






http://blog.csdn.NET/mdcmy/article/details/38167955?utm_source=tuicool&utm_medium=referral
*******************************************************************************
花了一段时间学习lucene今天有时间把所学的写下来,网上有很多文章但大部分都是2.X和3.X版本的(当前最新版本4.9),希望这篇文章对自己和初学者有所帮助。
学习目录
(1)什么是lucene
(2)lucene常用类详解
(3)lucene简单实例
(4)lucene常用分词器
(5)lucene多条件查询
(6)修改删除索引
(7)lucene优化、排序
(8)lucene高亮显示
(9)lucene分页
(10)lucene注意几点
一、什么是lucene
Lucene是一套用于全文检索和搜寻的开源程式库是全文检索的框架而不是产品(不像百度不同), lucene其实就做两种工作:一入一出。所谓入是写入,即将你提供的源(本质是字符串)写入索引或者将其从索引中删除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源。
百科是这样说的:Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
二、lucene常用类
(1)IndexWriter 索引过程的核心组件。这个类负责创建新索引或者打开已有索引,以及向索引中添加、删除或更新索引文档的信息。可以把IndexWriter看做这样一个对象:提供针对索引文件的写入操作,但不能用于读取或搜索索引。IndexWriter需要开辟一定空间来存储索引,该功能可以由Directory完成。
(2)Diretory 索引存放的位置,它是一个抽象类,它的子类负责具体制定索引的存储路径。lucene提供了两种索引存放的位置,一种是磁盘,一种是内存。一般情况将索引放在磁盘上;相应地lucene提供了FSDirectory和RAMDirectory两个类。
(3)Analyzer 分析器,主要用于分析搜索引擎遇到的各种文本,Analyzer的工作是一个复杂的过程:把一个字符串按某种规则划分成一个个词语,并去除其中的无效词语(停用词),这里说的无效词语如英文中的“of”、“the”,中文中的“的”、“地”等词语,这些词语在文章中大量出现,但是本身不包含什么关键信息,去掉有利于缩小索引文件、提高效率、提高命中率。分词的规则千变万化,但目的只有一个:按语义划分。这点在英文中比较容易实现,因为英文本身就是以单词为单位的,已经用空格分开;而中文则必须以某种方法将连成一片的句子划分成一个个词语。具体划分方法下面再详细介绍,这里只需了解分析器的概念即可。
(4)Document 文档 Document相当于一个要进行索引的单元,可以是文本文件、字符串或者数据库表的一条记录等等,一条记录经过索引之后,就是以一个Document的形式存储在索引文件,索引的文件都必须转化为Document对象才能进行索引。
(5)Field 一个Document可以包含多个信息域,比如一篇文章可以包含“标题”、“正文”等信息域,这些信息域就是通过Field在Document中存储的。
Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要,下面举例说明:还是以刚才的文章为例子,我们需要对标题和正文进行全文搜索,所以我们要把索引属性设置为true,同时我们希望能直接从搜索结果中提取文章标题,所以我们把标题域的存储属性设置为true,但是由于正文域太大了,我们为了缩小索引文件大小,将正文域的存储属性设置为false,当需要时再直接读取文件;我们只是希望能从搜索解果中提取最后修改时间,不需要对它进行搜索,所以我们把最后修改时间域的存储属性设置为true,索引属性设置为false。上面的三个域涵盖了两个属性的三种组合,还有一种全为false的没有用到,事实上Field不允许你那么设置,因为既不存储又不索引的域是没有意义的。
Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要,下面举例说明:还是以刚才的文章为例子,我们需要对标题和正文进行全文搜索,所以我们要把索引属性设置为true,同时我们希望能直接从搜索结果中提取文章标题,所以我们把标题域的存储属性设置为true,但是由于正文域太大了,我们为了缩小索引文件大小,将正文域的存储属性设置为false,当需要时再直接读取文件;我们只是希望能从搜索解果中提取最后修改时间,不需要对它进行搜索,所以我们把最后修改时间域的存储属性设置为true,索引属性设置为false。上面的三个域涵盖了两个属性的三种组合,还有一种全为false的没有用到,事实上Field不允许你那么设置,因为既不存储又不索引的域是没有意义的。
(6)IndexSearcher 是lucene中最基本的检索工具,所有的检索都会用到IndexSearcher工具。
(7)IndexReader打开一个Directory读取索引类。
(8)Query 查询,抽象类,必须通过一系列子类来表述检索的具体需求,lucene中支持模糊查询,语义查询,短语查询,组合查询等等,如有TermQuery,BooleanQuery,RangeQuery,WildcardQuery等一些类。
(9)QueryParser 解析用户的查询字符串进行搜索,是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象。
(10)TopDocs 根据关键字搜索整个索引库,然后对所有结果进行排序,取指定条目的结果。
(11)TokenStream Token 分词器Analyzer通过对文本的分析来建立TokenStreams(分词数据流)。TokenStream是由一个个Token(分词组成的数据流)。所以说Analyzer就代表着一个从文本数据中抽取索引词(Term)的一种策略。
(12)AttributeSource TokenStream即是从Document的域(field)中或者查询条件中抽取一个个分词而组成的一个数据流。TokenSteam中是一个个的分词,而每个分词又是由一个个的属性(Attribute)组成。对于所有的分词来说,每个属性只有一个实例。这些属性都保存在AttributeSource中,而AttributeSource正是TokenStream的父类。
三、lucene简单实例
1、 首先要导入需要的JAR包由于后面会用到其他的包,这里我把所有的包都加进去,关于去那下载大家都知道(apache官网或者从http://download.csdn.net/detail/mdcmy/7683533),包截图如下。
