






课程名称:《程序设计与数据结构》
学生班级:1623班
学生姓名:刘伟康
学生学号:20162330
实验时间:2017年10月23日—2017年10月27日
实验名称:树
指导老师:娄嘉鹏、王志强老师
实验要求:
实验二 树
(1)参考教材p375,完成链树LinkedBinaryTree的方法(getRight,contains,toString,preorder,postorder),用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试;
(2)基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二叉树的功能,比如教材P372,给出
HDIBEMJNAFCKGL和ABDHIEJMNCFGKL,构造出 附图 中的树,用JUnit或自己编写驱动类对自己实现的功能进行测试;
(3)完成PP16.6;
(4)完成PP16.8;
(5)完成PP17.1;
(6)参考 http://www.cnblogs.com/SuperGroup/p/7669198.html 对Java中的红黑树(TreeMap,HashMap)进行源码分析。
实验步骤及代码实现:
代码托管汇总
1. 树-1:(二叉树)
实现二叉树
LinkedBinaryTree,参考教材p375,完成链树LinkedBinaryTree的方法(getRight,contains,toString,preorder,postorder),用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试。- 要实现 LinkedBinaryTree 中的方法,首先要将结点类 BTNode 补充完整。在结点类中,需要补充先序遍历和后序遍历的函数,由于这里用到了迭代器和递归的思路,所以直接参考中序遍历给出的函数即可:
/*
Performs an inorder traversal on this subtree,updating the specified iterator.
*/
public void inorder(ArrayIterator<T> iter){
if(left != null)
left.inorder(iter);
iter.add(element);
if(right != null)
right.inorder(iter);
}调整左子树、右子树和根的访问顺序以及对应方法即可实现另外两种函数:
public void preorder(ArrayIterator<T> iter){
//根、左、右
iter.add(element);
if(left != null)
left.preorder(iter);
if(right != null)
right.preorder(iter);
}
public void postorder(ArrayIterator<T> iter){
//左、右、根
if(left != null)
left.postorder(iter);
if(right != null)
right.postorder(iter);
iter.add(element);
}实现了结点类之后,对应地去实现方法类 LinkedBinaryTree,方法类中需要补充的函数有:getRight,contains,isEmpty,toString,preorder,postorder.
getRight 方法可以参考给出的 getLeft 方法,注意要先判断根结点是否为空:
/*
Returns the right subtree of the root of this tree.
*/
public BinaryTree<T> getRight() {
if(root == null)
throw new EmptyCollectionException("Get right operation failed. The tree is empty.");
LinkedBinaryTree<T> result = new LinkedBinaryTree<>();
result.root = root.getRight();
return result;
}contains 方法我主要考虑了根为空、和检测元素为空的情况,并对此做出条件判断即可:(如果根为空则会因 node 的初始值返回 false)
/*
Determines if the specified target is in the tree.
*/
public boolean contains(T target) {
BTNode<T> node = null;
boolean result = true;
if(root != null)
node = root.find(target);
if(node == null)
result = false;
return result;
}isEmpty 方法的实现比较简单,但是我第一次做的时候,将判断条件写成了 root.count() == 0,
【注意】树结构不是链表,也不是数组,count方法是返回 子树的结点数,所以开始就默认根结点存在了即count方法的返回值至少为1,所以当然不能用在isEmpty方法中。
这里直接判断根结点是否为空即可:
/*
Determines if the tree is empty.
*/
public boolean isEmpty() {
return root == null;
}toString 方法的思路与之前实现的数据结构(栈、队列)有些类似,注意这里要用到遍历方法,要用到递归,所以我用数组迭代类创建对象,之后层序遍历输出。我在实现这个方法时出现了很多报错,借助IDEA的提示,才成功解决了问题:
/*
Returns the representation of the tree.
