






理论
磁盘文件:
基于终端指令
1)保证parse方法返回一个可迭代类型的对象(存储解析到的页面内容)
2)使用终端指令完成数据存储到指定磁盘文件中的操作,如:scrapy crawl 爬虫文件名称 -o 磁盘文件.后缀 --nolog
基于管道
items.py:存储解析到的页面数据
pipelines.py:处理持久化存储的相关操作
代码实现流程:
1)将解析到的页面数据存储到item对象
2)使用关键字yield将items提交给管道文件处理
3)在管道文件中编写代码完成数据存储的操作
4)在配置文件中开启管道操作
数据库:
基于mysql存储
基于Redis存储
代码实现流程:
1)将解析到的页面数据存储到item对象
2)使用关键字yield将items提交给管道文件处理
3)在管道文件中编写代码完成数据存储的操作
4)在配置文件中开启管道操作
思考:
如何爬取糗事百科多页面数据和将数据同时存储到磁盘文件、MySQL、Redis中?
问题一的解决方案:请求的手动发送
问题二的解决方案:
1)在管道文件中编写对应平台的管道类
2)在配置文件中对自定义的管道类进行生效操作
练习
需求:爬取糗事百科中作者和内容并基于终端指令存储
qiushi.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 class QiushiSpider(scrapy.Spider): 4 name = 'qiushi' 5 # allowed_domains = ['www.xxx.com'] 6 start_urls = ['https://www.qiushibaike.com/text/'] 7 def parse(self, response): 8 div_list=response.xpath('//div[@id="content-left"]/div') 9 data_list=[] 10 for div in div_list: 11 author=div.xpath('.//div[@class="author clearfix"]/a[2]/h2/text()').extract_first() 12 content=div.xpath('.//div[@class="content"]/span/text()').extract_first() 13 dict={ 14 'author':author, 15 'content':content 16 } 17 data_list.append(dict) 18 return data_list
settings.py
1 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400' 2 ROBOTSTXT_OBEY = False
终端操作:

需求:爬取糗事百科中作者和内容并基于管道存储
qiushi.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from qiushiProject.items import QiushiprojectItem 4 class QiushiSpider(scrapy.Spider): 5 name = 'qiushi' 6 # allowed_domains = ['www.xxx.com'] 7 start_urls = ['https://www.qiushibaike.com/text/'] 8 def parse(self, response): 9 div_list=response.xpath('//div[@id="content-left"]/div') 10 for div in div_list: 11 author=div.xpath('.//div[@class="author clearfix"]/a[2]/h2/text()').extract_first() 12 content=div.xpath('.//div[@class="content"]/span/text()').extract_first() 13 #第一步:将解析到的页面数据存储到item对象 14 item=QiushiprojectItem() 15 item['author'] = author 16 item['content'] = content 17 #第二步:使用关键字yield将items提交给管道文件处理 18 yield item
items.py
1 import scrapy 2 class QiushiprojectItem(scrapy.Item): 3 # define the fields for your item here like: 4 author = scrapy.Field() #声明属性 5 content = scrapy.Field()
pipelines.py
1 class QiushiprojectPipeline(object): 2 f=None 3 #该方法只在爬虫开始时调用一次 4 def open_spider(self,spider): 5 print('开始爬虫') 6 self.f=open('./qiushi.txt','w',encoding='utf-8') 7 #该方法可接受爬虫文件提交过来的item对象,并且对item对象中的数据进行持久化存储 8 #参数item:接受到的item对象 9 def process_item(self, item, spider): 10 # 每当爬虫文件向管道提交一次item,则该方法就会被执行一次,故open方法只需打开一次,不然只会写入最后数据 11 print('process_item被调用') 12 #取出item对象中的数据 13 author=item['author'] 14 content=item['content'] 15 self.f.write(author+":"+content) 16 return item 17 # 该方法只在爬虫结束时调用一次 18 def close_spider(self,spider): 19 print('爬虫结束') 20 self.f.close()
settings.py
1 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400'
2 ROBOTSTXT_OBEY = False
3 ITEM_PIPELINES = {
4 'qiushiProject.pipelines.QiushiprojectPipeline': 300,
5 }
终端指令

