






内推阿里电话面试中面试官给我出的一个题:
我想的头一个解决方式。就是放到stl 的map里面对出现的频率作为pair的第二个字段进行排序。之后依照排序结果返回:
以下口说无凭,show your code,当然在讨论帖子中遭遇了project界大牛的sql代码在技术上的碾压。什么是做project的,什么是project师的思维。不要一味的埋头搞算法。
讨论帖:
http://bbs.csdn.net/topics/391080906
python 抓取百度搜索结果的讨论贴:
http://bbs.csdn.net/topics/391077668
实验数据。python从百度抓得:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import urllib2
import re
import os
#connect to a URL
#一页的搜索结果中url大概是200个左右
file_url = open('url.txt','ab+')
#搜索框里的东西,这块能够设置成数字好让每次搜索的结果不一样
search = '123'
url = "http://www.baidu.com/s?wd="+search def setUrlToFile(): website = urllib2.urlopen(url) #read html code html = website.read() #use re.findall to get all the links links = re.findall('"((http|ftp)s?
://.*?)"', html) for s in links: print s[0] if len(s[0]) < 256: file_url.write(s[0]+'\r\n') #收集实验数据 for i in range(0,50): setUrlToFile() file_url.close() ###须要又一次打开再读一下 file_url = open('url.txt','r') file_lines = len(file_url.readlines()) print "there are %d url in %s" %(file_lines,file_url) file_url.close()
方法1:
c++ 写的读 url.txt放到map里面
对map<string , int>的value进行排序,得到前100个
执行一下也就55s,还是非常快的。url长度进行了限制小于256个字符
#pragma once
/*
//计算代码段执行时间的类
//
*/
#include <iostream>
#ifndef ComputeTime_h
#define ComputeTime_h
//单位毫秒
class ComputeTime
{
private:
int Initialized;
__int64 Frequency;
__int64 BeginTime;
public:
bool Avaliable();
double End();
bool Begin();
ComputeTime();
virtual ~ComputeTime();
};
#endif
#include "stdafx.h"
#include "ComputeTime.h"
#include <iostream>
#include <Windows.h>
ComputeTime::ComputeTime()
{
Initialized=QueryPerformanceFrequency((LARGE_INTEGER *)&Frequency);
}
ComputeTime::~ComputeTime()
{
}
bool ComputeTime::Begin()
{
if(!Initialized)
return 0;
return QueryPerformanceCounter((LARGE_INTEGER *)&BeginTime);
}
double ComputeTime::End()
{
if(!Initialized)
return 0;
__int64 endtime;
QueryPerformanceCounter((LARGE_INTEGER *)&endtime);
__int64 elapsed = endtime-BeginTime;
return ((double)elapsed/(double)Frequency)*1000.0; //单位毫秒
}
bool ComputeTime::Avaliable()
{
return Initialized;
}
// sortUrl.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
//#include <utility>
#include <vector>
#include <map>
#include <fstream>
#include <iostream>
#include <string>
#include <algorithm>
#include "ComputeTime.h"
using namespace std;
map<string,int> urlfrequency;
typedef pair<string, int> PAIR;
struct CmpByValue
{
bool operator()(const PAIR& lhs, const PAIR& rhs)
{
return lhs.second > rhs.second;
}
};
void find_largeTH(map<string,int> urlfrequency)
{
//把map中元素转存到vector中 ,依照value排序
vector<PAIR> url_quency_vec(urlfrequency.begin(), urlfrequency.end());
