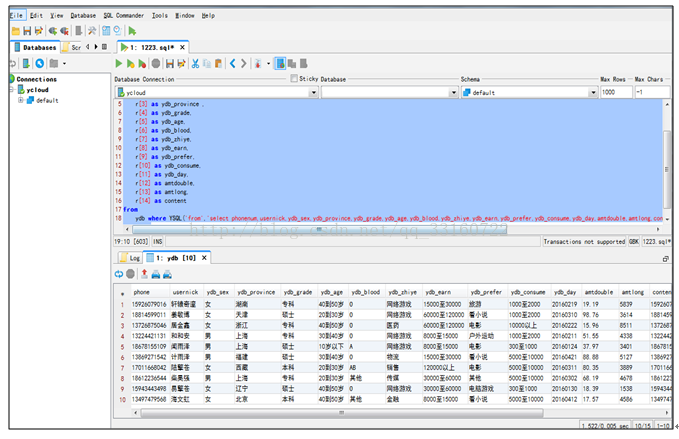
4.通过报表分析工具接入
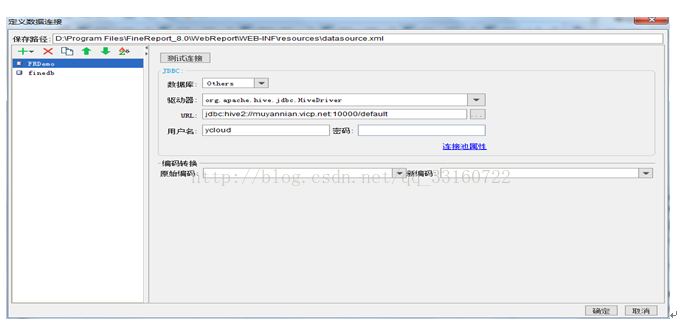
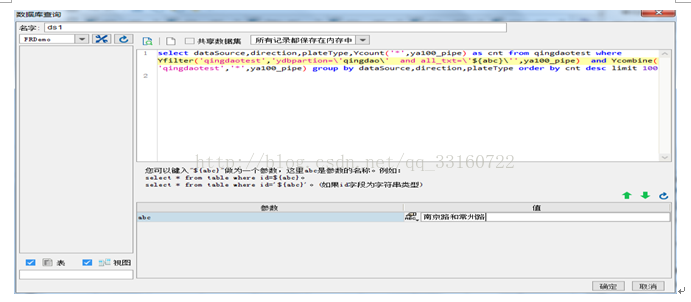
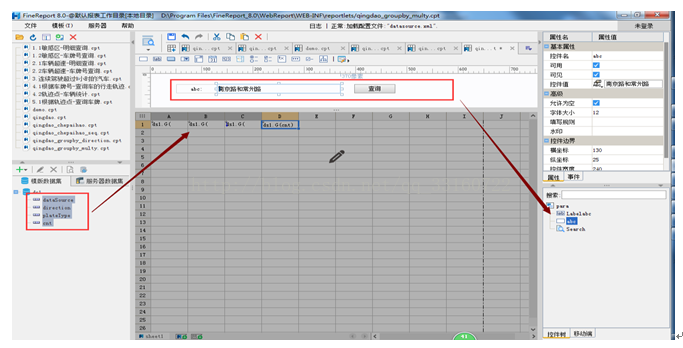
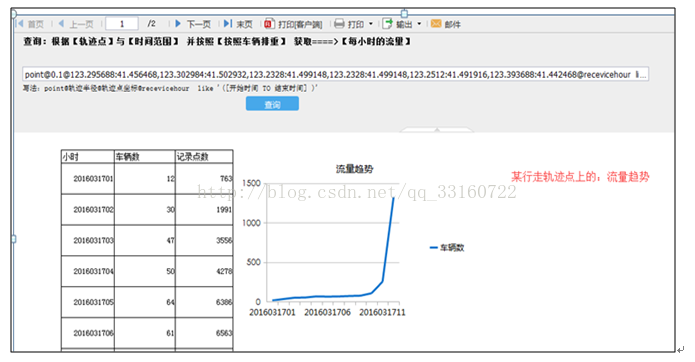
通过可视化报表分析工具,可以极大的提高程序开发的效率,只要是支持HIVE接口的可视化报表工具,都可以与YDB集成,下面以帆软报表为例。
五、YDB分区
1.关于分区的说明
随着时间的日积月累,单个索引会越来越大,从而导致系统瓶颈。YDB不会将全部的数据都完整的创建在一个索引中,YDB会对数据进行分区,分区的方式由用户来定义,可以按照日期分区,也可以按照某些固定的HASH方式来分区。
一条数据的分区,在导入的时候直接指定,具体请参考后面的数据导入用法。
如果按照日期进行分区,每天就会生成一个分区,如需查询哪天的数据,就去对应的分区中检索,其他的分区则闲置。
YDB 的SQL需要通过ydbpartion来指定分区; SQL查询必须要设置分区,而且要写在SQL的最外层。
如果没有指定ydbpartion分区的查询,ydb表默认会去查询 " ydb_default_partion" 这个分区,也就是说,如果我们真的不想进行数据分区,不想在sql上添加ydbpartion的条件来指定分区,那么请将数据都导入到 " ydb_default_partion"这个分区里面。
设置分区例子如下:
ydbpartion ='20140928'
ydbpartion in ('20140928','20140927')
目前不支持大于等于,小于等于的范围指定分区,仅支持等于与in的方式。
2.关于分区的数量与粒度,控制多少比较好?
l如果我们的数据可以按照时间进行切分,是不是切分的越细越好?
很遗憾,YDB并不适合特别多的分区,分区越多代表索引文件越多
1)YDB中打开一个索引是有很大的开销的,打开一个索引加载的列的信息、索引的BlockTree的相关主干节点等,需要消耗较多的内存,而且要持久化到内存里去维护这个索引的状态。这就是为什么大家会发现,对于一个表第一次查询会比较慢,但是我们进行一次count以后,在进行别的查询就会快很多。
2)YDB在一个进程里能够打开的索引数量是有限的,如果超过了打开的索引文件数量,那么就要关闭一些索引,以保证内存不会OOM。
3)小文件太多,对HDFS的NameNode的压力较大。
l那么分区粒度控制在多少为好?
基本原则就是在避免索引频繁的打开与关闭的情况下,索引粒度越小越好。
1)如果我们的数量不是很大,一年加在一起还不到10亿,那么我就建议采用按年分区。
2)如果我们的数据处于中等,每月的数据增量为1亿左右,那么我们建议按照季度分区。
3)如果我们的数据每天写入量特别大,如果按照月份分区,单个索引太大会造成写入瓶颈,那么我们建议按照天进行分区。
很多时候我们还可以根据不同的查询方式,采用两种粒度的分区
1)最近一两天的数据经常被查询,我们最近3天的数据按照天进行分区
2)但是偶尔也会发生查询整年的数据,如果采用按天分区的话,一次打开的索引太多,那么我们可以再加一个按照季度的分区。
3)按天的数据分区只保存最近7天的数据,超过7天的数据会通过insert的方式归档按照季度的分区里。
六、YDB的数据类型
1.基本类型
基本类型的存储方式均为 按列存储
| YDB类型 | 只索引 | 只存储 | Hive类型 | 解释 |
| string | synn | --- | string | 字符串类型,该类型不分词,通常用来存储比较短的字符串,如类目 |
| tint | tiynn | --- | int | 整形32位-适合大范围的range过滤查询 |
| tlong | tlynn | --- | bigint | 整形64位-适合大范围的range过滤查询 |
| tdouble | tdynn | --- | double | Double类型-适合大范围的range过滤查询 |
| tfloat | tfynn | --- | float | Float类型-适合大范围的range过滤查询 |
| int | iynn | --- | int | 整形32位,占用存储空间少,但是范围查找性能低 |
| long | lynn | --- | bigint | 整形64位,占用存储空间少,但是范围查找性能低 |
| double | dynn | --- | double | Double类型,占用存储空间少,但是范围查找性能低 |
| float | fynn | --- | float | Float类型,占用存储空间少,但是范围查找性能低 |
| geopoint | --- | --- | bigint | 用于地理位置搜索-使用方法详见《26.地理位置感知搜索.txt》 |
2.分词类型
分词( Word Segmentation) 指的是将一个词字序列切分成一个一个单独的词。分词就是将连续的词序列按照一定的规范重新组合成词序列的过程.
