






面向对象设计与构造已进行了三次表达式求导的作业。是时候做个总结(了结)了。。。
一. 三次作业的程序结构分析
第一次作业是简单多项式求导,即只含底数为x的指数函数相加减构成的表达式。第一步是要获取输入并对错误的输入格式给出反馈。利用正则表达式能很容易解决这一内容,只不过对第一项要单独考虑(但正则的使用有利有弊,见第二部分),这一部分我放在了MainClass中进行处理。相应正则如下,firstMatch为第一项的正则,nextMatch为其余项的正则,匹配完一项将它从源字符串中移除匹配下一项。
1 firstMatch = "\\s*[-+]?\\s*[-+]?\\d+\\s*|\\s*[-+]?\\s*[-+]?\\d+\\s*\\*\\s*x\\s*(\\^\\s*[-+]?\\d+\\s*)?|\\s*[-+]?\\s*[-+]?\\s*x\\s*(\\^\\s*[-+]?\\d+\\s*)?" 2 nextMatch = "\\s*[-+]\\s*[-+]?\\d+\\s*|\\s*[-+]\\s*[-+]?\\d+\\s*\\*\\s*x\\s*(\\^\\s*[-+]?\\d+\\s*)?|\\s*[-+]\\s*[-+]?\\s*x\\s*(\\^\\s*[-+]?\\d+\\s*)?"
第二步在输入正确的前提下我需要获取每一项的系数及指数构建一个对象(Handle),成员变量即系数(coeff)和指数(power),并设置求导方法(handle),返回一个新的同类型对象。
第三步将所有求导后的对象放到Poly类中进行输出,在输出时需要优化掉系数为0的项,以及合并指数相等的项。在合并同类项时,我采用的是Arraylist而不是HashMap,因为arraylist删除更加方便。
以下为第一次作业的类图,可以看出第一次作业还是较为简单,一共3个类,14个方法就能完成。

以下是第一次作业方法复杂度,可以看出有的方法的基本复杂度(ev)较高,该方法的非结构化程度较高,难以模块化和维护。有的方法模块设计复杂度较高(lv),意味着模块耦合度高,模块难于隔离,维护和复用。有的方法圈复杂度(v)高,说明程序易出错。总体上看第一次作业虽然简单,但是代码风格不尽如人意,这大概是第一次接触面向对象编程犯下的错误吧,这也是为什么我第二次作业完全重写的原因,因为代码可扩展性太差了。
第二次作业在第一次的基础上新增了因子这个概念,即一项可有多个因子相乘,并且因子不仅仅是指数函数,也包含三角函数。这就为求导这一步增加了许多难度。
第一步正则匹配就不赘述了,只不过多了项的匹配方式变得复杂一些而已。下图是一个因子的正则。
1 public static String factorPattern() { 2 String numFun = "[-+]?\\d+"; 3 String triFun = 4 "\\s*(sin|cos)\\s*\\(\\s*x\\s*\\)(\\s*\\^\\s*[-+]?\\d+)?"; 5 String powerFun = "\\s*x\\s*(\\^\\s*[-+]?\\d+)?"; 6 return "(" + powerFun + "|" + triFun + "|" + numFun + ")"; 7 }
第二步的求导部分困扰了我好久,如何能在正确求导的同时确保代码的可扩展性,在苦思冥想一天之后,我最终放弃了可扩展性这一要求,直接将一项归一化成三元组的形式:
