






1、汉字点阵码是一种用黑白两色点阵来表示汉字字形的编码。一个8*8点阵字模的存储容量为?
1、1字节(Byte)有8比特(Bit) 2、黑白两色每个点占用1Bit 3、8×8点阵需要64个Bit 4、因为1Byte有8Bit,所以64Bit/8Bit/Byte = 8Byte 答案是B:8字节。
2、(多选题) 选项中:关于为什么使用十六进制说法,选出你认为正确的是():
A十六进制比二进制更简短 B十六进制相比其他进制阅读和存储都更方便 C十六进制在数据交换时也很便利 D为了统一规范,CPU、内存、硬盘都是采用二进制计算 CPU、内存、硬盘采用的是十六进制计算;
1位十六进制能代表4位二进制,所以十六 进制更简短;
一个字节用2位十六进制就可以表示所以阅读存储都很方便,CPU运算也是遵照ASCII字符集,
以16、32、64的方向发展,故数据交换时十六进制也更便利,所以A,B,C正确。
16进制用在哪里
1、网络编程,数据交换的时候需要对字节进行解析都是一个byte一个byte的处理,1个byte可以用0xFF两个16进制来表达。通过网络抓包,可以看到数据是通过16进制传输的。
2、数据存储,存储到硬件中是0101的方式,存储到系统中的表达方式都是byte方式
3、一些常用值的定义,比如:我们经常用到的html中color表达,就是用的16进制方式,4个16进制位可以表达好几百万的颜色信息。
3、浮点数的精确度
二、浮点数 浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x10^9和12.3x10^8是相等的。
浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x10^9就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。 整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的,而浮点数运算则可能会有四舍五入的误差。 ---------------------
(单选题) python解释器在计算1.2-1.0的结果为(D):
- A0.2
- B0.199
- C0.1
- D以上都不是
# pyhton3中,"/"表示的就是float除,不需要再引入模块,就算分子分母都是int,返回的也将是浮点数 # 方法一:可以使用//求取两数相除的商、%求取两数相除的余数。[/在Python中获取的是相除的结果,一般为浮点数] # 方法二:使用divmod()函数,获取商和余数组成的元祖 # 实例代码: print(3/2) # 1.5 print(3//2) # 1 //是取商 print(1.0/2.0) # 0.5 print(1.2-1.0) # 0.19999999999999996 # 精确度去2 print('%.2f' %(1.2-1.0)) # 0.20 print(divmod(2,3)) # 0,2
---------------------------------
>>>1.2 – 1.0 == 0.2 False >>>2.0 – 1.0 == 1.0 True
第1个表达式结果为带有微小误差的近似值,所以不等于0.2;第2个表达式结果小数位为0,所以为True
-------------------------------------------------------
程序语言浮点数由单精度型和双精度型两种 单精度型占4个字节32位的内存空间只能提供七位有效数字 双精度型占8个字节64位的内存空间可提供17位有效数字 python 3 浮点数默认的是 17位数字的精度 将精度高的浮点数转化成精度低的浮点数,内置方法 round() roud(2.873 , 2) ===> 2.87 格式化 %.2f 保留两位小数 python 的浮点数损失精度问题,python 是以双精度64位来保存浮点数,多余的位会被截掉,
比如 0.1 ,电脑保存的不是精准的 0.1 ,而是 0.10000000001,参与运算后,就会产生误差,特别是哪些对精度要求高的,比如金融领域, 解决方法, round 方法 或 利用 decimal 模块 /raʊnd/ 英/'desɪm(ə)l/ 来解决浮点数精度问题,规定浮点数只到小数点几位数
-----------------------------------
一般是str类型转为decimal类型,而不是float直接转。
---------
2.0
2.4
4.323
4、字符串的replace和get
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
A replace方法如果没有替换成功则报错
B replace方法如果没有替换成功则将原字符串返回
C replace方法如果替换成功返回新的字符串
D replace方法如果替换成功,返回原字符串
答案:BC
对于单个字符的替换不管位置都可
对于连续的多个替换,
python解释器执行'abcd'.replace('ac','we')的结果是__。 'abcd'
--------------------------------------
---------------------------------