分词类型,均为按行存储,在YDB中可以进行模糊检索,但是不能在SQL里面进行group by(YSQL函数以外是可以的)。
| YDB类型 | 只索引 | 只存储 | Hive类型 | 解释 |
| simpletext | simpletextyn | simpletextny | string | ydb内置的普通文本分词 采用1~3元分词 |
| haoma | haomayn | haomany | string | ydb内置的适合号码类型的分词,采用3~5元分词实现,分词粒度为char |
| chepai | chepaiyn | chepainy | string | ydb内置的适合号码类型的分词,采用2~5元分词实现,分词粒度为char |
| text | tyn | tny | string | 为lucene默认的standard分词,在(处理手机号,邮箱,IP地址,网址等中英文与字典组合的数据上 不准确,请慎用) |
| cjkyy | cjkyn | cjkny | string | 为lucene默认的cjk分词即二元分词 (处理手机号,邮箱,IP地址,网址等中英文与字典组合的数据上 不准确,请慎用) |
以下类型除了分词外,还保存了分词后的词的顺序 ,可以进行顺序匹配
| YDB类型 | 只索引 | 只存储 | Hive类型 | 解释 |
| charlike | --- | --- | string | 按照字符char 1~5元分词 (效果较好,term区分了词元,适合车牌,手机号类型的较短文本) |
| wordlike | --- | --- | string | 按字与词 1~3元分词 (效果较好,term区分了词元,适合文本类型) |
| pchepai | --- | --- | string | 按照字符char 2~5元分词 |
| phaoma | --- | --- | string | 按照字符char 3~5元分词 |
| psimpletext | --- | --- | string | 按字与词 1~3元分词 |
| pyy | pyn | pny | string | lucene的cjk分词,中文采用二元分词,英文与数字采用 单字分词 |
3.多值列类型
有些时候,我们想在一个列里面存储多个值的时候,就可以考虑使用多值列了
比如说,可以将一个人 的多个标签值 存储在一个记录里面,一个人的每天的行为数据 放在一个记录里面。
一定要注意,
1.字符串类型的多值列,返回的值的无序,并且是排重的,故这块有额外注意。
2.数值型的则是有序的(与导入的顺序一致),并且是没有排重的。
3.传递的数值是按照空格拆分的,如 11 22 33 44
4.如果传递的是空值,会当做null处理
多值列所有数据类型均为按列存储
| YDB类型 | Hive类型 | 解释 |
| mt_syn | string | string类型的多值列 |
| mt_tlyn | string | tlong类型的多值列 |
| mt_lyn | string | long类型的多值列 |
| mt_tdyn | string | tdouble类型的多值列 |
| mt_dyn | string | double类型的多值列 |
| mt_iyn | string | int类型的多值列 |
| mt_tiyn | string | tint类型的多值列 |
| mt_fyn | string | float类型的多值列 |
| mt_tfyn | string | tfolat类型的多值列 |
七、创建YDB表
/*ydb.pushdown('->')*/
create table ydb_example_shu(
phonenum long,
usernick string,
ydb_sex string,
ydb_province string,
ydb_grade string,
ydb_age string,
ydb_blood string,
ydb_zhiye string,
ydb_earn string,
ydb_prefer string,
ydb_consume string,
ydb_day string,
amtdouble tdouble,
amtlong int,
content textcjk
)
/*('<-')pushdown.ydb*/
八、将HIVE表中的数据导入到YDB中
通过ydbpartion表向YDB中导入数据,下面示例中的ydb_example_shu为YDB表的表名,3000w为YDB表的分区名。
1.直接追加数据
insert into table ydbpartion
select 'ydb_example_shu', '3000w', '',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content
)
from ydb_import_txt;
2.覆盖数据
insert overwrite table ydbpartion
select 'ydb_example_shu', '3000w', '',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content
)
from ydb_import_txt;
3.在追加数据前,先执行按条件删除
insert into table ydbpartion
select 'ydb_example_shu', '3000w', 'ydb_sex='男' and ydb_blood='A'',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content
)
from ydb_import_txt;
4.HIVE表数据导入优化-控制并发数
#######为什么要控制并发数############
1)启动时候的Map数量不容易控制,如果启动的map数量很多,而Spark又没有容量调度器,会占满所有的资源,影响查询。
2)所以很多时候我们的业务期望,在进行数据导入的时候,不要启动太多的Map数量,而是希望留出一部分资源,能让给查询,于是控制Map数量就显得特别重要了。
3)我们导入数据,倾向于数据能更均衡一些,这样查询的时候,不会因为数据倾斜而影响性能。
4)针对大量小文件,Spark并没有像Hive那样使用了combine inputformat ,合并map查询,这样会导致启动的map数量很多,我们希望依然采用Hive那种能够将一些小的Map进行合并。
YDB提供了combine的方法,用来解决上述问题
类名为cn.NET.ycloud.ydb.handle.YdbCombineInputFormat (旧版名字为:cn.Net.ycloud.ydb.handle.Ya100FixNumCombineTextInputFormat)
1)####文本形式的示例####
drop table ydb_import_txt;
CREATE external table ydb_import_txt(
phonenum string, usernick string, ydb_sex string, ydb_province string, ydb_grade string, ydb_age string, ydb_blood string, ydb_zhiye string, ydb_earn string, ydb_prefer string, ydb_consume string, ydb_day string, amtdouble double,amtlong bigint,content string,multyvalue string
)
row format delimited fields terminated by ','
stored as
INPUTFORMAT 'cn.net.ycloud.ydb.handle.YdbCombineInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/data/example/ydb'
TBLPROPERTIES (
'ydb.combine.input.format.raw.format'='org.apache.hadoop.mapred.TextInputFormat'
);
select count(*) from ydb_import_txt limit 10;
insert overwrite table ydbpartion
select 'ydb_example_shu', 'txt', '',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content
)
from ydb_import_txt;
/*ydb.pushdown('->')*/
select count(*) from ydb_example_shu where ydbpartion = 'txt'
/*('<-')pushdown.ydb*/
;
2)####RCFILE格式示例####
drop table ydb_import_rcfile;
CREATE external table ydb_import_rcfile(
phonenum string, usernick string, ydb_sex string, ydb_province string, ydb_grade string, ydb_age string, ydb_blood string, ydb_zhiye string, ydb_earn string, ydb_prefer string, ydb_consume string, ydb_day string, amtdouble double,amtlong bigint,content string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
STORED AS
INPUTFORMAT 'cn.net.ycloud.ydb.handle.YdbCombineInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileOutputFormat'
TBLPROPERTIES (
'ydb.combine.input.format.raw.format'='org.apache.hadoop.hive.ql.io.RCFileInputFormat'
);
insert overwrite table ydb_import_rcfile select * from ydb_import_txt;
select count(*) from ydb_import_rcfile limit 10;
insert overwrite table ydbpartion
select 'ydb_example_shu', 'rcfile', '',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content
)
from ydb_import_rcfile;
/*ydb.pushdown('->')*/
select count(*) from ydb_example_shu where ydbpartion = 'rcfile'
/*('<-')pushdown.ydb*/
;
3)####SEQUENCEFILE格式示例####
drop table ydb_import_sequencefile;
CREATE external table ydb_import_sequencefile(
phonenum string, usernick string, ydb_sex string, ydb_province string, ydb_grade string, ydb_age string, ydb_blood string, ydb_zhiye string, ydb_earn string, ydb_prefer string, ydb_consume string, ydb_day string, amtdouble double,amtlong bigint,content string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
STORED AS
INPUTFORMAT 'cn.net.ycloud.ydb.handle.YdbCombineInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat'
TBLPROPERTIES (
'ydb.combine.input.format.raw.format'='org.apache.hadoop.mapred.SequenceFileInputFormat'
);
SET hive.exec.compress.output=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec;
SET mapred.output.compression.type=BLOCK;
insert overwrite table ydb_import_sequencefile select * from ydb_import_txt;
select count(*) from ydb_import_sequencefile limit 10;
insert overwrite table ydbpartion
select 'ydb_example_shu', 'sequencefile', '',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content
)
from ydb_import_sequencefile;
/*ydb.pushdown('->')*/
select count(*) from ydb_example_shu where ydbpartion = 'sequencefile'
/*('<-')pushdown.ydb*/
4)####PARQUET格式示例####
###Spark内部对SERDE含有Parquet格式的类名进行了特殊处理,会导致设置的inputformat不生效,所以YDB也特殊处理下,就换成不含有Parquet的名字
drop table ydb_import_parquet;
CREATE external table ydb_import_parquet(
phonenum string, usernick string, ydb_sex string, ydb_province string, ydb_grade string, ydb_age string, ydb_blood string, ydb_zhiye string, ydb_earn string, ydb_prefer string, ydb_consume string, ydb_day string, amtdouble double,amtlong bigint,content string
)
ROW FORMAT SERDE 'cn.net.ycloud.ydb.handle.combine.YdbParHiveSerDe'
STORED AS
INPUTFORMAT 'cn.net.ycloud.ydb.handle.YdbCombineInputFormat'
