






H264码流结构分析
http://blog.csdn.net/chenchong_219/article/details/37990541
1、码流总体结构:
h264的功能分为两层,视频编码层(VCL)和网络提取层(NAL)。H.264 的编码视频序列包括一系列的NAL 单元,每个NAL 单元包含一个RBSP。一个原始的H.264 NALU 单元常由 [StartCode] [NALU Header] [NALU Payload] 三部分组成,其中 Start Code 用于标示这是一个NALU 单元的开始,必须是"00 00 00 01" 或"00 00 01"。

其中RBPS有分为几种类型:
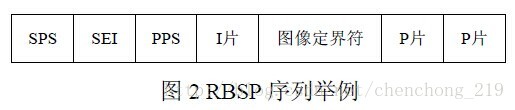
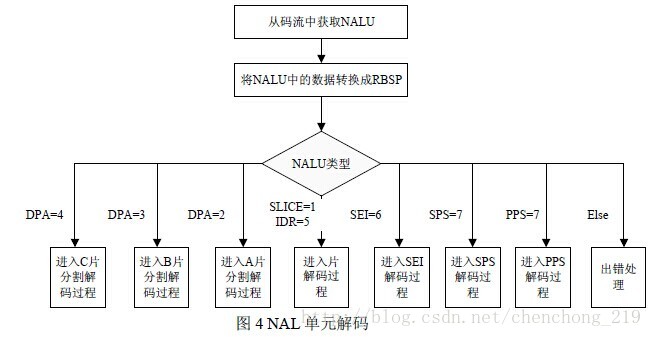
NAL的解码单元的流程如下:
2、 NAL Header:
占一个字节,由三部分组成forbidden_bit(1bit),nal_reference_bit(2bits)(优先级),nal_unit_type(5bits)(类型)。
forbidden_bit:禁止位。
nal_reference_bit:当前NAL的优先级,值越大,该NAL越重要。
nal_unit_type :NAL类型。参见下表
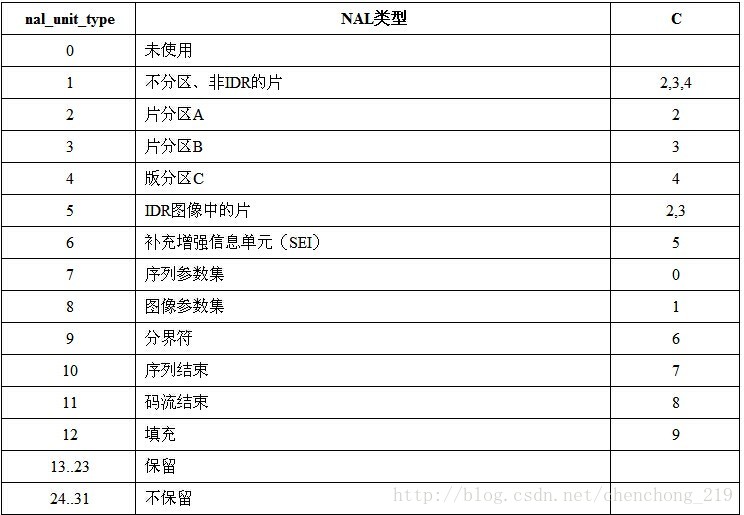
几个例子:

3、 ffmpeg解析H264流程分析
这是一段实际的码流

在上面的图片中,共有三个起始码:0x00 0000 01
const uint8_t*ff_h264_decode_nal(H264Context*h, const uint8_t *src,int *dst_length, int*consumed, int length)中分析过程为:
h->nal_ref_idc= src[0] >> 5;
h->nal_unit_type= src[0] & 0x1F;
此处src[0]即为06,写成二进制位0000 0110,则h->nal_ref_idc = 0,h->nal_unit_type = 6
可以判断这个NALU类型为SEI,重要性优先级为0。
src++;src向后移动一个位置,此时src指向图中第一行第五列的数据05
length--;未处理数据长度减1
#defineSTARTCODE_TEST \
if(i + 2 < length && src[i + 1] == 0 && src[i + 2]<= 3){ \
if(src[i + 2] != 3){ \
/* startcode, so we must bepast the end*/ \
length =i; \
} \
break; \
}
for(i = 0; i + 1 < length; i += 2) {
if(src[i])
continue;
if(i > 0 && src[i - 1] == 0)
i--;
STARTCODE_TEST;
}
上述分析:
1)如果src[i] !=0 ,则继续下一次循环,直到src[i] == 0,即等于下一个起始码的第二个00为止,即图中地址为000001a0h行的第3列,地址为0x00 00 01 a3(十进制为419),此时i为414,因为是从0x00 00 00 05地址开始的,此时则第一次执行continue下面的if语句,而且src[i-1]==0,则i--,此时i=413
2)执行宏定义STARTCODE_TEST,进行起始码检测:src[i+ 1] =src[414]=0,src[i+2]=src[415]=0;
继续执行,src[i+2] != 3,这里是进行竞争检测(前面有讲述,如果在编码的过程中出现连续00 00 00时,将会在第三个00前插入一个03,避免和起始码造成冲突),既然没有发生竞争现象,则表明这个确实是下一个NALU的起始码
3)length是指当前NALU单元长度,这里不包括nalu头信息长度,即一个字节,
length = i =413
后面的SEI解析不再赘述
(2)第二个 0x00 00 00 01:
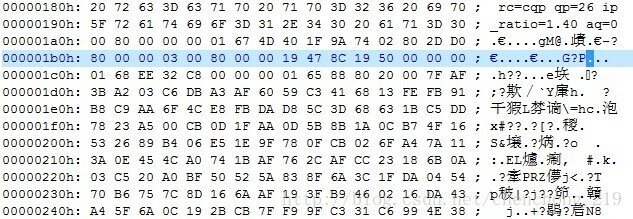
h->nal_ref_idc= src[0] >> 5;
h->nal_unit_type= src[0] & 0x1F;
此时src[0]是指起始码后面第一个数据67(地址为0x00 00 01a6h),写成二进制为0110 0111,则h->nal_unit_type = 7,h->nal_ref_idc =3
则这一个NALU单元类型为SPS
下面开始分析SPS的长度,这一段数据很巧,包含了竞争检测