a*x^b*sin(x)^c*cos(x)^d
然后按照求导法则得到待输出的项:
x^b*sin(x)^c*cos(x)^d+a*b*x*(b-1)*sin(x)^c*cos(x)^d+a*x^b*c*sin(x)^(c-1)*cos(x)^(d+1)-a*x^b*sin(x)^(c+1)*d*cos(x)^(d-1)
可以看到一项求导后会产生四项,即四个对象
第三步的化简我先合并了同类项,并对sin(x)^2+cos(x)^2=1产生的优化进行一定的考虑,只将含sin(x)^2和cos(x)^2的项检查是否可以合并,也是在优化的过程中,产生了一个让我付出惨痛代价的BUG(见第二部分)。
下图是第二次作业的类图,共4各类,50个方法,结构更复杂,较上一次作业有显著提升。

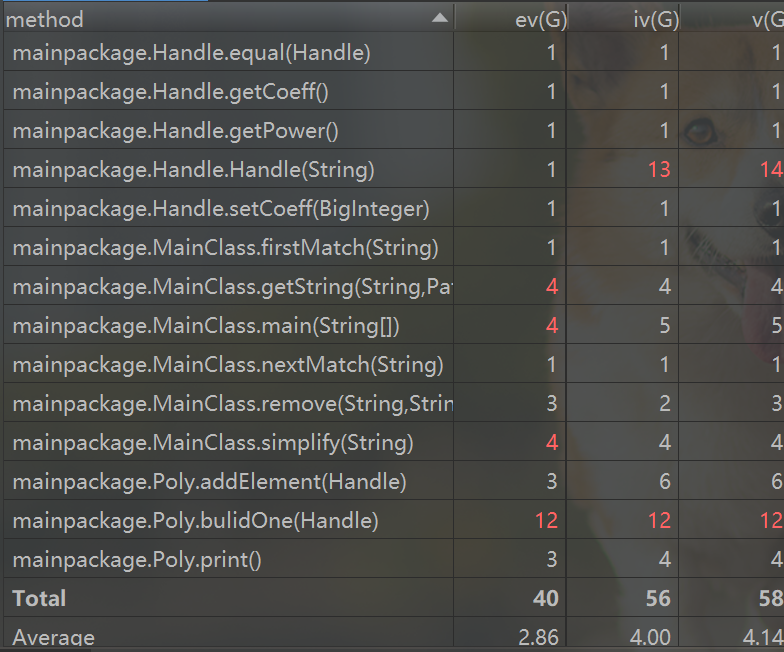
以下是第二次作业方法复杂度分析
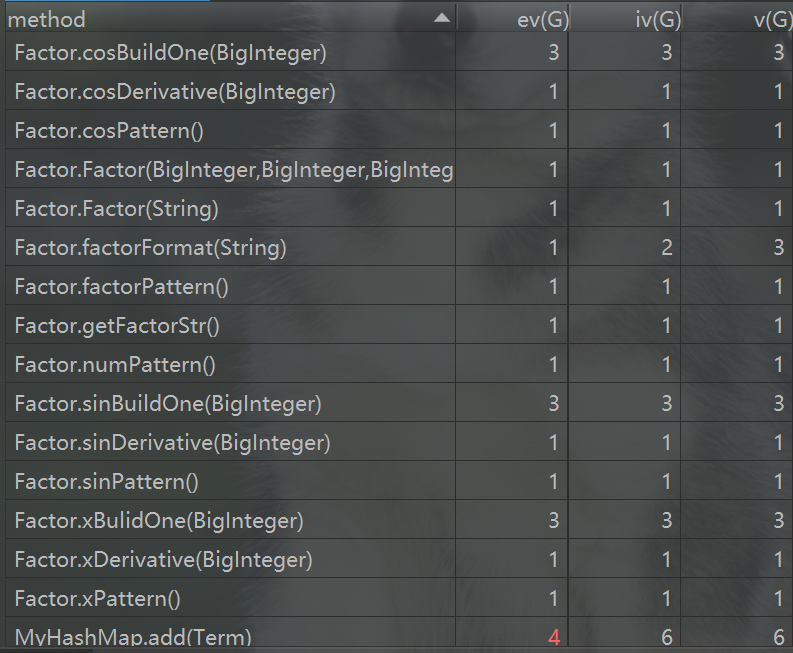
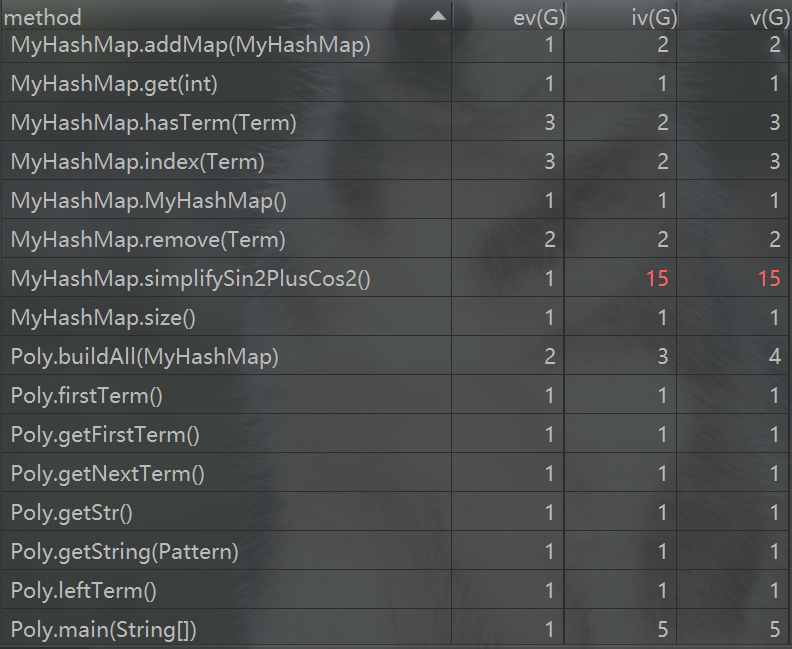
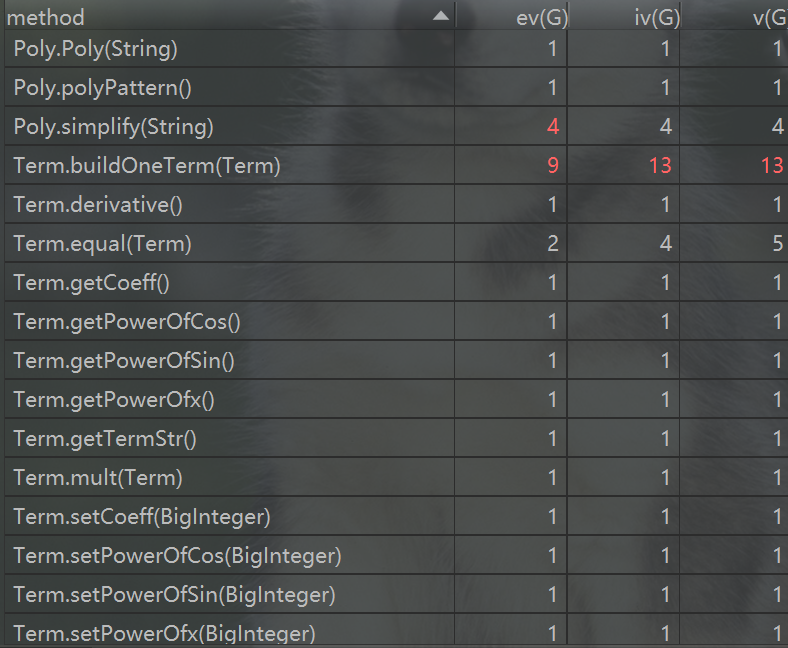
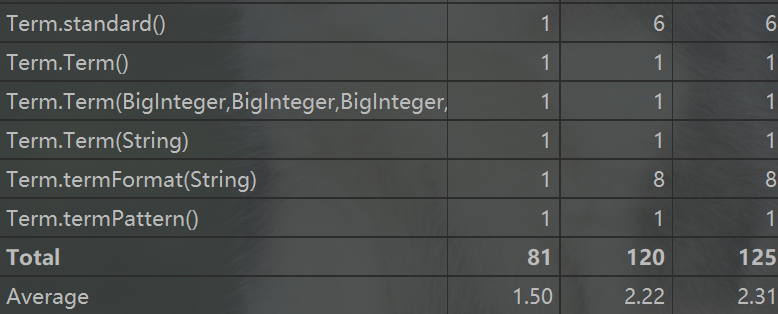
可以看出,虽然方法数量变多了,但复杂度高的方法较第一次有显著减少,主要复杂的方法集中在优化的方法中。例如Poly类中的simplify方法,将正号提前,以及Term中的buildOneTerm方法,将项的长度化到最短,以及MyHashMap中的simplifySin2PlusCos2,将sin(x)^2+cos(x)^2化简,巧合的是,我的bug也正是发生在这个方法中。
第三次作业也是最难的一次作业,简要的概括一下就是包含表达式因子,以及三角函数嵌套因子。第一眼看这道题就离不开递归。递归判断格式,递归求导,递归化简。我完成了前两步。
判断格式,最重要的一步就是如何将表达式拆分成项,显然要从加减号下手,但并不是所有加减号都是项与项之间的运算符,例如x^-1中的指数,以及sin((1-1))中表达式因子里的减号。那我是如何判断一个加减号是否是运算符呢?首先我将加减符号之间的空格去掉,将乘号,指数符号和加减号之间的空格去掉,可以证明这种操作不会将正确(错误)的输入判断成错误(正确)。接下来满足如下判断的就是项与项间的运算符
1.该符号之前左括号总数和右括号总数相等。
2.该符号左邻居不是加减乘,乘方运算符。
至此可以将表达式拆分为项,将项拆分为因子较为简单,只需按乘号进行拆分即可。判断格式的一步在因子类(Factor)内部进行,每一种因子都有相应的格式如下,对于嵌套因子,表达式因子,则需要递归调用相应类的判断格式方法。
1 String numFun = "[ \\t]*[-+]?\\d+[ \\t]*"; 2 String powerFun = "[ \\t]*x[ \\t]*(\\^[ \\t]*[-+]?\\d+)?[ \\t]*"; 3 Pattern polyFactorPattern = Pattern.compile("([ \\t])*\\((.*)\\)([ \\t]*)"); 4 Pattern nestPattern = Pattern.compile("([ \\t]*)(sin|cos)[ \\t]*" 5 + "\\((.*)\\)(([ \\t]*\\^[ \\t]*[-+]?\\d+)?)[ \\t]*");