2、定义三个常量
- private String filePath = "F:/myEclipse10/workspace/luceneTest/src/resource.txt";// 源文件所在位置
- private String indexDir = "F:/myEclipse10/workspace/luceneTest/src/index";// 索引目录
- private static final Version VERSION = Version.LUCENE_47;// lucene版本
- /**
- * 创建索引
- *
- * @throws IOException
- */
- @Test
- public void createIndex() throws IOException {
- Directory director = FSDirectory.open(new File(indexDir));// 创建Directory关联源文件
- Analyzer analyzer = new StandardAnalyzer(VERSION);// 创建一个分词器
- IndexWriterConfig indexWriterConfig = new IndexWriterConfig(VERSION, analyzer);// 创建索引的配置信息
- IndexWriter indexWriter = new IndexWriter(director, indexWriterConfig);
- Document doc = new Document();// 创建文档
- String str = fileToString();// 读取txt中内容
- Field field1 = new StringField("title", "lucene测试", Store.YES);// 标题 StringField索引存储不分词
- Field field2 = new TextField("content", str, Store.NO);// 内容 TextField索引分词不存储
- Field field3 = new DoubleField("version", 1.2, Store.YES);// 版本 DoubleField类型
- Field field4 = new IntField("score", 90, Store.YES);// 评分 IntField类型
- doc.add(field1);// 添加field域到文档中
- doc.add(field2);
- doc.add(field3);
- doc.add(field4);
- indexWriter.addDocument(doc);// 添加文本到索引中
- indexWriter.close();// 关闭索引
- }
- /**
- * 查询搜索
- *
- * @throws IOException
- * @throws ParseException
- */
- @Test
- public void query() throws IOException, ParseException {
- IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(indexDir)));// 索引读取类
- IndexSearcher search = new IndexSearcher(reader);// 搜索入口工具类
- String queryStr = "life";// 搜索关键字
- QueryParser queryParser = new QueryParser(VERSION, "content", new StandardAnalyzer(VERSION));// 实例查询条件类
- Query query = queryParser.parse(queryStr);
- TopDocs topdocs = search.search(query, 100);// 查询前100条
- System.out.println("查询结果总数---" + topdocs.totalHits);
- ScoreDoc scores[] = topdocs.scoreDocs;// 得到所有结果集
- for (int i = 0; i < scores.length; i++) {
- int num = scores[i].doc;// 得到文档id
- Document document = search.doc(num);// 拿到指定的文档
- System.out.println("内容====" + document.get("content"));// 由于内容没有存储所以执行结果为null
- System.out.println("标题====" + document.get("title"));
- System.out.println("版本====" + document.get("version"));
- System.out.println("评分====" + document.get("score"));
- System.out.println("id--" + num + "---scors--" + scores[i].score + "---index--" + scores[i].shardIndex);
- }
- }
5、读取文本内容
- /**
- * 读取文件的内容
- *
- * @return
- * @throws IOException
- */
- public String fileToString() throws IOException {
- StringBuffer sb = new StringBuffer();
- InputStream inputStream = new FileInputStream(new File(filePath));
- InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
- BufferedReader br = new BufferedReader(inputStreamReader);
- String line = null;
- while ((line = br.readLine()) != null) {
- sb.append(line);
- }
- br.close();
- inputStreamReader.close();
- inputStream.close();