sort(url_quency_vec.begin(), url_quency_vec.end(), CmpByValue());
//url_quency_vec.size()
for (int i = 0; i != 100; ++i)
{
cout<<url_quency_vec[i].first<<endl;
cout<<url_quency_vec[i].second<<endl;
}
}
//urlheap的建立过程,URL插入时候存在的
void insertUrl(string url)
{
pair<map<string ,int>::iterator, bool> Insert_Pair;
Insert_Pair = urlfrequency.insert(map<string, int>::value_type(url,1));
if (Insert_Pair.second == false)
{
(Insert_Pair.first->second++);
}
}
int _tmain(int argc, _TCHAR* argv[])
{
fstream URLfile;
char buffer[1024];
URLfile.open("url.txt",ios::in|ios::out|ios::binary);
if (! URLfile.is_open())
{ cout << "Error opening file"; exit (1); }
else
{
cout<<"open file success!"<<endl;
}
ComputeTime cp;
cp.Begin();
int i = 0;
while (!URLfile.eof())
{
URLfile.getline (buffer,1024);
//cout << buffer << endl;
string temp(buffer);
//cout<<i++<<endl;
insertUrl(temp);
}
find_largeTH(urlfrequency);
cout<<"running time: "<<cp.End()<<"ms"<<endl;
getchar();
//system("pause");
return 0;
}
实验结果:55s还不算太差。能够接受,毕竟是头脑中的第一个解决方式。
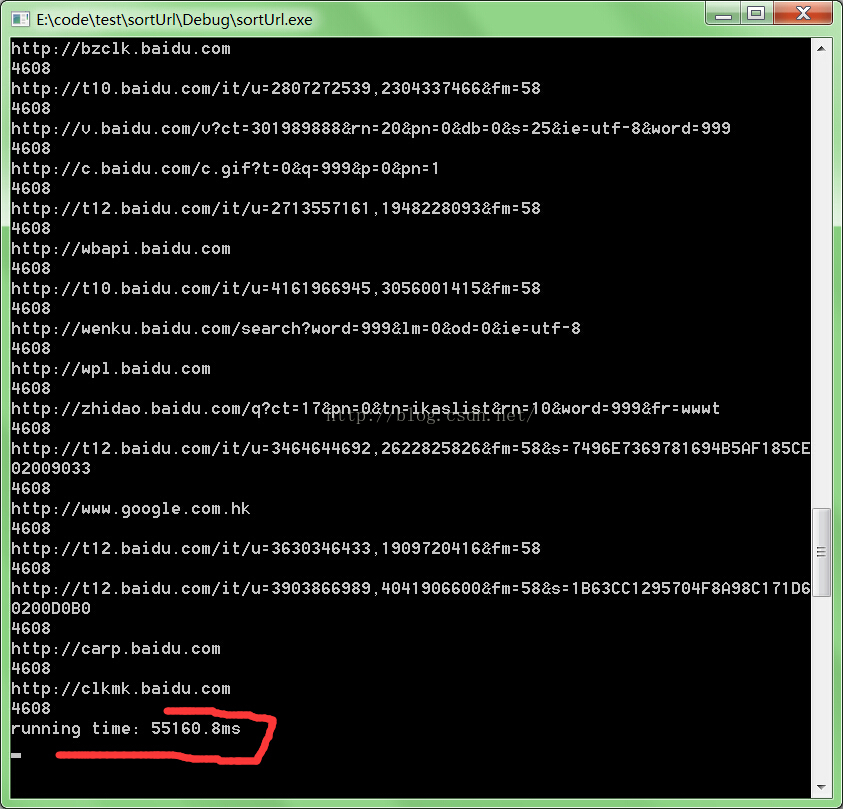
方法2:
hash code 版本号。仅仅是不知道怎么 hash和url关联起来:
// urlFind.cpp : 定义控制台应用程序的入口点。// // sortUrl.cpp : 定义控制台应用程序的入口点。
// #include "stdafx.h" #include <vector> #include <map> #include <fstream> #include <iostream> #include <string> #include <algorithm> #include <unordered_map> #include "ComputeTime.h" using namespace std; map<unsigned int,int> urlhash; typedef pair<unsigned int, int> PAIR; struct info{ string url; int cnt; bool operator<(const info &r) const { return cnt>r.cnt; } }; unordered_map<string,int> count; //priority_queue<info> pq; struct CmpByValue { bool operator()(const PAIR& lhs, const PAIR& rhs) { return lhs.second > rhs.second; } }; void find_largeTH(map<unsigned int,int> urlhash) { //把map中元素转存到vector中 ,依照value排序 vector<PAIR> url_quency_vec(urlhash.begin(), urlhash.end()); sort(url_quency_vec.begin(), url_quency_vec.end(), CmpByValue()); //url_quency_vec.size() for (int i = 0; i != 100; ++i) { cout<<url_quency_vec[i].first<<endl; cout<<url_quency_vec[i].second<<endl; } } // BKDR Hash Function unsigned int BKDRHash(char *str) { unsigned int seed = 131; // 31 131 1313 13131 131313 etc.. unsigned int hash = 0; while (*str) { hash = hash * seed + (*str++); } return (hash & 0x7FFFFFFF); } // void insertUrl(string url) { unsigned int hashvalue = BKDRHash((char *)url.c_str()); pair<map<unsigned int ,int>::iterator, bool> Insert_Pair; Insert_Pair = urlhash.insert(map<unsigned int, int>::value_type(hashvalue,1)); if (Insert_Pair.second == false) { (Insert_Pair.first->second++); } } int _tmain(int argc, _TCHAR* argv[]) { fstream URLfile; char buffer[1024]; URLfile.open("url.txt",ios::in|ios::out|ios::binary); if (! URLfile.is_open()) { cout << "Error opening file"; exit (1); } else { cout<<"open file success!"