依然是下面这段代码:
src++;src向后移动一个位置,此时src指向图中地址为00 0001 a7h的数据
length--;未处理数据长度减1
#defineSTARTCODE_TEST \
if(i + 2 < length && src[i + 1] == 0 && src[i + 2]<= 3){ \
if(src[i + 2] != 3){ \
/* startcode, so we must bepast the end*/ \
length =i; \
} \
break; \
}
for(i = 0; i + 1 < length; i += 2) {
if(src[i])
continue;
if(i > 0 && src[i - 1] == 0)
i--;
STARTCODE_TEST;
}
分析:
1)自地址0x00 00 01 a7h开始查找src[i] ==0,此时src[i]的地址为0x00 00 01 b1h,此时src[i]==0,而src[i-1]=80 != 0,此时i = 10 ;
2)执行宏定义STARTCODE_TEST:if(i+2 <lengthn&&src[i+1]==0&&src[i+2]<=3)其中src[i+1]=src[11]=0,且src[i+2]=src[12]=3,继续执行,if(src[i+2] !=3),显然不满足,执行break,跳出循环,此时 i=10
此时尚不能确定下一个nalu单元的起始码在何处,因此当前nalu单元的长度也是未定的,
bufidx =h->nal_unit_type == NAL_DPC ? 1: 0;bufidx=0
si =h->rbsp_buffer_size[bufidx];
av_fast_padded_malloc(&h->rbsp_buffer[bufidx],&h->rbsp_buffer_size[bufidx],length+MAX_MBPAIR_SIZE);
dst =h->rbsp_buffer[bufidx];
以上是为当前NALU分配缓存,并清零
memcpy(dst,src, i);将当前确定的nalu内容拷贝到dst缓存中
si = di = i;目的缓存长度和源缓存长度=i=10
while (si + 2< length) {
//remove escapes (very rare 1:2^22)
if(src[si + 2] > 3) {
dst[di++]= src[si++];
dst[di++]= src[si++];
}else if (src[si] == 0 && src[si + 1] == 0) {
if(src[si + 2] == 3) { // escape
dst[di++] = 0;
dst[di++] = 0;
si += 3;
continue;
}else // next start code
goto nsc;
}
dst[di++]= src[si++];
}
nsc:
memset(dst+ di, 0, FF_INPUT_BUFFER_PADDING_SIZE);
*dst_length= di;
*consumed = si + 1; // +1 forthe header
/*FIXME store exact number of bits in the getbitcontext
*(it is needed for decoding) */
returndst;
分析:src[0]=4D位于0x00 00 01a7h,src[10]=0位于0x00 00 01b1h后面的地址不再赘述,依次为起始位置
从图中可以看出:
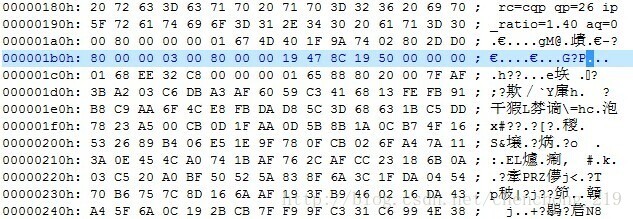
src[10]=00,src[11]=00,src[12]=03,src[13]=00,src[14]=80,src[15]=00,src[16]=00,src[17]=19,src[18]=47,src[19]=8C,src[20]=19,src[21]=50,src[22]=00,src[23]=00,src[24]=00
1)进入while循环,
此时si=10:
src[si+2] =src[12]=03且src[11]=00,src[10]=00,则执行:
dst[di++]=0:即dst[10]=0,di=11,dst[11]=0,di=12;
si+=3:si=13,然后continue,开始下一次循环
注:此处的03即为竞争检测,最后将03跳过了
此时si=13:
src[15]=00,src[13]=00,src[14]=80,则执行
dst[di++]=src[si++];