*/
public String toString() {
String result = "";
ArrayIterator<T> arr;
arr = (ArrayIterator<T>) levelorder();
for(T i : arr){
result += i + " ";
}
return result;
}preorder 和 postorder 方法只需参考给出的 inorder 方法改一下遍历方式就行:(这三者的遍历方式都是按子树进行的,所以框架相同)
public Iterator<T> preorder() {
ArrayIterator<T> iter = new ArrayIterator<>();
if(root != null)
root.preorder(iter);
return iter;
}
public Iterator<T> postorder() {
ArrayIterator<T> iter = new ArrayIterator<>();
if(root != null)
root.postorder(iter);
return iter;
}所有方法实现之后,即可进行测试,考虑到驱动类测试和 Junit 测试的各自优势,我对此方法类分别进行了测试:
其中,我用驱动类测试了 levelorder,preorder,inorder,postorder,iterator,toString 方法:
[](http://images2017.cnblogs.com/blog/1062725/201710/1062725-20171029184704133-1214173796.png)
**又用 Junit 测试了 getRootElement,getRight,getLeft,contains,isEmpty,size,find 方法:**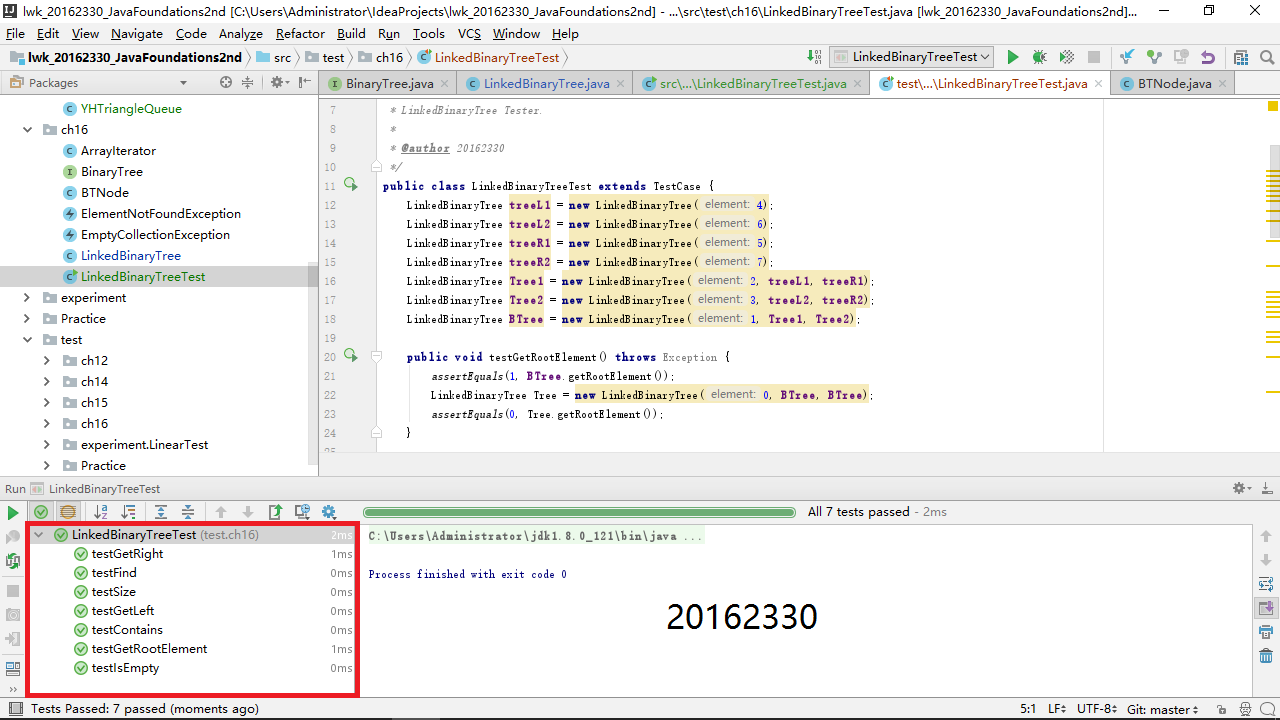
我不太清楚老师要求测试哪些方法,就都测试了一遍。2. 树-2:(构造二叉树)
基于
LinkedBinaryTree,实现基于中序先序序列构造唯一一棵二叉树。比如教材P372,给出H D I B E M J N A F C K G L和A B D H I E J M N C F G K L,构造出附图中的树,用JUnit或自己编写驱动类对自己实现的功能进行测试。这个实验有难度,我查询了一些资料,参考了其中的思路和方法:http://blog.csdn.net/diu_brother/article/details/50926481
设计思路如下:
(1)确定树的根结点;(先序遍历的第一个结点就是二叉树的根)
(2)求解树的子树;(找到根在中序遍历的位置,位置左边就是二叉树的左孩子,位置右边是二叉树的右孩子,如果根结点左边或右边为空,那么该方向子树为空;如果根节点左边和右边都为空,那么根节点已经为叶结点)
(3)对二叉树的左、右孩子分别进行步骤(1)(2),直到求出二叉树的结构为止。这个设计思路的关键就在于第二部分的实现,首先看第一部分,除了迭代器之外,我们还可以使用数组存储二叉树结点对应的索引,之后遍历元素确定树的根结点:
public int findRoot(String[] a, String x, int begin, int end) { for (int i = begin; i <= end; i++) { if (a[i] == x) return i; } return -1; }关于如何确定树的子树,我们可以考虑传入数组序列中不同元素与根之间的关系,比如在中序遍历时,小于根结点对应索引的元素全在左子树,大于的全在右子树。运用索引递归就可以将左右子树依次构造出来:
public void initTree(String[] preorder, String[] inorder) { this.root = this.initTree(preorder, 0, preorder.length - 1, inorder, 0, inorder.length - 1); } public BTNode initTree(String[] preorder, int s1, int e1, String[] inorder, int s2, int e2) { if (s1 > e1 || s2 > e2) { return null; } String rootE = preorder[s1]; BTNode head = new BTNode(rootE); //找到根结点的位置 int rootG = findRoot(inorder, rootE, s2, e2); //构建左子树 BTNode left = initTree(preorder, s1 + 1, s1 + rootG - s2, inorder, s2, rootG - 1); //构建右子树 BTNode right = initTree(preorder, s1 + rootG - s2 + 1, e1, inorder, rootG + 1, e2); head.left = left; head.right = right; return head; }之后可以调用书中已实现的层序遍历方法将其输出即可:(我同样做了两次测试)


3. 树-3:(决策树)
简易20问游戏,完成PP16.6。
- 这个实验算是最令人愉悦的一个吧!可以自己设计问题和答案,课本上也有一个示例代码可以参考,这样思路上就比较容易了。
决策树需要注意的就是不要搞混左子树和右子树的对象,在传递元素时可以参考书中的格式,先定义元素,再定义对应类型的树,之后再将元素依次实例化并填入构建的子树,根据回答迭代输出问题,直到只剩下最后一层叶结点,输出判定结果即可:
//定义元素
String e1 = "这个伙伴是在草帽海贼团进入红土大陆之前上船的吗?";
String e2 = "这个伙伴戴帽子吗?";
......
//定义对应类型的树
LinkedBinaryTree<String> n2,n3,n4,......;
//将元素依次实例化并填入构建的子树
n17 = new LinkedBinaryTree<>(e17);
n18 = new LinkedBinaryTree<>(e18);
n16 = new LinkedBinaryTree<>(e14,n17,n18);
......
tree = new LinkedBinaryTree<>(e1,n2,n3);
......
