






在安全圈里我们会经常听到或用到一些0day漏洞,在印象里我们都觉的只有真正的大神才能挖掘到这样的漏洞,事实也的确如此。不过也不要被吓到,其实大部分的0day是缓冲区溢出漏洞演化而来,只要我们了解了缓冲区溢出原理,假以时日也可以自己挖掘出0day漏洞。
由于是本系列的开篇,所以不给大家讲解过多的原理,今天先让大家直观感受一下什么是缓冲区溢出,让各位有一个初步的认识,闲话少叙,让我们开始。
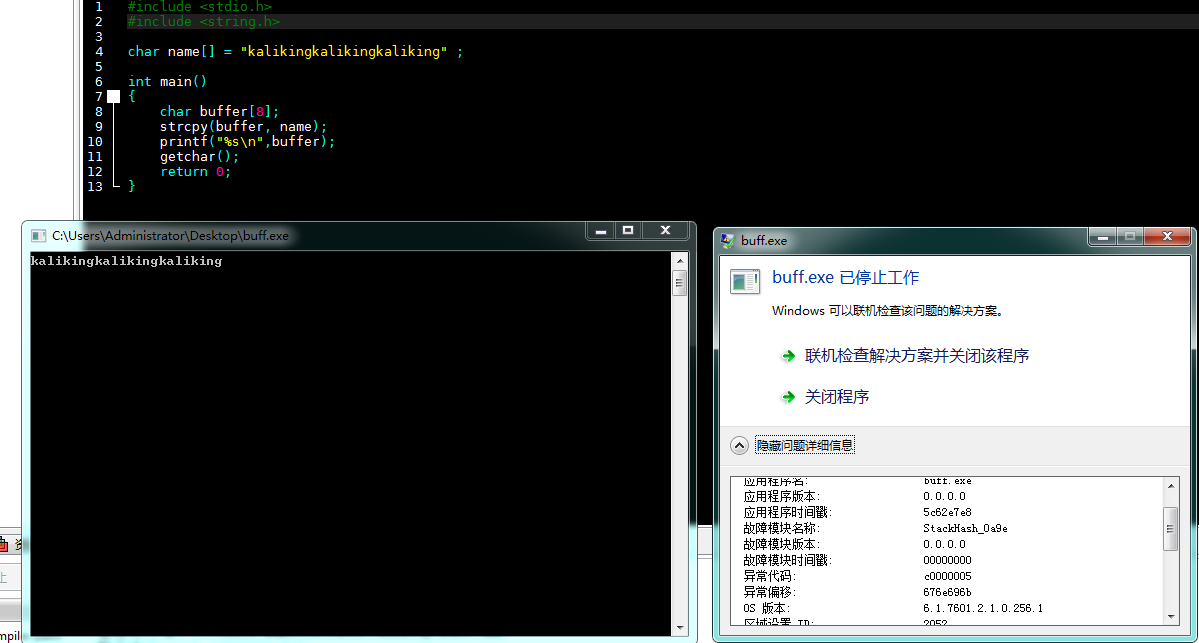
给大家一段c语言编写的代码,大家在DEV中编译执行一下:
在win7中会出现以下报错,如图所示:
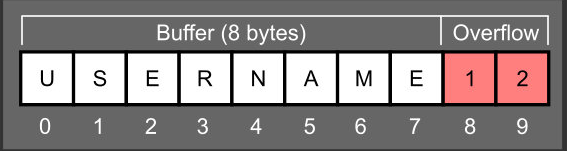
 有一点c语言基础的人就不难看出问题所在,在程序中我们要把变量name的值拷贝给变量buffer,但我们分配给变量的空间只有8个字节,而name的长度远远大于8个字节。这就导致系统原本分配的空间不足而占用了本来用于存储程序返回地址的空间,导致程序无法正常运行。
有一点c语言基础的人就不难看出问题所在,在程序中我们要把变量name的值拷贝给变量buffer,但我们分配给变量的空间只有8个字节,而name的长度远远大于8个字节。这就导致系统原本分配的空间不足而占用了本来用于存储程序返回地址的空间,导致程序无法正常运行。
今天先不讲原理,先讲讲分析缓冲区溢出必备的几款软件:
1.Dev-C ++ 是一个免费的全功能集成开发环境(IDE),分布在GNU通用公共许可证下,用于 C和C ++编程。它是用Delphi编写的。
免费下载地址:://sourceforge.net/projects/orwelldevcpp/files/latest/download
2.OllyDbg(以其作者Oleh Yuschuk命名)是一个强调二进制代码分析的x86调试器。