OUTPUTFORMAT 'cn.net.ycloud.ydb.handle.combine.YdbParMapredParquetOutputFormat'
TBLPROPERTIES (
'ydb.combine.input.format.raw.format'='org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
);
set parquet.block.size=16777216;
insert overwrite table ydb_import_parquet select * from ydb_import_txt;
select count(*) from ydb_import_parquet limit 10;
insert overwrite table ydbpartion
select 'ydb_example_shu', 'parquet', '',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content
)
from ydb_import_parquet;
/*ydb.pushdown('->')*/
select count(*) from ydb_example_shu where ydbpartion = 'parquet'
/*('<-')pushdown.ydb*/
九、YDB 查询SQL 写法
注意YDB的表强制必须指定分区
为了区分YDB表与Hive表,YDB语句需要使用
/*ydb.pushdown('->')*/ 与 /*('<-')pushdown.ydb*/ 前后包含起来,以方便解析
1.基本示例
----count(*)计数
/*ydb.pushdown('->')*/
select count(*) from ydb_example_shu where ydbpartion = '2015'
/*('<-')pushdown.ydb*/ ;
----数据预览
/*ydb.pushdown('->')*/
select * from ydb_example_shu where ydbpartion = '3000w' limit 10
/*('<-')pushdown.ydb*/;
----全文检索
/*ydb.pushdown('->')*/
select content,usernick from ydb_example_shu where ydbpartion = '3000w' and content='王老吉' limit 10
/*('<-')pushdown.ydb*/;
----多个条件组合过滤
/*ydb.pushdown('->')*/
select ydb_sex,ydb_grade,ydb_age,ydb_blood,amtlong from ydb_example_shu where ydbpartion = '3000w' and ydb_sex='女' and ydb_grade='本科' and (ydb_age='20到30岁' or ydb_blood='O') and (amtlong like '([3000 TO 4000] )') limit 10
/*('<-')pushdown.ydb*/;
----sum求和
/*ydb.pushdown('->')*/
select sum(amtdouble) from ydb_example_shu where ydbpartion = '3000w'
/*('<-')pushdown.ydb*/;
----avg求平均数
/*ydb.pushdown('->')*/
select avg(amtdouble) as avgamt from ydb_example_shu where ydbpartion = '3000w'
/*('<-')pushdown.ydb*/;
----更复杂点的统计
/*ydb.pushdown('->')*/
select count(*),count(amtdouble),avg(amtdouble),sum(amtdouble),min(amtdouble),max(amtdouble)
,min(ydb_province),max(ydb_province) from ydb_example_shu where ydbpartion = '3000w'
/*(‘<-’)pushdown.ydb*/;
----单列group by
/*ydb.pushdown('->')*/
select ydb_sex,count(*),count(amtdouble),sum(amtdouble) from ydb_example_shu where ydbpartion = '3000w' group by ydb_sex limit 10
/*('<-')pushdown.ydb*/;
----多列group by
/*ydb.pushdown('->')*/
select ydb_sex,ydb_province,count(*) as cnt,count(amtdouble),sum(amtdouble) from ydb_example_shu where ydbpartion = '3000w' group by ydb_sex,ydb_province order by cnt desc limit 10
/*('<-')pushdown.ydb*/;
----top N 排序
/*ydb.pushdown('->')*/
select ydb_sex, phonenum,amtlong,amtdouble
from ydb_example_shu where ydbpartion='3000w' order by amtdouble desc ,amtlong limit 10
/*('<-')pushdown.ydb*/;
2.YDB特有的BlockSort排序(排序大跃进)
按照时间逆序排序可以说是很多日志系统的硬指标。在延云YDB系统中,我们改变了传统的暴力排序方式,通过索引技术,可以超快对数据进行单列排序,不需要全表暴力扫描,这个技术我们称之为BlockSort,目前支持tlong、tdouble、tint、tfloat四种数据类型。
由于BlockSort是借助搜索的索引来实现的,所以采用blockSort的排序,不需要暴力扫描,性能有大幅度的提升。
BlockSort的排序,并非是预计算的方式,可以全表进行排序,也可以基于任意的过滤筛选条件进行过滤排序。
|
| 正常写法 | blockSort写法 |
| 单列升序 | /*ydb.pushdown('->')*/ select tradetime, nickname from blocksort_ydb order by tradetime limit 10 /*('<-')pushdown.ydb*/;
| /*ydb.pushdown('->')*/ select tradetime, nickname from blocksort_ydb where ydbkv='blocksort.field:tradetime' and ydbkv='blocksort.limit:10' order by tradetime limit 10 /*('<-')pushdown.ydb*/; |
| 单列降序 | /*ydb.pushdown('->')*/ select tradetime, nickname from blocksort_ydb order by tradetime desc limit 10 /*('<-')pushdown.ydb*/; | /*ydb.pushdown('->')*/ select tradetime, nickname from blocksort_ydb where ydbkv='blocksort.field:tradetime' and ydbkv='blocksort.limit:10' and ydbkv='blocksort.desc:true' order by tradetime desc limit 10 /*('<-')pushdown.ydb*/; |
3.数据导出
----导出数据到hive表
insert overwrite table ydb_import_importtest
/*ydb.pushdown('->')*/
select phonenum,usernick,ydb_sex,ydb_province,
ydb_grade,ydb_age,ydb_blood,ydb_zhiye,ydb_earn,
ydb_prefer,ydb_consume,ydb_day,amtdouble,amtlong,content
from ydb_example_shu where ydbpartion = '3000w'
/*('<-')pushdown.ydb*/;
#有limit的导出示例 (在Spark的当前版本有BUG,需要采用如下变通方法解决)
insert overwrite table ydb_import_importtest
select * from (
/*ydb.pushdown('->')*/
select
phonenum,usernick,ydb_sex,ydb_province,ydb_grade,ydb_age,ydb_blood,ydb_zhiye,ydb_earn,ydb_prefer,ydb_consume,ydb_day,amtdouble,amtlong,content
from ydb_example_shu where ydbpartion = '3000w' and ydbkv='export.max.return.docset.size:1000'
/*('<-')pushdown.ydb*/
) tmp order by rand() limit 1000;
----数据导出到YDB的其他分区里示例
insert overwrite table ydbpartion
select 'ydb_example_shu', 'test3', '',
YROW(
'phonenum',tmp.phonenum,
'usernick',tmp.usernick,
'ydb_sex',tmp.ydb_sex,
'ydb_province',tmp.ydb_province,
'ydb_grade',tmp.ydb_grade,
'ydb_age',tmp.ydb_age,
'ydb_blood',tmp.ydb_blood,
'ydb_zhiye',tmp.ydb_zhiye,
'ydb_earn',tmp.ydb_earn,
'ydb_prefer',tmp.ydb_prefer,
'ydb_consume',tmp.ydb_consume,
'ydb_day',tmp.ydb_day,
'amtdouble',tmp.amtdouble,
'amtlong',tmp.amtlong,
'content',tmp.content
)
from (
/*ydb.pushdown('->')*/
select
phonenum,usernick,ydb_sex,ydb_province,ydb_grade,ydb_age,ydb_blood,ydb_zhiye,ydb_earn,ydb_prefer,ydb_consume,ydb_day,amtdouble,amtlong,content
from ydb_example_shu where ydbpartion = '3000w'
/*('<-')pushdown.ydb*/
) tmp
;
----导出数据到HDFS
由于Spark当前版本无法通过insert Directory的方式直接导出数据到HDFS,但是可以将数据导出到Hive表,故数据导出到HDFS可以通过导出到Hive表变通的方式来解决
可以通过创建一个导出表来解决
CREATE external table ydb_import_importtest(
phonenum bigint, usernick string, ydb_sex string, ydb_province string, ydb_grade string, ydb_age string, ydb_blood string, ydb_zhiye string, ydb_earn string, ydb_prefer string, ydb_consume string, ydb_day string, amtdouble double,amtlong int,content string
)location '/data/example/ydb_import_importtest';
如果我们创建表的时候,没有加location,我们可以通过show create table xxx表名 可以看到location的位置
4.多表关联示例
1)---两个卡口left semi join
select k1.vehiclePlate as vehiclePlate from (
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='1'
/*('<-')pushdown.ydb*/
) k1
LEFT SEMI JOIN
(
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='2'
/*('<-')pushdown.ydb*/
) k2
on (k1.vehiclePlate=k2.vehiclePlate);
+---------------+--+
| vehiclePlate |
+---------------+--+
| c22 |
| c23 |
| c33 |
| c34 |
+---------------+--+
2)---两个卡口left join
select k1.vehiclePlate as vehiclePlate,k2.vehiclePlate from (
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='1'
/*('<-')pushdown.ydb*/
) k1
LEFT JOIN
(
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='1'
/*('<-')pushdown.ydb*/
) k2
on (k1.vehiclePlate=k2.vehiclePlate);
+---------------+---------------+--+
| vehiclePlate | vehiclePlate |
+---------------+---------------+--+
| c11 | NULL |
| c22 | c22 |
| c23 | c23 |
| c33 | c33 |
| c34 | c34 |
+---------------+---------------+--+
3)---三个卡口left semi join
select k21.vehiclePlate from(
select k1.vehiclePlate as vehiclePlate from (
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='1'
/*('<-')pushdown.ydb*/
) k1
LEFT SEMI JOIN
(
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='2'
/*('<-')pushdown.ydb*/