//根据回答迭代输出问题
while(current.size() > 1){
System.out.println(current.getRootElement());
if(scan.nextLine().equalsIgnoreCase("N"))
current = (LinkedBinaryTree<String>) current.getLeft();
else
current = (LinkedBinaryTree<String>) current.getRight();
}
//输出判定结果
System.out.println(current.getRootElement());
......将上述代码写在一个方法中,在测试类中只调用这一个方法即可实现此游戏:
[](http://images2017.cnblogs.com/blog/1062725/201710/1062725-20171029213706898-1359388945.png)
这个20问游戏在网上也挺热闹,20问对于玩家来说物体的范围就更宽泛了,网上游戏设置的可选答案有很多,大概是实现了 n 叉决策树吧:http://www.20q.net/.这个实验激发了我的一些兴趣,感觉自己测试了自己写的游戏就很爽:
[](http://images2017.cnblogs.com/blog/1062725/201710/1062725-20171029214235445-653703465.png)4. 树-4:(表达式树)
表示算术表达式,完成PP16.8。
- 经过上一个实验的适当放松之后,迎来的又是一个有难度的实验,使用树来表示算术表达式,我知道一部分,又参考了利用Java实现表达式二叉树,但还是没能实现输入后缀,输出中缀的情况。这里的表达式结果输出我理解为中序输出,至于输入我想使用后缀表达式,我继续查找相关资料,并参考了其中的部分代码:
public static Node buildTree(String str) {
Stack<Node> stack = new Stack<>();
for (char c : str.toCharArray()) {
if (c == '+' || c == '-' || c == '*' || c == '/') {
Node node = new Node(c);
Node right = stack.pop();
Node left = stack.pop();
node.left = left;
node.right = right;
stack.push(node);
} else {
Node node = new Node(c);
stack.push(node);
}
}
Node root = stack.pop();
return root;
}这个类创建了一个栈对象,并且实现了依次压入根(符号)、左子树(数字)和右子树(数字)的循环,并且只针对后缀表达式中的符号与元素的位置关系,之后在测试类中传入输入元素构造表达式树之后再中序遍历即可:
[](http://images2017.cnblogs.com/blog/1062725/201710/1062725-20171029220015414-880012614.png)5. 树-5:(二叉查找树)
实现二叉查找树