免费下载地址:http://www.ollydbg.de/odbg201.zip
3.IDA (Interactive Disassembler)是反汇编为计算机软件,其生成汇编语言源代码从机器可执行代码。它支持多种可执行文件格式为不同的处理器和操作系统。它还可以用作Windows PE,Mac OS X Mach-O和Linux ELF可执行文件的调试器。

免费版下载地址:https://www.hex-rays.com/products/ida/support/download_freeware.shtml
接下来介绍一下三个软件的基本使用方法:
在这里只介绍在程序分析过程中常用的方法,其余的详细使用教程请自行Google
Dev c++的使用方法:
1.新建源代码文件
由于我们编写的源代码,只为了了解缓冲区溢出的原理,所以不必过于复杂,我们只需要新建个源代码文件就可以了,没必要创建项目文件。 
把我们上边的示例代码拷贝进去,保存与其他编辑器无异,ctrl+s就ok,我习惯保存成c文件,这个大家随意。 
2.编译运行:
编译运行就很简单了,点击工具栏最上方的运行,接着在下拉菜单中找到编译和运行,点击:
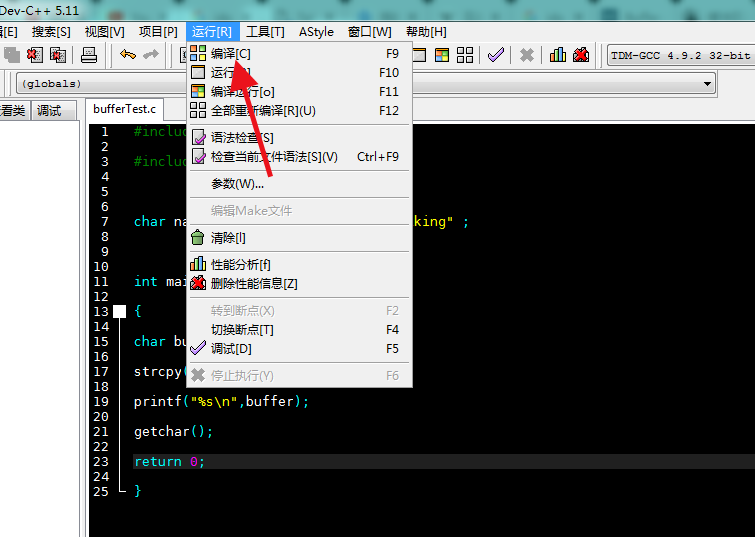
这时候会看到文件夹中多了一个exe文件这就是我们要用来调试的程序:

3.调试和查看汇编代码
这个是比较重要的一步,因为在编写shellcode的时候会用到,这里只讲用法,如何提取shellcode以后再讲。
首先设置断点,选择设置断点的行,可以再前面行标出单击也可以按F4,当行标处出现红点说明断点设置成功。

