






一、MCMC 简介
1. Monte Carlo 蒙特卡洛
蒙特卡洛方法(Monte Carlo)是一种通过特定分布下的随机数(或伪随机数)进行模拟的方法。典型的例子有蒲丰投针、定积分计算等等,其基础是大数定律。
蒙特卡洛方法有哪些优缺点如下:
- 优点:计算准确性由采样的均匀程度决定;大大简化问题复杂性
- 缺点:
- 由于要进行大量的抽样计算,对计算机速度依赖性强
- 目前绝大多数随机数发生器均为伪随机数,一定程度上有偏
- 定积分求解问题中,对于\(\color{blue}{复杂或者高维的分布}\),利用蒙特卡洛方法生成随机样本非常困难
蒙特卡罗方法在金融工程学,宏观经济学,生物医学,计算物理学(如粒子输运计算、量子热力学计算、空气动力学计算、核工程)等领域应用广泛。
2. 随机数生成算法简介
2.1 均匀分布随机数生成
均匀分布随机数生成最普遍的算法为线性同余算法(LCG),他是一个伪随机数发生器,默认的初始种子为系统时间戳,算法递推公式如下:
\[ X_{i+1} = (A \times X_{i} + B) mod M \]
其中:
- \(B, M\)互质
- M的所有质因子的积能整除\((A-1)\):比如M是3的倍数则\((A-1)\)也是
- \(A, B, X_0\)都比\(M\)小
- \(A,B\)是正整数
python代码如下:
import matplotlib.pyplot as plt
import time
import math
def random(num = 2000):
M = 1000
A = 3^4
B = 1
x_0 = time.time()
result = [x_0]
while len(result) < num:
result.append((result[-1]*A+B) % M)
result.pop(0)
return result
result = random(2000)
xaixs = [i for i,j in enumerate(result)]
print result[:10]
f = plt.figure(1)
p1 = plt.scatter(xaixs,result)
#p2 = plt.hist(result)
plt.show()
目前纯的随机数生成算法非常的复杂,而且性能消耗非常的大,所以在此不做介绍。
2.2 标准正态分布随机数生成
已知均匀分布随机数如何生成,我么可以根据其生成标准正态分布随机数,Box和Muller(1958) (G. E. P. Box and Mervin E. Muller, A Note on the Generation of Random Normal Deviates, The Annals of Mathematical Statistics (1958), Vol. 29, No. 2 pp. 610–611)提出了产生\(N(0,1)\)随机数的简单方法:设\(U_1,U_2\)是独立同分布的\(U(0,1)\)变量,记:
\[ \begin{cases} X_1 = (-2 lnU_1)^{1/2}cos(2\pi U_2) \\ X_2 = (-2 lnU_2)^{1/2}cos(2\pi U_1) \end{cases} \]
则\(X_1\)和\(X_2\)相互独立且均服从标准正态分布。python代码如下:
import matplotlib.pyplot as plt
import time
import math
def rnorm(num = 1000):
uniform1 = random(num)
uniform2 = random(num)
return [math.sqrt(-2*math.log(i/1000,math.e))*math.cos(2*math.pi*j/1000) for i,j in zip(uniform1,uniform2)]