- return sb.toString();
- }
运行结果:
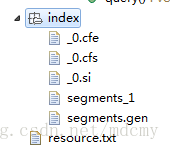
(1)先运行createIndex方法index文件夹下会生成几个文件
(2)运行query方法得出查询的结果
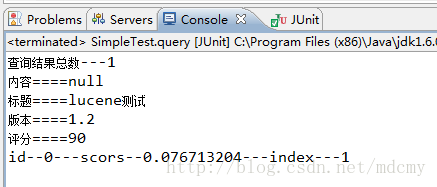
最后附加上resource.txt的内容:ccasionally, life can be undeniably, impossibly difficult. We are faced with challenges and events that can seem overwhelming, life-destroying to the point where it may be hard to decide whether to keep going. But you always have a choice. Jessica Heslop shares her powerful, inspiring journey from the worst times in her life to the new life she has created for herself
四、lucene常用分词器
前面用到StandardAnalyzer分词器这是一个标准分词器,下面介绍另外几个分词器SimpleAnalyzer、CJKAnalyzer、IKAnalyzer对这四个分词器(当然分词器有很多种大家有兴趣可以研究下)结果一一对比。
- public class AnalyzerTest {
- private static final Version VERSION = Version.LUCENE_47;// lucene版本
- @Test
- public void test() throws IOException {
- String txt = "我是中国人";
- Analyzer analyzer1 = new StandardAnalyzer(VERSION);// 标准分词器
- // Analyzer analyzer2 = new SimpleAnalyzer(VERSION);// 简单分词器
- // Analyzer analyzer3 = new CJKAnalyzer(VERSION);// 二元切分
- // Analyzer analyzer4 = new IKAnalyzer(false);// 语意分词
- TokenStream tokenstream = analyzer1.tokenStream("content", new StringReader(txt));// 生成一个分词流
- // TokenStream tokenstream = analyzer2.tokenStream("content", new StringReader(txt));
- // TokenStream tokenstream = analyzer3.tokenStream("content", new StringReader(txt));
- // TokenStream tokenstream = analyzer4.tokenStream("content", new StringReader(txt));
- CharTermAttribute termAttribute = tokenstream.addAttribute(CharTermAttribute.class);// 为token设置属性类
- tokenstream.reset();// 重新设置
- while (tokenstream.incrementToken()) {// 遍历得到token
- System.out.print(new String(termAttribute.buffer(), 0, termAttribute.length()) + " ");
- }
- }
- }
运行结果:
(1)我 是 中 国 人
(2)我是中国人
(3)我是 是中 中国 国人
(4)我 是 中国人 中国 国人
(2)我是中国人
(3)我是 是中 中国 国人
(4)我 是 中国人 中国 国人
从结果上看StandardAnalyzer是把每个字都拆分开了、SimpleAnalyzer没做任何改变、CJKAnalyzer是将相邻的两个字做为一个词、IKAnalyzer从结果上看有一定的语意。
五、lucene多条件查询
利用测试一创建的索引事例多条件查询
- public class MultiseQueryTest {
- private String indexDir = "F:/myEclipse10/workspace/luceneTest/src/index";// 索引目录
- private static final Version VERSION = Version.LUCENE_47;// lucene版本
- /**
- * 多条件查询 查询内容必须包含life内容和评分大于等于80分的结果
- *
- * @throws IOException
- * @throws ParseException
- */
- @Test
- public void query() throws IOException, ParseException {
- IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(indexDir)));// 索引读取类
- IndexSearcher search = new IndexSearcher(reader);// 搜索入口工具类
- String queryStr1 = "life";// 搜索关键字
- BooleanQuery booleanQuery = new BooleanQuery();
- // 条件一内容中必须要有life内容
- QueryParser queryParser = new QueryParser(VERSION, "content", new StandardAnalyzer(VERSION));// 实例查询条件类
- Query query1 = queryParser.parse(queryStr1);
- // 条件二评分大于等于80
- Query query2 = NumericRangeQuery.newIntRange("score", 80, null, true, false);
- booleanQuery.add(query1, BooleanClause.Occur.MUST);