5、浅拷贝和深拷贝
# 深拷贝,包含对象里面的自对象的拷贝,所以原始对象的改变不会造成深拷贝里任何子元素的改变 import copy l1 = [1,2,[3,4]] l2 = copy.deepcopy(l1) l1[2] = 'a' print(l1) #[1, 2, 'a'] print(l2) # [1, 2, [3, 4]] # copy浅拷贝,没有拷贝子对象,所以原始数据改变,子对象会改变 import copy l1 = [1,2,3,[4,5]] l2 =copy.copy(l1) l1[3][0] = 'a' print(l1) # [1, 2, 3, ['a', 5]] print(l2) # [1, 2, 3, ['a', 5]]
总结:浅拷贝只是对指针的拷贝,拷贝后两个指针指向同一个内存空间,
深拷贝不但对指针进行拷贝,而且对指针指向的内容进行拷贝,经深拷贝后的指针是指向两个不同地址的指针。
6、可变与不可变数据类型
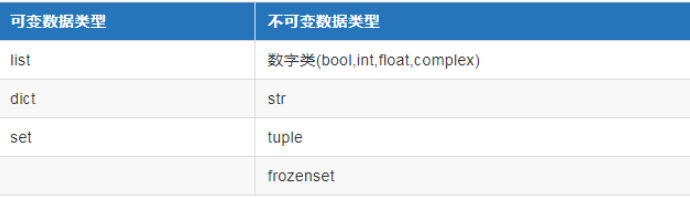
可变数据类型是允许同一对象的内容,即值可以变化,但是地址是不会变化的。
7、字典key值唯一
不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,
key要为不可变类型
d = {(1, [2]): 'a', (1, 2): 1}
print(d)
TypeError: unhashable type: 'list'
-----------------------------------------------
现有字典d1 = {'a':1, 'b':2, 'c':3}和d2 = {1:'a', 'b':4, 'd':3},那么python3解释器执行d1.update(d2)后d1的结果是():
A{'a':1, 'b':2, 'c':3}
B{'d': 3, 1: 'a', 'b': 4, 'c': 3, 'a': 1}
C{1:'a', 'b':4, 'd':3}
D以上都不对
把字典d2的更新到d1
8、集合
python3解释器执行 {{2, 3, 4}.issubset({1, 2, 'a'})的结果为_
答案是False,issubset()用来判断一个集合是否为另一个集合的子集,是则返True,否则返回False
python3解释器执行 {2, 3, 4}.issuperset({2, 3,4})的结果为__
答案是True,两个集合互为超集
9、切片(顾头不顾尾)
现有列表l=[1,2,3,4,5,6,7,8,9,0],那么python3解释器执行l[1:3]='abc'后执行 l[2]的结果是(): A 4 B b C abc D c 把l[1:3]的值为2,3 把这两个值替换为a,b,c,那前三个值为,1,'a','b','c' 〉print(l) #[1, 'a', 'b', 'c', 4, 5, 6, 7, 8, 9, 0]
-----------------------------------------------------------------------------------
现有列表l=[1,2,3,4,5,6,7,8,9,0],那么python3解释器执行l[1:3]=['abc']后执行 l[1]的结果是():
- A a
- B abc'
- C ['abc']
- D b
答案是B,把l[1:3]的值为2,3 把这两个值替换为'abc',那前三个值为,1,'abc',4
print(l) # [1, 'abc', 4, 5, 6, 7, 8, 9, 0]
print(l[1]) # abc
---------------------------------------------------------------------
现有列表l=[2,3,['a','b','c'],1],那么python3解释器执行l[2].extend('de')后l的值是__。
答案是[2, 3, ['a', 'b', 'c', 'd', 'e'], 1],l[2]是['a','b','c'] ,在['a','b','c'] 里追加 ‘d','e', 两个元素。
10 hash
在python中,关于hash()的说法正确的是(): A hash函数只能获取对象的哈希值 B hash()对对象使用时,结果只和对象的内容有关 C hash()可以应用于list,set,dictionary D hash()只能应用于数字,字符串和对象 答案是D,hash()只能应用于数字,字符串和对象 ------------------------------------------------------------------ 在python中,传输文件,通常在先将文件hash后将哈希值一起传递,接收方本地需要再次校验哈希值,这么做为了(): A 这样做为了避免文件损坏 B 是为了防止文件中途被篡改 C 保证了文件的一致性 D 增加文件的传输速度 答案是B,C
11。title
print('AB2AC3DGaa'.lower().title()) >Ab2Ac3Dgaa lower()是将字符串中字母全部转化为小写 Python title() 方法返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写(见 istitle())。 语法 title()方法语法: str.title();
12、单元测试
(多选题) Python Web开发最火的web框架是Django,下列属于Python生态框架选项是哪些():
异步高并发的主流框架Tornado,强大的插件扩展的flask,轻量级bottle框架,完美的django重型框架
----------------------------
python3解释器执行l=[1,4,3].extend(list())
extend方法并无返回值,所以l是 None
------------------------------------------------
列表切片取值 步长为负值的情况
print(num2[::-1])#切片步长为负数,从后面往前面取值,相当于翻转了
---------------------------------------------------------------
集合的概念
41、 (填空题) python3解释器执行 {2, 3, 4}.symmetric_difference({1, 2, 'a'})的结果为__。
答案是{3, 1, 'a', 4},对称补集,就是各自求了一次补集,然后加在一起的结果














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









