






目前,工作中一个项目的数据 Table 和 Stored Procedure 在 DB2 数据库,需要访问之。下面把使用过程中遇到的几个问题整理下:
(说实话,DB2 并没有 SQLServer 好用,也可能我是太小白了,有待于进步 ...)
环境搭建
DB2 Client
DB2 客户端:DB2 v9.1
安装完成后,可以通过cmd命令行查看 DB2Client 相关信息:
- db2level:查看DB2Client版本信,包括32/64位
在开始直接运行 db2cmd 来运行 db2cmd.exe 启动 db2命令行程序,执行 db2:
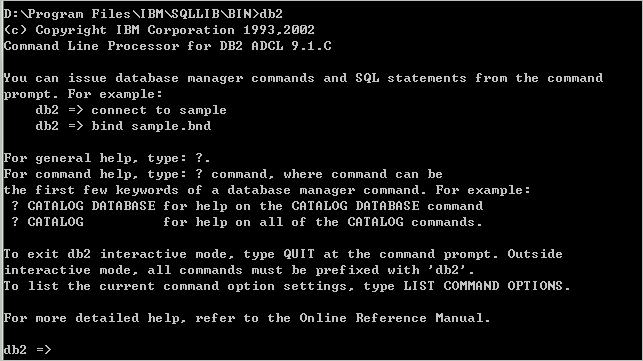
之后,可以执行连接数据库、访问数据等操作。
db2命令行连接数据库
catalog tcpip node runnode_My remote IP server Port
catalog database calldb_Dest as calldb_My at node runnode_My
再凭 用户名和登录密码 即可访问数据库了。其中,DB2 数据库默认端口是 50000。
connect to calldb_My user 用户名 using 密码
catalog 命令只需本地执行一次即可,后续只需执行connect命令。
其他命令备忘
查看结点编目:db2 list node directory
查看数据库编目:db2 list db directory
删除数据库编目:db2 uncatalog db数据库别名
删除结点编目:db2 uncatalog node 结点名
在使用 DB2 过程中,注意:
工程项目中引用的 IBM.Data.DB2.dll 的版本,不能高于本地安装的 DB2 的版本。
否则会出现如下异常信息
System.EntryPointNotFoundException
Unable to find an entry point named 'SQLFreeConnAttribsADONET' in DLL 'db2app.dll'.
Stack Trace:
at IBM.Data.DB2.UnsafeNativeMethods.DB232.SQLFreeConnAttribsADONET(DB2SQLGetConnAttribsADONETParams& pParam)
at IBM.Data.DB2.ConnSettingsFromXmlConfig.Dispose(Boolean disposing)
at IBM.Data.DB2.ConnSettingsFromXmlConfig.Finalize()
考虑 DB2 Client 的版本和安装位数,是否与 .dll 的版本匹配。
具体参见:http://www.toadworld.com/products/toad-for-ibm-db2/f/18/t/25374
或直接百度:无法在 DLL“db2app64.dll”中找到名为“SQLFreeConnAttribsADONET”的入口点
Quest Central
DB2 可视化工具:Quest Central for DB2 v5.0.2.4
关于注册码
- Quest Central for DB2:2-95710-05964-91891-64750 和 Bergelmir/CORE
- Knowledge Xpert for DB2:147851648424638496327 和 stenny
安装之后,启动遇到如下问题:
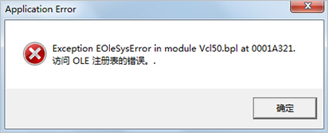
解决方法:程序上点击鼠标右键-->属性-->兼容性;勾选以兼容模式运行这个程序(兼容windowsXP);勾选以管理员身份运行程序,即可解决。
具体操作
通过 db2命令 连接到数据后,在 Quest Central 首页会显示已连接的相应数据库的连接结点。
除 Quest Central 外,还有其他 DB2可视化工具,可扩展学习。
Quest Central 实在是太弱鸡了,还是另寻她路...