判断完格式之后进行求导,方法与判断格式类似,只不过到Factor类之后返回求导后得到的字符串,返回到Term类,Term类负责乘法公式,Poly类负责加法公式。
Term类求导方法:
public static String derivative(String str) { ArrayList<String> derivativeArray = fetchFactors(str); String result = ""; for (int i = 0; i < derivativeArray.size(); i++) { result = result + "+" + Factor.derivative(derivativeArray.get(i)); for (int j = 0; j < derivativeArray.size(); j++) { if (j == i) { continue; } else { result = result + "*" + derivativeArray.get(j); } } } return result.substring(1); }
Poly类求导方法:
1 public static String derivative(String str) { 2 ArrayList<String> derivativeArray = fetchTerms(str); 3 for(int i = 0 ;i< derivativeArray.size();i++) { 4 System.out.println(derivativeArray.get(i)); 5 } 6 String result = ""; 7 for (int i = 0; i < derivativeArray.size(); i++) { 8 result = result + "+" + Term.derivative(derivativeArray.get(i)); 9 } 10 return result.substring(1); 11 }
求导完后,我只对没有括号的并且存在0因子的项进行移除,并将没有括号的并且存在多个常数因子的项进行化简。但一旦套了一层括号我就无法化简。例如(+++1),我的输出是(0*+1*+1+0*+1*+1+0*+1*+1),但+++1输出就是0。也就是说化简这部分我没有实现递归化简。
以下是第三次作业的类图,可以看到这次类的数量很少,方法也很少,可想而知方法的复杂度一定很高。而且我类与类之间唯一的联系就是递归调用进行判断格式和求导。

那么方法复杂度有多高呢,来看看方法复杂度表。
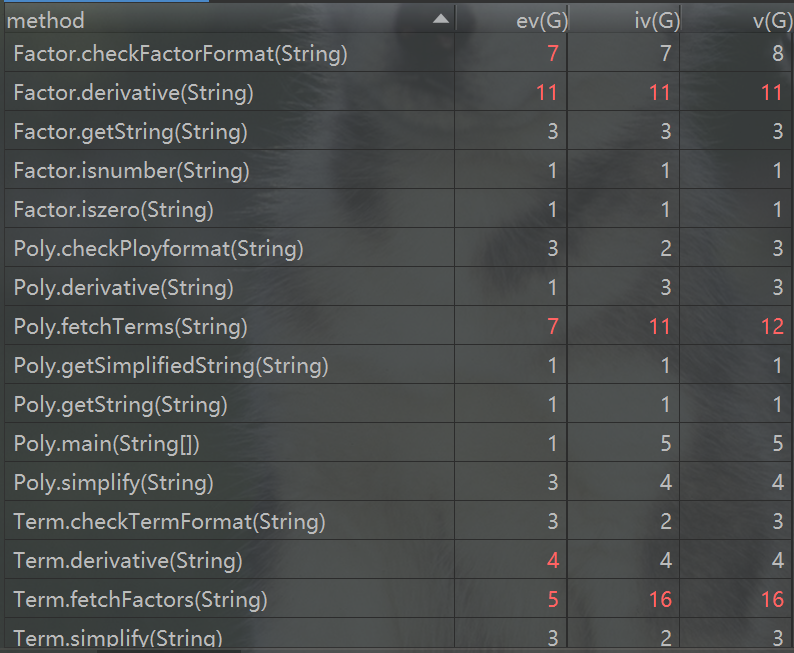

可以看出,方法不多,但标红的数字不少,老实说,这次作业我有点抛弃面向对象的思想了,很大程度上都是面向过程在主导。毕竟一旦涉及到算法问题,设计结构层面很难做到完善,这也是我以后应该弥补的地方。
二. 三次作业产生的BUG分析
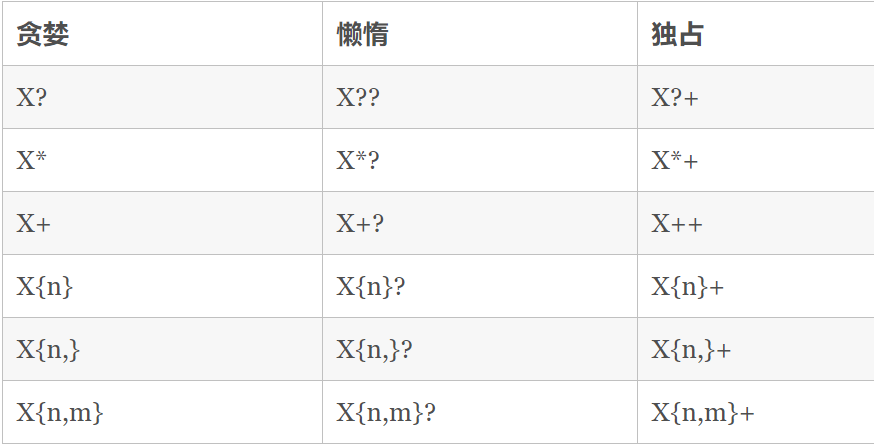