即:dst[12]=src[13]=00,di=13,si=14;
此时si=14:
src[16]=00,src[15]=00,src[14]=80
则执行dst[di++]=src[si++];
即:dst[13]=src[14]=00,di=14,si=15
此时si=15:
src[15]=00,src[16]=00,src[17]=19
则执行:dst[di++] = src[si++];
dst[di++]= src[si++];
dst[di++]= src[si++]
即:dst[14]=src[15]=00,di=15,si=16;
dst[15]=src[16]=00,di=16,si=17;
dst[16]=src[17]=19,di=17,si=18;
此时si=18:
src[18]=47,src[19]=8C,src[20]=19
执行:
dst[di++] = src[si++];
dst[di++]= src[si++];
dst[di++] =src[si++]
即:dst[17]=src[18]=47,di=18,si=19
dst[18]=src[19]=8C,di=19,si=20
dst[19]=src[20]=19,di=20,si=21
此时si=21:
src[21]=50,src[22]=00,src[23]=00
执行:
dst[di++]= src[si++];
即dst[20]=src[21]=50,di=21,si=22
此时si=22:
src[22]=00,src[23]=00,src[24]=00
执行:
goto nsc;
那就看一下nsc:
nsc:
memset(dst+ di, 0, FF_INPUT_BUFFER_PADDING_SIZE);
*dst_length= di;
*consumed = si + 1; // +1 forthe header
/*FIXME store exact number of bits in the getbitcontext
*(it is needed for decoding) */
returndst;
此时di=21,si=22
memset()函数是向SPS单元尾部补零
dst_length=di=21,;即SPS单元的RBSP长度为21,不包括起始码
consumed=si+1=23;表示SPS单元共消耗的字节数,加1表示SPS单元信息头占一个字节,注意consumed比dst_length大1,这是由于竞争检测时,将编码时添加的一个字节的03过滤掉造成的。
H264编码原理以及I帧、B和P帧详解
H264是新一代的编码标准,以高压缩高质量和支持多种网络的流媒体传输著称,在编码方面,我理解的他的理论依据是:参照一段时间内图像的统计结果表明,在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,而色度差值的变化只有1%以内。所以对于一段变化不大图像画面,我们可以先编码出一个完整的图像帧A,随后的B帧就不编码全部图像,只写入与A帧的差别,这样B帧的大小就只有完整帧的1/10或更小!B帧之后的C帧如果变化不大,我们可以继续以参考B的方式编码C帧,这样循环下去。这段图像我们称为一个序列(序列就是有相同特点的一段数据),当某个图像与之前的图像变化很大,无法参考前面的帧来生成,那我们就结束上一个序列,开始下一段序列,也就是对这个图像生成一个完整帧A1,随后的图像就参考A1生成,只写入与A1的差别内容。
在H264协议里定义了三种帧,完整编码的帧叫I帧,参考之前的I帧生成的只包含差异部分编码的帧叫P帧,还有一种参考前后的帧编码的帧叫B帧。
H264采用的核心算法是帧内压缩和帧间压缩,帧内压缩是生成I帧的算法,帧间压缩是生成B帧和P帧的算法。
序列的说明
在H264中图像以序列为单位进行组织,一个序列是一段图像编码后的数据流,以I帧开始,到下一个I帧结束。
一个序列的第一个图像叫做 IDR 图像(立即刷新图像),IDR 图像都是 I 帧图像。H.264 引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
一个序列就是一段内容差异不太大的图像编码后生成的一串数据流。当运动变化比较少时,一个序列可以很长,因为运动变化少就代表图像画面的内容变动很小,所以就可以编一个I帧,然后一直P帧、B帧了。当运动变化多时,可能一个序列就比较短了,比如就包含一个I帧和3、4个P帧。
三种帧的说明
1、I帧
I帧:帧内编码帧 ,I帧表示关键帧,你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)
I帧特点:
1)它是一个全帧压缩编码帧。它将全帧图像信息进行JPEG压缩编码及传输;