result = rnorm()
xaixs = [i for i,j in enumerate(result)]
f = plt.figure(1)
#p1 = plt.scatter(xaixs,result)
p2 = plt.hist(result)
plt.show()2.3 其他简单分布随机数生成
对于已知pdf或是cdf的分布,可以根据cdf求反函数的方法来生成该分布的随机数。因为cdf值域为\([0,1]\),我们只需要获得均匀分布随机数\(U_1 \sim U(0,1)\),即可根据反函数\(cdf^{-1}\)得到此次抽得的随机数。对于再复杂一点的分布,我们可以通过构造包络分布进行Rejection Sampling,如ARS和ARMS算法等等。
3. Markov Chain 马尔科夫链
在蒙特卡洛模拟中,我们在后验分布中抽取样本,当这些样本独立时,利用大数定律样本均值会收敛到期望值。如果得到的样本是不独立的,那么就要借助于马尔科夫链进行抽样。马尔科夫链又称为马尔科夫过程是一种离散的随机过程,随机过程可以看做一个随时间变化的随机变量序列。
对一个马尔科夫链来说,未来状态只与当前t时刻有关,而与t时刻之前的历史状态无关。马尔科夫链的每个状态的状态转移概率构成了其状态转移矩阵\(P\)
** 当步长\(n\)足够大时,一个非周期且任意状态联通的马氏链可以收敛到一个平稳分布\(\pi(x)\) **,马氏链收敛定理是MCMC的基础。
二、Sampling Algorithm 抽样算法
1. MCMC与M-H算法
MCMC方法就是构造合适的马尔科夫链进行抽样而使用蒙特卡洛方法进行积分计算。 既然马尔科夫链可以收敛到平稳分布。我们可以建立一个以\(\pi\)为平稳分布的马尔科夫链,对这个链运行足够长时间之后,可以达到平稳状态。此时马尔科夫链的值就相当于在分布\(\pi(x)\)中抽取样本。利用马尔科夫链进行随机模拟的方法就是MCMC。
MCMC的主要问题是:如何构造转移矩阵\(P\),使得平稳分布恰好是我们要的分布\(\pi (x)\)。由此,我们首先有了M-H算法,它用到可马尔科夫链的另一个性质,如果具有转移矩阵\(P\)和分布\(\pi(x)\)的马氏链对所有的状态\(i,j\)满足下面的等式:
\[ \pi(i)P(i,j) = \pi(j)P(j,i) \]
这个等式称为细致平衡方程,此时该马氏链的分布\(\pi(x)\)是平稳的。一般情况下,任意给的\(\pi(x)\)不一定平稳,那么可以构造函数\(\alpha(i,j)\),使得:
\[ \pi(i)P(i,j)\alpha(i,j) = \pi(j)P(j,i)\alpha(j,i) \]
此时取\(\alpha(i,j) = \pi(j)P(j,i)\),\(\alpha(j,i) = \pi(i)P(i,j)\)时等式(2)必然成立。
(2)式中的\(\alpha(i,j)\)又叫接受率,是接受状态从\(i\)转移到\(j\)的概率。如果\(\alpha\)过小,将会导致频繁拒绝转移,马氏链难以收敛,所以我们考虑放大\(\alpha\),使得\(\alpha(i,j)\)和\(\alpha(j,i)\)中大的值为\(1\),小的值同比放大为\(\frac{\pi(j)P(j,i)}{\pi(i)P(i,j)}\),那么\(\alpha(i,j) = min\{1,\frac{\pi(j)P(j,i)}{\pi(i)P(i,j)}\}\)。在马尔科夫链状态转移过程中,我们以概率\(\alpha(i,j)\)接受转移,从而得到最终的稳定分布,这种算法称为M-H算法。