需求:爬取糗事百科中作者和内容并基于mysql存储
qiushi.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from qiushiProject.items import QiushiprojectItem 4 class QiushiSpider(scrapy.Spider): 5 name = 'qiushi' 6 # allowed_domains = ['www.xxx.com'] 7 start_urls = ['https://www.qiushibaike.com/text/'] 8 def parse(self, response): 9 div_list=response.xpath('//div[@id="content-left"]/div') 10 for div in div_list: 11 author=div.xpath('.//div[@class="author clearfix"]/a[2]/h2/text()').extract_first() 12 content=div.xpath('.//div[@class="content"]/span/text()').extract_first() 13 #第一步:将解析到的页面数据存储到item对象 14 item=QiushiprojectItem() 15 item['author'] = author 16 item['content'] = content 17 #第二步:使用关键字yield将items提交给管道文件处理 18 yield item
items.py
1 import scrapy 2 class QiushiprojectItem(scrapy.Item): 3 # define the fields for your item here like: 4 author = scrapy.Field() #声明属性 5 content = scrapy.Field()
pipelines.py
1 import pymysql 2 class QiushiprojectPipeline(object): 3 conn=None 4 cursor=None 5 def open_spider(self,spider): 6 print('开始爬虫') 7 self.conn=pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123456',db='qiushibaike')#链接数据库 8 def process_item(self, item, spider): 9 sql='insert into qiushi values("%s","%s")'%(item['author'],item['content'])#插入数据 10 self.cursor=self.conn.cursor()#生成游标对象 11 try: 12 self.cursor.execute(sql)#执行sql语句 13 self.conn.commit()#提交事务 14 except Exception as e: 15 print(e) 16 self.conn.rollback() 17 return item 18 def close_spider(self,spider): 19 print('爬虫结束') 20 self.cursor.close() 21 self.conn.close()
settings.py
1 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400'
2 ROBOTSTXT_OBEY = False
3 ITEM_PIPELINES = {
4 'qiushiProject.pipelines.QiushiprojectPipeline': 300,
5 }
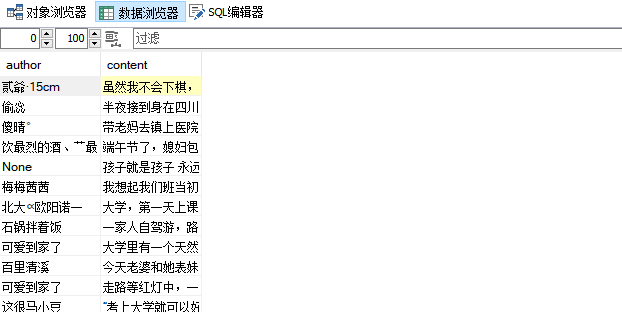
启动MySQL数据库,创建数据库qiushibaike和表qiushi
mysql> create database qiushibaike; mysql> use qiushibaike; mysql> create table qiushi(author char(20),content char(255)); mysql> desc qiushi;
终端指令

查看数据库
mysql> select * from qiushi;
可视化界面
需求:爬取糗事百科中作者和内容并基于Redis存储
qiushi.py
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from qiushiProject.items import QiushiprojectItem
4 class QiushiSpider(scrapy.Spider):
5 name = 'qiushi'
6 # allowed_domains = ['www.xxx.com']
7 start_urls = ['https://www.qiushibaike.com/text/']
8 def parse(self, response):
9 div_list=response.xpath('//div[@id="content-left"]/div') 10 for div in div_list: 11 author=div.xpath('.//div[@class="author clearfix"]/a[2]/h2/text()').extract_first() 12 content=div.xpath('.//div[@class="content"]/span/text()').extract_first() 13 #第一步:将解析到的页面数据存储到item对象 14 item=QiushiprojectItem() 15 item['author'] = author 16 item['content'] = content 17 #第二步:使用关键字yield将items提交给管道文件处理 18 yield item
items.py
1 import scrapy 2 class QiushiprojectItem(scrapy.Item): 3 # define the fields for your item here like: 4 author = scrapy.Field() #声明属性 5 content = scrapy.Field()
pipelines.py
1 import redis 2 class QiushiprojectPipeline(object): 3 conn=None 4 def open_spider(self,spider): 5 print('开始爬虫') 6 self.conn=redis.Redis(host='127.0.0.1',port=6379)#链接数据库 7 def process_item(self, item, spider): 8 dict={ 9 'author':item['author'], 10 'content':item['content'] 11 } 12 self.conn.lpush('data',str(dict))#data为列表名,前后两者必须为字符串类型 13 return item 14 def close_spider(self,spider): 15 print('爬虫结束')
settings.py
1 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400'
2 ROBOTSTXT_OBEY = False
3 ITEM_PIPELINES = {
4 'qiushiProject.pipelines.QiushiprojectPipeline': 300,
5 }
终端指令