2)解码时仅用I帧的数据就可重构完整图像;
3)I帧描述了图像背景和运动主体的详情;
4)I帧不需要参考其他画面而生成;
5)I帧是P帧和B帧的参考帧(其质量直接影响到同组中以后各帧的质量);
6)I帧是帧组GOP的基础帧(第一帧),在一组中只有一个I帧;
7)I帧不需要考虑运动矢量;
8)I帧所占数据的信息量比较大。
2、P帧
P帧:前向预测编码帧。P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。(也就是差别帧,P帧没有完整画面数据,只有与前一帧的画面差别的数据)
P帧的预测与重构:P帧是以I帧为参考帧,在I帧中找出P帧“某点”的预测值和运动矢量,取预测差值和运动矢量一起传送。在接收端根据运动矢量从I帧中找出P帧“某点”的预测值并与差值相加以得到P帧“某点”样值,从而可得到完整的P帧。
P帧特点:
1)P帧是I帧后面相隔1~2帧的编码帧;
2)P帧采用运动补偿的方法传送它与前面的I或P帧的差值及运动矢量(预测误差);
3)解码时必须将I帧中的预测值与预测误差求和后才能重构完整的P帧图像;
4)P帧属于前向预测的帧间编码。它只参考前面最靠近它的I帧或P帧;
5)P帧可以是其后面P帧的参考帧,也可以是其前后的B帧的参考帧;
6)由于P帧是参考帧,它可能造成解码错误的扩散;
7)由于是差值传送,P帧的压缩比较高。
3、B帧
B帧:双向预测内插编码帧。B帧是双向差别帧,也就是B帧记录的是本帧与前后帧的差别(具体比较复杂,有4种情况,但我这样说简单些),换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累。
B帧的预测与重构
B帧以前面的I或P帧和后面的P帧为参考帧,“找出”B帧“某点”的预测值和两个运动矢量,并取预测差值和运动矢量传送。接收端根据运动矢量在两个参考帧中“找出(算出)”预测值并与差值求和,得到B帧“某点”样值,从而可得到完整的B帧。
B帧特点
1)B帧是由前面的I或P帧和后面的P帧来进行预测的;
2)B帧传送的是它与前面的I或P帧和后面的P帧之间的预测误差及运动矢量;
3)B帧是双向预测编码帧;
4)B帧压缩比最高,因为它只反映丙参考帧间运动主体的变化情况,预测比较准确;
5)B帧不是参考帧,不会造成解码错误的扩散。
注:I、B、P各帧是根据压缩算法的需要,是人为定义的,它们都是实实在在的物理帧。一般来说,I帧的压缩率是7(跟JPG差不多),P帧是20,B帧可以达到50。可见使用B帧能节省大量空间,节省出来的空间可以用来保存多一些I帧,这样在相同码率下,可以提供更好的画质。
压缩算法的说明
h264的压缩方法:
1.分组:把几帧图像分为一组(GOP,也就是一个序列),为防止运动变化,帧数不宜取多。
2.定义帧:将每组内各帧图像定义为三种类型,即I帧、B帧和P帧;
3.预测帧:以I帧做为基础帧,以I帧预测P帧,再由I帧和P帧预测B帧;
4.数据传输:最后将I帧数据与预测的差值信息进行存储和传输。
帧内(Intraframe)压缩也称为空间压缩(Spatial compression)。当压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。帧内一般采用有损压缩算法,由于帧内压缩是编码一个完整的图像,所以可以独立的解码、显示。帧内压缩一般达不到很高的压缩,跟编码jpeg差不多。
帧间(Interframe)压缩的原理是:相邻几帧的数据有很大的相关性,或者说前后两帧信息变化很小的特点。也即连续的视频其相邻帧之间具有冗余信息,根据这一特性,压缩相邻帧之间的冗余量就可以进一步提高压缩量,减小压缩比。帧间压缩也称为时间压缩(Temporal compression),它通过比较时间轴上不同帧之间的数据进行压缩。帧间压缩一般是无损的。帧差值(Frame differencing)算法是一种典型的时间压缩法,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
顺便说下有损(Lossy )压缩和无损(Lossy less)压缩。无损压缩也即压缩前和解压缩后的数据完全一致。多数的无损压缩都采用RLE行程编码算法。有损压缩意味着解压缩后的数据与压缩前的数据不一致。在压缩的过程中要丢失一些人眼和人耳所不敏感的图像或音频信息,而且丢失的信息不可恢复。几乎所有高压缩的算法都采用有损压缩,这样才能达到低数据率的目标。丢失的数据率与压缩比有关,压缩比越小,丢失的数据越多,解压缩后的效果一般越差。此外,某些有损压缩算法采用多次重复压缩的方式,这样还会引起额外的数据丢失。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