LinkedBinarySearchTree,完成PP17.1。- 这个实验相对容易些,要求实现二叉查找树中的方法 findMin 和 findMax,这两种方法无非是找出二叉查找树中的特殊元素,所以可以从遍历方式上考虑。由于二叉查找树的最小元素始终位于整棵树左下角最后一个左子树的第一个位置,所以就可以直接返回这个元素的位置,至于怎么获取这个元素就可以使用之前的遍历方法,二叉查找树的最小元素是中序遍历的第一个元素,而后序遍历就不一定,其他的遍历方式也不行。于是就返回中序遍历后的第一个元素即可。
二叉查找树中最大元素的查找过程同理,还是采用中序遍历最保险,需要使用两次强转:
public T findMin() {
ArrayIterator itr = (ArrayIterator) inorder();
return (T) itr.get(0);
}
public T findMax() {
ArrayIterator itr = (ArrayIterator) inorder();
return (T) itr.get(size()-1);
}这个思路相对简洁,测试结果如下:
[](http://images2017.cnblogs.com/blog/1062725/201710/1062725-20171029221638476-1049468285.png)6. 树-6:(红黑树分析)
参考 http://www.cnblogs.com/SuperGroup/p/7669198.html .对Java中的红黑树(TreeMap,HashMap)进行源码分析。
这两个类的源码比较长,我只针对其中的几个方法进行了分析。
首先说说红黑树:参考 http://www.cnblogs.com/skywang12345/p/3245399.html
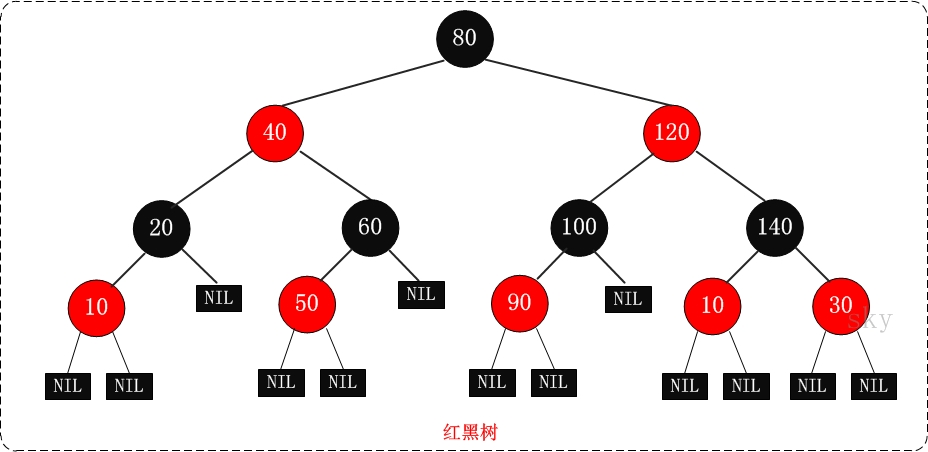
红黑树,即 R-B Tree,全称是Red-Black Tree,它一种特殊的二叉查找树。红黑树的每个结点上都有存储位表示结点的颜色,可以是红(Red)或黑(Black)。红黑树的特性:
(1)每个结点或者是黑色,或者是红色。
(2)根结点是黑色。
(3)每个叶结点(NIL)是黑色。 【注意:这里叶结点,是指为空(NIL或NULL)的叶结点!】
(4)如果一个结点是红色的,则它的子节点必须是黑色的。
(5)从一个结点到该结点的子孙结点的所有路径上包含相同数目的黑结点。【注意】
(01) 特性(3)中的叶结点,是只为空(NIL或null)的结点。
(02) 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。
红黑树示意图:

- TreeMap类:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.SerializableTreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
- firstEntry()和getFirstEntry()方法:
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
}
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}firstEntry() 和 getFirstEntry() 都是用于获取第一个节点。firstEntry() 是对外接口;getFirstEntry() 是内部接口。而且,firstEntry() 是通过 getFirstEntry() 来实现的。
那么为什么不直接调用getFirstEntry() ,而调用 firstEntry() 呢?