DbVisualizer
首先给出数据库连接示意图,DB2为例
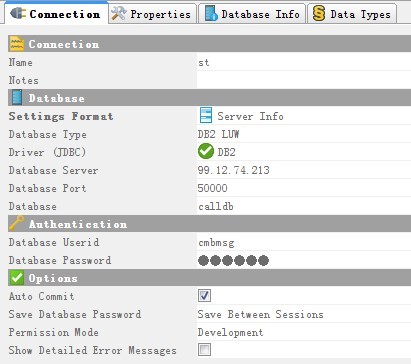
基础使用
之前多是用 SQLServer,初次操作 DB2 数据库,虽说语法大多相仿,还是各种不顺手。
关于DB2,相关资料和书籍推荐:
- 牛新庄 -《循序渐进DB2》《深入解析DB2》《DB2性能调整与优化》
- 《DB2 Express-C 快速入门》
此外,可参考:DB2中国社区;
一个服务器可以建多个实例,一个实例下可以建多个数据库,一个数据库可以包含多个表空间。
- SQL 语句必须要以 ; 结尾
- declare 定义变量不要带 @,这是与 SQL Server 的区别
- SQLSTATE 和 SQLCODE 可以提供 SQL 命令的运行状态
- 存储过程调用:call ProcedureName(inVal, ..., inVal, ?, ... , ?);,其中,? 是输出参数占位符
- NULL 对于完整性约束和查询带来副作用,建议表中最好没有空值,在建表时加上非空约束
- 表存储在表数据空间,索引存储在索引数据空间
- 分区提高系统性能
db2命令行
//导入存储过程
db2 -td@ -vf /tmp/pro.sql/.db2
注意:存储过程体最后务必以END@结尾。
先cd到当前目录,然后db2cmd进入环境,再连接对应数据库结点,最后直接执行上述命令,不要预先先执行db2命令进入db2环境,否则会报错。
- -td:使用@作为语句终止字符
- -v:将命令文本回显到标准输出
- -f:从指定文件读取命令输入
注意,存储过程文件名建议务必跟里面创建的名称保持一致。
//查看存储过程
select * from syscat.PROCEDURES where PROCNAME ='存储过程名'
//导出存储过程
export to F:\xxx.del of del modified by lobsinfile select * from syscat.PROCEDURES where PROCNAME ='存储过程名'
注意,查看和导出存储过程名字务必全部大写,导出方法具体可参考:https://www.cnblogs.com/bhlsheji/p/5332333.html
执行存储过程时,若遇到:
数据库执行异常, ERROR 42884 IBMDB2/AIX64 SQL0440N
找不到具有兼容自变量的类型为 "PROCEDURE" 的名为 "RISKAVOID.PR_TEST" 的已授权例程。
解决思路:确认存储过程是否存在、输入输出参数是否匹配等。
常用命令
(1)查询
// 查看表字段信息
[1]. describe table schemaName.tableName;
[2]. describe select * from schemaName.tableName;
// 查看表索引信息
[1]. describe indexes for table schemaName.tableName show detail;
[2]. select * from syscat.indexes where tabname='大写的表名';
[3]. select I.INDNAME as 索引名,I.COLNAMES as 索引字段 from SYSCAT.INDEXES I where TABSCHEMA='schemaName' and TABNAME='tableName';
// 查看表主键信息
[1]. select K.COLNAME as 主键名 from SYSCAT.keycoluse K where TABSCHEMA='schemaName' and TABNAME='tableName';
[2]. select A.TABNAME, B.COLNAME from SYSCAT.tabconst A, SYSCAT.keycoluse B where A.CONSTNAME=B.CONSTNAME and A.TYPE='P'and A.TABNAME='tableName'
注意,使用时可能要求表名大写。
DB2数据库中,筛选 binary8字段 (DECLARE t_CustId CHAR(8) FOR BIT DATA;),过滤条件格式如下
where "CUSTID" = x'21E8AFA703989120'
(2)删除
// 删除索引
drop index schemaName.indexName;
// 删除存储过程
DROP SPECIFIC PROCEDURE SchemaName.ProcedureName;
(3)重命名
// 重命名 表名
rename table schemaName.oldTabName to newTabName;
// 重命名 字段
alter table schemaName.TabName