) k2
on (k1.vehiclePlate=k2.vehiclePlate)
) k21
LEFT SEMI JOIN
(
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='3'
/*('<-')pushdown.ydb*/
) k22 on k21.vehiclePlate=k22.vehiclePlate order by k21.vehiclePlate;
+---------------+--+
| vehiclePlate |
+---------------+--+
| c33 |
| c34 |
+---------------+--+
4)---三个卡口left join
select k21.vehiclePlate,k22.vehiclePlate from(
select k1.vehiclePlate as vehiclePlate from (
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='1'
/*('<-')pushdown.ydb*/
) k1
LEFT JOIN
(
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='2'
/*('<-')pushdown.ydb*/
) k2
on (k1.vehiclePlate=k2.vehiclePlate)
) k21
LEFT JOIN
(
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='3'
/*('<-')pushdown.ydb*/
) k22 on k21.vehiclePlate=k22.vehiclePlate ;
+---------------+---------------+--+
| vehiclePlate | vehiclePlate |
+---------------+---------------+--+
| c11 | NULL |
| c22 | NULL |
| c23 | NULL |
| c33 | c33 |
| c34 | c34 |
+---------------+---------------+--+
5)----三个卡口 先left SEMI join 之后再 left join
select k21.vehiclePlate,k22.vehiclePlate from(
select k1.vehiclePlate as vehiclePlate from (
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='1'
/*('<-')pushdown.ydb*/
) k1
LEFT SEMI JOIN
(
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='2'
/*('<-')pushdown.ydb*/
) k2
on (k1.vehiclePlate=k2.vehiclePlate)
) k21
LEFT JOIN
(
/*ydb.pushdown('->')*/
select vehiclePlate,tollCode from vehiclepass where ydbpartion = '3000w' and tollCode='3'
/*('<-')pushdown.ydb*/
) k22 on k21.vehiclePlate=k22.vehiclePlate ;
+---------------+---------------+--+
| vehiclePlate | vehiclePlate |
+---------------+---------------+--+
| c22 | NULL |
| c23 | NULL |
| c33 | c33 |
| c34 | c34 |
+---------------+---------------+--+
5.UNION示例
1)--union--统计的结果
select sum(cnt) as cnt from
(
/*ydb.pushdown('->')*/
select count(*) as cnt from ydb_example_shu where ydbpartion = '3000w'
/*('<-')pushdown.ydb*/
union all
/*ydb.pushdown('->')*/
select count(*) as cnt from ydb_example_shu where ydbpartion = '300winsert'
/*('<-')pushdown.ydb*/
union all
/*ydb.pushdown('->')*/
select count(*) as cnt from ydb_example_shu where ydbpartion = '300winsert2'
/*('<-')pushdown.ydb*/
union all
/*ydb.pushdown('->')*/
select count(*) as cnt from ydb_example_shu where ydbpartion = '3000w' and content='王老吉'
/*('<-')pushdown.ydb*/
union all
/*ydb.pushdown('->')*/
select count(*) as cnt from ydb_example_shu where ydbpartion = '20151011' and content='工商银行'
/*('<-')pushdown.ydb*/
union all
/*ydb.pushdown('->')*/
select count(*) as cnt from ydb_example_shu where ydbpartion = '20151011'
/*('<-')pushdown.ydb*/
) tmp limit 10;
2)--union order by的结果,注意,这里有个子查询SQL
select * from
(
/*ydb.pushdown('->')*/ s
elect amtlong,content from ydb_example_shu where ydbpartion = '3000w' and content='旺旺' order by amtlong desc limit 1
/*('<-')pushdown.ydb*/
union all
/*ydb.pushdown('->')*/
select amtlong,content from ydb_example_shu where ydbpartion = '3000w' and content='王老吉' order by amtlong desc limit 1
/*('<-')pushdown.ydb*/
union all
/*ydb.pushdown('->')*/
select amtlong,content from ydb_example_shu where ydbpartion = '3000w' and content='汇源' order by amtlong desc limit 1
/*('<-')pushdown.ydb*/
union all
/*ydb.pushdown('->')*/
select amtlong,content from ydb_example_shu where ydbpartion = '3000w' and content='哇哈哈' order by amtlong desc limit 1
/*('<-')pushdown.ydb*/
) tmp limit 1000;
3)YDB表的多个分区一起查询,通过IN来实现
/*ydb.pushdown('->')*/
select count(*),count(amtdouble),sum(amtdouble),avg(amtdouble),min(amtdouble),max(amtdouble),min(ydb_province),max(ydb_province) from ydb_example_shu where ydbpartion in ( '3000w0','3000w1' ,'3000w2','3000w3','3000w4','3000w5','3000w6','3000w7','3000w8','3000w9','3000w10' ,'3000w11','3000w12','3000w13','3000w14','3000w15' ,'3000w16' ,'3000w17','3000w18','3000w19'
,'3000a0','3000a1' ,'3000a2','3000a3','3000a4','3000a5','3000a6','3000a7','3000a8','3000a9','3000a10' ,'3000a11','3000a12','3000a13','3000a14','3000a15' ,'3000a16' ,'3000a17','3000a18','3000a19'
,'3000b0','3000b1' ,'3000b2','3000b3','3000b4','3000b5','3000b6','3000b7','3000b8','3000b9','3000b10' ,'3000b11','3000b12','3000b13','3000b14','3000b15' ,'3000b16' ,'3000b17','3000b18','3000b19'
)
/*('<-')pushdown.ydb*/
;
6.DISTINCT示例
-----#####如果distinct的数据并不多,可以考虑采用collect_set 性能较好#######
1)----####直接count distinct##########
select
size(collect_set(tmp.ydb_sex)) as dist_sex,
size(collect_set(tmp.ydb_province)) as dist_province,
count(*) as cnt,
count(tmp.amtlong) as cnt_long,
count(distinct tmp.amtlong) as dist_long
from (
/*ydb.pushdown('->')*/
select ydb_sex,ydb_province,amtlong from ydb_example_shu where ydbpartion = '3000w' and content='王老吉'
/*('<-')pushdown.ydb*/
) tmp limit 10;
2)----group by 加 count distinct####
select
tmp.ydb_sex as ydb_sex,
size(collect_set(tmp.ydb_province)) as dist_province,
count(*) as cnt,
count(tmp.amtlong) as cnt_long,
count(distinct tmp.amtlong) as dist_long
from
(
/*ydb.pushdown('->')*/
select ydb_sex,ydb_province,amtlong from ydb_example_shu where ydbpartion = '3000w' and content='王老吉'
/*('<-')pushdown.ydb*/
) tmp
group by tmp.ydb_sex limit 10;
7.行转列示例
select ydb_sex,concat_ws('#', sort_array(collect_set(concat_ws(',',ydb_province,cnt,cntamt,sumamt)))) from (
/*ydb.pushdown('->')*/
select ydb_sex,ydb_province,count(*) as cnt,count(amtdouble) as cntamt,sum(amtdouble) as sumamt from ydb_example_shu where ydbpartion = '3000w' group by ydb_sex,ydb_province
/*('<-')pushdown.ydb*/
)tmp group by ydb_sex limit 10;

select ydb_province,sum(cnt) as scnt,concat_ws('#', sort_array(collect_set(concat_ws(',',ydb_sex,cnt,cntamt,sumamt)))) from (
/*ydb.pushdown('->')*/
select ydb_sex,ydb_province,count(*) as cnt,count(amtdouble) as cntamt,sum(amtdouble) as sumamt from ydb_example_shu where ydbpartion = '3000w' group by ydb_sex,ydb_province
/*('<-')pushdown.ydb*/
)tmp group by ydb_province order by scnt desc limit 10;
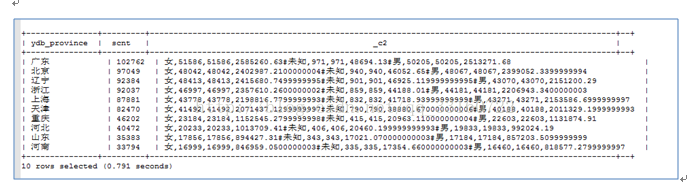
select ydb_province,sum(cnt) as scnt,concat_ws('#', sort_array(collect_set(concat_ws(',',ydb_blood,ydb_sex,cnt,cntamt)))) from (
/*ydb.pushdown('->')*/
select ydb_blood,ydb_sex,ydb_province,count(*) as cnt,count(amtdouble) as cntamt from ydb_example_shu where ydbpartion = '3000w' group by ydb_blood,ydb_sex,ydb_province
/*('<-')pushdown.ydb*/
)tmp group by ydb_province order by scnt desc limit 10;

select ydb_day,sum(cnt) as scnt,concat_ws('#', sort_array(collect_set(concat_ws(',',ydb_blood,ydb_sex,cnt,cntamt)))) from (
/*ydb.pushdown('->')*/
select ydb_day,ydb_sex,ydb_blood,count(*) as cnt,count(amtdouble) as cntamt from ydb_example_shu where ydbpartion = '3000w' group by ydb_day,ydb_sex,ydb_blood
/*('<-')pushdown.ydb*/
)tmp group by ydb_day order by scnt desc limit 10;

8.对于时间的高效处理
我数据里面时间格式是yyyy-MM-dd hh:mm:ss
1)ydb没有时间类型,应该怎么处理?