M-H算法需要提前构造提议分布(proposal distribution)\(\pi(x)\),然后经过提议分布采样后计算出接受概率,对采样进行接受或是拒绝,最后得到服从特定分布的样本。优点是通过构造精妙的马尔科夫链,提高了抽样的效率,尤其是面对条件分布抽样时。缺点是需要找到合适的提议分布,而且收敛速度可能较慢。
现欲对自由度为5的t分布抽取10000个样本,我们分别用M-H算法和R语言自带的t分布抽样命令rt进行抽样,然后对比二者结果。
对于M-H抽样,我们选择标准正态分布为其提议分布,进行10000次模拟,R语言代码和得到结果如下:
ptm <- proc.time()
#### M-H algorithm ####
N = 10000
x = vector(length = N)
x[1] = 0
# uniform variable: u
u = runif(N)
sd = 1
df = 5
# sample the student distrubution with 5 freedom
for (i in 2:N) {
y = rnorm(1,mean = x[i-1],sd = sd)
p_accept = dt(y,df) * pnorm(x[i-1],y,sd) / pnorm(x[i-1],y,sd) / (dt(x[i-1],df))
if ((u[i] <= p_accept))
{ x[i] = y }
else
{ x[i] = x[i-1] }
}
HM_result <- x
proc.time()-ptm
#plot(x,type = 'l')
test = rt(10000,5)
par(mfrow=c(2,2))
hist(test)
plot(density(test),main = "density of test dataset")
hist(HM_result)
plot(density(HM_result),main = "density of MH result") 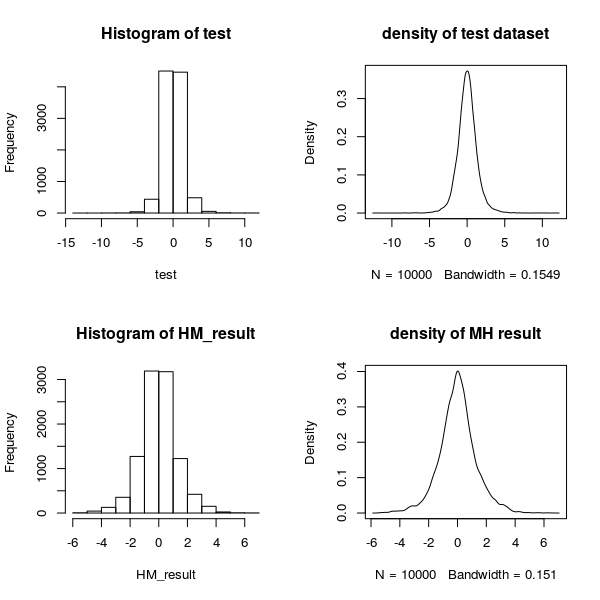
2. Gibbs抽样
M-H抽样在较低维度值运算中是比较方便的,然而在维数较高时,选择适当的提议分布并非易事,而Gibbs抽样仅仅需要了解满条件分布(full conditi- onal distribution),因此在高维积分时更具有优势(朱慧明 等, 《贝叶斯计量经济模型》, 2009,科学出版社)。
n维变量的Gibbs抽样方法如下:给定抽样初始点\(x^{(0)} = (x_1^{(0)},x_2^{(0)},...,x_n^{(0)}\) \()\),并假设第\(t-1\)次迭代的迭代值为\(x^{(t-1)}\),则第\(t\)次迭代由以下步骤完成:
- 由满条件分布\(\pi(x_1 | x_2^{(t-1)},...,x_n^{(t-1)})\)抽取\(x_1^{(t)}\)
- 由满条件分布\(\pi(x_2 | x_1^{(t-1)},x_3^{(t-1)}...,x_n^{(t-1)})\)抽取\(x_2^{(t)}\)
- ... ...
- 由满条件分布\(\pi(x_n | x_1^{(t-1)},...,x_{n-1}^{(t-1)})\)抽取\(x_n^{(t)}\)
至此完成\(t-1\)到\(t\)的一次迭代,重复迭代直到\(x^{(t)}\)分布稳定后即可。
Gibbs抽样实例
以二维正态分布抽样为例,不妨设\(X = (X_1,X_2)\)服从二元正态分布,即:
\[ \begin{eqnarray} x \sim N \left( \begin{pmatrix} 0 \\ 0 \end{pmatrix} , \begin{pmatrix} 1 & \rho \\ \rho & 1 \end{pmatrix} \right),\ 0<\rho\le1 \end{eqnarray} \]