rename column oldColName to newColName;
其中,表 oldTabName 不要有外键约束和视图引用。此外,尽量避免字段重命名。
(4)merge into
数据备份(增量)、数据合并
MERGE INTO table_name alias1
USING (table|view|sub_query) alias2
ON (join condition)
WHEN MATCHED THEN
UPDATE table_name SET col1 = col_val1,col2 = col2_val
WHEN NOT MATCHED THEN
INSERT (column_list) VALUES (column_values)
(5)建表
已知存在表 tabSqh,创建 tabSqh 的副本 tabSqh_Copy:
CREATE TABLE tabSqh_Copy like tabSqh;
INSERT INTO tabSqh_Copy select * from tabSqh;
注意,该方法只复制表结构和表数据,tabSqh_Copy 没有相关的表约束,需要手动添加:
alter table tabName
add constraint P_tabName primary key(IDKey);
alter table tabName1
add constraint F_IDKey foreign key (IDKey)
references tabName2 (IDKey)
on delete restrict on update restrict;
其他相关约束添加方法如是之。
SELECT 高级用法
此处介绍 select 在 DB2 中的几种高级用法:
(1)复制表结构
CREATE TABLE new_table_name LIKE table_name;
(2)创建结果表
CREATE TABLE new_table_name AS (
SELECT * FROM table_name
) DEFINITION ONLY;
(3)创建物化查询表(MQT)
create table new_table_name AS (
select * from table_name
) data initially deferred refresh deferred;
refresh table new_table_name;
物化表SELECT语句类似一个查询,没有真正形成表,类型显示为Query,但它完全可以当表来用。
(4)存储过程返回结果集
创建存储过程时,CREATE语句后要加:DYNAMIC RESULT SETS 1
最后,返回结果集采用如下形式
BEGIN
DECLARE CUR_RESULT CURSOR WITH RETURN TO CALLER FOR
select
Col1 ,
Col2 ,
Col3 ,
from SchemaName.TableName
where Col1 = col1_val
FOR READ ONLY;
OPEN CUR_RESULT;
END;
注意,返回结果集时,不要加COMMIT WORK
删表
(1)删除单行数据或批量删除数据:方法2比方法1性能好
// 方法1
DELETE FROM tabName WHERE 过滤条件
// 方法2
DELETE FROM
(
SELECT * FROM tabName WHERE 过滤条件
);
(2)全表数据删除
// 方法1
DELETE FROM tabName;
// 方法2
DROP TABLE ...
CREATE TABLE ...
// 方法3
ALTER TABLE tabName ACTIVATE NOT LOGGED INITIALLY WITH EMPTY TABLE;
(3)直接删除表
DROP TABLE tabName;
临时表
DB2的临时表基于会话(session),且会话之间相互隔离。当会话结束时,临时表的数据被删除,临时表也会被删除。
临时表的作用:
- 保存中间结果集,以便任务的后续处理
- 避免复杂的SQL语句,将一条较为复杂的SQL语句分解成多条简单的SQL语句,提高运行效率
// 创建临时表
DECLARE GLOBAL TEMPORARY TABLE session.TmpTableName
LIKE rvc.TableName INCLUDING COLUMN DEFAULTS
WITH REPLACE
ON COMMIT PRESERVE ROWS
NOT LOGGED;
// 向临时表中插入数据
INSERT INTO session.TmpTableName
SELECT * FROM rvc.TableName WHERE <过滤条件>;
其中,NOT LOGGED 表示不记录日志,WITH REPLACE 表示若已存在临时表则替换之,ON COMMIT PRESERVE ROWS 表示commit后仍然保留表中的数据。之后,临时表可以当作是普通表,查询、联表均可。