可以用tlong类型代替时间类型
存储的值 转换成 yyyyMMddhhmmss ,这样是定长的,而且可读性好(比unix时间磋可读性好)
如果时间精度是 秒 ,毫秒,纳秒的 话 一定要使用 tlong (范围查找比long快很多),如果是天,小时的话,可以使用long 节省存储空间
2)这些用于时间操作的转换函数我们一定会用到
cast (from_unixtime(unix_timestamp(substring(recevicetime,0,18),'dd-MMM-yy HH.mm.ss'),'yyyyMMddHHmmss') as bigint),
cast (from_unixtime(unix_timestamp(substring(recevicetime,0,18),'dd-MMM-yy HH.mm.ss'),'yyyyMMddHHmm')as bigint),
cast (from_unixtime(unix_timestamp(substring(recevicetime,0,18),'dd-MMM-yy HH.mm.ss'),'yyyyMMddHH')as bigint) ,
select (2017-cast(substring('201831198307123487',7,4) as bigint) ) from spark_txt limit 10;
9.null值与空值的匹配
1)----匹配空串
/*ydb.pushdown('->')*/
select phonenum,usernick,ydb_sex,ydb_province from ydb_example_shu where ydbpartion = 'nullcheck' and ydb_sex='empty'
/*('<-')pushdown.ydb*/
;
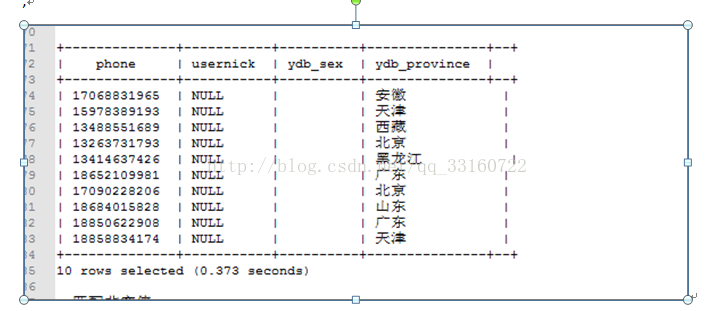
2)--匹配非空值
/*ydb.pushdown('->')*/
select phonenum,usernick,ydb_sex,ydb_province from ydb_example_shu where ydbpartion = 'nullcheck' and ydb_sex<>'empty'
/*('<-')pushdown.ydb*/
;

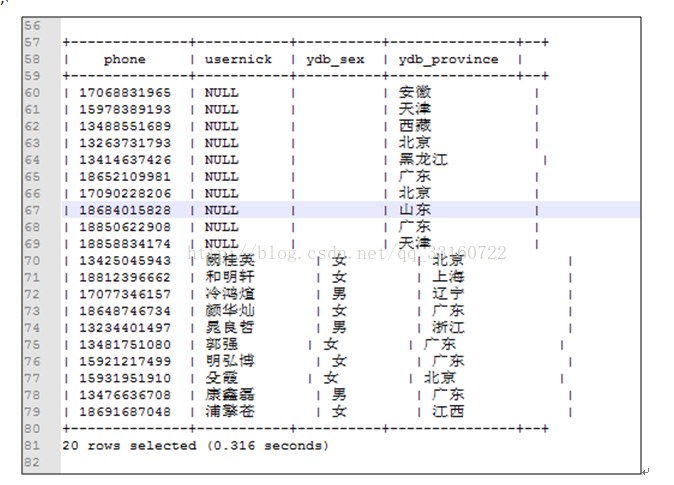
3)--匹配null值
##############null值的匹配非常消耗性能,采用暴力扫描倒排表的方式实现,如果该列的值排重后的值特别多,如sessionId,身份证号码,手机号等,请慎用########
####如果是检索明细数据,建议在hive层进行过滤####
####TODO 未来可以通过标签里面的live bits改进null值匹配的性能####
/*ydb.pushdown('->')*/
select phonenum,usernick,ydb_sex,ydb_province from ydb_example_shu where ydbpartion = 'nullcheck' and ydb_sex='null'
/*('<-')pushdown.ydb*/
;

4)--匹配非null值
/*ydb.pushdown('->')*/
select phonenum,usernick,ydb_sex,ydb_province from ydb_example_shu where ydbpartion = 'nullcheck' and ydb_sex<>'null'
/*('<-')pushdown.ydb*/
;
10.近似文本匹配
1)近似文本匹配
有些时候,我们只想找到一篇跟当前指定文章类似的文章。可能中间相差几个字不一样无所谓,或者局部的字顺序前后颠倒也无所谓。
需要注意
a)单词会进行排重。
b)并不考虑单词顺序(虽然伪造的数据是有顺序的,但是匹配是不考虑顺序的)。
c)30表示排重后,至少有30%的单词会匹配上才算匹配
d)匹配是按照分词的结果后进行匹配的,并不是按照空格进行拆分的,具体如何检验分词,
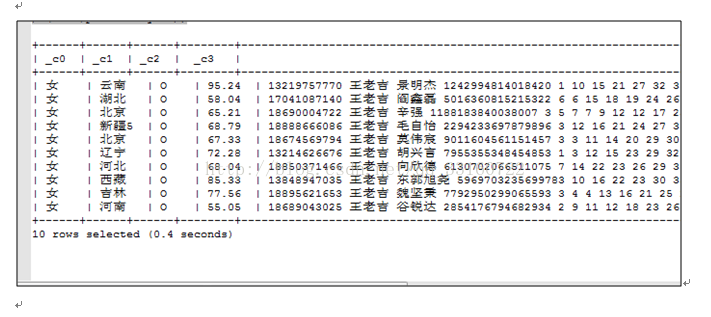
1:近似文本匹配示例
/*ydb.pushdown('->')*/
select content from ydb_example_shu where ydbpartion = '3000w' and content='YTermlike@30@100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 ' limit 10
/*('<-')pushdown.ydb*/;

2)近似特征匹配
有一种搜索是这样的搜索,我指定一系列的特征,如 高矮、胖瘦、年龄段、性别、时间等一系列目击者看到的嫌疑人特征,但是有可能有些目击者描述的不准确,所以不能进行精确匹配,如果能与大部分的匹配条件都相似,一两个条件没匹配上,但已经足以相似了,那么也要返回匹配结果。
--五个特征中必须匹配4个特征
/*ydb.pushdown('->')*/
select ydb_sex,ydb_province,ydb_blood,amtdouble,content from ydb_example_shu where ydbpartion = '3000w' and ydb_raw_query_s like 'YQuerylike@hits=4&fq=ydb_sex:女&fq=ydb_province:辽宁&fq=amtdouble:[14 TO 200]&fq=ydb_blood:O&fq=content:王老吉'
limit 10
/*('<-')pushdown.ydb*/;

==通过wt与score参数将content模糊匹配的权重增大
/*ydb.pushdown('->')*/
select ydb_sex,ydb_province,ydb_blood,amtdouble,content from ydb_example_shu where ydbpartion = '3000w' and ydb_raw_query_s like 'YQuerylike@hits=4&score=8&fq=ydb_sex:女&wt=1&fq=ydb_province:辽宁&wt=1&fq=amtdouble:[14 TO 200]&wt=1&fq=ydb_blood:O&wt=1&fq=content:王老吉&wt=9'
limit 10
/*('<-')pushdown.ydb*/;
11.多值列示例
有些时候,我们想在一个列里面存储多个值的时候,就可以考虑使用多值列了
比如说,可以将一个人 的多个标签值 存储在一个记录里面,一个人的每天的行为数据 放在一个记录里面。
一定要注意,
1.字符串类型的多值列,返回的值的无序,并且是排重的,故这块有额外注意。
2.数值型的则是有序的(与导入的顺序一致),并且是没有排重的。
3.传递的数值是按照空格 拆分的 ,如 11 22 33 44
4.如果传递的是空值,会当做null处理
5.只要数据类型定义为多之列,程序目前会按照空格识别来将传入的数据拆分成多个值分别存储
1)--检索--
/*ydb.pushdown('->')*/
select multyvalue_string,multyvalue_tlong,multyvalue_long,multyvalue_tdouble,multyvalue_double from ydb_example_shu_multyvalue where ydbpartion='3000w'
limit 10
/*('<-')pushdown.ydb*/;

2)--多值列group by
/*ydb.pushdown('->')*/
select multyvalue_long,count(*) as cnt from ydb_example_shu_multyvalue where ydbpartion = '3000w' group by multyvalue_long order by cnt
limit 10
/*('<-')pushdown.ydb*/;
3)普通列与多值列group by
/*ydb.pushdown('->')*/
select multyvalue_long,ydb_sex,count(*) as cnt from ydb_example_shu_multyvalue where ydbpartion = '3000w' group by multyvalue_long,ydb_sex order by cnt
limit 10
/*('<-')pushdown.ydb*/;
4)--两个多值列group by ,(笛卡尔集,要注意内存,以及性能,要慎重)
/*ydb.pushdown('->')*/
select multyvalue_long,multyvalue_string,count(*) from ydb_example_shu_multyvalue where ydbpartion = '3000w' group by multyvalue_long,multyvalue_string order by multyvalue_long,multyvalue_string
limit 10
/*('<-')pushdown.ydb*/;
12.地理位置感知搜索
现在手机APP满天飞,我想大家都用过这个功能:【搜索我附近的饭店或宾馆】之类的功能,类似这样的地理位置搜索功能非常适用,因为它需要利用到用户当前的地理位置数据,是以用户角度出发,找到符合用户自身需求的信息,应用返回的信息对于用户来说满意度会比较高。可见,地理位置空间搜索在提高用户体验方面有至关重要的作用。在Lucene中,地理位置空间搜索是借助Spatial模块来实现的。
要实现地理位置空间搜索,我们首先需要对地理位置数据创建索引,比较容易想到的就是把经度和纬度存入索引,可是这样做,有个弊端,因为地理位置数据(经纬度)是非常精细的,一般两个地点相差就0.0几,这样我们需要构建的索引体积会很大,这会显著减慢你的搜索速度。在精确度上采取折衷的方法通常是将纬度和经度封装到层中。您可以将每个层看作是地图的特定部分的缩放级别,比如位于美国中央上方的第 2 层几乎包含了整个北美,而第 19 层可能只是某户人家的后院。尤其是,每个层都将地图分成 2层的箱子或网格。然后给每个箱子分配一个号码并添加到文档索引中。如果希望使用一个字段,那么可以使用 Geohash编码方式将纬度/经度编码到一个 String 中。Geohash 的好处是能够通过切去散列码末尾的字符来实现任意的精度。在许多情况下,相邻的位置通常有相同的前缀。
1)测试表的创建,注意使用mortonhash的列的类型是geopoint
create table lonlattable_test(
lon tdouble,
lat tdouble,
mortonhash geopoint
)
2)导入数据-注意YMortonHash函数是用于生成Morton数的,将来在索引中用于匹配
insert overwrite table ydbpartion
select 'lonlattable_test', '3000w', '',
YROW(
'lon',r[0],
'lat',r[1],
'mortonhash',YMortonHash(r[0],r[1])
)
from ydb where YSQL('from','select LAT,LON from ydb_oribit where ydbpartion='20160619' ','segment') ;
3)#数据预览,注意YMortonUnHash用于将数据在还原为经纬度,YMortonHashDistance则用来计算距离,单位是m
select tmp.lon,tmp.lat,tmp.mortonhash,YMortonUnHash(tmp.mortonhash),YMortonHashDistance(tmp.mortonhash,8.1,9.2) as distance from
(
/*ydb.pushdown('->')*/
select lon,lat,mortonhash from lonlattable_test where ydbpartion='3000w'
/*('<-')pushdown.ydb*/
)tmp order by distance limit 10 ;

4)地理位置检索,给一个坐标,搜寻最近多少米远的所有记录,注意YGeo@的使用
select tmp.lon,tmp.lat,tmp.mortonhash,YMortonUnHash(tmp.mortonhash),YMortonHashDistance(tmp.mortonhash,8.1,9.2) as distance from
(
/*ydb.pushdown('->')*/
select lon,lat,mortonhash from lonlattable_test where ydbpartion='3000w' and ydb_raw_query_s like 'YGeo@fl=mortonhash&lon=8.1&lat=9.2&radius=10000'
/*('<-')pushdown.ydb*/
)tmp order by distance limit 10 ;

5)####################按照矩形区域搜索isbox=true
select tmp.lon,tmp.lat,tmp.mortonhash,YMortonUnHash(tmp.mortonhash),YMortonHashDistance(tmp.mortonhash,8.1,9.2) as distance from
(