- booleanQuery.add(query2, BooleanClause.Occur.MUST);
- TopDocs topdocs = search.search(booleanQuery, 100);// 查询前100条
- System.out.println("查询结果总数---" + topdocs.totalHits);
- ScoreDoc scores[] = topdocs.scoreDocs;// 得到所有结果集
- for (int i = 0; i < scores.length; i++) {
- int num = scores[i].doc;// 得到文档id
- Document document = search.doc(num);// 拿到指定的文档
- System.out.println("内容====" + document.get("content"));// 由于内容没有存储所以执行结果为null
- System.out.println("标题====" + document.get("title"));
- System.out.println("版本====" + document.get("version"));
- System.out.println("评分====" + document.get("score"));
- System.out.println("id--" + num + "---scors--" + scores[i].score + "---index--" + scores[i].shardIndex);
- }
- }
- }
BooleanClause用于表示布尔查询子句关系的类,包括:BooleanClause.Occur.MUST,BooleanClause.Occur.MUST_NOT,BooleanClause.Occur.SHOULD。有以下6种组合:
1.MUST和MUST:取得连个查询子句的交集。
2.MUST和MUST_NOT:表示查询结果中不能包含MUST_NOT所对应得查询子句的检索结果。
3.MUST_NOT和MUST_NOT:无意义,检索无结果。
4.SHOULD与MUST、SHOULD与MUST_NOT:SHOULD与MUST连用时,无意义,结果为MUST子句的检索结果。与MUST_NOT连用时,功能同MUST。
5.SHOULD与SHOULD:表示“或”关系,最终检索结果为所有检索子句的并集。
1.MUST和MUST:取得连个查询子句的交集。
2.MUST和MUST_NOT:表示查询结果中不能包含MUST_NOT所对应得查询子句的检索结果。
3.MUST_NOT和MUST_NOT:无意义,检索无结果。
4.SHOULD与MUST、SHOULD与MUST_NOT:SHOULD与MUST连用时,无意义,结果为MUST子句的检索结果。与MUST_NOT连用时,功能同MUST。
5.SHOULD与SHOULD:表示“或”关系,最终检索结果为所有检索子句的并集。
对于多条件查询还有其他的一些实现类比如 MultiFieldQueryParser.parse()来创建一个Query有多个参数,比较简单查下api就能明白。
运行结果: 前后对比
前后对比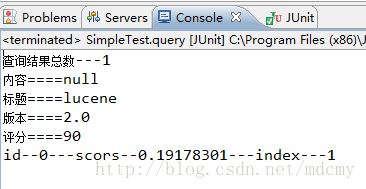
注意:(1)所谓的更新索引是分两步进行的:先删除然后再添加索引,添加的索引占用删除前索引的位置;如果在删除索引时lucene在索引文件中找不到相应的数据,就会在索引文件的最后面添加新的索引。
删除索引就比较简单了,直接找到对应的字段域调用deleteDocuments方法。
(2)排序lucene lucene默认情况下是根据“评分机制”来进行排序的,也就是scores[i].score属性值。如果两个文档得分相同,那么就按照发布时间倒序排列;否则就按照分数排列。
首先看下默认情况下排序结果:

运行结果:

选择结果: lucene的分页有两种方式:(1)查询出所有结果然后进行分布。(2)通过TopScoreDocCollector.topDocs(int num1,int num2)来实现分页。
lucene的分页有两种方式:(1)查询出所有结果然后进行分布。(2)通过TopScoreDocCollector.topDocs(int num1,int num2)来实现分页。
六、修改删除索引
同样利用测试一创建的索引。
(1)更新索引
- /**
- * 修改索引
- *
- * @throws IOException
- */
- @Test
- public void updateIndex() throws IOException {
- Directory director = FSDirectory.open(new File(indexDir));// 创建Directory关联源文件
- Analyzer analyzer = new StandardAnalyzer(VERSION);// 创建一个分词器
- IndexWriterConfig indexWriterConfig = new IndexWriterConfig(VERSION, analyzer);// 创建索引的配置信息
- IndexWriter indexWriter = new IndexWriter(director, indexWriterConfig);
- Document doc = new Document();// 创建文档
- Field field1 = new StringField("title", "lucene", Store.YES);// 标题 StringField索引存储不分词
- Field field2 = new TextField("content", "Is there life on Mars", Store.NO);// 内容 TextField索引分词不存储
- Field field3 = new DoubleField("version", 2.0, Store.YES);// 版本 DoubleField类型
- Field field4 = new IntField("score", 90, Store.YES);// 评分 IntField类型
- doc.add(field1);// 添加field域到文档中
- doc.add(field2);
- doc.add(field3);
- doc.add(field4);
- indexWriter.updateDocument(new Term("title", "lucene测试"), doc);
- indexWriter.commit();
- indexWriter.close();
- }