启动Redis,并写入数据库
127.0.0.1:6379> lrange data 0 -1
可视化界面

需求:实现爬取糗事百科多页面数据和将数据同时存储到磁盘文件、MySQL、Redis中
qiushi.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from qiushiProject.items import QiushiprojectItem 4 class QiushiSpider(scrapy.Spider): 5 name = 'qiushi' 6 # allowed_domains = ['www.xxx.com'] 7 start_urls = ['https://www.qiushibaike.com/text/'] 8 url='https://www.qiushibaike.com/text/page/%s/' 9 pageNum=1 10 def parse(self, response): 11 div_list=response.xpath('//div[@id="content-left"]/div') 12 for div in div_list: 13 author=div.xpath('.//div[@class="author clearfix"]/a[2]/h2/text()').extract_first() 14 content=div.xpath('.//div[@class="content"]/span/text()').extract_first() 15 item=QiushiprojectItem() 16 item['author'] = author 17 item['content'] = content 18 yield item 19 #13表示最后一页 20 if self.pageNum <= 13: 21 print('第%s页爬取成功并写入文件' % self.pageNum) 22 self.pageNum += 1 23 new_url = 'https://www.qiushibaike.com/text/page/%s/'% self.pageNum 24 yield scrapy.Request(url=new_url,callback=self.parse)
items.py
1 import scrapy 2 class QiushiprojectItem(scrapy.Item): 3 # define the fields for your item here like: 4 author = scrapy.Field() #声明属性 5 content = scrapy.Field()
pipelines.py
1 import redis 2 class QiushiprojectPipeline(object): 3 conn=None 4 def open_spider(self,spider): 5 print('开始爬虫') 6 self.conn=redis.Redis(host='127.0.0.1',port=6379)#链接数据库 7 def process_item(self, item, spider): 8 dict={ 9 'author':item['author'], 10 'content':item['content'] 11 } 12 self.conn.lpush('data',str(dict))#data为列表名,前后两者必须为字符串类型 13 return item 14 def close_spider(self,spider): 15 print('数据已写入Redis数据库中') 16 17 import pymysql 18 class QiushiprojectByMysql(object): 19 conn=None 20 cursor=None 21 def open_spider(self,spider): 22 print('开始爬虫') 23 self.conn=pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123456',db='qiushibaike') 24 def process_item(self,item,spider): 25 sql='insert into qiushi values ("%s","%s")'%(item['author'],item['content']) 26 self.cursor=self.conn.cursor() 27 try: 28 self.cursor.execute(sql) 29 self.conn.commit() 30 except Exception as e: 31 print(e) 32 self.conn.rollback() 33 return item 34 def close_spider(self,spider): 35 print('数据已写入MySQL数据库中') 36 self.cursor.close() 37 self.conn.close() 38 39 class QiushiprojectByFiles(object): 40 f = None 41 def open_spider(self, spider): 42 print('开始爬虫') 43 self.f = open('./qiushi.txt', 'w', encoding='utf-8') 44 def process_item(self, item, spider): 45 author = str(item['author']) 46 content = str(item['content']) 47 self.f.write(author + ":" + content) 48 return item 49 def close_spider(self, spider): 50 print('数据已写入到磁盘文件中') 51 self.f.close()
settings.py
1 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400' 2 ROBOTSTXT_OBEY = False 3 ITEM_PIPELINES = { 4 'qiushiProject.pipelines.QiushiprojectPipeline': 300, 5 'qiushiProject.pipelines.QiushiprojectByMysql': 400, 6 'qiushiProject.pipelines.QiushiprojectByFiles': 500, 7 }
终端指令















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