/*ydb.pushdown('->')*/
select lon,lat,mortonhash from lonlattable_test where ydbpartion='3000w' and ydb_raw_query_s like 'YGeo@fl=mortonhash&isbox=true&lon=8.1&lat=9.2&radius=10000'
/*('<-')pushdown.ydb*/
)tmp order by distance limit 10 ;

13.考虑单词顺序的模糊匹配
默认YDB提供了simpletex,haoma等类型进行模糊匹配。
他们本质上是通过分词进行匹配,并不考虑匹配的词的顺序,如果要进行模糊匹配并且又要保证匹配的先后顺序,那么就需要在进行中文分词的时候保存词的位置。
如果保存了顺序,我们可以通过Ylike@方法 按照单词顺序进行匹配查询
如:
phonenum='Ylike@824963'
phonenum='Ylike@188*63*72*76'
phonenum='Ylike@188*2*6*3*6*88'
content='Ylike@可口*可乐*磊'
content='Ylike@14 15 * 24 28 * 37 41 '
目前保存词的位置的数据类型有如下几种:
charlike: 按照字符char 1~5元分词 (效果较好,term区分了词元,适合车牌,手机号类型的较短文本)
wordlike: 按字与词 1~3元分词 (效果较好,term区分了词元,适合文本类型)
pchepai:按照字符char 2~5元分词
phaoma :按照字符char 3~5元分词
psimpletext: 按字与词 1~3元分词
pyy :lucene的cjk分词,中文采用二元分词,英文与数字采用 单字分词
注意:目前的这种Ylike还实现不了前缀与后缀匹配,如果要进行前缀与后缀匹配,建议在导入数据前,加入前缀与后缀的特殊符号
比如说如果ip地址是192.168.3.40,那么我们可以使用charlike类型的字段,并且导入的时候 加上 start192.168.3.40end ,这样前后分别由start与end里两个特殊的字符串
这样进行前缀匹配的时候,可以通过phonenum='Ylike@start192.168' 来匹配,后缀匹配可以通过 phonenum='Ylike@3.40end' 来进行匹配
1.##############号码与车牌类型的示例
/*ydb.pushdown('->')*/
select phonenum from ydb_example_shu_positon where ydbpartion = '3000w' and phonenum='Ylike@824963'
limit 10
/*('<-')pushdown.ydb*/
;
+------------------+--+
| phonenum |
+------------------+--+
| 18882496377 |
| 18824963110 |
| 18824963481 |
| 17082496383 |
| 13824963971 |
| 15928249639 |
| 18824963904 |
| 13238249639 |
+------------------+--+
8 rows selected (0.272 seconds)
2.#######使用*通配符###
/*ydb.pushdown('->')*/
select phonenum from ydb_example_shu_positon where ydbpartion = '3000w' and phonenum='Ylike@824*963'
limit 100
/*('<-')pushdown.ydb*/
;
+------------------+--+
| phonenum |
+------------------+--+
| 13824096330 |
| 13824229634 |
| 18824963481 |
| 18824096302 |
| 17082496383 |
| 18824296372 |
| 18824963110 |
| 18824196307 |
| 13238249639 |
| 13824769963 |
| 18824649639 |
| 18882496377 |
| 13482479635 |
| 13824799638 |
| 13824963971 |
| 18824396346 |
| 15928249639 |
| 18824963904 |
| 18898248963 |
+------------------+--+
19 rows selected (0.26 seconds)
/*ydb.pushdown('->')*/
select phonenum from ydb_example_shu_positon where ydbpartion = '3000w' and phonenum='Ylike@188*63*72*76'
limit 100
/*('<-')pushdown.ydb*/
;
+------------------+--+
| phonenum |
+------------------+--+
| 18863872476 |
| 18863767276 |
| 18836372076 |
| 18863726576 |
+------------------+--+
4 rows selected (0.241 seconds)
3.文本类型顺序匹配检索示例
/*ydb.pushdown('->')*/
select content from ydb_example_shu_positon where ydbpartion = '3000w' and content='Ylike@1 5 14 15 24 28 37 41 49'
limit 100
/*('<-')pushdown.ydb*/
;
4.通过* 允许中间某些词 不连续,但依然保证顺序######
/*ydb.pushdown('->')*/
select content from ydb_example_shu_positon where ydbpartion = '3000w' and content='Ylike@1 5 14 * 24 28 37'
limit 100
/*('<-')pushdown.ydb*/
;
14.管理员命令
--查看YDB表
/*ydb.pushdown('->')*/
show tables
/*('<-')pushdown.ydb*/
;
--查看表的分区
/*ydb.pushdown('->')*/
show partions ydb_example_shu
/*('<-')pushdown.ydb*/
;
--按条件删除
/*ydb.pushdown('->')*/
select count(*) from ydb_example_shu where ydbpartion='3000w' and ydb_sex='男' and ydb_blood='A' and ydbkv='ydb.delete.query:true'
/*('<-')pushdown.ydb*/
;
--整个分区清理,数据清空,但是分区还在
/*ydb.pushdown('->')*/
select count(*) from ydb_example_shu where ydbpartion='3000w' and ydbkv='ydb.truncate:true'
/*('<-')pushdown.ydb*/
;
--物理清理掉整个分区的数据(清理后分区也跟着删掉)
/*ydb.pushdown('->')*/
drop table ydb_example_shu partions 3000a4
/*('<-')pushdown.ydb*/
;
/*ydb.pushdown('->')*/
drop table ydb_example_shu partions 3000a4,3000a5,3000a6
/*('<-')pushdown.ydb*/
;
--删除一个表的所有分区-保留表结构
/*ydb.pushdown('->')*/
truncate table ydb_example_shu
/*('<-')pushdown.ydb*/
;
--删除一个表,表结构也删除掉
/*ydb.pushdown('->')*/
drop table ydb_example_shu
/*('<-')pushdown.ydb*/
;
--暂停kafka的消费3600秒
/*ydb.pushdown('->')*/
select count(*) from y_system_log where ydbkv='ydb.reader.pause:true' and ydbkv='ydb.reader.pause.secs:3600'
/*('<-')pushdown.ydb*/
;
--恢复 暂停的kafka的消费,让kafka继续消费数据
/*ydb.pushdown('->')*/
'select count(*) from y_system_log where ydbkv='ydb.reader.pause:true' and ydbkv='ydb.reader.pause.secs:0'
/*('<-')pushdown.ydb*/
;
--将binlog立即刷到磁盘上
/*ydb.pushdown('->')*/
select count(*) from ydb_example_trade where ydbpartion='k25_005_0' and ydbkv='ydb.force.sync.binlog:true'
/*('<-')pushdown.ydb*/
;
--刷新缓冲区的数据,让其能被搜索到,(binlog会持久化但数据并不会立即持久化到hdfs)
/*ydb.pushdown('->')*/
select count(*) from ydb_example_trade where ydbpartion='k25_005_0' and ydbkv='ydb.force.sync.ram:true'
/*('<-')pushdown.ydb*/
;
--主动触发,将内存中的数据刷盘操作,(数据会被搜索到,并且持久化到磁盘)
/*ydb.pushdown('->')*/
select count(*) from ydb_example_trade where ydbpartion='k25_005_0' and ydbkv='ydb.force.sync:true'
/*('<-')pushdown.ydb*/
;
15.变通方式的分页方案
默认Spark SQL无法进行分页,YDB由于使用了Spark也存在这个问题,故我们采取了变通方式来实现分页。
以每页pagesize大小为10为例
######1024条记录以内####
第一页 直接limit 10,并且将每一行的数据,都按pagekey取个crc32的值 存储在lru的hashmap中
第二页 直接limit 20,并且根据第一页的crc32与当前的20条记录进行移除,有可能剩余12条或更多,但至少剩余10条,然后取出10条返回,并且将crc32缓存在LRU的hashmap中
第三页 直接limit 30,同第二页一样,移除掉与crc32匹配的记录,返回10条并且添加第三页的crc32
这样一直处理到1024条记录 ,如果同时能处理1024个session,我们认为内存是能够放1024*1024个crc32的long类型
######超过1024条记录######
我们采用导出成文件的方式,即insert overwrite table的方式,但是考虑到insert 的方式响应可能会很慢,故我们改写了outputformat,也就是后面大家看到的YdbMoreTextOutputFormat
通过YdbMoreTextOutputFormat我们不需要等待这个insert overwrite执行完毕后才返回,而是在YdbMoreTextOutputFormat中将少量数据发送到缓冲区供立即返回,而大量数据写入到磁盘。
在这种方式下,由于需要与先前生成的crc32值进行排重,目前的实现没有精确控制返回的数据条数,而是返回介于pagesize到pagesize*2的记录数,
----这个分页的使用限制大家注意--
1.不能跳页,只能一页一页的向下翻。
2.只能向后翻页,不能向前翻页。
3.每页返回的行数是一个近似值,介于pagesize到pagesize*2的记录数。
4.SQL本身就不在需要写limit了
4.sql中的 as pagekey与pagevalue 不能省略,本质是KV返回
如果数据表的规模很大,建议配置如下参数控制每个segments导出的记录条数,以免占用太多的HDFS空间
and ydbkv="export.max.return.docset.size:1000" and ydbkv="max.return.docset.size:1000"
###使用方法##
---先创建如下的表
drop table ydb_page_session;
CREATE external table ydb_page_session(
pagekey string,
pagevalue string
)
partitioned by (ydbsession string)
stored as INPUTFORMAT 'cn.net.ycloud.ydb.handle.Ya100FixNumCombineTextInputFormat' OUTPUTFORMAT 'cn.net.ycloud.ydb.handle.more.YdbMoreTextOutputFormat'