<<endl; } ComputeTime cp; cp.Begin(); int i = 0; while (!URLfile.eof()) { URLfile.getline (buffer,1024); //cout << buffer << endl; string temp(buffer); //cout<<i++<<endl; insertUrl(temp); } find_largeTH(urlhash); cout<<"running time: "<<cp.End()<<"ms"<<endl; getchar(); //system("pause"); return 0; }
性能15秒左右:缺点在于没有把hashcode和url进行关联,技术的处理速度已经很可观了
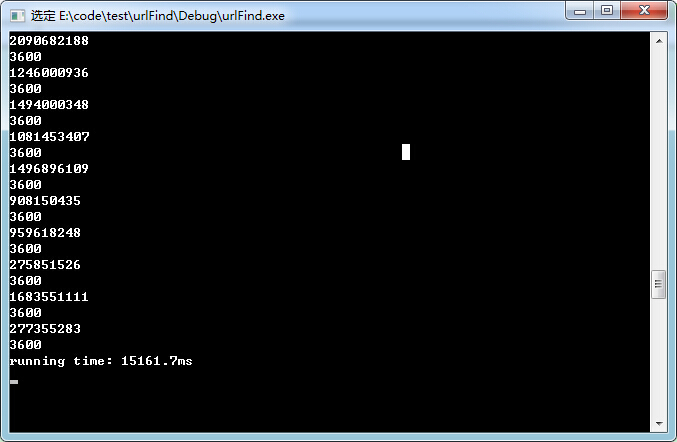
方法3:
以下用STL的hash容器unordered_map。和优先队列(就是堆)来实现这个问题。
// urlFind.cpp : 定义控制台应用程序的入口点。// // sortUrl.cpp : 定义控制台应用程序的入口点。 // #include "stdafx.h" #include <vector> #include <map> #include <fstream> #include <iostream> #include <string> #include <algorithm> #include <unordered_map> #include <queue> #include "ComputeTime.h" using namespace std; typedef pair<string, int> PAIR; struct info { string url; int cnt; bool operator<(const info &r) const { return cnt<r.cnt; } }; unordered_map<string,int> hash_url; priority_queue<info> pq; void find_largeTH(unordered_map<string,int> urlhash) { unordered_map<string,int>::iterator iter = urlhash.begin(); info temp; for (; iter!= urlhash.end();++iter) { temp.url = iter->first; temp.cnt = iter->second; pq.push(temp); } for (int i = 0; i != 100; ++i) { cout<<pq.top().url<<endl; cout<<pq.top().cnt<<endl; pq.pop(); } } void insertUrl(string url) { pair<unordered_map<string ,int>::iterator, bool> Insert_Pair; Insert_Pair = hash_url.insert(unordered_map<string, int>::value_type(url,1)); if (Insert_Pair.second == false) { (Insert_Pair.first->second++); } } int _tmain(int argc, _TCHAR* argv[]) { fstream URLfile; char buffer[1024]; URLfile.open("url.txt",ios::in|ios::out|ios::binary); if (! URLfile.is_open()) { cout << "Error opening file"; exit (1); } else { cout<<"open file success!"<<endl; } ComputeTime cp; cp.Begin(); int i = 0; while (!URLfile.eof()) { URLfile.getline (buffer,1024); //cout << buffer << endl; string temp(buffer); //cout<<i++<<endl; insertUrl(temp); } find_largeTH(hash_url); cout<<"running time: "<<cp.End()<<"ms"<<endl; getchar(); //system("pause"); return 0; }
基本上算是算法里面比較优秀的解决方式了,面试官假设能听到这个方法应该会比較欣喜。
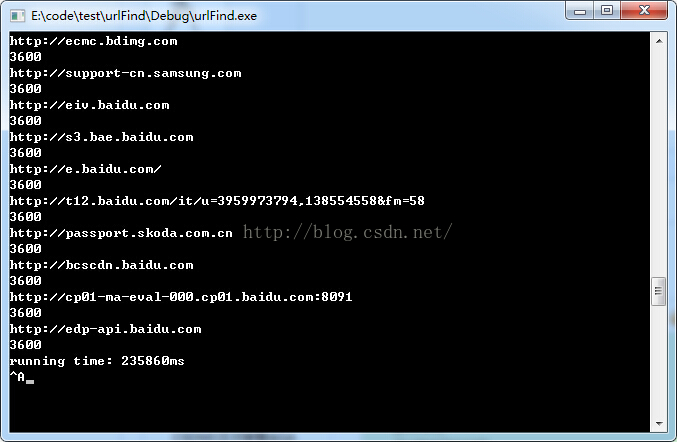
方法4:实验耗时未知,技术上碾压了上述解决方式,中高年轻人。不要反复造轮子。哈哈
数据库,SQL语句:
load data infile "d:/bigdata.txt" into table tb_url(url);
SELECT
url,
count(url) as show_count
FROM
tb_url
GROUP BY url
ORDER BY show_count desc
LIMIT 100














 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