然后开启调试模式,我们点击下方选项卡里的调试,接着点击调试按钮。
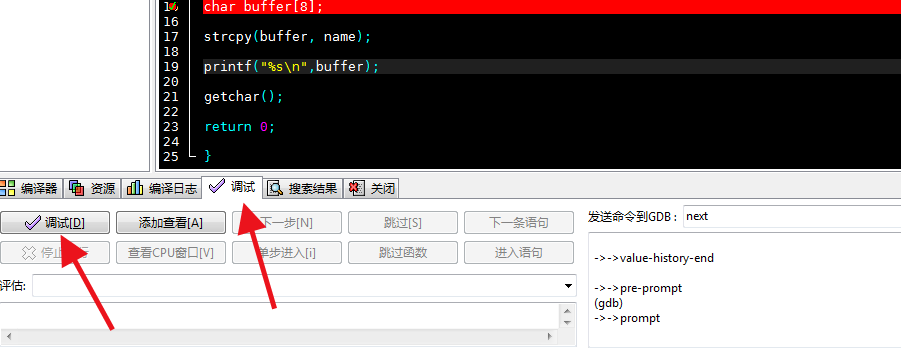
接着点击查看CPU窗口: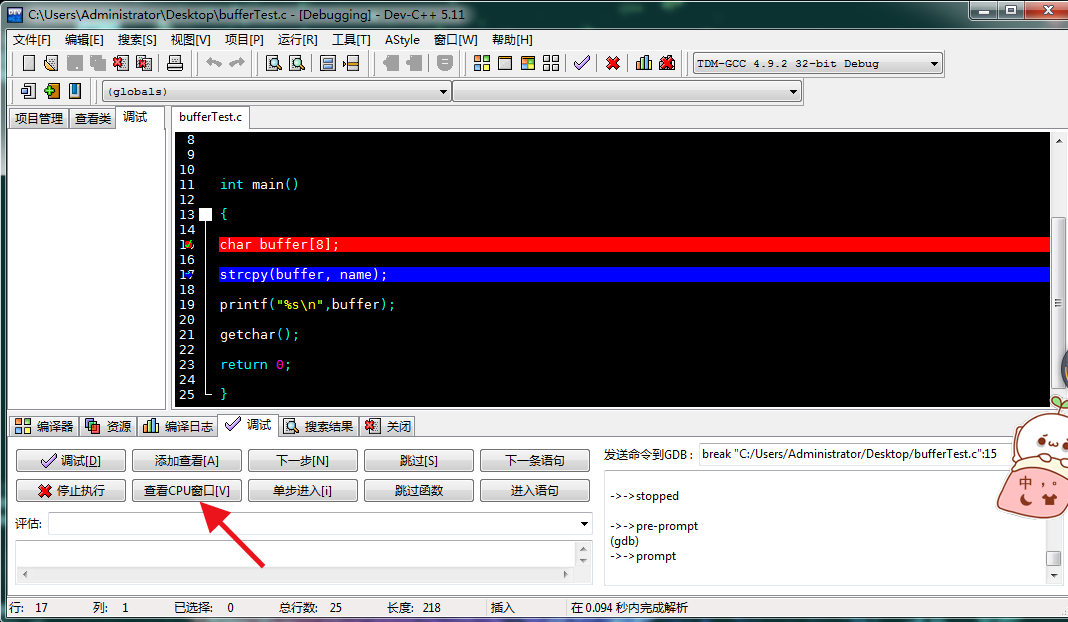
我们就会看到汇编代码界面:
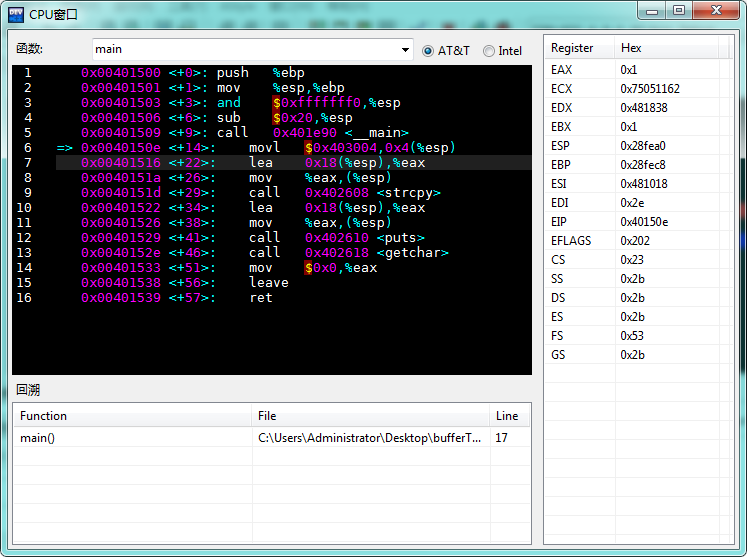
dev c++几个重要用法已经说完了,还要跟大家说一下如何解决安装使用过程中经常会出现zlib2.dll文件丢失的问题。
解决办法如下:
1.下载zlib1.dll:
http://www.pc6.com/softview/SoftView_81060.html
2.解压后放到系统目录中
32位系统:放到C:\Windows\System32\(此处为系统目录)
64位系统:放到C:\Windows\SysWOW64\
为了不使篇幅过长,其余两个软件使用方法我将在下一篇文章中进行讲解。















 716
716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