第一次作业唯一的BUG就是将没有将\f,\v等非法空白字符排除,导致在强测满分的情况下互测被Hack了8次,还好都是同质BUG,5行就能改完。BUG产生原因还是没有认真读指导书,自以为输入的空白字符只能是空格和制表符。值得一提的是,在本次作业中的正则匹配环节,我是采用一项一项匹配,而没有采用大正则匹配整个表达式。有的同学采用大正则匹配,在输入为500个“+x”后会产生“StackOverflow”异常。虽然我没有犯这个错误,但我也上网查了查这个错误的原因。正则分为三种模式,而我们通常使用的贪婪模式的回溯特性会给栈空间造成大麻烦。具体如何使用这三种模式见下图。
第二次作业的BUG无疑是致命的,导致我强测只有60出头的分数,勉勉强强进入互测,而这个BUG也是我万万没有想到的一个BUG。具体的说,一旦求导结果符合我的优化要求,在优化过程中就会抛出异常
Exception in thread "main" java.util.ConcurrentModificationException
百度了一下发现我在迭代Arraylist过程中,Arraylist的元素进行了删除增加等操作。
1 for (Term term : terms)
1 this.remove(term); 2 this.add(newTermOne); 3 this.add(newTermTwo);
网上找了一下为什么这样会有错误,CSDN上说Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来集合的单链索引表,当原来的集合数量发生变化时,这个索引表的内容不会同步改变,当索引指针往后移动的时候就找不到要迭代的对象,按照 fail-fast 原则 Iterator 会马上抛出 java.util.ConcurrentModificationException 异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的,但可以使用 Iterator 本身的方法 remove() 来删除对象, Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。 然而我代码中的remove()方法是Arraylist自带的方法,故会产生异常。在这之前,我根本就没有用过迭代器,更别说知道不能删除元素这一原则,只不过是idea提醒我能将for循环简化,我就照着做了,没想到会这么惨,下次再也不敢用迭代器了。
第三次作业目前为止只发现了一个BUG,是没能将错误的输入反馈“WRONG FORMAT!”。具体的就是输入“1+++sin(x)”,但我会输出“cos(x)”。找了找原因,发现下图代码中的问题。
1 if (str.length() > 0) { 2 if (str.charAt(0) != '(') { 3 if (str.length() > 1) { 4 if (str.charAt(1) == '+') { 5 str = str.substring(0, 1) + "+1*" + str.substring(2); 6 } else if (str.charAt(1) == '-') { 7 str = str.substring(0, 1) + "-1*" + str.substring(2); 8 } 9 } 10 } 11 }