前后对比注意:(1)所谓的更新索引是分两步进行的:先删除然后再添加索引,添加的索引占用删除前索引的位置;如果在删除索引时lucene在索引文件中找不到相应的数据,就会在索引文件的最后面添加新的索引。
(2)如果我把indexWriter.updateDocument(new Term("title", "lucene测试"), doc);换成indexWriter.updateDocument(new Term("title"), doc);的话同样是新创建索引。
(3)更新索引时必须把其他的字段域都加上否则你只是创建了你添加了的字段域索引。例如你只添加了title字段域,在查询时其他的字段都会查不到。
(2)删除索引
- /**
- * 删除索引
- *
- * @throws IOException
- */
- @Test
- public void deleteIndex() throws IOException {
- Directory director = FSDirectory.open(new File(indexDir));// 创建Directory关联源文件
- Analyzer analyzer = new StandardAnalyzer(VERSION);// 创建一个分词器
- IndexWriterConfig indexWriterConfig = new IndexWriterConfig(VERSION, analyzer);// 创建索引的配置信息
- IndexWriter indexWriter = new IndexWriter(director, indexWriterConfig);
- indexWriter.deleteDocuments(new Term("title", "lucene"));
- indexWriter.commit();
- // indexWriter.rollback();
- indexWriter.close();
- }
删除索引就比较简单了,直接找到对应的字段域调用deleteDocuments方法。
注意:网上有很多说在以前的版本可以能过IndexWriter.undeleteAll()恢复已删除的版本,在4.7中已经没有这个方法了,要想恢复只有通过indexWriter.rollback();有点像数据库中的事务。但有个疑问不解:IndexWriter.forceMergeDeletes();在之前版本是删除已经删除的索引删除回收站的文件,但在4.7中还有这个方法,已经没有undeleteAll方法了那forceMergeDeletes方法又起什么作用呢?
七、lucene优化、排序
(1)优化lucene能过forceMerge方法来将当小文件达到多少个时,就自动合并多个小文件为一个大文件,因为它的使用代价较高不意见使用此方法,默认情况下lucene会自己合并。
- /**
- * 优化
- *
- * @throws IOException
- */
- @Test
- public void optimize() throws IOException {
- Directory director = FSDirectory.open(new File(indexDir));// 创建Directory关联源文件
- Analyzer analyzer = new StandardAnalyzer(VERSION);// 创建一个分词器
- IndexWriterConfig indexWriterConfig = new IndexWriterConfig(VERSION, analyzer);// 创建索引的配置信息
- IndexWriter indexWriter = new IndexWriter(director, indexWriterConfig);
- indexWriter.forceMerge(1);// 当小文件达到多少个时,就自动合并多个小文件为一个大文件
- indexWriter.close();
- }
修改下创建索引的方法如下:
- /**
- * 创建索引
- *
- * @throws IOException
- */
- @Test
- public void createIndex() throws IOException {
- Directory director = FSDirectory.open(new File(indexDir));// 创建Directory关联源文件
- Analyzer analyzer = new StandardAnalyzer(VERSION);// 创建一个分词器
- IndexWriterConfig indexWriterConfig = new IndexWriterConfig(VERSION, analyzer);// 创建索引的配置信息
- IndexWriter indexWriter = new IndexWriter(director, indexWriterConfig);
- for (int i = 1; i <= 5; i++) {
- Document doc = new Document();// 创建文档
- Field field1 = new StringField("title", "标题" + i, Store.YES);// 标题 StringField索引存储不分词
- Field field2 = new TextField("content", "201" + i + "文章内容", Store.NO);// 内容 TextField索引分词不存储
- Field field3 = new DoubleField("version", 1.2, Store.YES);// 版本 DoubleField类型
- Field field4 = new IntField("score", 90 + i, Store.YES);// 评分 IntField类型
- Field field5 = new StringField("date", "2014-07-0" + i, Store.YES);// 评分 IntField类型
- doc.add(field1);// 添加field域到文档中
- doc.add(field2);
- doc.add(field3);
- doc.add(field4);
- doc.add(field5);
- indexWriter.addDocument(doc);// 添加文本到索引中
- }
- indexWriter.close();// 关闭索引
- }
首先看下默认情况下排序结果:
- /**
- * 排序
- *
- * @throws IOException