则有:
- $x_2^{(t+1)}| x_1^{(t+1)} \sim N(\rho x_1^{t+1},1-\rho^2) $
- \(x_1^{(t+1)} | x_2^{(t+1)} \sim N(\rho x_2^{t+1},1-\rho^2)\)
并且可以证明:
\[ \begin{eqnarray} \begin{pmatrix} x_1^{(t)} \\ x_2^{(t)} \end{pmatrix} \sim N \left( \begin{pmatrix} \rho^{2t-1}x_1^{(0)} \\ \rho^{2t}x_2^{(0)} \end{pmatrix} , \begin{pmatrix} 1 - \rho^{4t-2} & \rho - \rho^{4t-1} \\ \rho - \rho^{4t-1} & 1 - \rho^{4t} \end{pmatrix} \right) \end{eqnarray} \]
当\(t \to \infty\)时,\((x_1^{t},x_2^{t})\)的分布将收敛到目标分布。R语言代码和结果如下:
n <- 5000 #抽样个数
n_1 <- 2500 # 收敛个数
X <- matrix(0, n, 2)
mu1 <- 0
mu2 <- 0
sigma1 <- 1
sigma2 <- 1
rho <- 0.5
s1.c <- sqrt(1 - rho^2) * sigma1
s2.c <- sqrt(1 - rho^2) * sigma2
X[1, ] <- c(mu1, mu2) #初始化
for (i in 2:n) {
x2 <- X[i - 1, 2]
m1.c <- mu1 + rho * (x2 - mu2) * sigma1/sigma2
X[i, 1] <- rnorm(1, m1.c, s1.c)
x1 <- X[i, 1]
m2.c <- mu2 + rho * (x1 - mu1) * sigma2/sigma1
X[i, 2] <- rnorm(1, m2.c, s2.c)
}
b <- n_1 + 1
x.mcmc <- X[b:n, ]
library(MASS)
MVN.kdensity <- kde2d(x.mcmc[, 1], x.mcmc[, 2], h = 5) #估计核密度
par(mfrow=c(2,2))
plot(x.mcmc, col = "blue", xlab = "X1", ylab = "X2") #绘制二元正态分布等高线图
contour(MVN.kdensity, add = TRUE)
hist(x.mcmc[, 1],main = "histogram of x1")
hist(x.mcmc[, 2],mian = "histogram of x2")
x<-y<-seq(-4,4,length=20)
f<-function(x,y){(exp(-0.5*x^2-0.5*y^2))/(2*pi)}
z<-outer(x,y,f)
persp(x,y,z,theta=45,phi=25,col='lightblue') 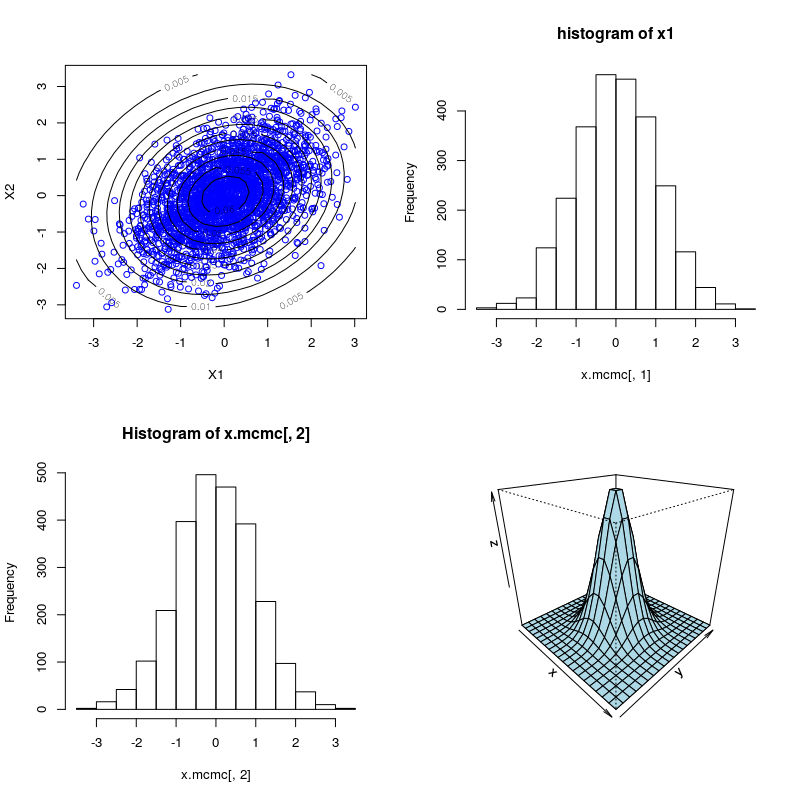
三、MCMC和线性回归模型
当我们讨论贝叶斯估计方法和线性回归模型时,会包括:
- \(\beta\)的先验分布
- \(\sigma\)的先验分布
给定一元线性回归模型:
\[ Y_i = \beta_0 + \beta_1 X_i + \epsilon_i \]
我们将其中心化,变为:
\[ \begin{eqnarray} Y_i &=& \beta_0^{*} + \beta_1 (X_i - \bar{X}) + \epsilon_i \\ Y_i &=& \beta_0^{*} - \beta_1 \bar{X} + \beta_1 X_i + \epsilon_i \end{eqnarray} \]