关于session临时表的几个问题:http://www.db2china.net/Question/28913
关于session临时表控制选项 ON COMMIT PRESERVE ROWS的解释:http://www.db2china.net/Article/9916
注意,全局临时表允许创建索引、但不允许创建主键和唯一约束。创建的临时表同原表有相同的表结构,但是相关列的属性(主键、外键、唯一约束、索引等)信息是没有的。
其余信息可参考:DECLARE GLOBAL TEMPORARY TABLE - IBM;
DGTT 与 CGTT
上述临时表均为 DGTT(已声明的全局临时表),DB 9.7 开始支持 CGTT(已创建的全局临时表)。
共同点:
- 支持基于会话的数据
- 支持索引,但不支持唯一约束或主键
两者都支持基于会话的数据。
CGTT 优点:
- 持久化的,在系统设置时预先创建、供以后共享之,而 DGTT 是在某一回话中声明、仅供该会话使用;
- 避免在各用户会话开始时声明临时表的要求;
- 采用与普通表相同的模式规则,而 DGTT 必须是固定的模式 SESSION;
创建 CGTT:
CREATE GLOBAL TEMPORARY TABLE <table_name> (
<column_name> <column_datatype>,
<column_name> <column_datatype>,
… )
ON COMMIT [PRESERVE|DELETE] ROWS
ON ROLLBACK [PRESERVE|DELETE] ROWS
[NOT LOGGED|LOGGED]
DISTRIBUTE BY HASH ( col1,..)
IN <tspace-name>;
给出一个简单的示例
//--定义全局临时表
DECLARE GLOBAL TEMPORARY TABLE TMP_INFO (
IDType CHAR(3) NOT NULL,
IDCard VARCHAR(32) NOT NULL,
Name VARCHAR(32) NOT NULL,
CustID CHAR(8) FOR BIT DATA
)
WITH REPLACE ON COMMIT PRESERVE ROWS NOT LOGGED;
其余详细信息可参考:DB2 临时表 - DGTT 和 CGTT;
索引
索引是有序键值的集合,每一个键值指向表的一行。
索引是一把双刃剑,当表的索引过多时,数据删除、插入和更新效率会降低,当索引过少或者设计不合理时会影响数据的查询效率。尽量不要在包含 null 值的字段上建立(单列)索引,因为索引不会存储该条记录的信息。
对于组合索引,引导列(组合索引中排在最左边的列)对查询语句中where条件的影响最大。因此,应该对索引键中的列按重复值由少到多的顺序排序,该排序会使索引键提供最佳性能。
优点:
- 加快查询速度
- 避免不必要的表扫描 或 排序操作
- 减少死锁的发生
- 唯一性索引保证数据的唯一性
缺点:
- 额外的存储空间
- 索引创建和维护的耗时
统计信息
数据库对象的统计参数信息,如表的数据量大小、占用的页数、表的行数、索引的情况和所在的分区情况等。
一个SQL在写完并运行之后,我们只是告诉DB2去做什么,而不是如何去做。具体怎样做,取决于优化器。优化器为了生成最优的执行计划,需要掌握当前的系统信息、目录中的统计信息等。runstats 命令就是用来收集数据库对象的状态信息,对优化器生成最优的执行计划至关重要。
对数据表频繁的insert, update,会导致数据库存储中出现物理碎片,runstats可以对数据库进行数据重组,有助于数据块连续化、提高数据存取的效率,原理类似于OS中的磁盘碎片整理。
// 针对表
runstats on table schemaName.tableName;
// 针对表和索引信息
runstats on table schemaName.tableName [with distribution] and [detailed] indexes all;
// 针对某个单一索引
runstats on table schemaName.tableName for/and indexes schemaName.indexName;
执行计划
在关系型数据库调优过程中,SQL语句是关乎性能问题的主要原因,而执行计划则是解释SQL语句执行过程的语言。
- 不同数据库之间对于执行计划的表示方法各不相同
- 每次导入存储过程,生成的存储过程执行计划不一定完全相同,受当前的数据库参数、统计信息的影响
SQL语句的执行过程总共包含两个关键环节:
- 数据读取方式(scan):表扫描 or 索引扫描
- 表之间如何进行连接(join):包含Nest Loop 、Merge Join、Hash join及半连接等、多表间的连接顺序选择
关于多表间连接的顺序选择问题:
不论在同一条SQL语句中包含了多少张表连接,同一时刻只有两张表进行连接,但多表间的连接顺序也是决定性能的主要原因。数据库对于表的顺序的选择,根据两个表之间连接后得出的行数进行排序,如果统计信息与实际情况偏差较大,有可能会导致由于连接顺序不当而导致的性能问题。
相关信息请参考:DB2执行计划浅析;
对于稍微复杂的SQL,建议使用 Quest Central 中的 SQL Turning 功能,比较直观。
SQL语句执行计划的其他查看方法:
(1)db2expln
db2expln执行计划分为三部分:
- 当前采集执行计划的语句
- 执行计划详细信息
- 执行计划图:从下往上,从左往右,按照编号从大到小的顺序进行阅读
在cmd命令行运行 db2expln 命令,可以查看该命令的使用帮助。
db2expln -d 数据库名称 -u 用户名 密码 -q "sql语句"[-f "文件名.sql"] -t -o 输出文件名.out
其中,文件名.sql 中的多条独立的SQL语句各占1行,行末不要带分号。
db2expln -d dbName -u sqh cmb@2018 -q "sql语句" -g -t -o tmp_sqh.out
db2expln -d dbName -u sqh cmb@2018 -f "sqh.sql" -g -t -o tmp_sqh.out
对上述命令的解释:
- -t:输出到终端,-o:输出到文件
- -q:执行一个SQL语句,-f:执行某个保存了多条SQL语句的文件
- -g:图形化显示
- -z:指定SQL语句间的分隔符
参考:利用 db2expln 的 DB2 SQL性能优化示例;
(2)db2exfmt
该方法需要在DB2安装目录 ...\IBM\SQLLIB\MISC\ 下有 explain.dll 文件,有待于进一步学习。
关于查看存储过程的执行计划
首先,获取存储过程相对应的包
SELECT bname, bschema, pkgname, pkgschema
FROM syscat.packagedep
WHERE btype='T' AND pkgname in (
select bname from sysibm.sysdependencies where dname in (
select specificname from syscat.procedures where procname='存储过程名称' AND procschema='存储过程模式名称'
)
);
然后,再通过如下命令获取包中的执行计划
db2expln -d 数据库名称 -u 用户名 密码 -g -c 包模式名称 -p 包名称 -s 0 -t -o tmp_sqh.out
注意,上述代码获取存储过程对应的包,某些情况下查询不到信息,至于为啥还不清楚,再提供另一种方法
select c.PROCSCHEMA, c.PROCNAME, b.*
from syscat.STATEMENTS b, syscat.PROCEDURES c, syscat.ROUTINEDEP d
where b.pkgname = d.bname
AND c.SPECIFICNAME = d.SPECIFICNAME
AND c.PROCSCHEMA = d.ROUTINESCHEMA
AND c.PROCSCHEMA = '存储过程模式名称' AND c.PROCNAME = '存储过程名称';
总结之,鉴于数据库存储过程执行计划的多变性,建议:
- runstats + rebind
- 删除重建
runstats 命令参见上述统计信息部分,下面给出其他常用命令
// 重新绑定包
rebind package pkgSchemaName.pkgName;
// 更新 package cache 中的执行计划
flush package cache dynamic;
注意,runstats 仅是更新执行计划的一方面(对动态SQL生效、但对存储过程无效),另一方面还需 rebind 包(对更新存储过程执行计划才有效)。
常见总结
作中偶然遇到执行存储过程报错,信息如下
ErrMsg="[--sqlcode: -727 --sqlstate: 00000
--error_message: SQL0727N An error occurred during implicit system action type "5".
Information returned for the error includes SQLCODE "-204", SQLSTATE "42704"
and message tokens "SESSION.TMP_UUID". SQLSTATE=56098]"
网上信息比较少,经验证,因为存储过程中调用了外部函数,而数据库已经禁止使用外部函数。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