这么做的目的是:防止用户修改返回的Entry。getFirstEntry()返回的Entry是可以被修改的,但是经过firstEntry()返回的Entry不能被修改,只可以读取Entry的key值和value值。
- HashMap类:
初始容量与加载因子是影响HashMap的两个重要因素:
public HashMap(int initialCapacity, float loadFactor)初始容量默认值:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16加载因子默认值:
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;为什么默认的负载因子大小为0.75呢?我查找了资料:
默认0.75这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
- containsValue类:
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}如果在map中包含对应的特定的键值则返回true,否则返回false。
方法有些类似于contains方法,在功能上contains检测是否有对应关联的键,containsValue检测是否有对应的值,内部使用V(泛型)定义一个值,而Node<K,V>实现了Map.Entry<K,V>这个接口,每个key-value都放在了Node<K,V>这个对象中,采用 Node<K,V>[] tab 数组的方式来保存key-value对,之后判断tab数组是否为空,size是transient声明的实例变量,确保其大于0后,遍历存放key-value的tab数组,每对键值又定义了e来保存并遍历,直到e对应的下一个值为空,将e对应的某值赋给v,最后判断是否和指定值地址相同,或者判断是否键值不为空并且字符完全相同,至少一者成立才能返回true,比之前链表中contains方法的开销、时间复杂度更大。
查找树结点:
/**
* Finds the node starting at root p with the given hash and key.
* The kc argument caches comparableClassFor(key) upon first use
* comparing keys.
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}此方法通过hash值的比较,递归遍历红黑树,
compareableClassFor(Class k):判断实例k对应的类是否实现了Comparable接口。
其他的在资料上找到:compareTo()方法在这里需要通过反射机制来check他们到底是不是属于同一个类,是不是具有可比较性。
测试过程及遇到的问题:
1. 第一个实验中 LinkedBinaryTree 类的 toString 方法怎么实现?
- 解决办法:(询问张旭升以及使用IDEA调试)
如果要在 Junit 或者测试类中输出完整遍历的树,就要用到 toString 方法,树的 toString 方法和之前的数组、队列等相似,但是我不知道怎么实现,使用之前的框架会报出很多错误,于是去问张旭升。
张旭升是用数组迭代器创建了一个对象,之后将层序遍历的结果赋给该对象并且遍历输出,我参考了他的思路,实现了代码,最后即可得到正确结果:
public String toString() {
String result = "";
ArrayIterator<T> arr;
arr = (ArrayIterator<T>) levelorder();
for(T i : arr){
result += i + " ";
}
return result;
}之所以使用数组迭代器是因为这个类本身实现了Iterator接口和ArrayList类,而层序遍历方法levelorder()的返回类型是Iterator<T>,其中的临时变量类型也是用ArrayIterator类创建的,所以这样使用是合理的,只需要将levelorder()的结果强转即可。(使用 ArrayList 定义 arr 也能实现该方法)
[](http://images2017.cnblogs.com/blog/1062725/201710/1062725-20171030022945715-1100636280.png)
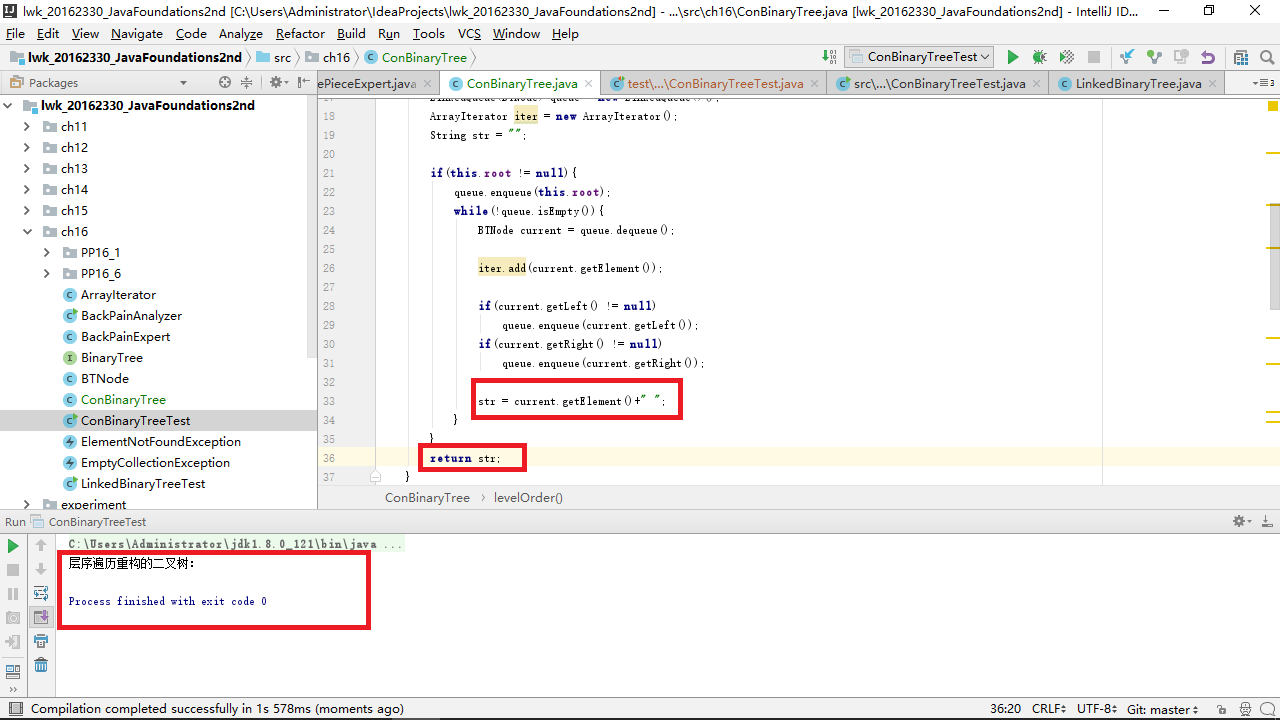
【注意】这里如果使用普通的 for 循环或者 while 循环替换会比较麻烦。在进行迭代输出时,arr 并不是数组,因此务必使用对应的 T 类型的变量依次进行赋值。2. 第二个实验在根据先序序列和中序序列构造二叉树之后的层序遍历输出为什么是空值?