首先str是单独的一项(不带加减运算符),如果第零位不是'(',我就要对开头的正负号进行处理,先判断第一位是不是正负号,如果是进行下图操作。我当时只考虑了++1这种项,却忽视了++sin(x)这种项,前者会处理成“+1*+1*1”,而后者会处理成“+1*+1*sin(x)”,这样就会判断错误。事实上这段代码没有存在的意义。即使没有这段代码“++1”在我的程序中会处理成“+1*+1”,而“++sin(x)”会处理成“+1*+sin(x)”,这样就能正确判断格式了。不过还好这次互测不Hack"WRONGFORMAT!", 否则我又要成大礼包了。
三. 互测环节的策略
第一次作业的互测方法主要就是两点。StackOverflow和\f问题,我们组所有人也只有这两个BUG。
第二次作业,由于我被分到了C组,故同组人的BUG异常的多,但我HACK的点主要还是WRONG FORMAT。例如下面这个测试点
+ + +1 + +1 * x ^ +1 * sin ( x ) ^ -1 * cos ( x ) ^ -1
这个测试点将所有可能存在空白字符的地方都放置了一个空格和一个制表符,并在末尾也加了一个空白字符(事实证明好多人都有这个BUG)。
第三次作业,由于过于复杂,自己构造测试样例,自己观察输出变得很不现实,故我开始采用自动评测的方法。将所有人的程序打包成.jar文件放在同意目录下,并在该目录下写my.sh脚本文件。
1 #!/bin/bash 2 #excute .jar(s) 3 find . -name "*.txt" -exec rm -rf {} \; 4 touch archer.txt 5 touch assassin.txt 6 touch berserker.txt 7 touch caster.txt 8 touch lancer.txt 9 touch rider.txt 10 touch saber.txt 11 for ((;;)) 12 do 13 python generate.py > tem.txt 14 15 cat tem.txt >> final.txt 16 cat tem.txt | java -jar archer.jar > archer.txt 17 echo " " >> archer.txt 18 cat tem.txt | java -jar assassin.jar > assassin.txt 19 echo " " >> assassin.txt 20 cat tem.txt | java -jar berserker.jar > berserker.txt 21 cat tem.txt | java -jar lancer.jar > lancer.txt 22 echo " " >> lancer.txt 23 cat tem.txt | java -jar saber.jar > saber.txt 24 cat berserker.txt >> archer.txt 25 cat berserker.txt >> assassin.txt 26 cat berserker.txt > tem.txt 27 cat tem.txt >> berserker.txt 28 cat berserker.txt >> lancer.txt 29 cat berserker.txt >> saber.txt 30 echo "archer and berserker:" >> final.txt 