- * @throws ParseException
- */
- @Test
- public void defaultSortTest() throws IOException, ParseException {
- IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(indexDir)));// 索引读取类
- IndexSearcher search = new IndexSearcher(reader);// 搜索入口工具类
- String queryStr = "文章";// 搜索关键字
- QueryParser queryParser = new QueryParser(VERSION, "content", new StandardAnalyzer(VERSION));// 实例查询条件类
- Query query = queryParser.parse(queryStr);
- TopDocs topdocs = search.search(query, 100);// 查询前100条
- System.out.println("查询结果总数---" + topdocs.totalHits);
- ScoreDoc scores[] = topdocs.scoreDocs;// 得到所有结果集
- for (int i = 0; i < scores.length; i++) {
- int num = scores[i].doc;// 得到文档id
- Document document = search.doc(num);// 拿到指定的文档
- System.out.println("内容====" + document.get("content"));// 由于内容没有存储所以执行结果为null
- System.out.println("标题====" + document.get("title"));
- System.out.println("版本====" + document.get("version"));
- System.out.println("评分====" + document.get("score"));
- System.out.println("日期====" + document.get("date"));
- System.out.println("id--" + num + "---scors--" + scores[i].score + "---index--" + scores[i].shardIndex);
- }
- }
- }
五个文章评分相同会那么就按照发布时间倒序排列。
接下来根据字段score域降序排序,只需修改两行代码。
- Sort sort = new Sort(new SortField("score", SortField.Type.INT, true));// false升序true降序
- TopDocs topdocs = search.search(query, 100, sort);// 查询前100条
运行结果:
八、lucene高亮显示
高亮显示,就是根据用户输入的检索关键字,检索找到该关键字对应的检索结果文件,提取对应于该文件的摘要文本,然后根据设置的高亮格式,将格式写入到摘要文本中对应的与关键字相同或相似的词条上,在网页上显示出来,该摘要中的与关键字有关的文本就会以高亮的格式显示出来。
高亮显示需要几个实现类:
(1)Fragmenter接口。作用是将原始字符串拆分成独立的片段。有三个实现类: NullFragmenter 是该接口的一个具体实现类,它将整个字符串作为单个片段返回,这适合于处理title域和前台文本较短的域,而对于这些域来说,我们是希望在搜索结果中全部展示。SimpleFragmenter 是负责将文本拆分封固定字符长度的片段,但它并处理子边界。你可以指定每个片段的字符长度(默认情况100)但这类片段有点过于简单,在创建片段时,他并不限制查询语句的位置,因此对于跨度的匹配操作会轻易被拆分到两个片段中; SimpleSpanFragmenter 是尝试将让片段永远包含跨度匹配的文档。
(2)Scorer接口。Fragmenter输出的是文本片段序列,而Highlighter必须从中挑选出最适合的一个或多个片段呈现给客户,为了做到这点,Highlighter会要求Scorer来对每个片段进行评分。有两个实现类:QueryTermScorer 基于片段中对应Query的项数进行评分。QueryScorer只对促成文档匹配的实际项进行评分。
(3)Formatter接口。它负责将片段转换成String形式,以及将被高亮显示的项一起用于搜索结果展示以及高亮显示。有两个类:SimpleHTMLFormatter简单的html格式。GradientFormatter复杂型式对不同的得分实现不同的样式。
(1)Fragmenter接口。作用是将原始字符串拆分成独立的片段。有三个实现类: NullFragmenter 是该接口的一个具体实现类,它将整个字符串作为单个片段返回,这适合于处理title域和前台文本较短的域,而对于这些域来说,我们是希望在搜索结果中全部展示。SimpleFragmenter 是负责将文本拆分封固定字符长度的片段,但它并处理子边界。你可以指定每个片段的字符长度(默认情况100)但这类片段有点过于简单,在创建片段时,他并不限制查询语句的位置,因此对于跨度的匹配操作会轻易被拆分到两个片段中; SimpleSpanFragmenter 是尝试将让片段永远包含跨度匹配的文档。
(2)Scorer接口。Fragmenter输出的是文本片段序列,而Highlighter必须从中挑选出最适合的一个或多个片段呈现给客户,为了做到这点,Highlighter会要求Scorer来对每个片段进行评分。有两个实现类:QueryTermScorer 基于片段中对应Query的项数进行评分。QueryScorer只对促成文档匹配的实际项进行评分。
(3)Formatter接口。它负责将片段转换成String形式,以及将被高亮显示的项一起用于搜索结果展示以及高亮显示。有两个类:SimpleHTMLFormatter简单的html格式。GradientFormatter复杂型式对不同的得分实现不同的样式。
- /**
- * 高亮
- *
- * @throws IOException
- * @throws ParseException
- * @throws InvalidTokenOffsetsException
- */
- @Test
- public void highlighter() throws IOException, ParseException, InvalidTokenOffsetsException {
- IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(indexDir)));// 索引读取类
- IndexSearcher search = new IndexSearcher(reader);// 搜索入口工具类
- Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_47);// 分词器
- QueryParser qp = new QueryParser(Version.LUCENE_47, "content", analyzer);// 实例查询条件类
- Query query = qp.parse("文章");
- TopDocs topDocs = search.search(query, 100);// 查询前100条
- System.out.println("共查询出:" + topDocs.totalHits + "条数据");
- ScoreDoc scoreDoc[] = topDocs.scoreDocs;// 结果集
- // 高亮
- Formatter formatter = new SimpleHTMLFormatter("<font color='red'>", "</font>");// 高亮html格式
- Scorer score = new QueryScorer(query);// 检索评份
- Fragmenter fragmenter = new SimpleFragmenter(100);// 设置最大片断为100
- Highlighter highlighter = new Highlighter(formatter, score);// 高亮显示类
- highlighter.setTextFragmenter(fragmenter);// 设置格式
- for (int i = 0; i < scoreDoc.length; i++) {// 遍历结果集
- int docnum = scoreDoc[i].doc;
- Document doc = search.doc(docnum);
- String content = doc.get("content");
- System.out.println(content);// 原内容
- if (content != null) {
- TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(content));
- String str = highlighter.getBestFragment(tokenStream, content);// 得到高亮显示后的内容
- System.out.println(str);
- }
- }
- }
选择结果:
九、lucene分页
- /**
- * 分页
- *
- * @throws IOException
- * @throws ParseException
- */
- @Test
- public void pageTest() throws IOException, ParseException {
- IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(indexDir)));// 索引读取类
- IndexSearcher search = new IndexSearcher(reader);// 搜索入口工具类
- String queryStr = "文章";// 搜索关键字
- QueryParser queryParser = new QueryParser(VERSION, "content", new StandardAnalyzer(VERSION));// 实例查询条件类
- Query query = queryParser.parse(queryStr);// 查询
- TopScoreDocCollector results = TopScoreDocCollector.create(100, false);// 结果集
- search.search(query, results);// 查询前100条
- TopDocs topdocs = results.topDocs(1, 2);// 从结果集中第1条开始取2条
- ScoreDoc scores[] = topdocs.scoreDocs;// 得到所有结果集
- for (int i = 0; i < scores.length; i++) {
- int num = scores[i].doc;// 得到文档id
- Document document = search.doc(num);// 拿到指定的文档
- System.out.println("内容====" + document.get("content"));// 由于内容没有存储所以执行结果为null
- System.out.println("标题====" + document.get("title"));
- System.out.println("版本====" + document.get("version"));
- System.out.println("评分====" + document.get("score"));
- System.out.println("id--" + num + "---scors--" + scores[i].score + "---index--" + scores[i].shardIndex);
- }
- }
十、lucene注意几点
其实任何好的框架都有他的缺陷,lucene也不例外,下面这几点是网上找的也是我们开发中要注意的地方。1、lucene的索引不能太大,要不然效率会很低。大于1G的时候就必须考虑分布索引的问题
2、不建议用多线程来建索引,产生的互锁问题很麻烦。经常发现索引被lock,无法重新建立的情况
3、中文分词是个大问题,目前免费的分词效果都很差。如果有能力还是自己实现一个分词模块,用最短路径的切分方法,网上有教材和demo源码,可以参考。
4、建增量索引的时候很耗cpu,在访问量大的时候会导致cpu的idle为0
5、默认的评分机制不太合理,需要根据自己的业务定制
整体来说lucene要用好不容易,必须在上述方面扩充他的功能,才能作为一个商用的搜索引擎。
最后附加上实例代码下载地址:点击打开链接















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