这样变化后,我们发现\(\beta_1\)是不变的,由于\(X\)的扰动没变而\(\bar{X}\)无扰动。而\(\beta_0\)的期望相对增加了,有\(E(\beta_0) = \bar{Y}\),且自变量\(X_i - \bar{X}\)均值为0。这样模型的极大似然值可以写成:
\[ y_i | x_i,\beta_0,\beta_1,\sigma^2 \sim N(\beta_0 + \beta_1(x_i - \bar{x}),\sigma^2),i = 1,2,...,n \]
贝叶斯模型充分利用样本的先验信息,对于中心化一元线性模型(5)式, 我们有先验信息:
\[ p(\beta_0, \beta_1,\sigma^2) \propto \frac{1}{\sigma^2},-\infty < \beta_0,\beta_1 < \infty,0<\sigma^2<\infty \]
同时我们有三个充分统计量:
\[ \begin{eqnarray} \nonumber \hat{\beta_0} &=& \bar{y} \\ \nonumber \hat{\beta_1} &=& \frac{\sum_{i} (x_i - \bar{x})(y_i - \bar{y})}{\sum_i (x_i - \bar{x})^2} \\ \nonumber s^2 & =& \frac{SSR}{n-2} = \frac{\sum_{i} (y_i - \hat{\beta_0} - \hat{\beta_1}(x_i - \bar{x})^2)}{n-2} \end{eqnarray} \]
根据这三个充分统计量、先验分布、极大似然函数,我们可以求得联合后验分布\(p(\beta_0, \beta_1,\sigma^2|y)\)\footnote{Applied Bayesian Statistics with R and OpenBUGS, 187-190}
之后求得三个参数各自的边缘后验密度分布:
\[ \begin{eqnarray} \beta_0|y &\sim& t(\hat{\beta_0},\frac{s^2}{n},n-2) \\ \beta_1|y &\sim& t(\hat{\beta_1},\frac{s^2}{\sum (x_i - \bar{x})^2},n-2) \\ \sigma^2 | y &\sim& IG (\frac{n-2}{2},\frac{(n-2)s^2}{2}) \end{eqnarray} \]
其中\(\beta_0,\beta_1\)的后验分布服从含位置和尺度参数的t分布\footnote{if \(X \sim t(\mu,\sigma^2,freedom)\),then \((X - \mu) / \sigma^2 \sim t(freedom)\)};而\(\sigma^2\)服从逆伽马分布。
得到参数的后验分布之后,我们就可以利用MCMC进行模拟并且收敛到最后的估计值。具体步骤如下:
- 参数赋予初始值(直接影响收敛速度) \(\beta_0^{(0)},\beta_1^{(0)},\sigma^2{(0)}\)
- 根据公式(5)更新\(\beta_0\),其中\(\sigma^2 = (n-2) s /n\)
- 根据公式(6) 和公式(7)更新\(\beta_1,\sigma^2\)
- 重复(2) - (4) N轮,并观察三个参数的收敛情况,从而得到稳健的估计值














 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