31 cat archer.txt | python OO.py >> final.txt 32 echo "assassin and berserker:" >> final.txt 33 cat assassin.txt | python OO.py >> final.txt 34 echo "berserker and himself:" >> final.txt 35 cat berserker.txt | python OO.py >> final.txt 36 echo "lancer and berserker:" >> final.txt 37 cat lancer.txt | python OO.py >> final.txt 38 echo "saber and berserker:" >> final.txt 39 cat saber.txt | python OO.py >> final.txt 40 done
其中generate.py是陈宇轩巨佬在讨论区提供的自动生成测试样例的程序,OO.py是我自己写的用于比较两个结果是否等价的程序。
OO.py代码如下:
1 from sympy import * 2 from sympy.abc import x 3 4 input_str = input() 5 input_str_two = input() 6 input_str = "(" + input_str.replace("^","**") + ")" 7 input_str_two = "-(" + input_str_two.replace("^","**") + ")" 8 input_str_final = input_str + input_str_two 9 try: 10 if(simplify(input_str_final) == 0):#如果两个结果等价 11 print("Same") 12 else: #否则 13 print("Different") 14 except: #一旦有一个人的程序产生异常,就输出Different 15 print("Different")
自动化测试的优点在于人变得轻松不少,但缺点就是找到的BUG大部分都是同质BUG,且BUG涵盖面不广。老实说,三次互测我都没用认真看过一个人的代码,主要还是太耗时间且收益不大,再加上OS,离散概统数学建模的压迫,不得已才采用如上的互测方法,事实证明效果不错。
四. 创建型模式(Creation Pattern)
说实话,在写博客之前,我都没听说过这个术语,更别说Applying it了。如果非要讲讲的话。前两次作业的创建实例方法类似于工厂模式。
而第三次作业就没有模式可言了,因为整个程序中我一个对象都没有建立,全是用类的静态方法,彻彻底底的面向方法编程。不过我以后再也不敢了。
五. 心得与体会
学了一个月的java和面向对象的思想,就我本人而言,还是没有感受到与面向过程有多大的不同,即使有了类,对象的概念,但在我眼里与C语言的结构体没什么两样。可能是我思维还没有转换过来,这也是我在接下来的作业中要努力去改变的。希望大家一起努力啊?。














 58万+
58万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