location '/data/ycloud/ydb/rawdata/ydb_page_session';
drop table ydb_more_session;
CREATE external table ydb_more_session(
line string
)
partitioned by (ydbsession string)
stored as INPUTFORMAT 'cn.net.ycloud.ydb.handle.Ya100FixNumCombineTextInputFormat' OUTPUTFORMAT 'cn.net.ycloud.ydb.handle.more.YdbMoreTextOutputFormat'
location '/data/ycloud/ydb/rawdata/ydb_more_session';
---通过如下接口查询数据----
注意生成的pagekey不能省略,用于排重,如果是查询明细可以用y_uuid_s的内置列填充。
http://ydbmaster:1210/ydbpage?reqid=002_page&pagesize=100&sql=select r[0] as pagekey,concat_ws(',',r) as pagevalue from ydb where YSQL('from','select y_uuid_s,phonenum,usernick,content from ydb_example_shu where ydbpartion="3000w" and content="王老吉" and ydbkv="export.max.return.docset.size:1000" and ydbkv="max.return.docset.size:1000" ','segment')
http://ydbmaster:1210/ydbpage?reqid=00d3_page&pagesize=100&sql=select r[0] as pagekey,concat_ws(',',r) as pagevalue from ydb where YSQL('from','select y_uuid_s,phonenum,usernick from ydb_example_shu where ydbpartion="3000w" and ydbkv="export.max.return.docset.size:1000" and ydbkv="max.return.docset.size:1000" ','segment')
http://ydbmaster:1210/ydbpage?reqid=0234_page&pagesize=100&sql=select concat_ws(',',r[0],r[1],r[2]) as pagekey,concat_ws(',',r) as pagevalue from ydb where YSQL('from','select amtdouble,amtlong,y_uuid_s,content,usernick,ydb_sex from ydb_example_shu where ydbpartion="3000w" and ydbkv="export.max.return.docset.size:1000" and ydbkv="max.return.docset.size:1000" ','segment')
16.分词
分词( Word Segmentation) 指的是将一个词字序列切分成一个一个单独的词。分词就是将连续的词序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。
默认YDB提供了如下几种分词
simpletext ydb内置的普通文本分词 采用1~3元分词
haoma ydb内置的适合号码类型的分词,采用3~5元分词实现,分词粒度为char
chepai ydb内置的适合号码类型的分词,采用2~5元分词实现,分词粒度为char
text 为lucene默认的standard分词,在(处理手机号,邮箱,IP地址,网址等中英文与字典组合的数据上 不准确,请慎用)
cjkyy 为lucene默认的cjk分词即二元分词 (处理手机号,邮箱,IP地址,网址等中英文与字典组合的数据上 不准确,请慎用)
ikyy与textik 为开源的ik分词的实现,采用词库分词,词库我们可以再lib下找到
以下类型除了分词外,还保存了分词后的词的顺序,可以进行顺序匹配 更多请参考《27.考虑单词顺序的模糊匹配》
charlike: 按照字符char 1~5元分词 (效果较好,term区分了词元,适合车牌,手机号类型的较短文本)
wordlike: 按字与词 1~3元分词 (效果较好,term区分了词元,适合文本类型)
pchepai:按照字符char 2~5元分词
phaoma :按照字符char 3~5元分词
psimpletext: 按字与词 1~3元分词
pyy :lucene的cjk分词,中文采用二元分词,英文与数字采用 单字分词
--我们可以通过如下SQL 了解不同分词的差异
select
YAnalyzer('charlike','query','中华人民123456') as charlikequery,
YAnalyzer('charlike','index','中华人民123456') as charlikeindex
from (
/*ydb.pushdown('->')*/
select content from ydb_example_shu_multyvalue where ydbpartion='3000w'
/*('<-')pushdown.ydb*/
) tmp
limit 1;

select
YAnalyzer('wordlike','query','中华人民123456') as wordlikequery,
YAnalyzer('wordlike','index','中华人民123456') as wordlikeindex
from
(
/*ydb.pushdown('->')*/
select content from ydb_example_shu_multyvalue where ydbpartion='3000w'
/*('<-')pushdown.ydb*/
) tmp
limit 1;
+-------------------------+---------------------------------------------------------------------------+--+
| wordlikequery | wordlikeindex |
+-------------------------+---------------------------------------------------------------------------+--+
| 3@中华人 3@华人民 3@人民123456 | 1@中 1@华 1@人 1@民 1@123456 2@中华 2@华人 2@人民 2@民123456 3@中华人 3@华人民 3@人民123456 |
+-------------------------+---------------------------------------------------------------------------+--+
1 row selected (0.889 seconds)
select
YAnalyzer('phaoma','query','中华人民123456') as phaomaquery,
YAnalyzer('phaoma','index','中华人民123456') as phaomaindex
from
(
/*ydb.pushdown('->')*/
select content from ydb_example_shu_multyvalue where ydbpartion='3000w'
/*('<-')pushdown.ydb*/
) tmp
limit 1;
+--------------------------------------+---------------------------------------------------------------------------------------------------------+--+
| phaomaquery | phaomaindex |
+--------------------------------------+---------------------------------------------------------------------------------------------------------+--+
| 中华人民1 华人民12 人民123 民1234 12345 23456 | 中华人 华人民 人民1 民12 123 234 345 456 中华人民 华人民1 人民12 民123 1234 2345 3456 中华人民1 华人民12 人民123 民1234 12345 23456 |
+--------------------------------------+---------------------------------------------------------------------------------------------------------+--+
select
YAnalyzer('psimpletext','query','中华人民123456') as psimpletextquery,
YAnalyzer('psimpletext','index','中华人民123456') as psimpletextindex
from
(
/*ydb.pushdown('->')*/
select content from ydb_example_shu_multyvalue where ydbpartion='3000w'
/*('<-')pushdown.ydb*/
) tmp
limit 1;
+-------------------+---------------------------------------------------+--+
| psimpletextquery | psimpletextindex |
+-------------------+---------------------------------------------------+--+
| 中华人 华人民 人民123456 | 中 华 人 民 123456 中华 华人 人民 民123456 中华人 华人民 人民123456 |
+-------------------+---------------------------------------------------+--+
ik词库分词
词库文件位于 ya100/lib/IK_ext.dic
17.with as 写法简化SQL
如果我们的SQL,嵌套层级太深,可以考虑通过with as 方法,将子SQL抽取出来,让整体的SQL看起来逻辑更清晰,大家阅读SQL的时候也便于理解。
with as 遵循HIVE语法,下面为写法示例
Hive 可以用with as将某个查询命名为一个临时的表名,其他语句可以随时使用该临时表名进行查询。
with q1 as (select * from src where key= ‘5’),
q2 as (select * from src s2 where key = ‘4’)
select * from q1 union all select * from q2;
一个简单的例子
with
y_customer as (
/*ydb.pushdown('->')*/
select c_custkey from customer_ydb where c_mktsegment = 'BUILDING'
/*('<-')pushdown.ydb*/
),
y_lineitem as (
/*ydb.pushdown('->')*/
select l_orderkey,l_extendedprice,l_discount from lineitem_ydb where l_shipdate > '1995-03-15'
/*('<-')pushdown.ydb*/
)
,
y_orders as (
/*ydb.pushdown('->')*/
select o_orderdate, o_shippriority,o_orderkey,o_custkey from orders_ydb where o_orderdate < '1995-03-15'
/*('<-')pushdown.ydb*/
)
select
l_orderkey, sum(l_extendedprice*(1-l_discount)) as revenue, o_orderdate, o_shippriority
from
y_customer c join y_orders o
on c.c_custkey = o.o_custkey
join y_lineitem l
on l.l_orderkey = o.o_orderkey
where
o_orderdate < '1995-03-15'
group by l_orderkey, o_orderdate, o_shippriority
order by revenue desc, o_orderdate ,l_orderkey, o_shippriority
limit 10;
一个稍微复杂点的例子
with
