






网络爬虫爬行过程中,会爬到一些新的URL,对这些 URL 爬取的顺序,是由爬行策略来决定的
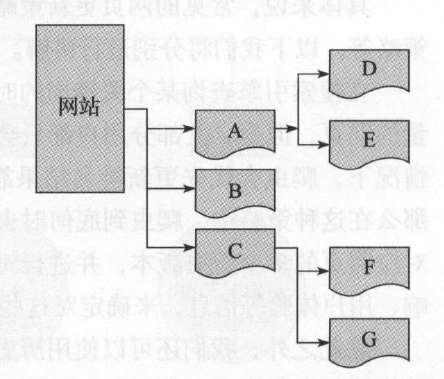
(1) 深度优先爬行策略:先爬取一个网页,然后将这个网页的下层链接依次爬取完再返回上一层进行爬取,如下图,爬取的顺序是 A → D → E → B → C → F → G
(2) 广度优先爬行策略:先爬取同一层次的网页,同一层次的网页爬取完之后再选择下一个层次的网页进行爬取,如下图,爬取的顺序是 A → B → C → D → E → F → G
(3) 大站优先爬行策略:按照网页所属的站点进行归类,如果某个网站的网页数量多,就称其为大站,优先爬取
(4) 反链爬行策略:反链指的是该网页被其他网页指向的次数,这个次数在一般程度上代表着该网页被推荐的次数,因此反链数量多的被优先爬取














 8673
8673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