解决办法:(使用debug单步跟踪进行调试)
我将 levelOrder 方法检查了几遍,发现没有问题,我在最后也定义了String变量存储输出的元素:
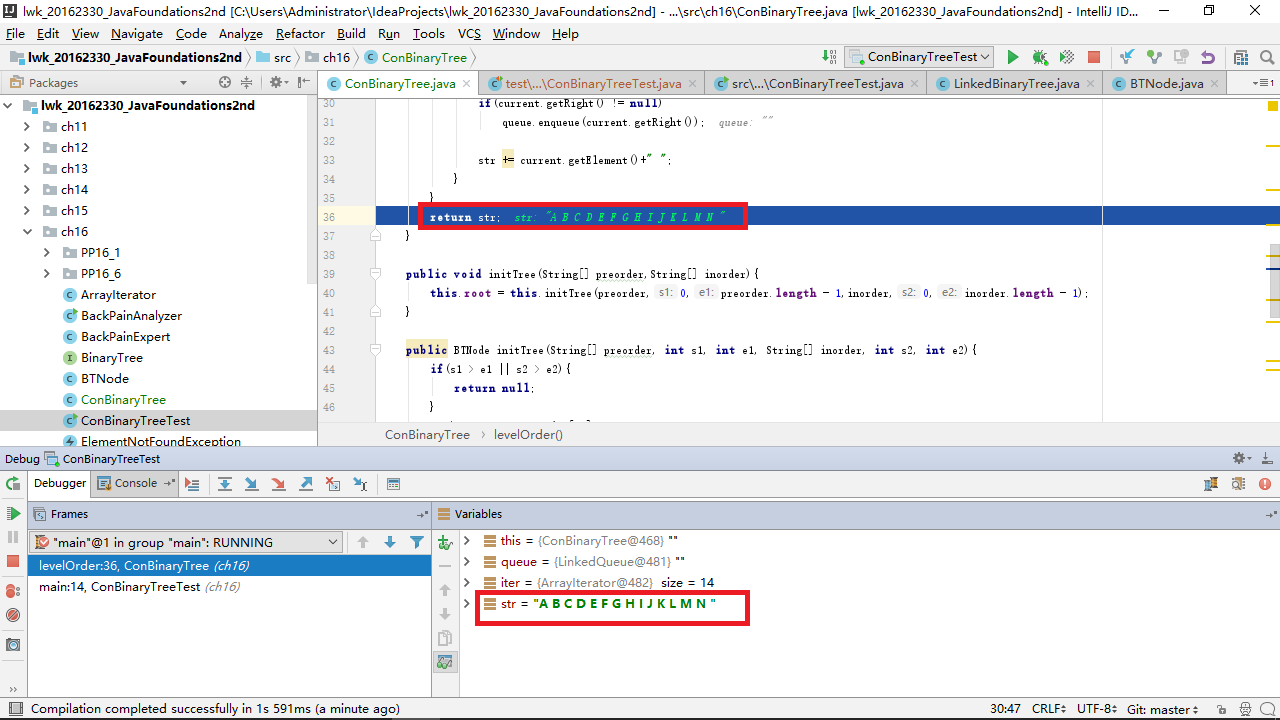
开始时发现 str 变量没有迭代,我加上了,但是输出结果仍然为空。后来我使用debug单步跟踪,结果如下:

从方法开始,一直到返回临时存储的变量,过程没有问题,还有哪部分会出现问题呢?我开始检查我的测试类,果然,这个方法的返回值是String类型的,并不是调用了就可以输出的,在测试类中我只调用了这个方法,并没有输出这个字符串,自然就看不见结果了。只有返回值为空并且内部含有输出语句的方法调用时才可以得到输出结果,在这里就需要添加一个输出语句:

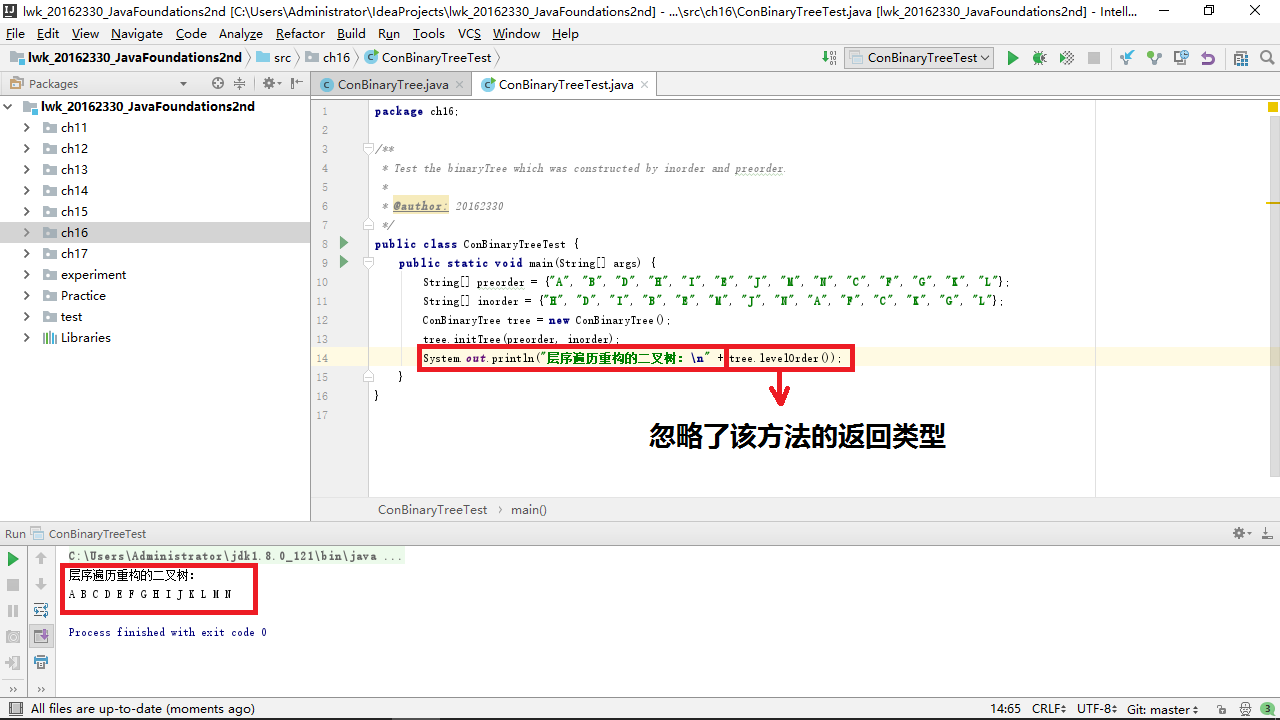
3. 在第五个实验(二叉查找树)中,类声明语句一直报错。

- 解决办法:(询问了几个同学)
我将书中的代码一行一行敲进去,但是类声明一直报错,要么就是抽象方法的类没有实现完全,要么就是这个类要被声明为抽象类,还有的就是继承的方法和实现接口中的方法类型不一样,但是我看了返回值类型是相同的。如果将此类声明为抽象类,那么这个类就失去了原来的意义,我问了几个同学,有的说在实现的接口类中方法声明后面加上throws语句抛出异常,这个问题我后来也遇到过,但不是针对我,IDEA中的提示并没有显示需要抛出异常,于是我就开始自己思考,不断的将继承类中的一些方法重写后又删除,但是不论怎样还是一直报错,好像是在说传入方法的元素的类型不一样,最后还是问了张旭升,张旭升花了一些时间,检查了此类继承和实现的每个类,包括泛型 T 继承的Comparable 类在那些类中有没有被声明,因为这个类声明中的泛型 T 是继承 Comparable 接口的:

public class LinkedBinarySearchTree<T extends Comparable<T>> extends LinkedBinaryTree<T>
implements BinarySearchTree<T>应该将那些没有继承 Comparable 的泛型修改为继承泛型类型,另外,我后来还将结点类的对象统一规定为由 BTNode 类创建的对象,这样确保了元素类型和实现方法类型的一致,于是再次点开这个类时,根据提示又加了几个课本上没有出现的方法,对测试没有太大的影响,之后终于成功了。这种类型的问题有时比较麻烦,需要将实现的接口和继承的类依次排查,但是不论怎样,我都从中学到了一些经验,虽然消耗了一个晚上。
分析总结:
本周的实验主要是考察各种树结构的应用,时间上更宽泛了一些,但是做实验的时候仍然有些匆忙,总的来说,还是呈现一种“前紧后松”的节奏,最后周末有些懈怠,所以将博客拖到现在,实在不应该。但是本次实验的完成质量我觉得比较好,至少前三个实验我测试了很多次,并且从一些问题中又学到了一些经验。
本次实验的不足之处:
(1)完成速度较慢,但是感觉很充实;
(2)做实验的时候就可以将一部分内容写进博客中,不用等到周末再重新总结;
(3)不要沉迷于某个实验太久,做不出来先放放。也希望老师在以后发布蓝墨云班课上的实验任务时能够更明确一点,比如说:这次的第一个实验是测试所有方法还是测试课本中缺少的几个方法?第四个实验要求的表达式树具体要怎么输入,怎么输出?这样可能效果会更好一些,从而避免一些对实验要求的误解。
PSP(Personal Software Process)时间统计:
-
步骤 耗时 百分比 需求分析 40min 10% 设计 40min 10% 代码实现 120min 30% 测试 100min 25% 分析总结 100min 25%
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