y_nation as (
/*ydb.pushdown('->')*/
select n_name,n_regionkey,n_nationkey from nation_ydb
/*('<-')pushdown.ydb*/
),
y_region as (
/*ydb.pushdown('->')*/
select r_regionkey,r_name from region_ydb where r_name = 'EUROPE'
/*('<-')pushdown.ydb*/
),
y_supplier as (
/*ydb.pushdown('->')*/
select s_acctbal, s_name,s_address,s_phone, s_comment ,s_nationkey,s_suppkey
from supplier_ydb
/*('<-')pushdown.ydb*/
),
y_partsupp as (
/*ydb.pushdown('->')*/
select ps_supplycost,ps_suppkey,ps_partkey
from partsupp_ydb
/*('<-')pushdown.ydb*/
),
y_part as (
/*ydb.pushdown('->')*/
select p_partkey,p_mfgr,p_size,p_type
from part_ydb where p_size = 15 and p_type like '%BRASS'
/*('<-')pushdown.ydb*/
),
q2_minimum_cost_supplier_tmp1 as (select
s.s_acctbal, s.s_name, n.n_name, p.p_partkey, ps.ps_supplycost, p.p_mfgr, s.s_address, s.s_phone, s.s_comment
from
y_nation n join y_region r
on
n.n_regionkey = r.r_regionkey
join y_supplier s
on
s.s_nationkey = n.n_nationkey
join y_partsupp ps
on
s.s_suppkey = ps.ps_suppkey
join y_part p
on
p.p_partkey = ps.ps_partkey ),
q2_minimum_cost_supplier_tmp2 as (
select
p_partkey, min(ps_supplycost) as ps_min_supplycost
from
q2_minimum_cost_supplier_tmp1
group by p_partkey
)
select
t1.s_acctbal, t1.s_name, t1.n_name, t1.p_partkey, t1.p_mfgr, t1.s_address, t1.s_phone, t1.s_comment
from
q2_minimum_cost_supplier_tmp1 t1 join q2_minimum_cost_supplier_tmp2 t2
on
t1.p_partkey = t2.p_partkey and t1.ps_supplycost=t2.ps_min_supplycost
order by s_acctbal desc, n_name, s_name, p_partkey,p_mfgr,s_address,s_phone,s_comment
limit 100;
十、通过Kafka实时导入数据
默认的Kafka导入数据只支持Json格式,如果需要支持其他格式,需要自己通过Java写Parser.。
1.Kafka配置的注意点
第一:注意Kafka server 的num.partitions一定要大于YDB启动的进程*线程数量,否则有的进程消费不到数据
如果发现之前配置错了,要清空下ZK相关路径(现在好像有API接口了),否则修改完了也不生效
Kafka的启动很简单 ./kafka-server-start.sh ../config/server.properties
第二:请参考第四章的Kafka配置注意事项,这里不再重复介绍
2.YDB中配置Kafka的消费
在ydb_site.yaml中添加如下的配置,并更改相关连接参数
ydb.reader.list: "default,filesplit,kafka_json"
#如果您要使用其他的消息中间件,可以自定义Reader,默认为Kafka的实现
ydb.reader.read.class.kafka_json: "cn.net.ycloud.ydb.server.reader.kafka.KafkaDataReader"
#如果您的数据格式是非标准的JSON格式,可以自定义Parser,默认为按照Json方式解析
ydb.reader.parser.class.kafka_json: "cn.net.ycloud.ydb.server.reader.JsonParser"
kafka.topic.kafka_json: "kafkaydb"
kafka.group.kafka_json: "kafkaydb_group"
bootstrap.servers.kafka_json: "192.168.3.2:6667"
3.重启YDB后,10分钟后会开始导入数据
4.Kafka导入的数据格式如下
1)一次只导入一条
{"tablename":"ydbexample","ydbpartion":"20151005","data":{"indexnum":4,"label":"l_4","userage":14,"clickcount":4,"paymoney":4.132,"price":4.12,"content":"4 4 4 延云 ydb 延云 测试 中文分词 中华人民共和国 沈阳延云云计算技术有限公司","contentcjk":"4 4 4 延云 ydb 延云 测试 中文分词 中华人民共和国 沈阳延云云计算技术有限公司"}}
2)一次导入多条(通过减少数据条数,提升Kafka性能)
{"tablename":"ydb_example_trade","ydbpartion":"20151018","list":[{"tradeid":"2016030811044018","nickname":"凌浦泽","province":"澳门特别行政区","tradetype"
...... ",\"amt\":8321,\"bank\":\"交通银行\"}"}]}
5.Kafka模式实时导入数据,为什么会有重复数据
YDB能确保从Kafka消费到的数据0丢失,但是由于Kafka的实现机制,以下情况会导致出现重复数据
具体原理可以参考这篇文章
http://www.iteblog.com/pdf/1716
进程异常退出(主动kill或者进程BUG等原因导致)
Kafka采用commitoffset的方式提交数据,由于此时会存在数据已经消费,但是Kafka的offset没有来得及提交,这样会导致数据重复。
Kafka的Rebalancing
由于进程退出,或者首次启动时,会产生一个新的consumer加入一个consumer group时,会有一个rebalance的操作,导致每一个consumer和partition的关系重新分配。也就会发生了rebalancing 。
如果一个消息已经被消费了,但是还没有提交offset,就开始了Rebalancing,这个时候会造成数据的重复。这个在Kafka里已经积累了一部分数据后的首次启动时最为明显。
如果仅仅发生了一个进程异常退出,但是没有导致Rebalancing,那么最多重复的数据条数就是这个进程还没有来得及提交的部分。
如果发生了Rebalancing(进程异常退出也会导致Rebalancing),那么则要按全部没有来得及提交的线程数来计算。
6.Kafka模式对数据可靠性的几种配置
ydb.realtime.kafka.commit.intervel用来控制Kafka的offset commit频率,每次commit也会导致binglog(wal)同步,所以该值一般要小于等于ydb.realtime.binlog.sync.intervel的频率
尽量减少进程重启 导致的数据重复的配置(每个线程32条重复数据)
ydb.realtime.kafka.commit.intervel: 32
ydb.realtime.binlog.sync.intervel: 1024
尽量增加吞吐量的配置, 可能有重复(每个线程1024条重复数据)
ydb.realtime.kafka.commit.intervel: 1024
ydb.realtime.binlog.sync.intervel: 2048
7.多个Kafka Topic一起消费
ydb.reader.list: "default,filesplit,kafka_json,kafka_json2,kafka_json3"
##kafka_json##
ydb.reader.read.class.kafka_json: "cn.net.ycloud.ydb.server.reader.kafka.KafkaDataReader"
ydb.reader.parser.class.kafka_json: "cn.net.ycloud.ydb.server.reader.JsonParser"
kafka.topic.kafka_json: "a961"
kafka.group.kafka_json: "bn961n_groupv1_kafka_json"
bootstrap.servers.kafka_json: "192.168.3.2:6667"
##kafka_json2##
ydb.reader.read.class.kafka_json2: "cn.net.ycloud.ydb.server.reader.kafka.KafkaDataReader"
ydb.reader.parser.class.kafka_json2: "cn.net.ycloud.ydb.server.reader.JsonParser"
kafka.topic.kafka_json2: "b961"
kafka.group.kafka_json2: "bn961n_groupv1_kafka_json2"
bootstrap.servers.kafka_json2: "192.168.3.2:6667"
##kafka_json3##
ydb.reader.read.class.kafka_json3: "cn.net.ycloud.ydb.server.reader.kafka.KafkaDataReader"
ydb.reader.parser.class.kafka_json3: "cn.net.ycloud.ydb.server.reader.JsonParser"
kafka.topic.kafka_json3: "c961"
kafka.group.kafka_json3: "bn961n_groupv1_kafka_json3"
bootstrap.servers.kafka_json3: "192.168.3.2:6667"
十一、通过mdrill提升简单查询的查询速度
默认配置所有的SQL查询均是通过spark SQL进行相应,但是由于SPARK本身的框架很重,每次任务调度都会有200~300毫秒的调度时间,对于简单查询来说,我们可以将简单查询的SQL通过轻量级的mdrill接口进行访问,而不通过SPARK SQL进行调度,从而在调度上节省时间。
默认简单SQL通过mdrill来执行这个功能是关闭的,大家可以通过下述方式,将一个简单SQL转换为mdrill查询。
1.通过统一配置
可以在ydb_site.yaml里配置 ydb.sql.ismdrill.first的值为true,让ydb系统自动选择是使用mdrill来进行查询还是使用spark调度来执行SQL。
通过该配置,数据明细查询、排序,以及不含有group by的统计会通过mdrill查询。
group by由于mdrill的一万个group 的限制,该方式不会启用。
2.通过ydb_force_to_mdrill_mark让SQL以mdrill的方式显示执行
如果ydb.sql.ismdrill.first为false,不会使用mdrill的调度,但如果我们在SQL加上该标记,就会强制该SQL采用mdrill的调度,而不是采用spark的调度。
示例如下:
/*ydb.pushdown('->')*/
select ydb_sex, count(*) as cbt from ydb_example_shu where ydbpartion='20150811' and ydbkv='mdrill.force:ydb_force_to_mdrill_mark' group by ydb_sex limit 10
/*('<-')pushdown.ydb*/
3.通过ydb_force_to_spark_mark让SQL以spark的方式执行
/*ydb.pushdown('->')*/
select ydb_sex, count(*) as cbt from ydb_example_shu where ydbpartion='20150811' and ydbkv='mdrill.force:ydb_force_to_spark_mark' group by ydb_sex limit 10
/*('<-')pushdown.ydb*/















 4203
4203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









